

英伟达超级芯片更新 首度引入H3Be
描述
近年来人工智能的火热,已经对算力的需求,已经不再是什么新鲜事了。
而围绕着这个市场,除了有几无敌手的英伟达GPU外,还有Graphcore、Cerebra、Sambanova和Tenstorrent等芯片新入者携带着各自打造的“武器”跃跃欲试,以求占有一席之地。
此外,AMD和Intel这些传统芯片巨头也不甘人后,纷纷加码这个赛道。他们一方面升级自己原有的CPU产品,与此同时还在升级GPU产品,其中英特尔甚至还通过对Habana的收购,通过多路进攻的方式押注人工智能。
进来,他们又更新了“武器库”,为新一轮的AI芯片竞赛做好准备。
英伟达超级芯片更新,首度引入H3Be
作为AI市场迄今为止最大的赢家,遥遥领先的英伟达虽然不至于被突然击败,但面对咄咄逼人的竞争对手,他们应该还是有点危机感。于是,在昨晚,英伟达CEO黄仁勋又带来了公司全新的 GH200“superchip”的新变体——世界上第一个配备 HBM3e 内存的 GPU 芯片。
因为人工智能对数据“搬运”的需求,HBM在过去几个月里已经成为产业关注的重中之重,也成为了限制GPU产能的关键因素之一。为此三星和SK海力士等厂商除了在提高HBM产能之余,也在升级其HBM技术,而HBM 3e就是他们正在最新推动的产品。
关于这个尚未敲定的标准,其很多参数也没有定论。但按照集邦咨询所说,HBM3e将采用24Gb单晶芯片堆叠,在8层(8Hi)基础下,单个HBM3e的容量将跃升至24GB。集邦认为,主要制造商预计将在 2024 年第一季度发布 HBM3e 样品,并计划在 2024 年下半年实现量产。而英伟达的GH200“superchip”的新变体计划于明年二季度发货,这体现了AI芯片巨头在其上的迫切。
自 2021 年该公司披露初步细节以来,Grace Hopper superchip一直是 Nvidia 首席执行官黄仁勋的一个大话题。Superchip集成了广泛应用于移动设备、可与英特尔和AMD的基于x86的芯片竞争Arm架构。而之所以Nvidia 称其为“Superchip”,是因为它将基于 Arm 的 Nvidia Grace CPU 与 Hopper GPU 架构结合在一起。而这个芯片在早几个月的发布,已经引起了市场的广泛讨论。
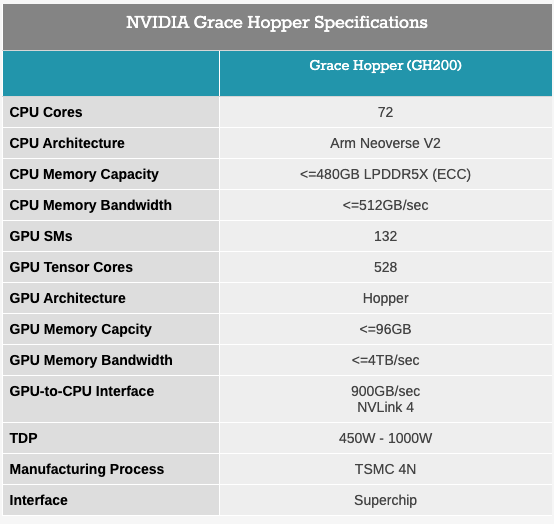
GH200的规格
而在时隔没多久,英伟达带来了全新的升级版本芯片。
据介绍,全新 GH200 Grace Hopper Superchip 同样是基于 72 核 Grace CPU,配备 480 GB ECC LPDDR5X 内存以及 GH100 计算 GPU,搭配 141 GB HBM3E 内存,采用 6 个 24 GB 堆栈,使用 6,144位存储器接口。虽然 Nvidia 物理安装了 144 GB 内存,但只有 141 GB 可用才能获得更高的良率。
作为世界上第一款配备HBM3e 内存的芯片,英伟达新版本的 GH200能够将其本地 GPU 内存增加 50%,这对于人工智能市场来说尤其受欢迎,因为顶级模型尺寸巨大且通常内存容量有限。而在双配置设置中,它将配备高达 282 GB 的 HBM3e 内存,NVIDIA 表示,与当前一代产品相比,内存容量高出 3.5 倍,带宽高出 3 倍。Nvidia还声称,HBM3e内存将使下一代GH200运行AI模型的速度比当前模型快3.5倍。
“我们对这款新的 GH200 感到非常兴奋。它将配备 141 GB 的 HBM3e 内存,”Nvidia 超大规模和 HPC 副总裁兼总经理 Ian Buck 在与媒体和分析师的会议上表示。“HBM3e 不仅增加了 GPU 的容量和内存量,而且速度也更快。”
