

一个简单的pipeline是如何构建起来的?
描述
续接上文,这一次我们来详细了解下一个简单的pipeline是如何构建起来的
》最简单的流水线
书接上文,一个最简单的流水线例子,这里对data_in打两拍做输出:
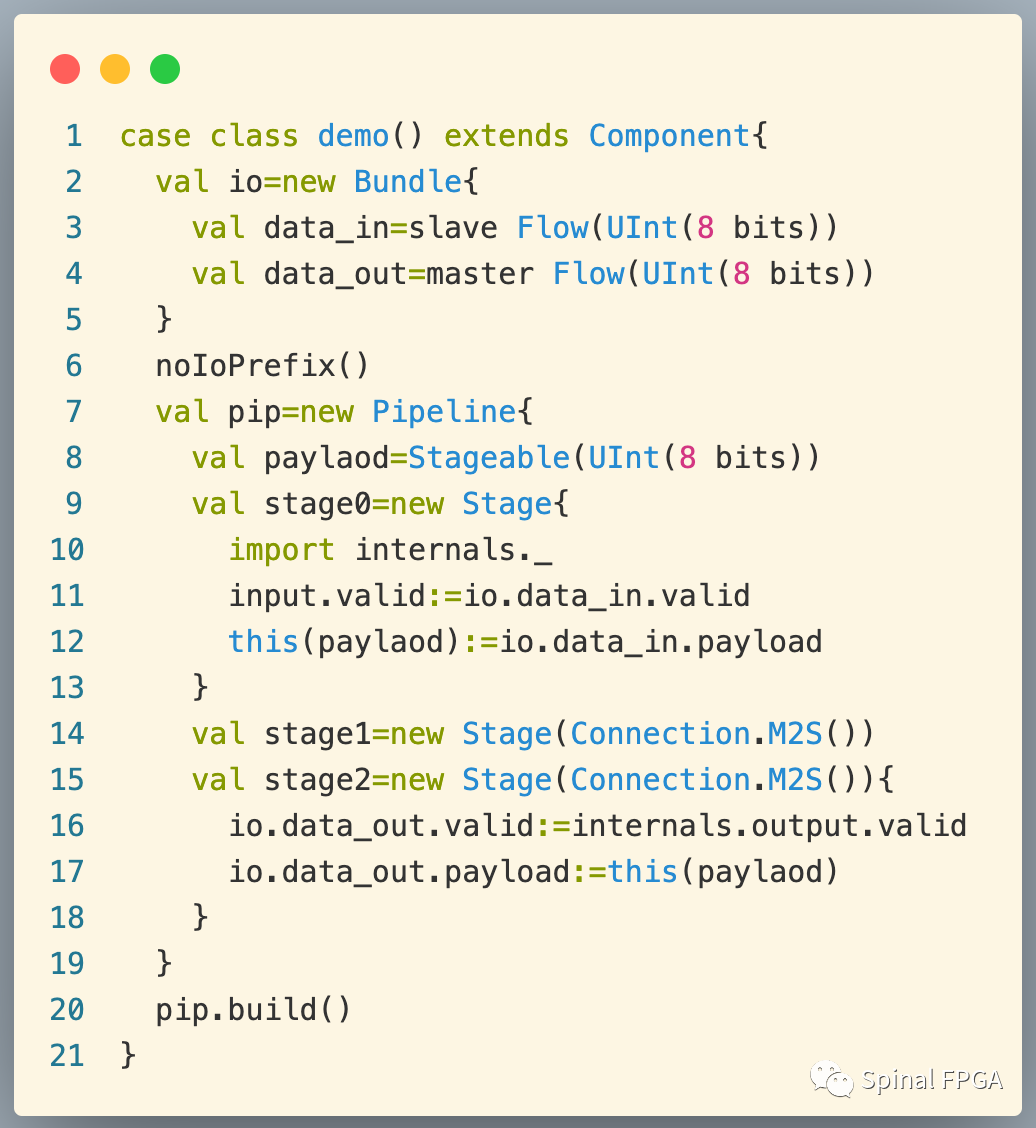
我们逐行分析pipeline里每一行代码都干了什么。
》Stage分析
在第八行我们声明了一个Stageable变量,如前文所述,Stageable变量并不会立即产生电路对象。
代码第9行,我们创建一个Stage,Stage中的下面的代码会通过调用Pipeline中的addStage函数向Pipeline中的StageSet添加当前Stage:
if(_pip != null) {
_pip.addStage(this)
}
在stage0中,第11行用io.data_in.valid驱动stage0中的internals.input.valid。而在第12行,从左向右看,this(payload)函数会调用Stage的apply函数:
def apply[T <: Data](key : Stageable[T]) : T = {
apply(StageableKey(key.asInstanceOf[Stageable[Data]], null)).asInstanceOf[T]
}
其进一步调用:
def apply(key : StageableKey) : Data = {
internals.stageableToData.getOrElseUpdate(key, ContextSwapper.outsideCondScope{
key.stageable()//.setCompositeName(this, s"${key}")
})
}
可以看到,这里的主要作用是一StageableKey作为Key查询internals.stageableToData中是否包含该key,如果有则返回其value,否则创建该key-value,并将value返回。
最终这里会返回一个UInt(8 bits)电路对象。并将io.data_in.payload赋值给该电路对象。此时,stage0中的internals.stageableToData中包含一个元素。
在第14行,我们创建了stage1,其例化时传入了Connection,其会调用:
if(_pip != null) {
_pip.addStage(this)
}
def chainConnect(connection: ConnectionLogic): Unit ={
