

CMU&MIT最新开源!超强通用视觉位置识别!
描述
0. 笔者个人体会
这项工作可以简称为"识别一切"!。看到官方demo的一瞬间,真的是感觉很惊叹。
视觉位置识别的工作有很多,本质上都可以归类为构建图像数据库+查询图像检索的过程。现在的主要问题是,很多识别算法都是针对特定环境进行的,换一个环境很可能直接就挂掉了。
那么,一个真正通用的位置识别算法,应该做到什么呢?
答案就是三个关键词:任何地点(无缝地运行在任何环境中,包括空中、地下和水下),任何时间(对场景中的时间变化,如昼夜或季节变化,或对临时物体具有鲁棒性),以及跨任何视角(对视角变化具有鲁棒性,包括完全相反的视角)。也就是说,在任何地点、任何时间、任何视角下都可以鲁棒得进行位置识别。这个任务想想就非常难!
但是最近有一个团队就推出了这样的工作,也就是CMU、IIIT Hyderabad、MIT、AIML联合开源的AnyLoc,性能非常的鲁棒,并且实验做得很详细。今天笔者就将带领读者一起欣赏一下这一力作,当然笔者水平有限,如果有理解不当的地方欢迎大家一起交流。限于篇幅,对本文的的深入思考与理解,我们发表在了「3D视觉从入门到精通」知识星球。
注:本文使用VPR做为视觉位置识别的简称(Visual Place Recognition)。
1. 效果展示
先来看一个最基础的任务,就是根据查询图像进行位置识别。这也是官方主页上提供的交互式demo,直接点击左侧Query图像上的任一点,就可以在右侧识别出选择的位置。感兴趣的小伙伴可以去官方主页上进行尝试!这里也推荐「3D视觉工坊」新课程《面向自动驾驶领域目标检测中的视觉Transformer》。
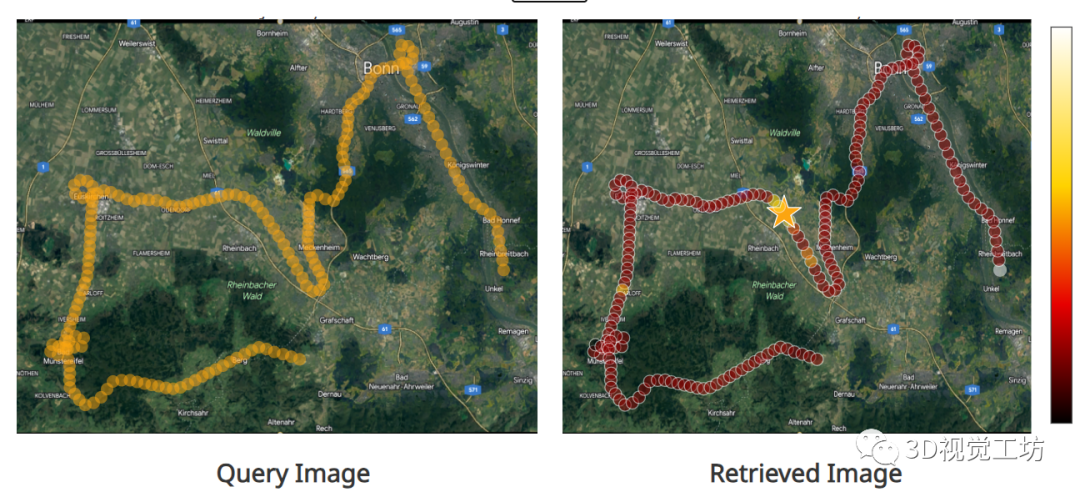
就像论文中提到的那样,AnyLoc在任何地点、任何时间、任何视角都可以进行位置识别。最关键的是,在各种结构化、非结构化、光照变化等挑战性场景中都可以进行准确识别!