在 SIGGRAPH 2023 的主题演讲中,NVIDIA 总裁兼首席执行官黄仁勋 (Jensen Huang) 表示:“为了满足生成式 AI 不断增长的需求,数据中心需要具有特殊需求的加速计算平台。”Jensen 还接着说道:“全新 GH200 Grace Hopper Superchip 平台通过卓越的内存技术和带宽来实现这一点,以提高吞吐量、连接 GPU 以不妥协地聚合性能的能力,以及可以在整个数据中心轻松部署的服务器设计。“
从昨晚英伟达的介绍中我们可以看到,他们不仅制造更快的芯片,还在新的服务器设计中对其进行扩展。
如Ian Buck就表示,Nvidia正在开发一种新的基于双GH200的Nvidia MGX服务器系统,该系统将集成两个下一代Grace Hopper Superchip。他解释说,新的GH200将与Nvidia的互连技术NVLink连接。借助新型双 GH200 服务器中的 NVLink,系统中的 CPU 和 GPU 将通过完全一致的内存互连进行连接。
“CPU 可以看到其他 CPU 的内存,GPU 可以看到其他 GPU 内存,当然 GPU 也可以看到 CPU 内存,”Buck说。“因此,合并后的超大超级 GPU 可以作为一个整体运行,提供 144 个 Grace CPU 核心,超过 8 petaflops 的计算性能以及 282 GB 的 HBM3e 内存。”他强调。
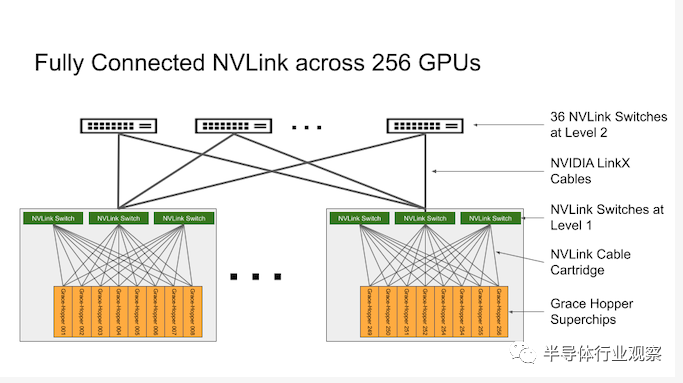
值得一提的是,在此前,我们已经介绍了围绕 NVIDIA Grace Hopper 平台构建的已发布的 DGX GH200 AI 超级计算机。DGX GH200 是完全基于 NVIDIA 架构构建的 24 机架集群,每个 DGX GH200 都结合了 256 个芯片,并提供 120 TB 的 CPU 连接内存。它们使用 NVIDIA 的 NVLink 进行连接,该 NVLink 具有多达 96 个本地 L1 交换机,可在 GH200 刀片之间提供即时通信。NVIDIA 的 NVLink 允许部署与高速一致的互连一起工作,使 GH200 能够完全访问 CPU 内存,并在双配置时允许访问高达 1.2 TB 的内存。
英特尔 Falcon Shores 2,卷土重来
为了应对来自英伟达和AMD的竞争,英特尔最初计划为其称为 Falcon Shores 的 芯片配备 GPU 和 CPU 内核,打造该公司首款用于高性能计算的“XPU”。但是在几个月前,他们意外宣布,Falcon Shores将转向纯 GPU 设计并将芯片推迟到 2025 年,这让行业观察家感到震惊——因为这使得英特尔无法与AMD 的 Instinct MI300和Nvidia 的 Grace Hopper处理器竞争,后两者均采用 CPU+GPU的混合处理器设计。
然而在近日的财报说明会上,英特尔首席执行官 Pat Gelsinger 透露,公司计划于 2026 年推出新版本的 Falcon Shores 芯片,代号为 Falcon Shores 2。Falcon Shores 2 芯片将于 2025年接替首款 Falcon Shores 芯片,后者是一款用于人工智能和超级计算的高性能 GPU。
“当我们将 GPU 和加速器整合到一个产品中时,我们有一个简化的路线图,”
虽然英特尔并未过多谈论这款将于2026 年推出的产品,但英特尔方面曾表示,因为Falcon Shores 芯片将使用Chiplet设计,因此英特尔将能够混合搭配 GPU、AI 加速器和第三方 CPU。
英特尔公司副总裁兼超级计算事业部总经理 Jeff McVeigh 在 5 月份的电话会议上更是表示:“这为跨供应商提供了将 Falcon Shores GPU 与其他 CPU 以及 CPU 与 GPU 比例结合起来的灵活性。”
McVeigh 表示,独立GPU Falcon Shores 产品模型使用基于 GPU 的通用编程接口,CPU 和 GPU 的 CXL 接口将提高代码的生产力和性能。
