

人工智能套装myCobot 320版视觉算法深度解析
电子说
描述
引言
今天我们将深入了解myCobot 320 AI Kit的机器识别算法是如何实现。
当今社会,随着人工智能技术的不断发展,机械臂的应用越来越广泛。作为一种能够模拟人类手臂动作的机器人,机械臂具有高效、精准、灵活、安全等一系列优点。在工业、物流、医疗、农业等领域,机械臂已经成为了许多自动化生产线和系统中不可或缺的一部分。例如,在工厂生产线上的自动化装配、仓库物流中的货物搬运、医疗手术中的辅助操作、农业生产中的种植和收获等场景中,机械臂都能够发挥出其独特的作用。本文将重点介绍机械臂结合视觉识别技术在myCobot 320 AI Kit场景中的应用,并探讨机械臂视觉控制技术的优势和未来发展趋势。
产品介绍
myCobot 320 M5Stack
myCobot 320是一款面向用户自主编程开发的六轴协作机器人,350MM的运动半径,最高可达1000g的末端负载,0.5MM的重复定位精度;全面开放软件控制接口,多种主流编程语言可以快速上手控制机械臂。

myCobot Adaptive gripper


mycobot自适应夹爪,自适应夹爪是一种机器人末端执行器,用于抓取和搬运各种形状和尺寸的物体。自适应夹爪具有很高的灵活性和适应性,可以根据不同的物体形状和尺寸自动调整其夹紧力度和夹取位置。它可以结合机器视觉,根据视觉算法获取到的信息调夹爪整夹紧力度和夹取位置。该夹爪能够负载抓取1kg的物体,最大的夹距90mm,使用电力驱动的一款夹爪,使用起来相当的方便。
以上就是我们使用到的设,以及后续用到的myCobot 320 AI Kit 。
视觉算法
视觉算法是一种利用计算机图像处理技术来实现对图像和视频进行分析和理解的方法。它主要包括图像预处理、特征提取、目标检测、姿态估计等几个方面。
图像预处理:
图像预处理是对原始图像进行处理,使其更适合后续的分析和处理,常用的算法有图像去噪算法、图像增强算法、图像分割算法。
特征点提取:
特征提取是从图像中提取出关键特征,以便进行进一步的分析和处理,SIFT算法、SURF算法、ORB算法、HOG算法、LBP算法等.
目标检测:
目标检测是在图像中寻找某个特定的物体或目标,常用的算法,有Haar特征分类器、HOG特征+SVM分类器、Faster R-CNN、YOLO
姿态估计:
姿态估计是通过识别物体的位置、角度等信息,来估计物体的姿态,常用的算法有PnP算法、EPnP算法、迭代最近点算法(ICP)等。
举例说明
颜色识别
这样说的太抽象,我们实践操作来演示这个步骤,如何从下面这张图片中检测到白色的高尔夫球。我们使用到的是OpenCV的机器视觉库。

图像处理:
首先我们得对图片进行预处理,方便计算机能够快速的找到目标物体,这一步的操作是将图片转化成灰度图。
灰度图:灰度图是一种将彩色图像转换为黑白图像的方法,它描述了图像中每个像素的亮度或灰度级别。在灰度图中,每个像素的值表示它的亮度,通常在0到255的范围内,其中0表示黑色,255表示白色。中间的值表示不同程度的灰度。
import cv2
import numpy as np
image = cv2.imread('ball.jpg')
# turn to gray pic
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow('gray', gray)

灰度处理后的图片
二值化处理:
我们可以看到图片中的高尔夫球跟背景是有很大的颜色差别的,可以通过颜色检测出目标物体。高尔夫球是白色,但是在光线的作用下,还有一些灰色的阴影部分。所以我们在设置灰度图的像素的时候得考虑进去灰色的部分。
lower_white = np.array([180, 180, 180]) # Lower limit
upper_white = np.array([255, 255, 255]) # Upper limit
# find target object
mask = cv2.inRange(image, lower_white, upper_white)
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
这一个步骤就叫做二值化处理,将目标物体从背景中分离出来.
过滤轮廓:
到二值化处理完后,我们需要设置一个过滤的轮廓面积的大小。如果不设置的话会出现下面图片中的结果,会发现有很多地方都被选中,我们只想要最大的那一个就将小面积的区域给过滤

#filter
min_area = 100
filtered_contours = [cnt for cnt in contours if cv2.contourArea(cnt) > min_area]
#draw border
for cnt in filtered_contours:
x, y, w, h = cv2.boundingRect(cnt)
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 0, 255), 2)