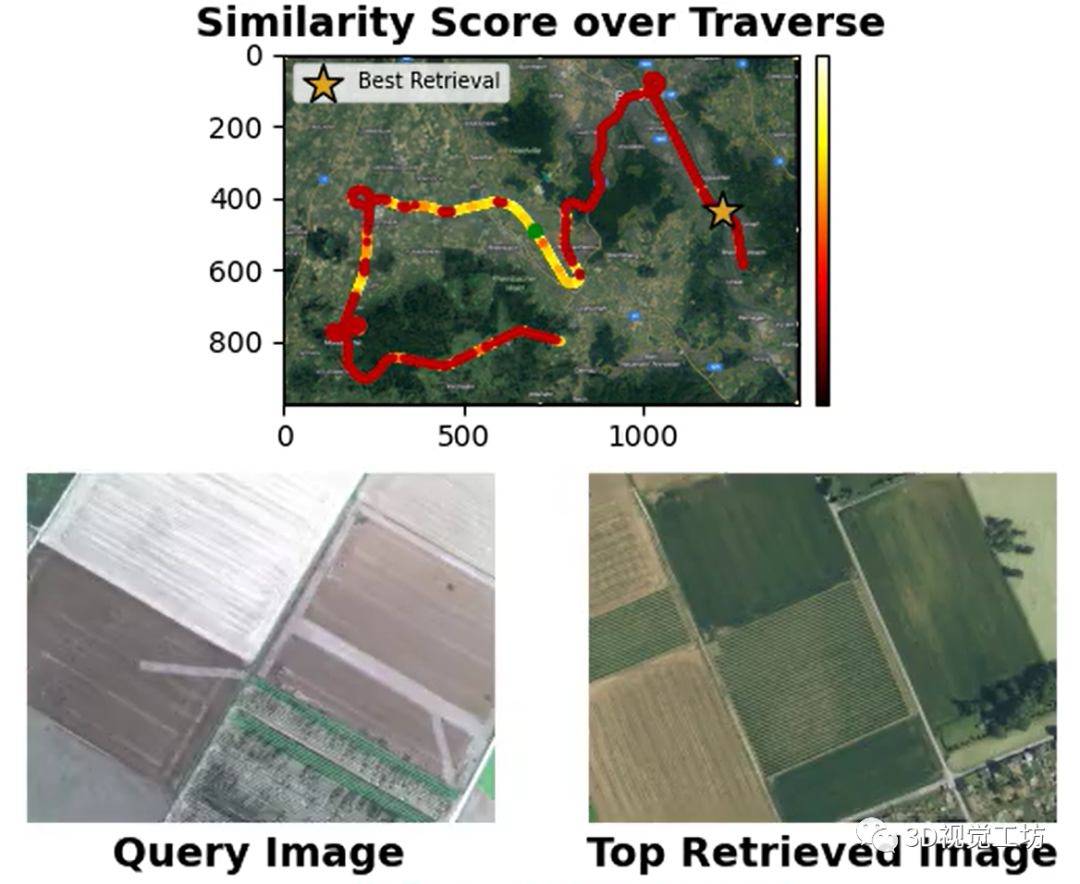
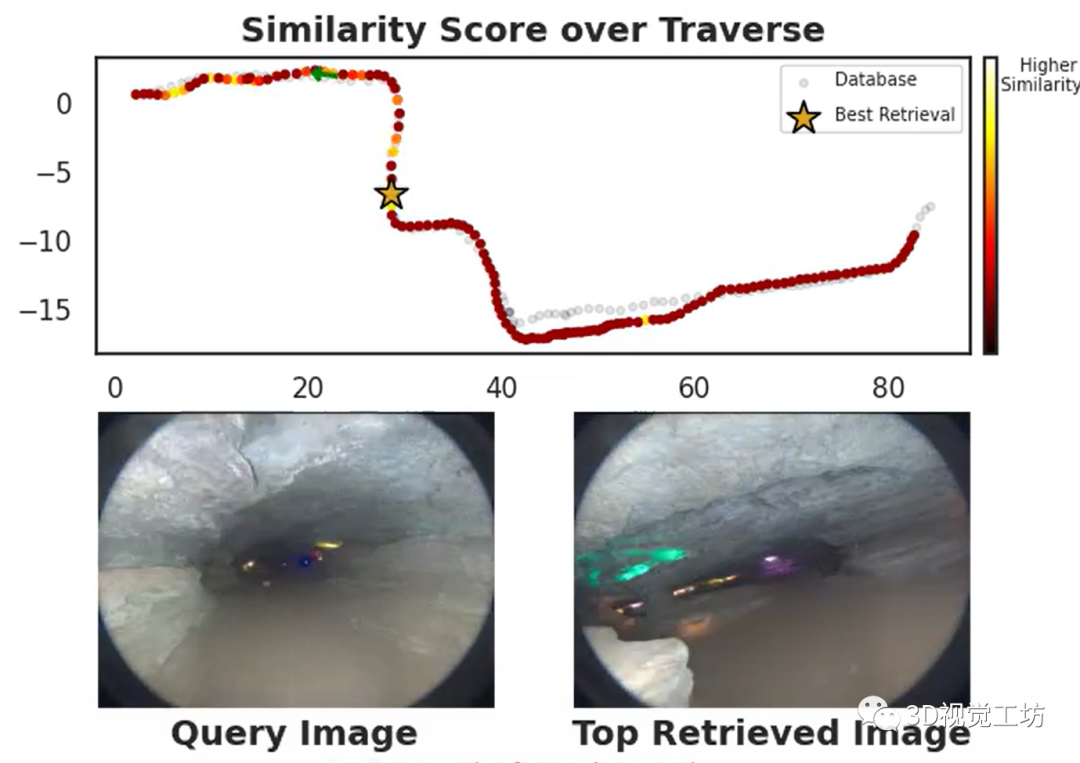
AnyLoc在室内室外、结构化非结构化、光照视角变化等挑战性场景中的性能都远远超过了同类算法,简直是"八边形战士"!
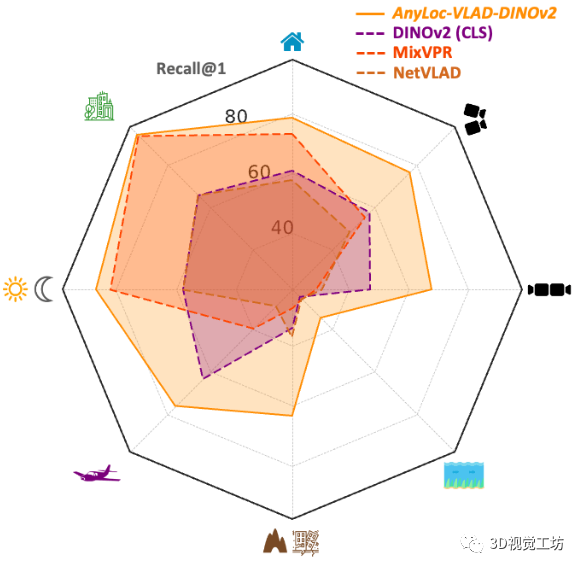
总之,算法已经开源了,官方主页上也提供了很多的demo。感兴趣的小伙伴赶快去试试吧,下面来看一下具体的论文信息。
3. 摘要
视觉位置识别( Visual Place Recognition,VPR )对机器人定位至关重要。迄今为止,性能最高的VPR方法都是针对环境和任务的:尽管它们在结构化环境(以城市驾驶为主)中表现出强劲的性能,但它们在非结构化环境中的性能严重下降,这使得大多数方法在实际部署中表现不佳。在这项工作中,我们开发了一个通用的VPR解决方案------一种跨越广泛的结构化和非结构化环境(城市、室外、室内、空中、水下和地下环境)的技术,无需任何重新训练或微调。我们证明,从没有VPR特定训练的现成的自监督模型中得到的通用特征表示是构建这种通用VPR解决方案的正确基础。