此外,2026 年的发布Falcon Shores 2,这也许意味着该芯片采用 Angstrom 时代的工艺制作。该芯片制造商将重点放在 2025 年之前的产品发布上,届时将实现四年内启动五个节点的目标。又因为Falcon Shores 2 的发布日期为 2026 年,这似乎代表着原始版本的 Falcon Shores GPU 的生命周期很短,是一个过渡产品。
如之前很多报道中所说,Falcon Shores 芯片是专为 HPC 和 AI 计算而设计,英特尔已经讨论过将 GPU 与 Gaudi 芯片系列合并。Gelsinger在财报电话会议上表示,Falcon Shores 的执行情况“良好”。他同时还表示Falcon Shores 将拥有最好的 GPU 和最好的矩阵加速。
对于其GPU和Gaudi等面向AI的芯片,英特尔的目标是确保人工智能软件堆栈通过其 OneAPI 软件堆栈在 Gaudi 和 Falcon Shores 芯片上向前兼容。
“我们将扩大该软件堆栈的灵活性。我们正在添加 FP8。我们刚刚添加了 PyTorch 2 支持。一路走来的每一步,它都会变得更好、更广泛的用例。正在支持更多语言模型。软件堆栈支持更多的可编程性,”Gelsinger强调。
此外,英特尔还在通过 OneAPI 采用部分开放的软件方法,该方法以名为 SYCLomatic 的工具为中心,可以转换专有的 CUDA 代码以在包括 Ponte Vecchio 在内的各种 GPU 上运行。
AMD也不甘人后
在英特尔和英伟达在为未来倾囊而出的同时,AMD也不甘人后。几个月前,公司就带来了全新的MI 300系列芯片,这也是公司面向AI市场祭出的一个杀手锏。具体信息参考半导体行业观察之前的报道《1530亿晶体管芯片发布,AMD正式叫板英伟达》。而在AMD最近的财报发布会上,该公司CEO Lisa Su也披露,AMD的AI芯片参与度在本季度增加了七倍多。
Lisa同时还表示,公司在遵守美国的出口管制之余。正在寻找机会为中国客户提供定制的人工智能解决方案。
众所周知,随着生成式人工智能的出现,市场对 GPU 的需求猛增。特斯拉的Elon Musk在该公司最近的财报电话会议上谈到了 Nvidia GPU 的短缺问题,微软也在其年报中谈到了GPU短缺可能带来的风险,为此这些公司正在寻找人工智能芯片替代品的机会。
其中,AMD无疑是最值得关注的一家。
审核编辑:刘清
-
英伟达发布RTX Spark超级芯片2026-06-02 1358
-
美对华芯片出口“松绑”:英伟达H200获准进入中国市场#AI芯片#英伟达#H200芯片jf_15747056 2026-01-14
-
英伟达H200芯片将大规模交付2024-07-04 2354
-
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片2024-05-13 6776
-
英伟达H200和H100的比较2024-03-07 10761
-
英伟达DRIVE Thor超级芯片首搭极氪新车2024-01-25 2331
-
英伟达斥资预购HBM3内存,为H200及超级芯片储备产能2024-01-02 1768
-
英伟达新一代人工智能(AI)芯片HGX H2002023-11-15 2461
-
英伟达全球首发超级AI芯片 训练大模型成本更低2023-08-09 2094
-
工业富联采用基于英伟达的超级芯片NVIDIA Grace CPU2022-05-26 5479
-
英伟达DPU的过“芯”之处2022-03-29 5979
-
NVIDIA发布最新Hopper架构的H100系列GPU和Grace CPU超级芯片2022-03-26 4305
-
英伟达携手微软合作进行超级计算2019-11-19 2853
全部0条评论

快来发表一下你的评论吧 !
