

对于极暗场景RAW图像去噪,你是否还在被标定折磨?
描述
本文为 [ICCV 2023] Lighting Every Darkness in Two Pairs: A Calibration-Free Pipeline for RAW Denosing 的简要介绍

Github:https://github.com/Srameo/LED
Homepage:https://srameo.github.io/projects/led-iccv23/
Paper:http://arxiv.org/abs/2308.03448
TL; DR;
基于标定的方法在极低光照环境下的 RAW 图像去噪中占主导地位。然而,这些方法存在几个主要缺陷:
噪声参数标定过程费力且耗时,
不同相机的降噪网络难以相互转换,
合成噪声和真实噪声之间的差异被高倍数字增益放大。
为了克服上述缺点,我们提出了一种无需标定的pipeline来照亮 Lighing Every Darkness(LED),无论数字增益或相机传感器的种类。我们的方法无需标定噪声参数和重复训练,只需少量配对数据和快速微调即可适应目标相机。此外,简单的结构变化可以缩小合成噪声和真实噪声之间的domain gap,而无需任何额外的计算成本。在SID[1]上仅需总共 6 对配对数据、和 0.5% 的迭代次数以及0.2%的训练时间,LED便表现出SOTA的性能!
Introduction
使用真实配对数据进行训练
SID[1] 首先提出一套完整的 benchmark 以及 dataset 进行RAW图像低光增强或去噪。为什么要从RAW图像出发进行去噪和低光增强呢?因为其具有更高的上限,具体可以参考 SID[1] 的文章。
那么它具体的做法是什么呢?很简单,如图1左,使用相机拍摄大量配对的真实数据,之后直接堆到网络里进行训练。
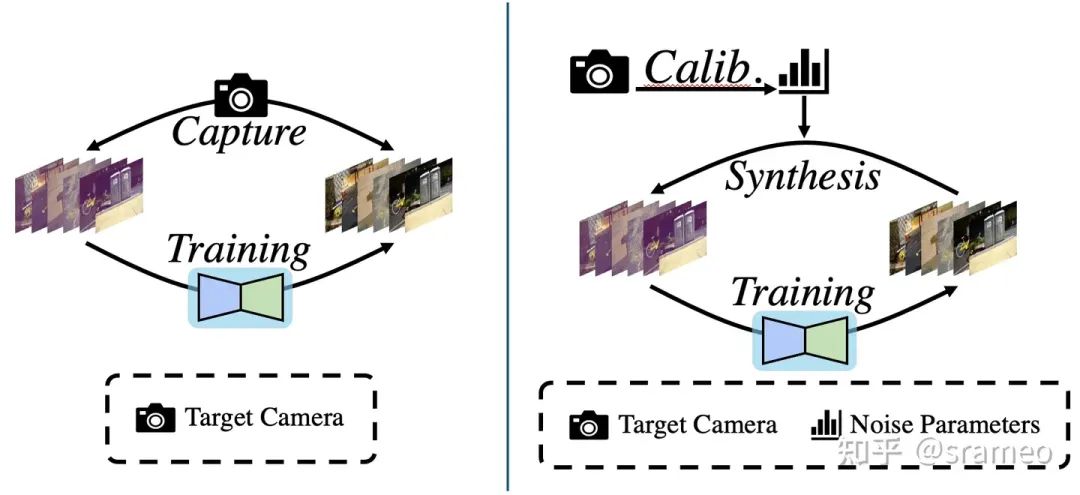
图1: 基于真实配对数据进行训练流程(左)以及基于噪声模型标定进行训练流程(右)
但是有一个很重要的问题,不同的传感器,噪声模型以及参数都是不同的。那么按照这种流程,难道我们对每种相机都需要重新收集大量数据并重新训练?是不是有点太繁琐了?
基于噪声模型标定的算法流程
对于上述提到的问题,近期的paper[2] [3] [4] [5]统一告诉我们:是的。现在,大家主要卷的,包括在各种工业场景(手机、边缘设备上),去噪任务都已经开始采用基于标定的手段。
那么什么是标定呢?具体的标定流程大家可以参考
@Wang Hawk
的文章Wang Hawk:60. 数码相机成像时的噪声模型与标定。当然,基于深度学习+噪声模型标定的算法大概就分为如下三步(可以参考图1右):
1. 设计噪声模型,收集标定用数据,
2.使用 1. 中的标定的数据对对噪声模型进行参数估计 埋个伏笔,增益(或者说iso)和噪声方差有着log域的线性关系
3. 使用 2. 中标定好的噪声模型合成配对数据并训练神经网络。
这样,对于不同的相机,我们只需使用不同的标定数据(收集难度相对于大规模配对数据集来讲少了很多),便可以训练出对应该相机的专用去噪网络。
但是,标定算法真的好吗?