_pip.connect(_pip.stagesSet.takeWhile(_ != this).last, this)(connection)
}
def this(connection: ConnectionLogic)(implicit _pip: Pipeline) {
this()
chainConnect(connection)
}
这里的的调用关系是:
当前Pipeline的StageSet添加当前Stage元素
通过调用pipeline的connect函数和StageSet中的最后一个元素建立连接关系:
def connect(m : Stage, s : Stage)(logics : ConnectionLogic*) = {
val c = new ConnectionModel
connections += c
c.m = m
c.s = s
c.logics ++= logics
c
}
在connection里,创建了一个连接关系ConnectionModel,用于连接stage0中的output接口和stage1的input接口,采用M2S()方式进行连接。
同样,15行同样stage2的创建亦如此。
代码第16行则是用stage2的output.valid驱动data_out的valid输出。而代码第17行通过同样的方式创建了一个UInt(8 bits)电路对象,用来驱动data_out.payload。此时stage2中的internals.stageableToData中包含一个元素。
最后调用pipeline的build函数进行流水线的搭建。
》build分析
我们按片段来分析build中的代码:
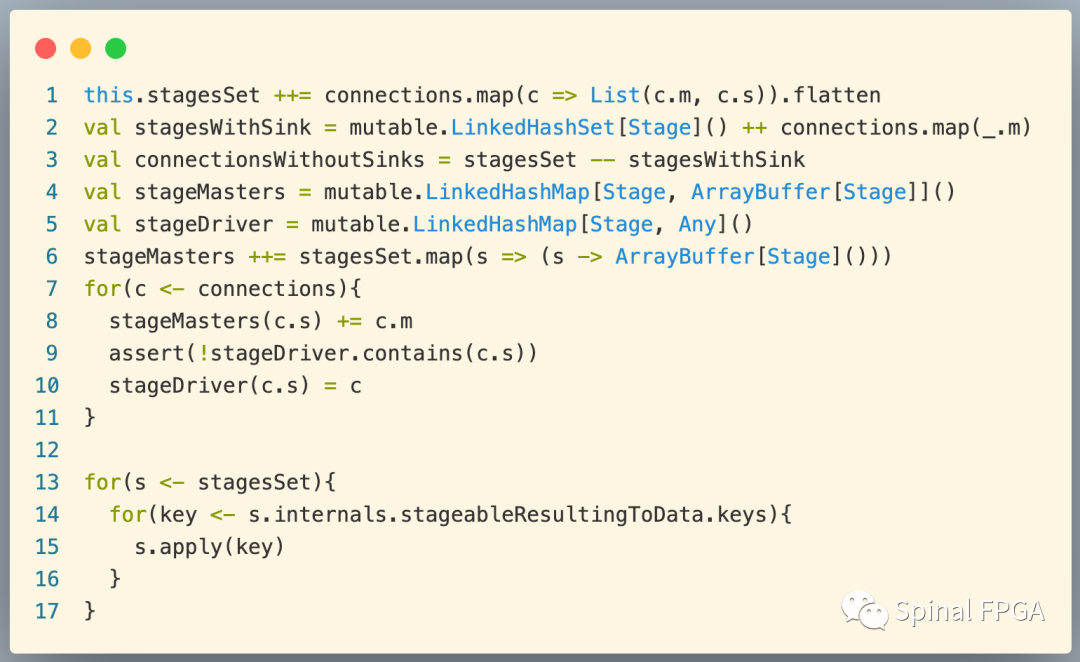
首先,上面第一行代码将connection中的stage添加到stageSet。在执行该行之前,stageSet中包含了stage0、stage1、stage2三个元素,而connection按照描述进行map后得到两个元素:(stage0,stage1),(stage1,stage2)。由于stageSet为LinkedHashSet,故执行完后依然是(stage0,stage1,stage2)。
第二行代码则是获取带有slave驱动的stage,这里即stage0(驱动stage1)、stage1(驱动stage2)。
第三行则是获取没有slave驱动的stage,这里只有stage2。