完整代码:
import cv2
import numpy as np
image = cv2.imread('ball.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
lower_white = np.array([170, 170, 170])
upper_white = np.array([255, 255, 255])
mask = cv2.inRange(image, lower_white, upper_white)
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
min_area = 500
filtered_contours = [cnt for cnt in contours if cv2.contourArea(cnt) > min_area]
for cnt in filtered_contours:
x, y, w, h = cv2.boundingRect(cnt)
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 0, 255), 2)
cv2.imshow('Object Detection', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
与之不同的是,我们是想用机械臂来抓取物体,找到检测的目标物体还不够,我们需要获取到目标物体得坐标信息。
为了获取被测目标物体的坐标信息,使用到了OpenCV的Arcuo码,是一种常见的二维码,用于相机标定,姿态估计和相机跟踪等计算机视觉任务。Arcuo码每个都是由唯一的标识符,通过在途中检测和识别这些码,可以推断相机的位置,相机与码之间的关系。


图片中两个唯一的二维码,来固定裁剪图片的大小,固定arcuo码的位置,就能通过计算获取到目标物体 。

这样就能检测出来目标物体所在的位置了,返回x,y坐标给到机械臂的坐标系中,机械臂就可以进行抓取。

具体的代码
# get points of two aruco
def get_calculate_params(self, img):
"""
Get the center coordinates of two ArUco codes in the image
:param img: Image, in color image format.
:return: If two ArUco codes are detected, returns the coordinates of the centers of the two codes; otherwise returns None.
"""
# Convert the image to a gray image
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Detect ArUco marker.
corners, ids, rejectImaPoint = cv2.aruco.detectMarkers(
gray, self.aruco_dict, parameters=self.aruco_params
)
"""
Two Arucos must be present in the picture and in the same order.
There are two Arucos in the Corners, and each aruco contains the pixels of its four corners.
Determine the center of the aruco by the four corners of the aruco.
"""
if len(corners) > 0:
if ids is not None:
if len(corners) <= 1 or ids[0] == 1:
return None
x1 = x2 = y1 = y2 = 0
point_11, point_21, point_31, point_41 = corners[0][0]
x1, y1 = int((point_11[0] + point_21[0] + point_31[0] + point_41[0]) / 4.0), int(
(point_11[1] + point_21[1] + point_31[1] + point_41[1]) / 4.0)
point_1, point_2, point_3, point_4 = corners[1][0]
x2, y2 = int((point_1[0] + point_2[0] + point_3[0] + point_4[0]) / 4.0), int(
(point_1[1] + point_2[1] + point_3[1] + point_4[1]) / 4.0)
return x1, x2, y1, y2
return None
# set camera clipping parameters
def set_cut_params(self, x1, y1, x2, y2):
self.x1 = int(x1)
self.y1 = int(y1)
self.x2 = int(x2)
self.y2 = int(y2)
# set parameters to calculate the coords between cube and mycobot320
def set_params(self, c_x, c_y, ratio):
self.c_x = c_x
self.c_y = c_y
self.ratio = 320.0 / ratio
# calculate the coords between cube and mycobot320
def get_position(self, x, y):
return ((y - self.c_y) * self.ratio + self.camera_x), ((x - self.c_x) * self.ratio + self.camera_y)
YOLOv5识别
YOLO算法区别与OpenCV算法不同的点在于,YOLOv5算法是一种基于深度学习的目标检测算法,与OpenCV的传统计算机视觉方法有所不同。虽然OpenCV也提供了目标检测功能,但它主要基于传统的图像处理和计算机视觉技术。Yolov5则是一种基于神经网络的深度学习模型,通过训练神经网络来实现目标检测。
神经网络就像是一个人的大脑一样,外界不停的给他传输知识,让他去学习,告诉他这个是苹果,这个是草莓。通过不断地训练学习,给不同地苹果地图片,草莓地图片给它认识。之后他就在能一张图片里面精准地找到苹果,草莓。