将这些派生特征与无监督的特征聚合相结合,使得我们的方法AnyLoc能够获得比现有方法高达4倍的性能。通过表征这些特征的语义属性,我们进一步获得了6 %的性能提升,揭示了封装来自相似环境的数据集的独特领域。我们详细的实验和分析为构建可以在任何地方、任何时间、任何视角部署的VPR解决方案奠定了基础。我们鼓励读者浏览我们的项目页面和互动演示。
4. 算法解析
本质上来说,VPR可以被定义为一个图像检索问题。机器人首先穿越环境采集图像,建立图像数据库,然后在后续的运行时提供查询图像,在参考数据库中检索与该图像最接近的匹配。但是具体的实现方式就多种多样了,大家可能更熟悉的是描述子方法,包括局部描述子还有全局描述子。
但想要达到最优性能,一般还是要针对特定环境进行大规模训练。只是这种高性能带来的是低泛化性,在自动驾驶场景中训练的模型,几乎不可能泛化到室内场景和非结构化场景中。
这篇文章的亮点就在于,分析了VPR的任务无关的ViT特征提取和融合,并开发了一个通用的解决方案,不需要任何针对特定VPR任务的训练!作者发现,来自现成基础模型的逐像素特征表现出显著的视觉和语义一致性,虽然用于通用VPR时,每个图像的特性都不是最佳的,但是可以将这些逐像素不变性转移到图像级别以识别地点。
那么,要选择何种基础模型呢?
