

雷达点云动态目标分割算法研究分析
军用/航空电子
描述
作者:泡椒味的口香糖
0. 笔者个人体会
视觉也好,激光也好,如何剔除动态物体的影响都是一个很麻烦的课题。一方面要检测动态物体,另一方面要建立去除干扰的静态环境地图。现有的动态物体剔除的工作其实有很多了,但是都有一个问题:如何解决分割的假阳性和假阴性。其实这也是CV很经典的问题"如何信任深度学习的结果"。
今天给大家介绍的这篇工作就解决了这个问题,来源于2023 IROS,它将当前帧的Lidar扫描和局部地图都输入到网络中,以此来修正历史帧的漏检和误检。
这篇文章其实和之前2021 RAL/IROS"Moving Object Segmentation in 3D LiDAR Data: A Learning-based Approach Exploiting Sequential Data"的工作有点相似,陈谢沅澧也是两篇文章的共同作者,感兴趣的小伙伴可以追一下陈博的Github(https://github.com/Chen-Xieyuanli)。
注:本文使用MOS作为Moving Object Segmentation的简称。
1. 效果展示
算法将雷达点云做为输入,可以直接判定点是否属于动态物体。还能构建Volumetric Belief地图(可以理解为存储每个点是否动态的概率),构建完地图以后可以直接对点进行查询。但笔者觉得最重要的一点是,它可以修正历史帧的假阳性和假阴性判据,这一点是很多算法没有涉及的。
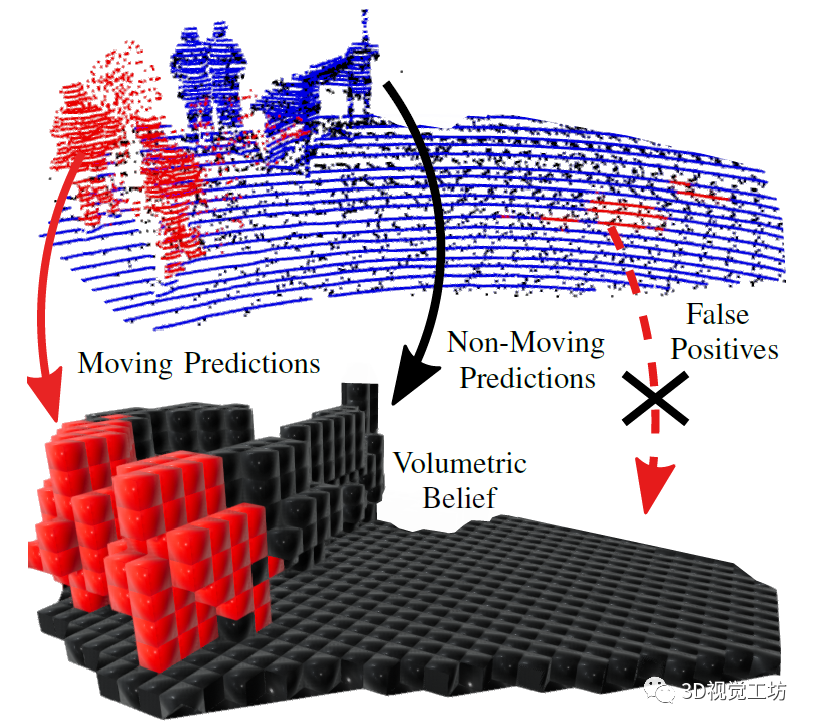
再来看一看动态环境下建图的结果,实心圆表示地图中动态物体的残留痕迹,虚线圆表示由于假阳性预测而被4DMOS移除的静态区域。整体来看,建立的动态环境地图还是很干净的。

算法已经开源了,感兴趣的小伙伴可以去试试,下面来看具体的论文信息。
2. 摘要
在未知环境中导航的移动机器人需要时刻感知周围环境中的动态物体,以便进行建图、定位和规划。对当前观测中的运动物体进行推理,同时对静态世界的内部模型进行更新以确保安全是关键。在本文中,我们解决了在当前3D LiDAR扫描和环境局部地图中联合估计运动物体的问题。我们使用稀疏的4D卷积从扫描和局部地图中提取时空特征,并将所有3D点分割为移动和非移动点。此外,我们提出使用贝叶斯滤波器将这些预测融合在动态环境的概率表示中。这种Volumetric Belief模型表示环境中的哪些部分可以被运动对象所占据。我们的实验表明,我们的方法优于现有的运动目标分割基线,甚至可以推广到不同类型的LiDAR传感器。我们证明了在在线建图场景中,我们的Volumetric Belief融合可以提高运动目标分割的精度和召回率,甚至可以检索到先前丢失的运动目标。
3. 算法解析
算法的整体目标是识别当前Lidar扫描和局部地图中的动态物体,并融合生成一个概率 Volumetric Belief图。
Lidar点云过来以后,首先使用KISS-ICP(参考https://github.com/PRBonn/kiss-icp)进行注册,并对点云进行体素化,之后再进行分割。Scan2Map的输入为当前帧Lidar扫描和局部地图(居然不需要位姿)点云的4D信息(位置+时间戳),使用4D卷积网络MinkUNet进行动态目标预测,最后将预测结果融合到Volumetric Belief图中。其使用的分割思想有两个:
(1)动态物体的Lidar扫描和局部地图有差异;
(2)动态物体上点云的时间戳的变化和静态点不同;
引入时间信息有啥好处呢?