Code
# detect object
def post_process(self, input_image):
class_ids = []
confidences = []
boxes = []
blob = cv2.dnn.blobFromImage(input_image, 1 / 255, (self.INPUT_HEIGHT, self.INPUT_WIDTH), [0, 0, 0], 1,
crop=False)
# Sets the input to the network.
self.net.setInput(blob)
# Run the forward pass to get output of the output layers.
outputs = self.net.forward(self.net.getUnconnectedOutLayersNames())
rows = outputs[0].shape[1]
image_height, image_width = input_image.shape[:2]
x_factor = image_width / self.INPUT_WIDTH
y_factor = image_height / self.INPUT_HEIGHT
cx = 0
cy = 0
try:
for r in range(rows):
row = outputs[0][0][r]
confidence = row[4]
if confidence > self.CONFIDENCE_THRESHOLD:
classes_scores = row[5:]
class_id = np.argmax(classes_scores)
if (classes_scores[class_id] > self.SCORE_THRESHOLD):
confidences.append(confidence)
class_ids.append(class_id)
cx, cy, w, h = row[0], row[1], row[2], row[3]
left = int((cx - w / 2) * x_factor)
top = int((cy - h / 2) * y_factor)
width = int(w * x_factor)
height = int(h * y_factor)
box = np.array([left, top, width, height])
boxes.append(box)
'''Non-maximum suppression to obtain a standard box'''
indices = cv2.dnn.NMSBoxes(boxes, confidences, self.CONFIDENCE_THRESHOLD, self.NMS_THRESHOLD)
for i in indices:
box = boxes[i]
left = box[0]
top = box[1]
width = box[2]
height = box[3]
cv2.rectangle(input_image, (left, top), (left + width, top + height), self.BLUE,
3 * self.THICKNESS)
cx = left + (width) // 2
cy = top + (height) // 2
cv2.circle(input_image, (cx, cy), 5, self.BLUE, 10)
label = "{}:{:.2f}".format(self.classes[class_ids[i]], confidences[i])
# draw real_sx, real_sy, detect.color)
self.draw_label(input_image, label, left, top)
# cv2.imshow("nput_frame",input_image)
# return input_image
except Exception as e:
print(e)
exit(0)
if cx + cy > 0:
return cx, cy, input_image
else:
return None

YOLO开发者提供了开源代码在GitHub上,如果有特殊地需求,可以自行设置训练的方式,达到效果。
除此之外,还有形状识别,特征点识别,二维码识别,形状识别等这些功能都集合在myCobot 320 AI Kit 当中。
myCobot 320 AI Kit
这是一个适配机械臂myCobot320的人工智能套装,将上述视觉算法跟机械臂相结合的一个应用场景。myCobot 320 机械臂末端搭配着自适应夹爪和吸泵,对物体进行抓取/吸取。
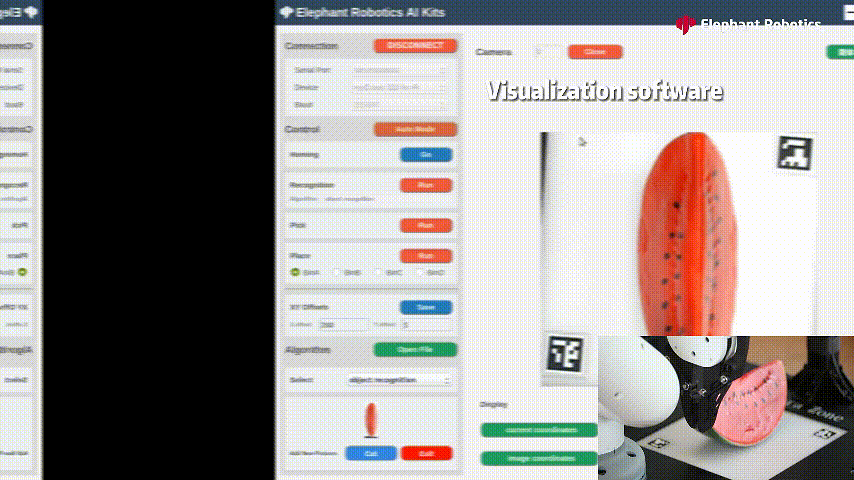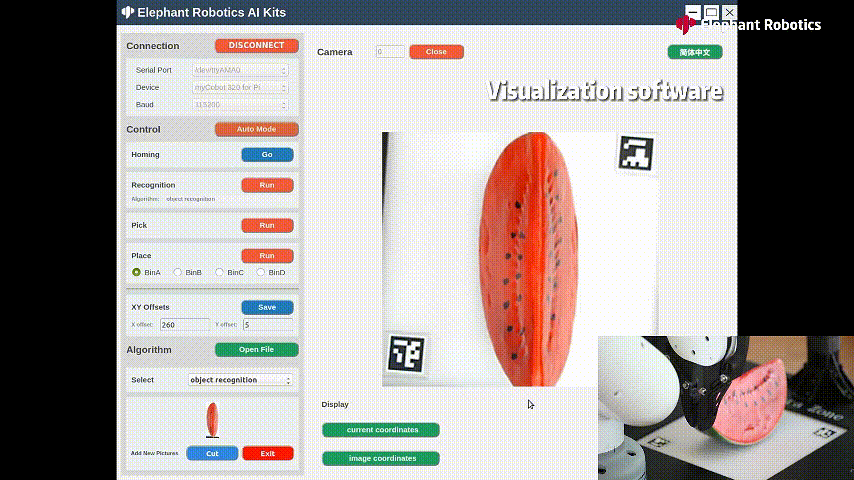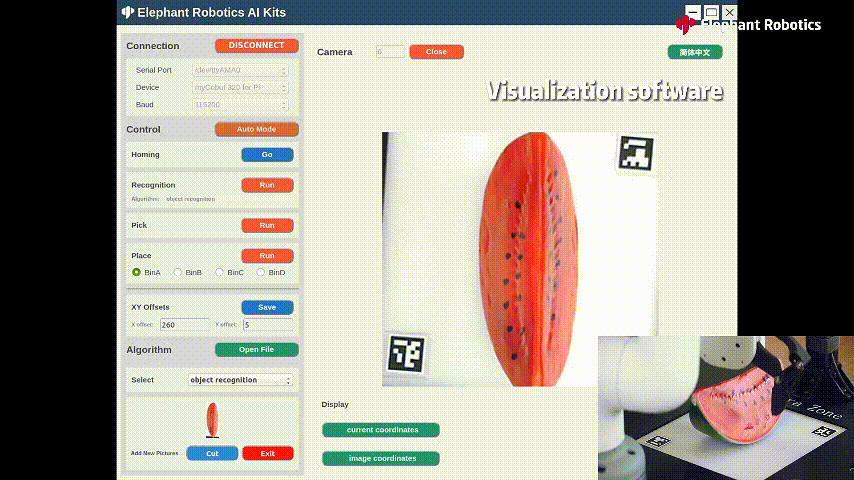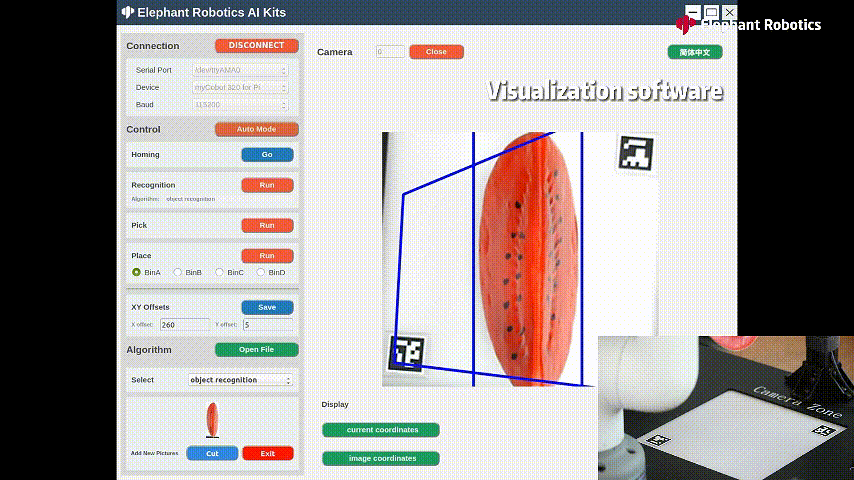
识别西瓜进行抓取