想要提取任务无关的视觉特征,这样的自监督基础模型有三大类:
(1)联合嵌入方法(DINO、DINOv2);
(2)对比学习方法(CLIP);
(3)基于掩码的自编码方法(MAE)。
作者经过实验,发现联合嵌入学习模型可以更好得捕获长范围的全局信息,因此AnyLoc使用DINO和DIONv2 ViT模型来提取视觉特征。
另一个问题来了,要从这些预训练的ViT中提取什么视觉特征呢?
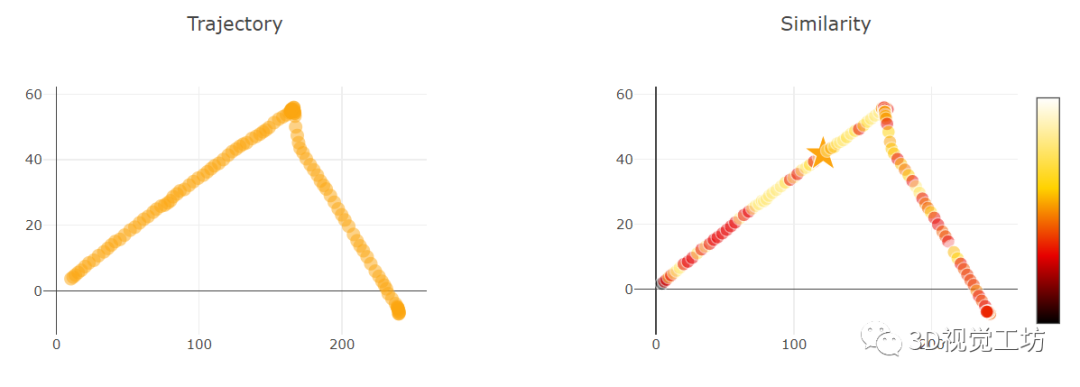
与提取单幅图像特征(图像特征向量)相比,提取逐像素特征可以实现更细粒度的匹配。而ViT的每一层都有多个特征(Query、Key、Value、Token)。因此,作者尝试从中间层提取特征,而不使用CLS Token。具体来说,就是从数据库图像中选择一个点,将其与来自查询图像的所有像素特征进行匹配,并绘制热力图。
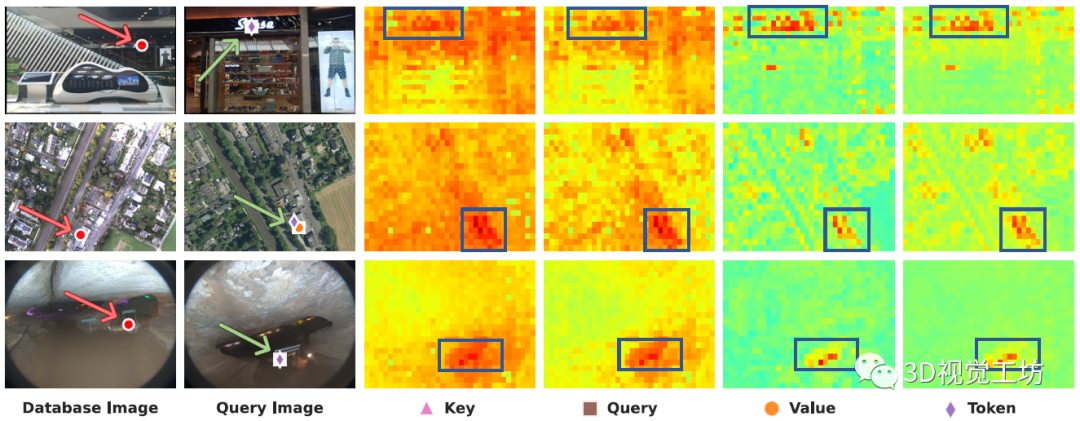
有什么发现呢?
