

生成式AI正在偷走你的数据?
人工智能
描述
1.大模型时代,数据安全的新挑战
数据,是AI发展的养料。人们在轻而易举获取数据的同时,对数据安全的讨论也此起彼伏。
2013年,线上辞典Dictionary.com将“Privacy(隐私)”选为当年的年度词汇。彼时美国政府棱镜计划被曝光、谷歌修改隐私协议以整合旗下各服务用户数据,个人隐私成为数据安全中关注度最高、涉及人群最广的方面。
相较于互联网对用户上网习惯、消费记录等信息的覆盖,人脸识别、智能设备、AI换脸等AI应用的出现,对用户个人信息的采集范围大幅扩大,包括人脸、指纹、声纹、虹膜、心跳、基因等强个人属性的生物特征信息。
2017年,中国第一例利用AI侵犯公民个人信息案犯罪在浙江绍兴破获,其中超10亿条公民个人信息被非法获取。
360集团首席安全官杜跃进此前接受「甲子光年」采访时就曾表示:“人工智能和大数据的安全必须放在一起看。”
生成式AI、大模型的出现,对数据提出了前所未有的要求,也随之带来了更加突出的数据安全问题。
在大模型的训练数据量上,以OpenAI的GPT模型为例:GPT-1预训练数据量仅为5GB;到了GPT-2,数据量已经增加至40GB;而GPT-3的数据量已经直接飞升至45TB(相当于GPT-2数据量的1152倍)。
市场逐渐凝成这样的共识:得数据者得天下,数据是大模型竞争的关键。
顶象安全专家告诉「甲子光年」:“模型需要数据来训练。数据除了自己采集,就是爬虫爬取。爬取的数据大部分没有经过数据所有者允许,可以说大部分是非授权的盗用。”
2022年11月,OpenAI和GitHub一起推出的代码助手Copilot就曾被程序员们告上法庭。原告们认为,Copilot在未获得GitHub用户授权的情况下,使用了公共存储库进行训练。
在今年6月,OpenAI同样因为未经允许使用个人隐私数据收到了一份长达157页的诉讼书。
除了模型的训练阶段,在模型的实际应用阶段中,个人隐私泄露的风险持续存在。
顶象安全专家告诉「甲子光年」,生成式AI不仅仅泄露人的隐私和秘密,甚至会让人变得透明。“就跟《三体》中的智子一样,提问者说的话会被记录下来,生产生活产生的数据信息会成为AIGC训练的素材。”
早在2020年,人们就发现OpenAI的GPT-2会透露训练数据中的个人信息。随后的调查发现,语言模型越大,隐私信息泄露的概率也越高。
今年3月,多名ChatGPT用户在自己的历史对话中看到了他人的对话记录,包括用户姓名、电子邮件地址、付款地址、信用卡号后四位以及信用卡有效期。
不到一个月之后,三星电子就因员工使用ChatGPT,被迫面临三起数据泄露事故:其半导体设备测量、良品/缺陷率、内部会议内容等相关信息被上传到了ChatGPT的服务器中。随后,三星立即禁止员工在公司设备及内网上使用类ChatGPT的聊天机器人,同样禁用的公司还包括苹果、亚马逊、高盛等世界500强公司。
观韬中茂律师事务所发布的《生成式AI发展与监管白皮书(三)》解释了大模型在应用上的特殊性。大模型与人之间的交互,不同于一般应用程序中填入式的收集个人信息方式,所以对于个人信息的披露也不同于往常意义上的“公开披露”,更类似于一种“被动公开”,即当某个用户的真实个人信息被摘录在语料库后,之后任意用户通过询问等方式均可以得知相关个人信息。
这意味着,在大模型时代,不仅个人信息泄露的范围扩大了,个人信息的采集过程也变得更为隐秘,难以辨认,而且一旦侵权,就是对大量用户造成的侵权。那么,泄露之后的个人信息去向了哪里?究竟会对用户造成什么影响?