第7~8行则是分别建立每个stage都是由谁驱动的映射存储至stageMaster、而stage input的驱动逻辑则存储至stageDriver。同时这里也限制了每个stage,最多只能由一个驱动逻辑。处理完后,stageMaster、stageDriver中存储的元素分别为:
stageMaster: stage0->ArrayBuffer() stage1->ArrayBuffer(stage0) stage2->ArrayBuffer(stage2) stageDriver: stage1->Connection(m=stage0,s=stage1,logic=M2S) stage2->Connection(m=stage1,s=stage2,logic=M2S)
代码13~16行由于我们并没有使用到stageableResultingToData,这里可以暂时忽略,等后续章节再进行讨论。
val clFlush = mutable.LinkedHashMap[ConnectionLogic, Bool]() val clFlushNext = mutable.LinkedHashMap[ConnectionLogic, Bool]() val clFlushNextHit = mutable.LinkedHashMap[ConnectionLogic, Bool]() val clThrowOne = mutable.LinkedHashMap[ConnectionLogic, Bool]() val clThrowOneHit = mutable.LinkedHashMap[ConnectionLogic, Bool]()
这里声明的变量我们这里都是用不上,可以暂时先不进行关注。
def propagateData(key : StageableKey, stage : Stage): Boolean ={
if(stage.internals.stageableTerminal.contains(key)) return false
stage.stageableToData.get(key) match {
case None => {
val hits = ArrayBuffer[Stage]()
for(m <- stageMasters(stage)){
if(propagateData(key, m)){
stage.apply(key) //Force creation
hits += m
}
}
hits.size match {
case 0 => false
case 1 => true
case 2 => PendingError(s"$key at $stage has multiple drivers : ${hits.mkString(",")}"); false