首先,即使存在语义文本和尺度变化(第一行)、感知混淆和视点偏移(第二行)、低光照结合相反视角(第三行),这些匹配关系也是鲁棒的。
最关键的来了。注意如何在匹配点和背景之间表现出最大的对比度,这对于抵抗图像中干扰物的鲁棒性至关重要。
通过进一步的跨层分析,可以发现一个很有意思的现象。ViT的较早层(顶行),特别是Key和Query,表现出很高的位置编码偏差,而第31层(更深的层)的Value在相似度图中的反差最大。
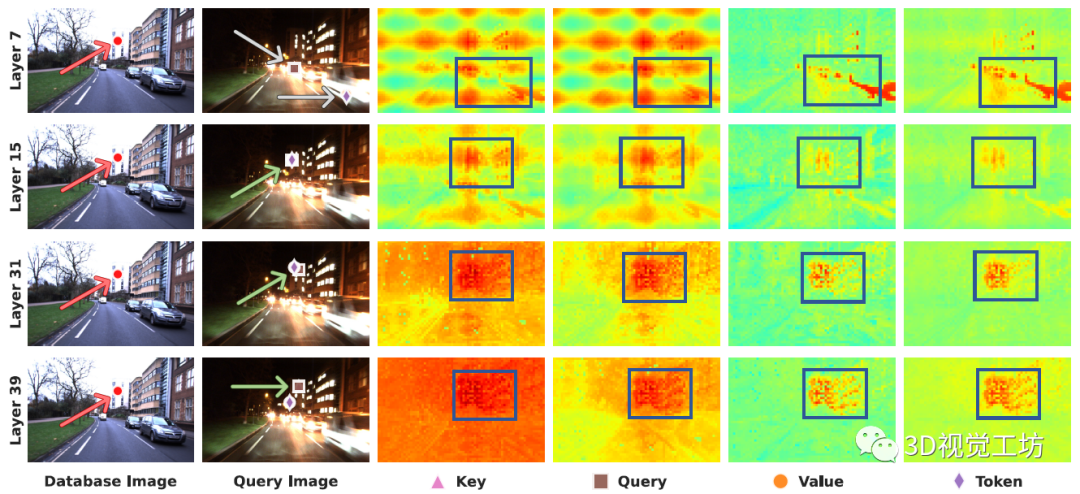
因此,作者选择Layer 31和Value做为局部特征表征。
特征提取完了,下面该聊聚合了。
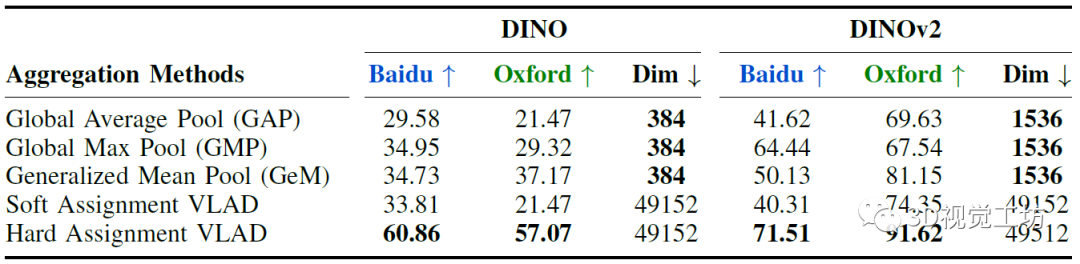
也就是如何将局部特征组合在一起以描述图像的各个部分,并最终描述一个环境。作者全面探索了多种无监督聚合技术:全局平均池化(GAP)、全局最大池化(GMP)、广义平均池化(GeM)以及VLAD的软硬对齐变体。最终选择了内部归一化、级联、间归一化来获取最终的VLAD描述子。
最后,构建词袋模型。
这一部分的目的是在不同的环境中,表征全局聚合的局部特征的独特语义属性。先前基于VLAD的工作虽然在城市场景中表现良好,但是并不适合基础模型特征编码中的开放集语义属性。因此,作者通过对GeM描述子进行表征来指导VLAD的词袋选择。这里也有个trick。就是使用PCA投影全局描述子可以在潜在空间发现不同的域,并且表征相似属性(Urban,Indoor,Air,SubT,Degrad和Underwater)。而且可以观察到查询图像的投影特征与各自数据库图像的投影特征接近,因此,最终VLAD的词袋构建是基于PCA分离进行的。
5. 实验