由于遮挡、有限FoV等因素,动态目标在短时间内很有可能是有遮挡的,如果使用固定长度的滑窗就没办法处理!而且这里还使用了一个trick,就是对序列的时间戳进行归一化处理,避免训练时对序列长度过拟合!
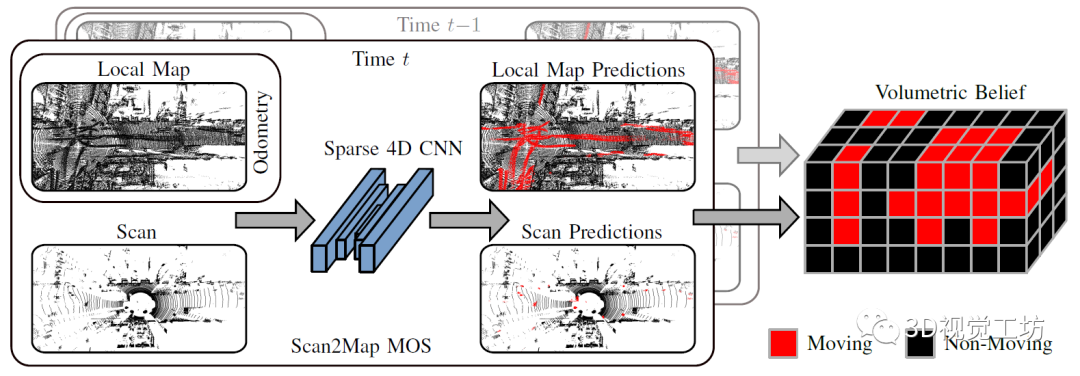
那为啥还要输入局部地图信息,而不仅仅是当前的Lidar扫描呢?
这里主要是考虑到分割的假阴性和假阳性问题。如果之前帧没有成功识别动态物体,那么还可以通过局部地图来回溯错误。
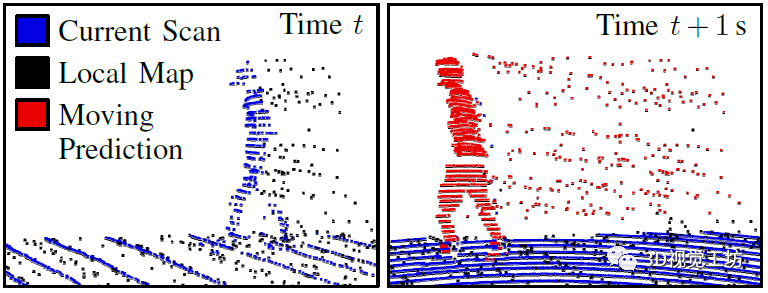
最后Volumetric Belief就是一个将多个独立预测随时间进行融合的过程。需要特别注意的是,这个Volumetric Belief存储的并不是每个点的预测,而是环境中哪部分有更高的概率包含动态对象。也就是说,不仅仅是要识别当前点是否为动态对象,还要确定地图的哪一部分被动态对象经过了(Dynamic Occupancy)。举个例子,就是如果一个点落入了动态体素中,那么就假设这个点也属于动态物体,如果一个体素被静态点占据,那么也就不再期望在这个体素中观察到动态物体。Volumetric Belief建立完成以后,也就可以根据概率查询其中哪个点是动态点。
4. 实验
作者所做的实验,其实是围绕四个点来进行:
(1) 基于过去观测的局部地图,将输入的LiDAR扫描精确地分割成动态和非动态的物体;
(2) 在实现最新性能的同时,很好地推广到新的环境和传感器设置;
(3) 通过将多个预测融合到Volumetric Belief中,提高MOS的精度和召回率;
(4) 通过Volumetric Belief从错误的预测中恢复到在线建图。
就数据集来说,作者除了在Semantic KITTI和Semantic KITTI MOS(参考https://codalab.lisn.upsaclay.fr/competitions/7088)这两个动态数据集上进行实验,还标注了KITTI Tracking、Apollo Columbia Park MapData、nuScenes这三个数据集中的子序列。评估指标就是分割任务常用的IoU。
先看一下在Semantic KITTI和Semantic KITTI MOS上的运动物体分割结果,分别对比了只是用当前帧(Scan)以及带有10帧的局部地图(Volumetric Belief)。验证集效果很好,但是测试集提升其实不太明显。效果比4DMOS好也就证明了使用时间信息对MOS是有利的。这里LMNet就是陈博之前的工作,RVMOS性能好是因为使用了额外的标签训练。