北京植德律师事务所合伙人王艺告诉了「甲子光年」答案。他表示,生成式AI造成的个人信息泄露,轻则可能侵害他人的肖像权,为造谣者实施便利,重则可能被犯罪分子利用,实施犯罪。
顶象的安全专家也表示,在所有互联网产品或软件都有可能被植入AI元素的当下,AI滥用带来的社会问题会越来越多。“造假会更简单,眼见不一定为实,电信诈骗、网络诈骗越来越复杂。”
2023年5月,安全技术公司迈克菲对来自七个国家的7054人进行了调查,发现有四分之一的成年人经历过某种形式的AI语音诈骗(10%发生在自己身上,15%发生在他们认识的人身上),10%的受害者因此造成经济损失。
「甲子光年」从慧科数据库、公开报道中发现,今年以来全国各地发现利用AI技术窃取个人隐私进行诈骗的案例至少有14例。
其中,大多数案例通过视频聊天与受害者进行联系,逼真的人脸和声音容易让人们放下警惕,冒充朋友、亲人也迅速让受害者交与信任。诈骗金额多在万元以上,最高被诈骗金额甚至高达430万元。
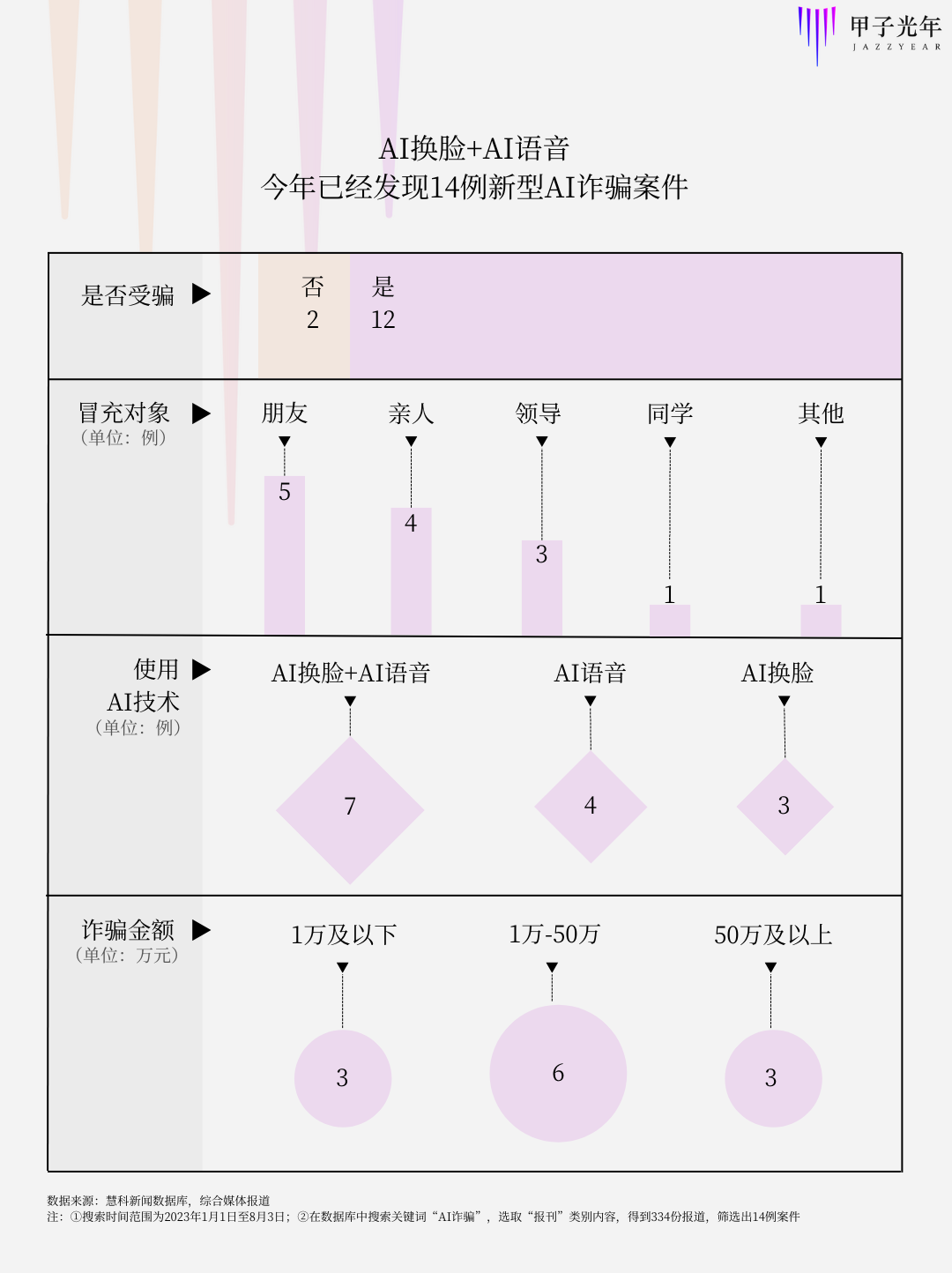
数据来源:慧科新闻数据库,综合媒体报道
除此之外,通过“AI换脸”造成肖像权被侵犯的案件也屡见不鲜。王艺表示,虽然此类案件的数量在逐步上升,但由于隐蔽性强,且是微型侵权,很多案例都没有走上法庭,即使进行了法院审判,得到的赔偿金额也并不高。
可以说,普通人在面对利用AI技术进行的个人隐私侵权面前,其实并没有太多的办法。
2.严苛的立法态度不是监管的唯一解法
技术发展与法律监管总是并驾齐驱的。如果说数据安全已经成为人工智能时代的必答题,法律与监管便是解答的关键。
今年4月,斯坦福大学以人为本人工智能研究所(Stanford HAI)发布了《2023年人工智能指数报告》(Artificial Intelligence Index Report 2023)报告。通过对127个国家的立法记录调研,报告显示,包含“人工智能”法案通过的数量,从2016年的1个增长到2022年的37个。在对81个国家涉及人工智能的议会记录进行分析后,研究人员发现全球立法程序中提及人工智能的次数自2016年以来增加了近6.5倍。
区别于信息剽窃、隐私侵犯等“老生常谈”的数据安全问题,由于涉及到人与AI的交互,大模型时代数据安全面临着更为迫切的难题——个人信息权利响应难以落实。
如何精准识别交互过程中收集的个人信息?如何划清用户服务与模型训练的使用界限?面对全新的数据安全、个人信息安全、网络安全难题,大模型时代亟须新的监管办法出台。
在监管和发展平衡中,此次条例的修改不无道理。因为立法监管并非是一蹴而就的,过于严苛的立法态度可能会成为技术发展的掣肘。在欧洲,部分技术从业者就该问题表达了担忧。
ChatGPT推出后,欧洲国家对OpenAI的监管逐步加紧。意大利宣布禁用ChatGPT后,出于数据保护的考虑,德国、法国、西班牙等国家也表示正在考虑对AI聊天机器人采取更严格的监管。