}
}
case Some(x) => true
}
}
for(stage <- stagesSet){
for(key <- stage.stageableToData.keys){
for(m <- stageMasters(stage)) {
propagateData(key, m);
}
}
}
这里就有点儿意思了对于StageSet中的每个stage中stageableToData中的每个元素,都会调用propgateData函数进行处理。我们不妨先来看看此时各stage中的stageableToData中的元素:
stage0: StageableKey(payload,null)->UInt(8) stage1: null stage2: StageableKey(payload,null)->UInt(8)
由于stage0没有master,无需考虑,stage1中stageableToData为空,也可以跳过。那么来看stage2,此时调用propagateData传入的参数为:
key=StageableKey(payload,null)->UInt(8) m=stage1
进入propagateData函数,由于stageableTerminal我们并未使用,继续往下看,由于stage1中的stageableToData为空,故这里match匹配为None,此时会看stage1的master端口,此时嵌套调用propagateData,传入参数为:
key=StageableKey(payload,null)->UInt(8) m=stage0
由于stage0中的stageableToData包含该key,那么此时返回true退出,再次回到头次调用的处理上。
由于嵌套返回true,那么此时会在stage1上调用apply函数,为stage1插入一个stageableKey。最终,各stage中stageableToData的结果为:
stage0: StageableKey(payload,null)->UInt(8) stage1: StageableKey(payload,null)->UInt(8) stage2: StageableKey(payload,null)->UInt(8)
看到这里,是不是明白了一些门道了呢?pipeline自动帮我们补齐了stage1中所依赖的元素,完成了payload从stage0到stage2中的传输元素补齐。
对于propagateRequirements函数,这里我们并用不上,这里我们先无需关注。