AnyLoc的实验可谓无限创造困难,提供了前所未有的环境多样性(任何地方),加上一系列时间(任何时候)和相机视点(任何视图)的变化。其中结构化环境使用了6个基准的室内和室外数据集,包含剧烈的视点偏移、感知混叠和显著的视觉外观变化。非结构化环境使用空中、水下、地下场景,包含各种视觉退化、卫星图像、低光照以及季节变化。
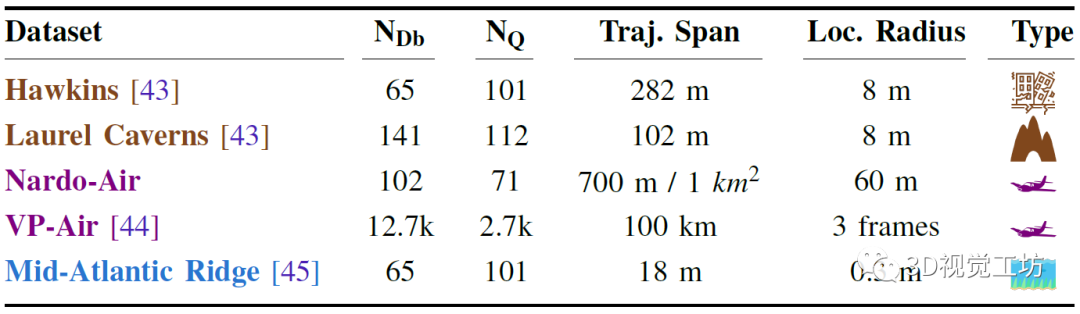
评估指标主要使用Recall,实验都在3090上进行。对比方案也都是SOTA方案,包含在大规模城市数据集上为VPR任务训练的3个特定baseline,以及使用基础模型CLS Token的3个新baseline。
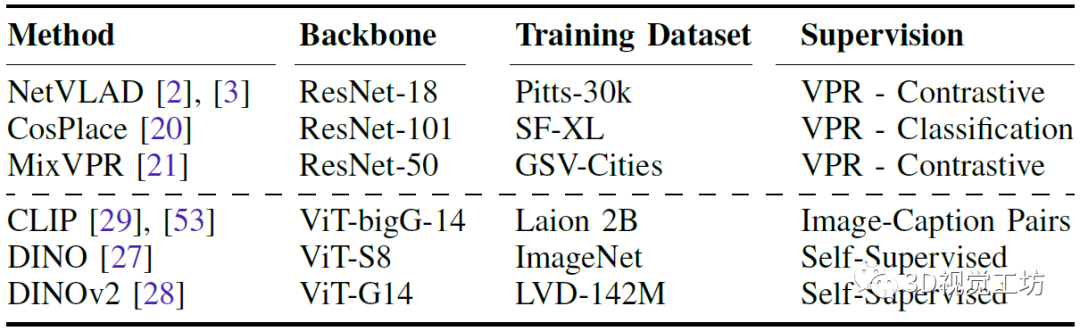
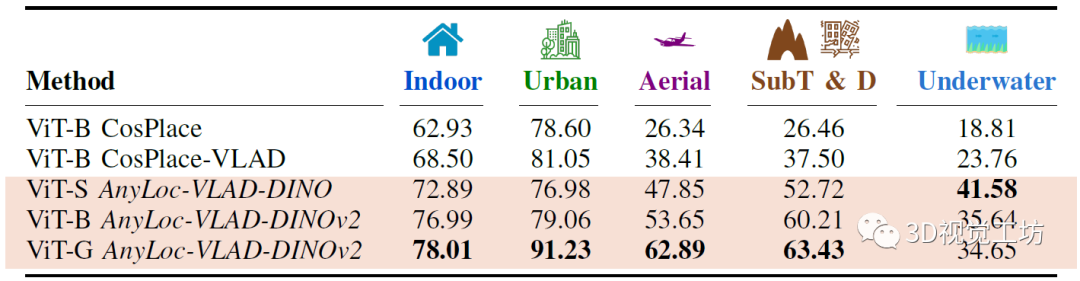
首先对比AnyLoc在结构、非结构环境、视点偏移、时间外观变化上对比其他SOTA VPR方案的结果。AnyLoc-VLAD-DINOv2在所有的室内数据集上都取得了最高的召回率,室外环境稍差,但在Oxford数据集上效果尤其的好。而且比较有意思的是,在DINOv2上简单地使用GeM池化就可以显著提高性能。
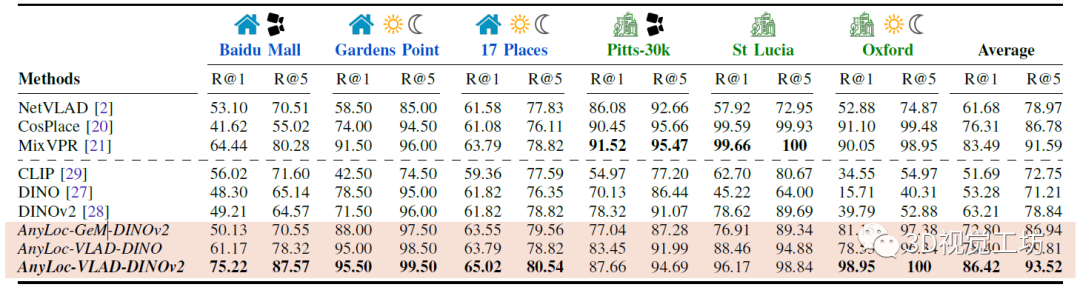
在非结构化环境中,AnyLoc很大程度上优于所有baseline,尤其是对于时间和视角变化。而聚合方法也很明显优于CLS方法。另一方面,NetVLAD、CosPlace和MixVPR这三个特定baseline也证实了随着城市训练数据规模的增加,在特定任务上回表现得更好。
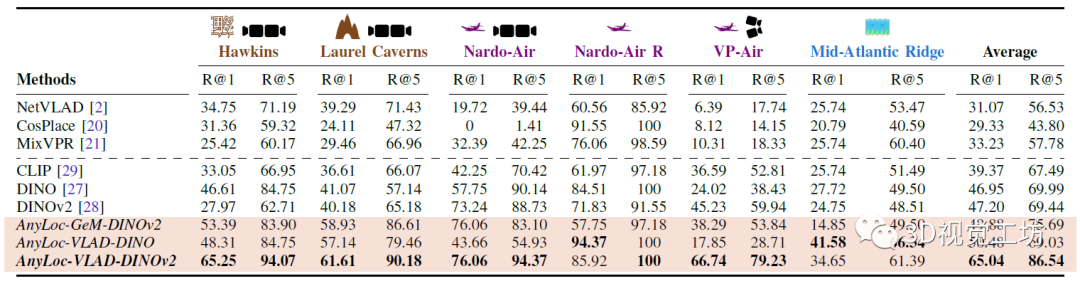
之后,对AnyLoc的设计进行词袋分析,特定领域的词袋可以带来最优性能。