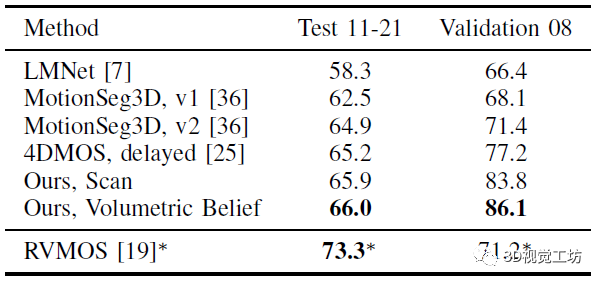
泛化性实验很有价值,主要还是因为MOS是有监督任务,并且标注成本极高(也推荐一个半监督点云分割框架https://ldkong.com/LaserMix)。LMNet和MotionSeg3D性能很差,是因为对Lidar安装位置和点云强度过拟合了。而4DMOS和作者的方法只是用时间信息,因此可以适应新的Lidar内参标定。
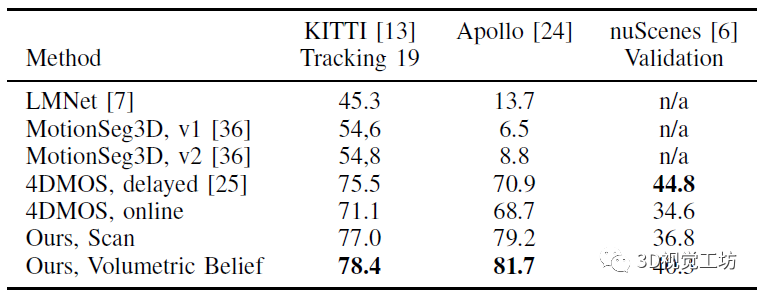
最后一个实验证明的是Volumetric Belief的具体设置如何提升IoU、召回和精度。表中的No Delay代表局部地图的点为动态点(主要还是做一个运行时间的平衡)。结果表明,Volumetric Belief可以在先验地图中排除假阳性,虽然有时精度和召回略低,但是IoU提升很明显。

5. 总结
跟动态视觉SLAM不同,动态雷达SLAM还是有很多可研究的点,但主要思想还是利用动态物体上scan和scan、scan和map之间的矛盾。可以直接利用这种矛盾做几何一致性判据,也可以输入到网络里进行训练。从这个角度出发,读者也可以构思新的判别方式,设计自己的动态点云检测算法。
IROS的文章都很精简,很多信息没办法从论文中获取,还是得死磕代码来解决问题。所以对论文细节感兴趣的小伙伴不妨阅读一下代码。
编辑:黄飞
-
基于深度学习的点云分割的方法介绍2023-07-20 819
-
点云分割相较图像分割的优势是啥?2022-12-14 4086
-
自动驾驶 | MINet:嵌入式平台上的实时Lidar点云数据分割算法2022-01-26 757
-
基于三维激光点云的目标识别与跟踪研究2022-01-17 1294
-
激光雷达点云数据分割算法的嵌入式平台上的部署实现2021-12-21 2624
-
求一种采用空间投影的点云分割方法2021-06-26 2627
-
基于激光雷达点云的三维目标检测算法2021-05-08 2096
-
基于深度学习的三维点云语义分割研究分析2021-04-01 1536
-
基于目标分层和路径分割的区域覆盖算法TLPS2021-03-17 1174
-
图像分割算法的深入研究2018-12-20 1501
-
基于多传感器的多模型机动目标跟踪算法设计2018-12-05 3213
-
雷达目标检测算法研究及优化2018-02-28 5427
-
激光雷达距离像背景抑制算法研究2009-08-08 3770
全部0条评论

快来发表一下你的评论吧 !