颜色木块的识别,用吸泵进行吸取
这是一套非常适合刚入门学习人工智能,计算机视觉算法识别,机械臂原理的套装。这个套装是开源的,提供全部的代码以供学习。
gif的python动图
如果你想要了解更多关于myCobot 320 AI Kit 的介绍,操作的使用,这边给你提供之前发布过的一篇AI Kit 320的介绍。
总结
如果你有更好的想法关于人工智能套装,你完全可以自己打造一个属于自己机械臂的应用场景,以AI Kit 为基础大胆的展示你的想法。
机械臂视觉控制技术是一种应用广泛、发展迅速的技术。相比传统的机械臂控制技术,机械臂视觉控制技术具有高效、精准、灵活等优势,可以在工业生产、制造、物流等领域得到广泛应用。随着人工智能、机器学习等技术的不断发展,机械臂视觉控制技术将会有更广泛的应用场景。在未来的发展中,需要加强技术研发和创新,不断提高技术水平和应用能力。
审核编辑 黄宇
-
挖到宝了!人工智能综合实验箱,高校新工科的宝藏神器2025-08-07 4315
-
myCobot 320 人工智能套装2023版震撼上市!突破工作半径和负载限制,全新夹爪抓取方式!2023-06-15 1772
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 2417
-
什么是人工智能、机器学习、深度学习和自然语言处理?2022-03-22 4733
-
人工智能对汽车芯片设计的影响是什么2021-12-17 2251
-
人工智能基本概念机器学习算法2021-09-06 2813
-
人工智能芯片是人工智能发展的2021-07-27 6756
-
人工智能AI-深度学习C#&LabVIEW视觉控制演示效果2020-11-27 3195
-
【HarmonyOS HiSpark IPC DIY Camera试用 】青少年人工智能教育套装之一2020-10-29 1410
-
人工智能:超越炒作2019-05-29 5076
-
人工智能技术及算法设计指南2019-02-12 5211
-
百度深度学习研究院科学家深度讲解人工智能2018-07-19 16757
-
深度解析行业场景中的人工智能应用2018-05-28 5091
-
分享:人工智能算法将带领机器人走向何方?2017-08-16 6114
全部0条评论

快来发表一下你的评论吧 !