下面来展示特定领域词袋的鲁棒域内一致性,具体做法是使用领域特定的词汇对局部特征的聚类赋值进行可视化。在Urban域中,道路、路面、建筑物和植被在不断变化的条件和地点被一致地分配到同一个簇中。对于室内域,可以观察到地板和天花板的域内一致性,以及文字标志和家具的域内一致性。对于航空领域,可以观察到道路、植被和建筑物在农村和城市图像中都被分配到独特的簇中。

进一步可以证明,这种域内的鲁棒一致性能够在缺乏信息丰富度的小型参考数据库的目标环境中部署AnyLoc-VLAD。对于属于给定领域的数据集,选择最大的参考数据库来形成词袋,并在来自该领域的其他数据集上进行评估。对于航拍和城市领域,可以观察到,当使用更大的词袋来源时,与仅仅使用较小的地图相比,可以实现7-18 %更高的召回率,从而证明了词袋在同一领域内的可迁移性。
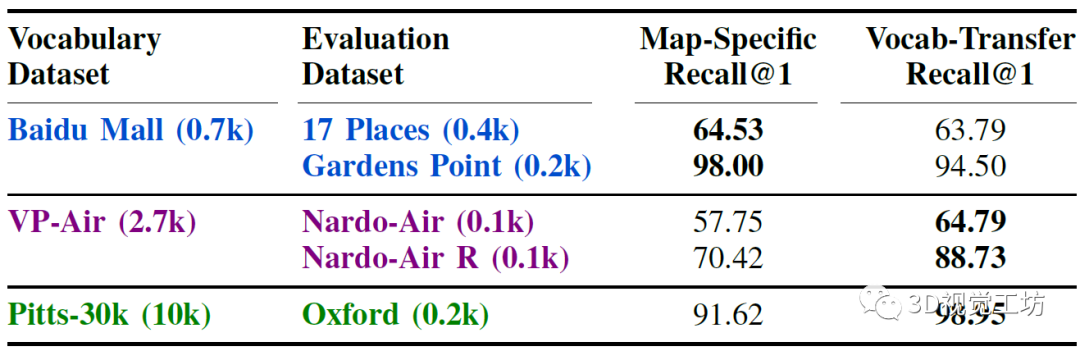
作者还对比了不同的ViT架构、选择的Layer以及不同的Facet对性能的影响。

还详细对比了各种无监督局部特征聚合方法对性能的影响,显示GeM聚合性能更优。有一点需要注意,就是硬分配比软分配要快1.4倍。
最后,还将专门面向VPR(CosPlace)训练的ViT与基于自监督(DINO、DINOv2)的ViT进行比较。举个例子,对比基于ViT-B的方法,即使CosPlace系的整体性能有所改善,但AnyLoc-VLAD-DINOv2仍然比VLAD提高了8-13 %。这里也推荐「3D视觉工坊」新课程《面向自动驾驶领域目标检测中的视觉Transformer》。
6. 总结
非常有意思的工作!
站在上帝视角来看,会觉得AnyLoc的思想很简单,就是使用任务无关的基础ViT模型来提取逐像素特征,然后进行特征聚合。但其实整个分析问题,解决问题的思路非常巧妙。尤其是AnyLoc的结果很棒,将机器人定位扩展到任何地点、任何时间、任何视角下,这对于机器人下游任务至关重要。