6月14日,欧盟通过的《人工智能法案》最新草案,也贯彻了以往严苛的立法态度。法案对于“基础模型”或经过大量数据训练的强大AI系统,明确规定了透明度和风险评估要求,包括在AI技术投入日常使用之前进行风险评估等。
对风险的猜想是否高于实际?欧盟严苛的立法态度招致了欧洲风投公司和科技公司的许多不满。
6月30日,欧洲各地的主要科技公司创始人、首席执行官、风险投资家等150家企业高管共同签署了一封致欧盟委员会的公开信,警告欧盟法律草案中对人工智能的过度监管。
“想要将生成式人工智能的监管纳入法律并以严格的合规逻辑进行,这种方法是官僚主义的,因为它无法有效地实现其目的。在我们对真正的风险、商业模式或生成人工智能的应用知之甚少的情况下,欧洲法律应该仅限于以基于风险的方法阐述广泛的原则。”公开信中指出,该立法草案将危及欧洲的竞争力和技术主权,而无法有效解决我们现在和未来可能要面临的挑战。
无独有偶,日本一名官员此前也表示,日本更倾向于采用比欧盟更宽松的规则来管理AI,因为日本希望利用该技术促进经济增长,并使其成为先进芯片的领导者。
“一项新技术从研发到进入市场,再到融入社会生产、生活,产生风险是难以避免的,不能因为风险而放弃新技术的研发和应用。理想目标应是把风险最小化,把技术获利最大化。”顶象的安全专家告诉「甲子光年」。
上述受访者继续说道,欧盟在规范AI问题上下手早,但其过度监管也限制了相关市场的发展,造成欧盟数字产业的发展速度落后于全球。在全球技术主权激烈竞争的背景下,立法与监管政策需要保持谨慎思考,在治理与发展之间做好平衡,在方便企业抵御AI伦理风险的同时,为企业、行业以及相关产业提供充分的发展空间。
“不发展是最大的不安全。”严苛的立法态度不是监管政策的唯一解法,企业和立法者也不应该是矛盾双方,而是谋求数据安全与技术发展的同路人。
以美国为例,谷歌、微软、OpenAI等科技巨头也在主动构建安全屏障。7月21日,谷歌、微软、OpenAI、Meta在内的7家AI公司参与白宫峰会,并就AI技术和研发的安全、透明、风险等问题作出“八大承诺”。7月26日,微软、谷歌、OpenAI、Anthropic四家AI科技巨头宣布成立行业组织——“前沿模型论坛”(Frontier Model Forum),来确保前沿AI开发的安全和负责。
面对尚未确定的技术生态,技术开发者、服务提供者都面临着潜在的合规风险。只有明确了合法获取的路径和规章底线,大模型训练者、服务提供者才能放下戒备,在更大的空间施展拳脚。
站在技术变革的十字路口,如何平衡好数据安全与技术发展的需求,制定出更为系统、更具针对性的监管细则,也是对各国立法者的新考验。
3.在创新与安全之间,如何平衡?
“监管,如果不向前迈进,就会面临人工智能被滥用的风险;如果仓促行事,就有导致行业陷入困境的危机。”