标定缺陷以及 LED
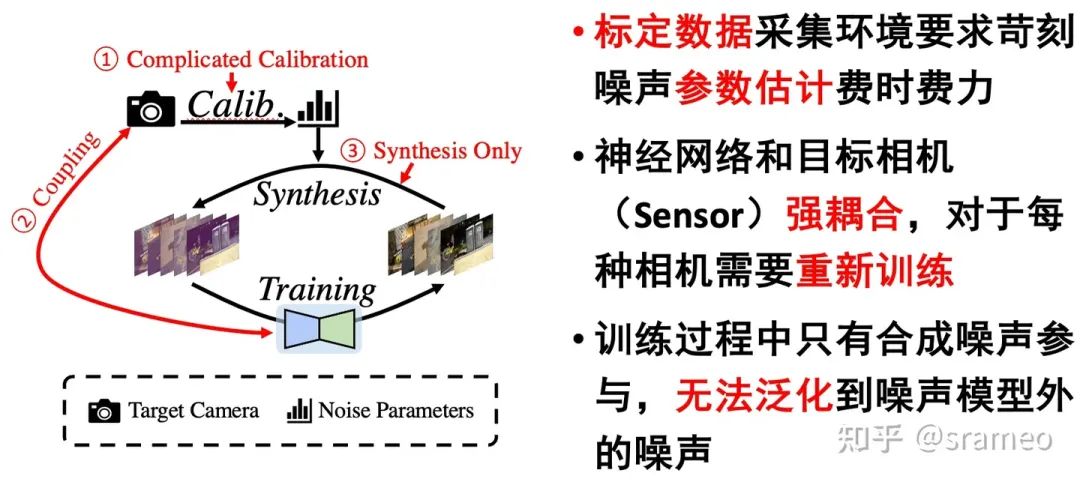
图2: 基于噪声模型标定的算法缺陷
那么我们喜欢什么呢?
简化标定[6][7],甚至无需标定,
快速部署到新相机上,
强大的“泛化”能力:很好的泛化到真实场景,克服合成噪声到真实噪声之间的domain gap。
So here comes LED!
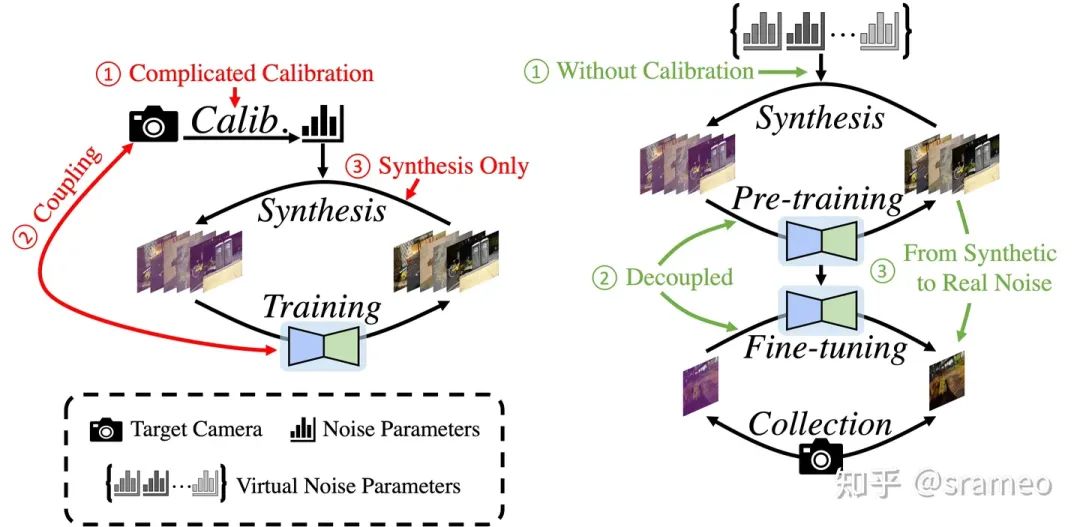
图3: 标定算法与LED的对比
无需标定:相比于标定算法需要使用真实相机的噪声参数,我们采用虚拟相机噪声参数进行数据合成,
快速部署:采用 Pretrain-Finetune 的训练策略,对于新相机仅需少量数据对网络部分参数进行微调,
克服 Domain Gap:通过少量真实数据进行 finetune 以获得去除真实噪声的能力。
LED 能做到什么?