接下来看时internal connections:
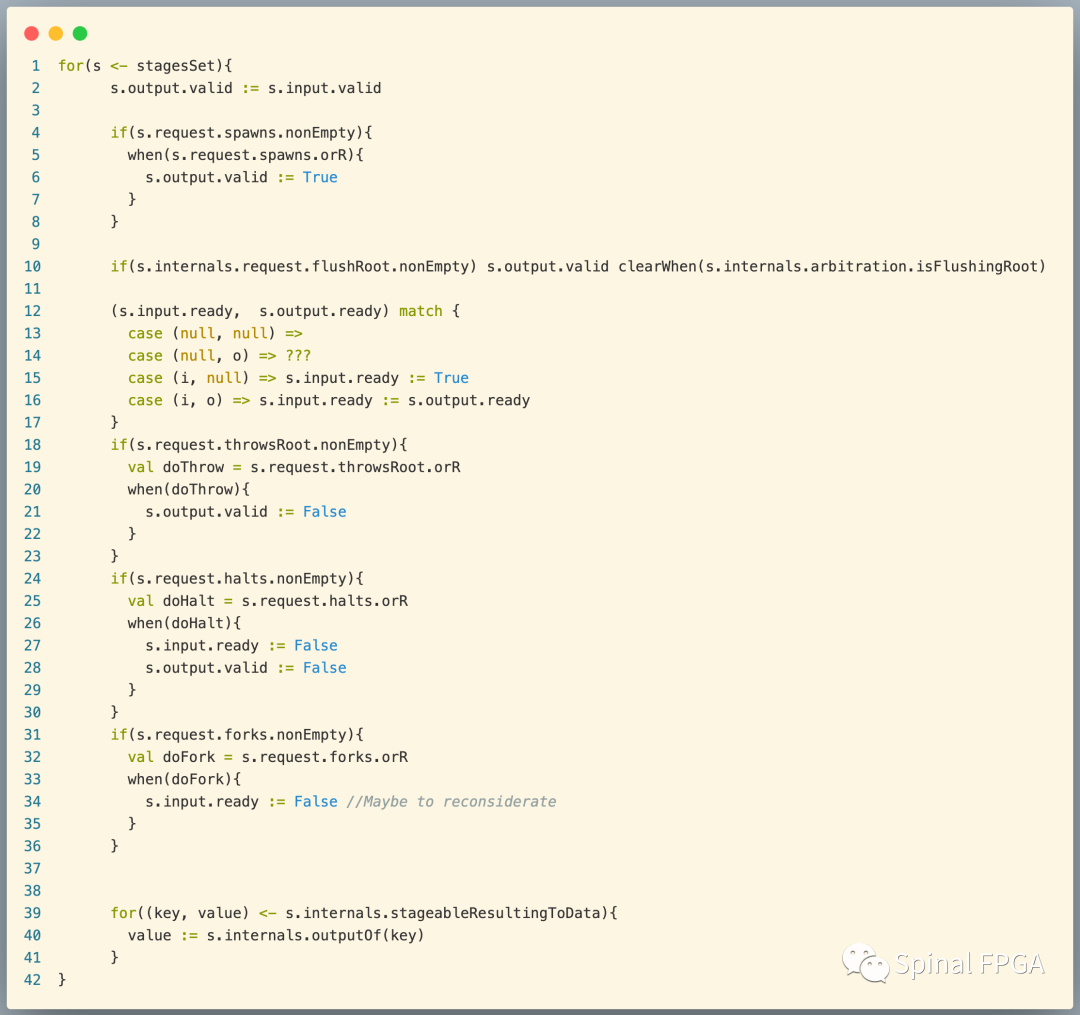
这里我们近会用到s.output.valid:=s.input.valid,即将每个stage中的internal.output.valid由internal.input.valid进行驱动。
剩下的就是stage之间的连接了:
for(c <- connections){
val stageables = (c.m.stageableToData.keys).filter(key => c.s.stageableToData.contains(key) && !c.m.stageableTerminal.contains(key))
var m = ConnectionPoint(c.m.output.valid, c.m.output.ready, stageables.map(c.m.outputOf(_)).toList)
for((l, id) <- c.logics.zipWithIndex){
val s = if(l == c.logics.last)
ConnectionPoint(c.s.input.valid, c.s.input.ready, stageables.map(c.s.stageableToData(_)).toList)
else {
ConnectionPoint(Bool(), (m.ready != null) generate Bool(), stageables.map(_.stageable.craft()).toList)
}
val area = l.on(m, s, clFlush(l), clFlushNext(l), clFlushNextHit(l), clThrowOne(l), clThrowOneHit(l))
if(c.logics.size != 1)
area.setCompositeName(c, s"level_$id", true)
else
area.setCompositeName(c, true)
m = s
}
}
对于每个connection,首先是将master端和slave端stage共有的stageableToData给筛选到stageables中去,这里对应的为:
Connection(m=stage0,s=stage1,logic=M2S): StageableKey(payload,null) Connection(m=stage1,s=stage2,logic=M2S): StageableKey(payload,null)