7月25日,Anthropic联合创始人兼CEO Dario Amodei、加州大学伯克利分校教授Stuart Russell和蒙特利尔大学教授Yoshua Bengio出席美国参议院司法委员会举行的人工智能听证会。在会议上,他们一致达成这样的观点:AI需要监管,但过犹不及。
面对大模型对隐私数据的挑战,在创新与安全的博弈之间,我们还有哪些解法?
加强数据安全保护可能是最容易想到的答案。360集团首席安全官杜跃进此前接受「甲子光年」采访时曾表示:“数据安全不应该关注采集了什么,而应该关注采集的数据是怎么用的,怎么保护的。”
隐私计算成为近些年数据隐私保护的技术最优解。与传统的加密技术相比,隐私计算可以在不泄露原始数据的前提下对数据进行分析计算,实现数据的共享、互通、计算和建模。
让数据变得“可用不可见”,也就规避了个人数据泄露或不当使用的风险。这项技术目前已经在医疗、金融、政府等对数据高度敏感的领域内相继落地。
在大模型时代,隐私计算也同样适用。中国信通院云计算与大数据研究所副主任闫树在7月的两次活动上都表达了这样的观点,隐私计算可以满足大模型预测阶段的隐私保护需求。
具体来说,隐私计算的不同路线,包括可信执行环境(TEE) 、多方安全计算(MPC)等都可以与大模型进行结合,“比如在云端部署TEE ,用户在推理时将输入数据加密传输至云端,在其内部解密然后进行推理;还有在模型推理阶段使用多方安全计算来提升隐私保护能力”。但值得注意的是,隐私计算也不可避免会对模型训练和推理的性能造成影响。
除了加强数据安全保护之外,还有一种可以从数据源头上解决隐私安全问题的方法——合成数据。
合成数据指通过AI技术和算法模型,基于真实数据样本生成虚拟数据,因此也不存在用户的个人隐私信息。
随着大模型的火热,合成数据也越来越受到关注,保护隐私就是合成数据研究背后强有力的驱动力之一。
“合成数据解决了三个挑战——质量、数量和隐私。”合成数据平台Synthesis AI的创始人兼CEO Yashar Behzadi接受科技媒体《VentureBeat》采访时表示:“通过使用合成数据,公司可以明确定义所需要的训练数据集,可以在最大程度上减少数据偏差并确保包容性,不会侵犯用户的隐私。”
OpenAI联合创始人兼CEO Sam Altman同样也看好合成数据。
根据英国《金融时报》报道,5月在伦敦举行的一次活动上,Sam Altman被问及是否担心监管部门对ChatGPT潜在隐私侵犯的调查,他并没有特别在意,而是认为“非常有信心所有的数据很快会成为合成数据”。
在合成数据方面,微软在今年更是动作频频。5月,微软在论文《TinyStories: How Small Can Language Models Be and Still Speak Coherent English?》中描述了一个由GPT-4生成的短篇小说合成数据集TinyStories,其中只包含了四岁儿童可以理解的单词,用它来训练简单的大语言模型,也能够生成出流畅且语法正确的故事。