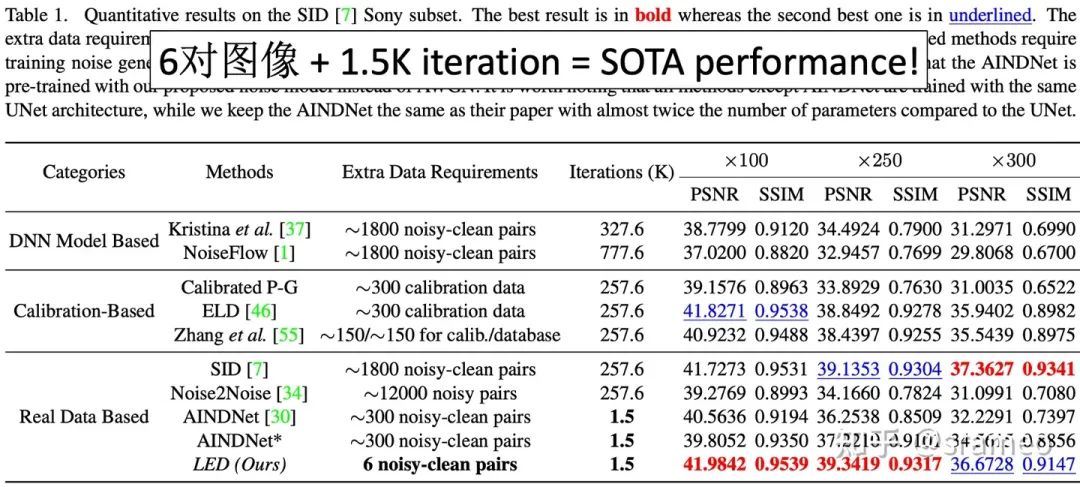
图4: 6对数据 + 1.5K iteration = SOTA Performance!
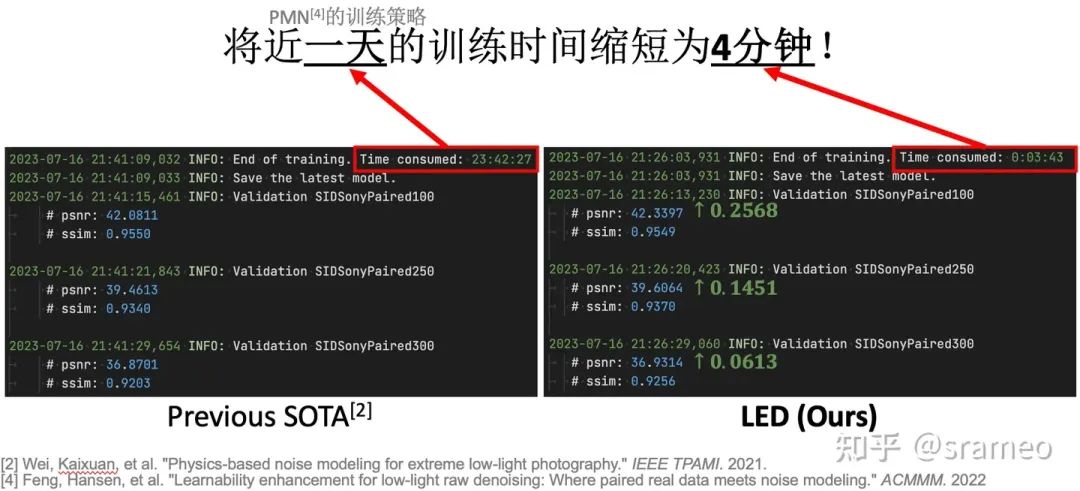
图5: 更直观的log对比
Method
LED大概分为一下几步:
预定义噪声模型Φ ,从参数空间中随机采集 N 组 “虚拟相机” 噪声参数,
使用 1. 中的 N 组 “虚拟相机” 噪声参数合成并 Pretrain 神经网络,
使用目标相机收集少量配对数据,
、
使用 3. 中的少量数据 Finetune 2. 中预训练的神经网络。
当然,一个普通的 UNet 并不能很好的完成我们前文说的3个“需要”。因此结构上也需要做少量更改:
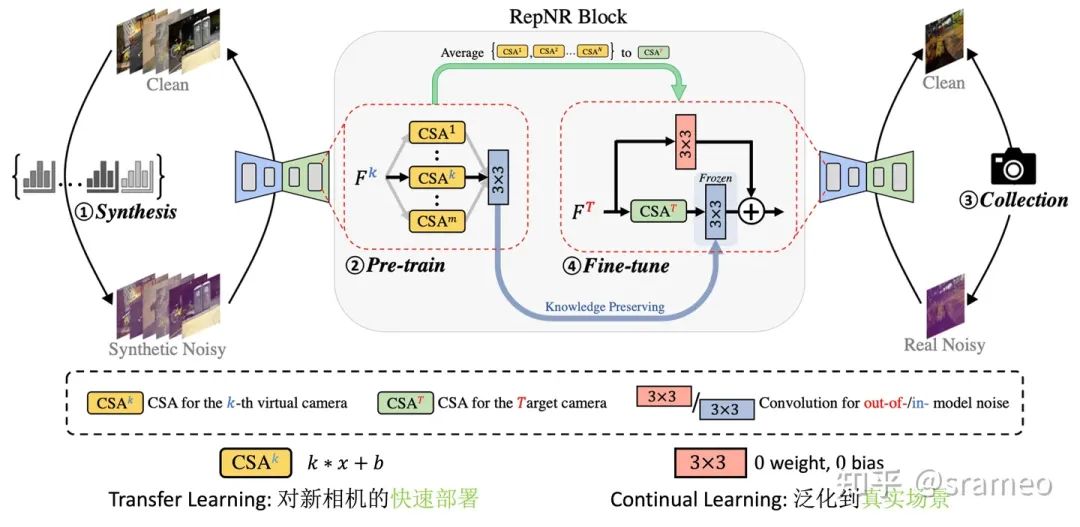
图6: UNet 结构中的 RepNR Block
首先,我们把 UNet 里所有的 Conv3 配上一组CSA (Camera Specific Alignment),CSA 指一个简单的 channel-wise weight 和一组 channel-wise 的 bias,用于 feature space 上的对齐。