另一方面,模型大一统真的是一个大趋势,不停的出现一个大模型实现这个领域内的所有功能。那么,下一个"一切"是什么呢?让我们拭目以待。
-
【KV260视觉入门套件试用体验】六、VITis AI车牌检测&车牌识别2023-09-26 9436
-
CMU200手机专用测试仪表2009-02-09 1054
-
R&S/CMU300特价清销CMU300基站综测仪CMU3002017-10-09 1225
-
基于CNN的恶意软件加密C&C通信流量识别方法2021-06-11 1120
-
【新品发布】教育领域新成果,P &T AI计算机视觉开发套件2021-11-05 3398
-
HUATOOP HT9530识别&修复小记2021-12-02 1951
-
存储类&作用域&生命周期&链接属性2021-12-09 894
-
2021 Kubernetes on AI & Edge Day圆满举行 共探边缘云融合2021-12-16 6252
-
如何区分Java中的&和&&2023-02-24 3569
-
if(a==1 && a==2 && a==3),为true,你敢信?2023-05-08 2408
-
HarmonyOS &润和HiSpark 实战开发,“码”上评选活动,邀您来赛!!!2022-04-11 2127
-
摄像机&雷达对车辆驾驶的辅助2022-11-26 2124
-
FS201资料(pcb & DEMO & 原理图)2024-07-16 534
-
onsemi LV/MV MOSFET 产品介绍 & 行业应用2024-10-13 1729
-
视觉传感器 | 这些常见的Q&A!今天统一回答!2024-11-05 1370
全部0条评论

快来发表一下你的评论吧 !