6月,微软在发布的论文《Textbooks Are All You Need》中论证,AI可以使用合成的Python代码进行训练,并且这些代码在编程任务上表现得相当不错。
在AI的圈子内,通过合成数据进行大模型的训练早已见怪不怪。全球IT研究与咨询机构Gartner预测,2030年,合成数据的体量将远超真实数据,成为AI研究的主要数据来源。
在技术之外,数据市场也在渐渐明朗。北京植德律师事务所合伙人王艺向「甲子光年」介绍,目前已经有数据交易所建立了语料库专区,并为相关语料数据产品挂牌(包括文本、音频、图像等多模态,覆盖金融、交通运输和医疗等领域),方便技术提供者和服务提供者合作采购。
在王艺看来,大模型数据的合法合规,需要生成式AI服务提供者首先做好数据分类分级,区分不同数据类型,如个人数据、商业数据、重要数据等,并根据这些不同数据的使用方式,找到对应的法律,分别开展数据来源合法性的审查工作。
而在监管方面,为了平衡好数据安全和AI的发展,王艺表示,对AI的监管需要有主次之分:重点在应用层的监管,尤其是内容监管和个人信息安全;其次是基础层和模型层的监管,对于相关深度合成算法要督促其及时完成备案;再次是要关注技术本身的主体是否涉及境外,可能会存在数据出境、出口管制等问题。
每一次技术产生变革的时期,期待和恐惧总是如影随形,发展和监管的呼声向来不相上下。
目前大模型的发展还在早期,应用层的爆发尚未实现,但AI不会停下脚步,如何把控前行的方向,如何平衡安全与创新,或许是AI发展历程中持续伴随的命题。
审核编辑:刘清
-
智能体化AI和生成式AI的区别2025-08-25 2094
-
聚云科技荣获亚马逊云科技生成式AI能力认证 助力企业加速生成式AI应用落地2025-02-14 512
-
生成式AI如何驱动收入和投资回报率飙升2025-01-24 1210
-
生成式AI工具好用吗2025-01-17 1322
-
生成式AI工具作用2024-10-28 1746
-
商汤发布《2024生成式AI赋能教育未来》白皮书2024-06-29 2054
-
原来这才是【生成式AI】!!2024-06-05 290
-
NVIDIA生成式AI开启药物研发与设计的新纪元2024-01-10 1746
-
生成式AI技术的应用前景2023-11-29 2464
-
生成式AI已成为企业新兴风险,但我们不应该因噎废食2023-09-08 849
-
智慧有数 浪潮信息发布生成式AI存储解决方案2023-07-11 1049
-
智慧有数,浪潮信息发布生成式AI存储解决方案2023-07-07 1128
-
什么是生成式AI?生成式AI的四大优势2023-05-29 5367
-
仪表放大器: CMRR,你偷走了我的精度2022-11-01 860
全部0条评论

快来发表一下你的评论吧 !