Pretrain 时,对于第 k 个相机合成的数据,我们只训练第 k 个CSA以及 Conv3。
Finetune 时,先将 Pretrain 时的CSA组进行 Average 得到初始化的CSA^T (for target camera),然后先将其训练收敛;之后添加一个额外分枝,继续微调,额外分枝用于学习合成噪声和真实噪声之间的 Domain Gap。
当然,由于CSA以及卷积都是线性操作,所以我们在部署时候可以将他们全部都重参数化到一起,因此最终不会引入任何额外计算量!
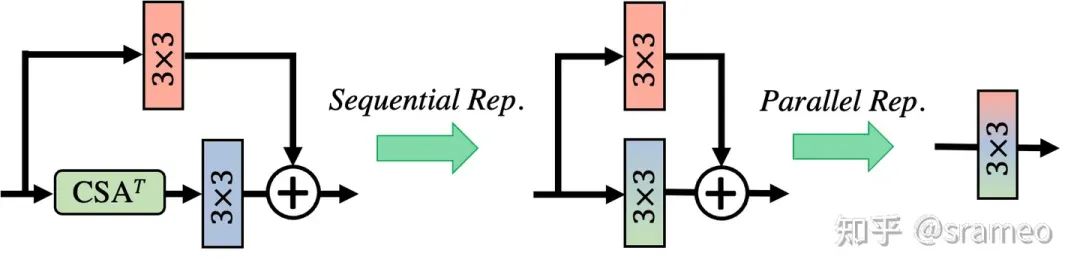
图7: 重参数化
Visual Result
下图表现出了 LED 对于 Out-of-model 噪声的去除能力(克服合成噪声与真实噪声之间 Domain Gap 的能力)。
Out-Of-Model Noise 指不被预定义在噪声模型中的噪声,如图8中由镜头所引起的噪声或图9中由 Dark Shading 所引起的噪声

图8: Out-Of-Model Pattern 去除能力(镜头引发的 Artifact)

图9: Out-of-model 噪声去除能力(Dark Shading)
Discussion on “为什么需要两对数据?”
