

如何实现自定义的应用层协议呢?
描述
简述
互联网上充斥着各种各样的网络服务,在对外提供网络服务时,服务端和客户端需要遵循同一套数据通讯协议,才能正常的进行通讯;就好像你跟台湾人沟通用闽南语,跟广东人沟通就用粤语一样。
实现自己的应用功能时,已知的知名协议(http,smtp,ftp等)在安全性、可扩展性等方面不能满足需求,从而需要设计并实现自己的应用层协议。
2.协议分类
2.1按编码方式
二进制协议比如网络通信运输层中的tcp协议。
明文的文本协议比如应用层的http、redis协议。
混合协议(二进制+明文)比如苹果公司早期的APNs推送协议。
2.2按协议边界
固定边界协议能够明确得知一个协议报文的长度,这样的协议易于解析,比如tcp协议。
模糊边界协议无法明确得知一个协议报文的长度,这样的协议解析较为复杂,通常需要通过某些特定的字节来界定报文是否结束,比如http协议。
3.协议优劣的基本评判标准
高效的快速的打包解包减少对cpu的占用,高数据压缩率降低对网络带宽的占用。
简单的易于人的理解、程序的解析。
易于扩展的对可预知的变更,有足够的弹性用于扩展。
容易兼容的
向前兼容,对于旧协议发出的报文,能使用新协议进行解析,只是新协议支持的新功能不能使用。
向后兼容,对于新协议发出的报文,能使用旧协议进行解析,只是新协议支持的新功能不能使用。
4.自定义应用层协议的优缺点
4.1优点
非知名协议,数据通信更安全,黑客如果要分析协议的漏洞就必须先破译你的通讯协议。
扩展性更好,可以根据业务需求和发展扩展自己的协议,而已知的知名协议不好扩展。
4.2缺点
设计难度高,协议需要易扩展,最好能向后向前兼容。
实现繁琐,需要自己实现序列化和反序列化。
5.动手前的预备知识
5.1大小端
计算机系统在存储数据时起始地址是高地址还是低地址。
大端从高地址开始存储。
小端从低地址开始存储。
图解
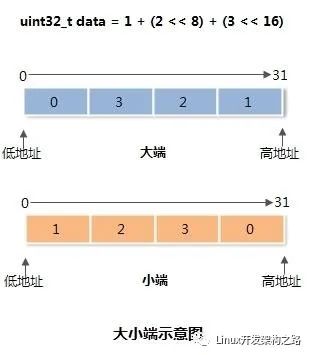
判断这里以c/c++语言代码为例,使用了c语言中联合体的特性。

5.2网络字节序
顾名思义就是数据在网络传送的字节流中的起始地址的高低,为了避免在网络通信中引入其他复杂性,网络字节序统一是大端的。
5.3本地字节序
本地操作系统的大小端,不同操作系统可能采用不同的字节序。
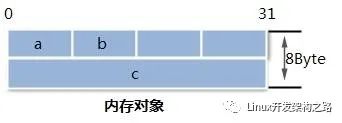
5.4内存对象与布局
任何变量,不管是堆变量还是栈变量都对应着操作系统中的一块内存,由于内存对齐的要求程序中的变量并不是紧凑存储的,例如一个c语言的结构体Test在内存中的布局可能如下图所示。

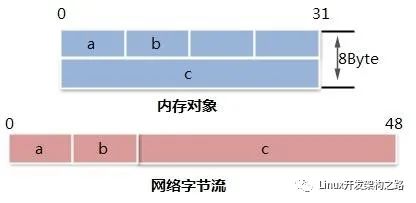
5.5序列化与反序列化
将计算机语言中的内存对象转换为网络字节流,例如把c语言中的结构体Test转化成uint8_t data[6]字节流。
将网络字节流转换为计算机语言中的内存对象,例如把uint8_t data[6]字节流转化成c语言中的结构体Test。
6.一个例子
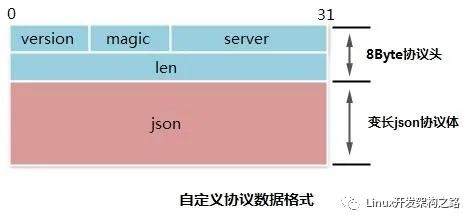
6.1 协议设计
本协议采用固定边界+混合编码策略。
协议头8字节的定长协议头。支持版本号,基于魔数的快速校验,不同服务的复用。定长协议头使协议易于解析且高效。
协议体变长json作为协议体。json使用明文文本编码,可读性强、易于扩展、前后兼容、通用的编解码算法。json协议体为协议提供了良好的扩展性和兼容性。
协议可视化图
6.2 协议实现
talk is easy,just code it,使用c/c++语言来实现。
6.2.1c/c++语言实现
使用结构体MyProtoHead来存储协议头


6.2.2打包(序列化)

6.2.3解包(反序列化)




7.完整源码与测试
code is easy,just run it.
7.1源码








7.2运行测试
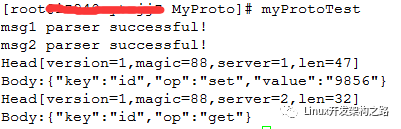
8.总结
不到350行的代码向我们展示了一个自定义的应用层协议该如何实现,当然这个协议是不够完善的,还可以对其完善,比如对协议体进行加密加强协议的安全性等。
审核编辑:刘清
-
自定义视图组件教程案例2022-04-08 1057
-
HarmonyOS应用自定义键盘解决方案2025-06-05 2857
-
何进行串口通信自定义协议,真心求教2016-09-23 4388
-
基于自定义协议的网络地理信息系统2009-04-18 1091
-
1602自定义字符2016-01-20 1014
-
如何在LabVIEW中实现自定义控件2021-01-14 2208
-
单片机学习笔记————51单片机实现常用的自定义串口通讯协议2021-11-23 1302
-
C#与STM32自定义通信协议2021-12-24 1793
-
基于HAL库的USB自定义HID设备实现2021-12-28 1313
-
深入理解RPC自定义网络协议2022-06-12 3763
-
ArkUI如何自定义弹窗(eTS)2022-08-31 4235
-
ESP32上的自定义UART协议开源2023-02-13 1432
-
自定义算子开发2022-04-07 5839
-
labview超快自定义控件制作和普通自定义控件制作2023-08-21 1170
-
TSMaster 自定义 LIN 调度表编程指导2024-05-11 3071
全部0条评论

快来发表一下你的评论吧 !