接着创建ConnectionPoint,对应的paylaod即为StageabelKey所对应的电路对象,也就意味着:
Connection(m=stage0,s=stage1,logic=M2S): m=ConenctionPoint(stage0.out.valid,stage0.out.ready,stage0.stageableToData(StageableKey(payload,null))) s=ConenctionPoint(stage1.in.valid,stage1.in.ready,stage1.stageableToData(StageableKey(payload,null))) Connection(m=stage1,s=stage2,logic=M2S): m=ConenctionPoint(stage1.out.valid,stage1.out.ready,stage1.stageableToData(StageableKey(payload,null))) s=ConenctionPoint(stage2.in.valid,stage2.in.ready,stage2.stageableToData(StageableKey(payload,null)))
最终,调用M2S.on创建stage之间的连接关系:
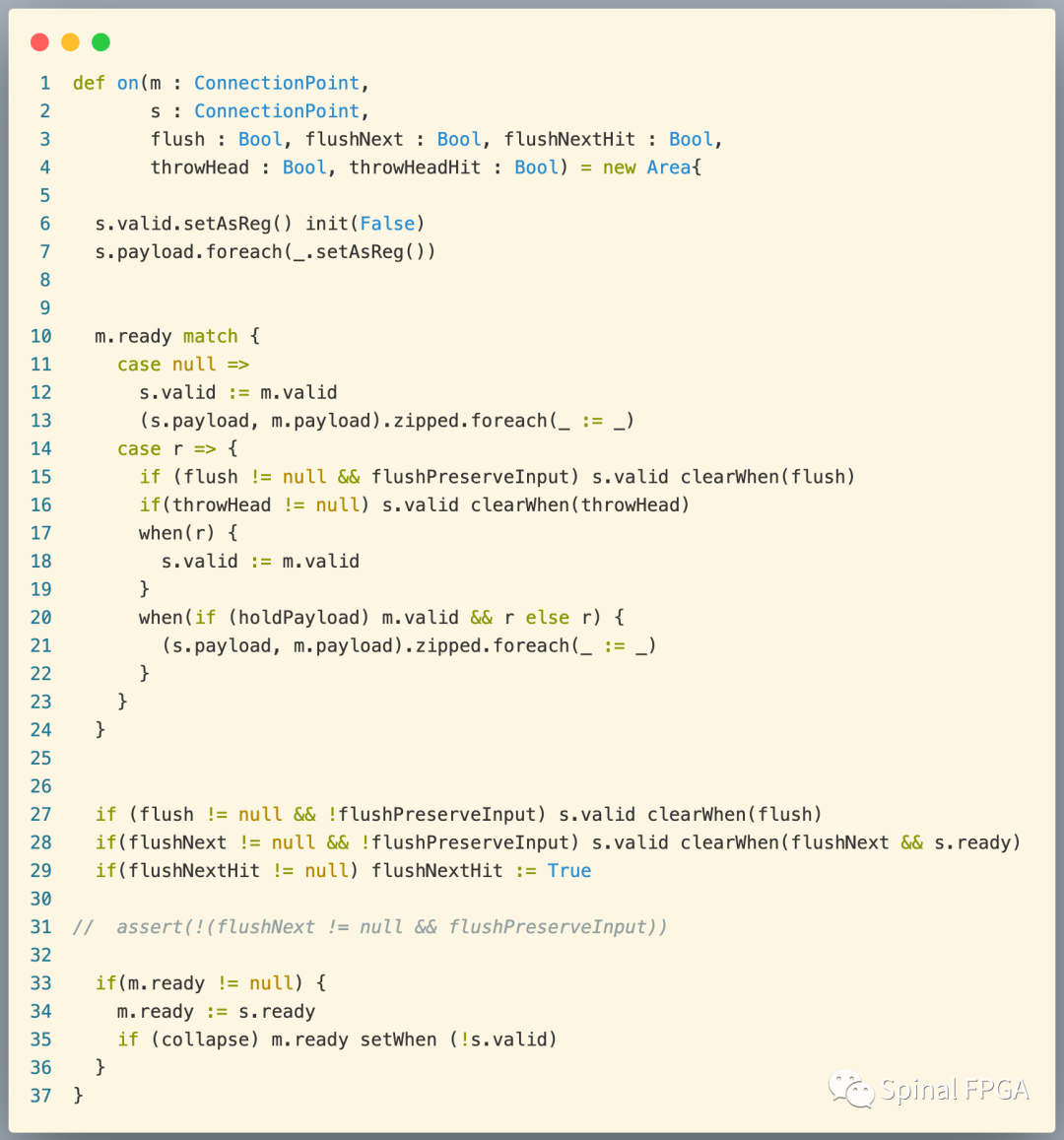
这里我们只用到6~7行,建立起各stage之间的连接关系。
至此!完成整个流水线的创建。
》写在最后
通过本篇,分析了一个简单的流水线在Pipeline中的创建实现,后续将陆续进行更加复杂流水线的Demo及其背后自动实现原理。
审核编辑:刘清
-
如何构建一个简单的对讲电路2022-11-21 3589
-
如何构建一个简单而强大的MP3播放器2023-01-25 7240
-
分享一个51上写的一个简单的操作系统,包含完整全部程序2012-07-15 30404
-
如何构建一个简单的传感器?2023-04-28 506
-
如何构建一个简单的基于红外的车门遥控器2023-04-02 2883
-
构建一个简单的机械臂2023-06-14 1071
-
构建一个简单的提醒报警电路2023-06-18 1942
-
如何构建一个简单的家庭自动化2023-07-05 734
-
什么是pipeline?Go中构建流数据pipeline的技术2024-03-11 2039
-
为THS3001构建一个简单的SPICE模型2024-10-29 459
全部0条评论

快来发表一下你的评论吧 !