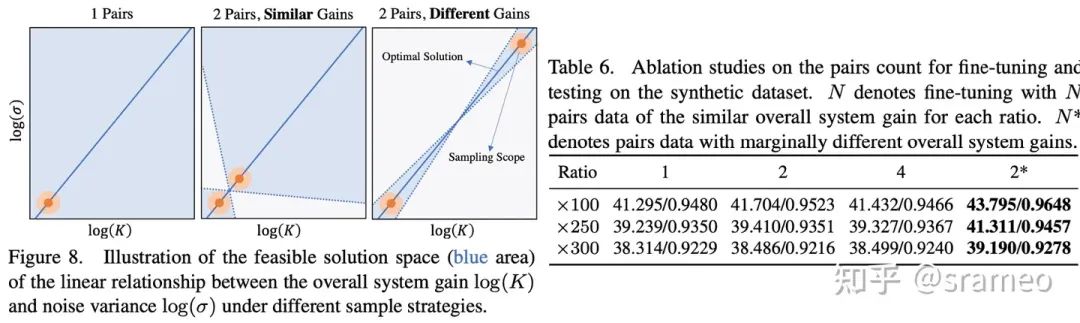
图10
不知道大家记不记得之前埋的一个伏笔:增益和噪声方差之间保持对数线性关系。
线性关系意味着什么呢?两点确定一条直线!也就是说两对数据(每对数据都能提供在某增益下噪声方差的值)就可以确定这个线性关系。但是,由于存在误差[2],所以我们需要增益差距尽可能大的两对数据以完成网络对线性关系的学习。
从图10右也能看出,当我们无论使用增益相同的 1、2、4 对数据,性能并不会有太大的差距。而使用增益差距很大的两对数据(差异很大指 ISO<500 与 ISO>5000)时,性能有巨大提升。这也能验证我们的假设,即两对数据便可以学习到线性关系。
后记:关于开源
我们的训练测试包括对ELD的复现代码都已经开源到 Github 上了,如果大家感兴趣的话可以帮我们点个 star。
当然不仅是代码,我们还一口气开源了 配对数据、ELD、PG(泊松-高斯)噪声模型在多款相机上、不同训练策略、不同阶段(指 LED 的 Pre-train 和 Fine-tune 阶段)的一共15个模型,详见 pretrained-model.md。
此外,由于 RepNR block 目前只在 UNet 上进行了测试,不过我们相信其在别的模型上的潜力。于是,我们提供了快速将 RepNR block 用于别的模型上的代码,仅需一行代码,便可在你自己的网络结构上使用 RepNR block,配合我们的 Noisy-Clean 生成器,可以快速验证 RepNR block 在其他结构上的有效性。相关讲解以及代码可以在 develop.md 中找到。
-
如何解决图像去噪在去除噪声的同时容易丢失细节信息的问题2019-01-03 2243
-
基于多通道联合估计的非局部均值彩色图像去噪方法2018-02-27 1285
-
基于中值滤波和小波变换的火电厂炉膛火焰图像去噪方法2017-11-27 1383
-
基于数据驱动紧框架图像去噪模型2017-11-05 1515
-
基于Gauss滤波和Euler修复模型的SAR图像去噪2017-01-07 864
-
免疫机理的图像去噪方法研究2017-01-03 641
-
求基于fpga的图像去噪的设计2013-05-12 3660
-
基于边缘检测的NSCT自适应阈值图像去噪2010-01-22 1222
-
基于一种新阈值函数的小波医学图像去噪2010-01-15 958
-
基于提升小波的图像去噪算法的FPGA设计2009-12-26 1111
-
一种自适应多尺度积阈值的图像去噪算法2009-11-11 658
-
基于小波变换气动光学效应模糊图像去噪2009-08-06 810
-
基于稀疏分解的图像去噪2008-12-03 1307
全部0条评论

快来发表一下你的评论吧 !
