

汽车领域拥抱Transformer需要多少AI算力?
汽车电子
描述
Transformer在汽车领域应用自然是针对视觉的,ChatGPT3这种至少需要八张英伟达A100显卡的大模型是绝对无法出现在汽车上的。视觉类的Transformer以微软亚洲研究院的Swin Transformer和谷歌大脑的ViT为代表。Swin Transformer出现较早,其出现证明Transformer能大幅超越CNN,即SOTA。
Transformer特别适合多种分类的语义分割应用,而语义分割又是OccupancyNetwork的关键。语义分割方面,即使训练数据不多,Transformer也能压倒CNN或FPN。如果是简单的目标检测,训练数据不多的情况下,CNN基本不落下风。
汽车领域拥抱Transformer需要多少AI算力?AI算力需求与输入像素数和模型参数关系最为密切,要计算AI算力需求,有一个关键的名词:token,其在自然语言处理(NLP)里指最小的词;在图像领域,指patch,即最小的图像“块”,而tokenization是指将输入的语言或图像切割为token的过程,通常transformer是16*16像素,这个自然是像素越小越好,一句话分词分的越细,这句话的语义也就更准确,一句话分的越粗,语义偏差就可能越大。据此经简化计算,200万像素所包含的token数就是大约1万个。800万像素就是大约4万个。
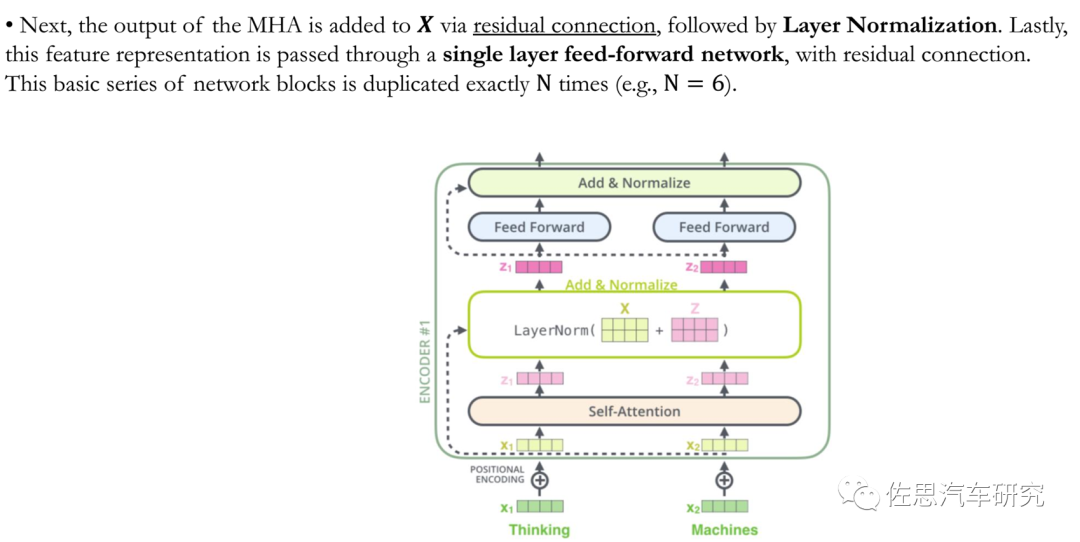
Transformer结构图
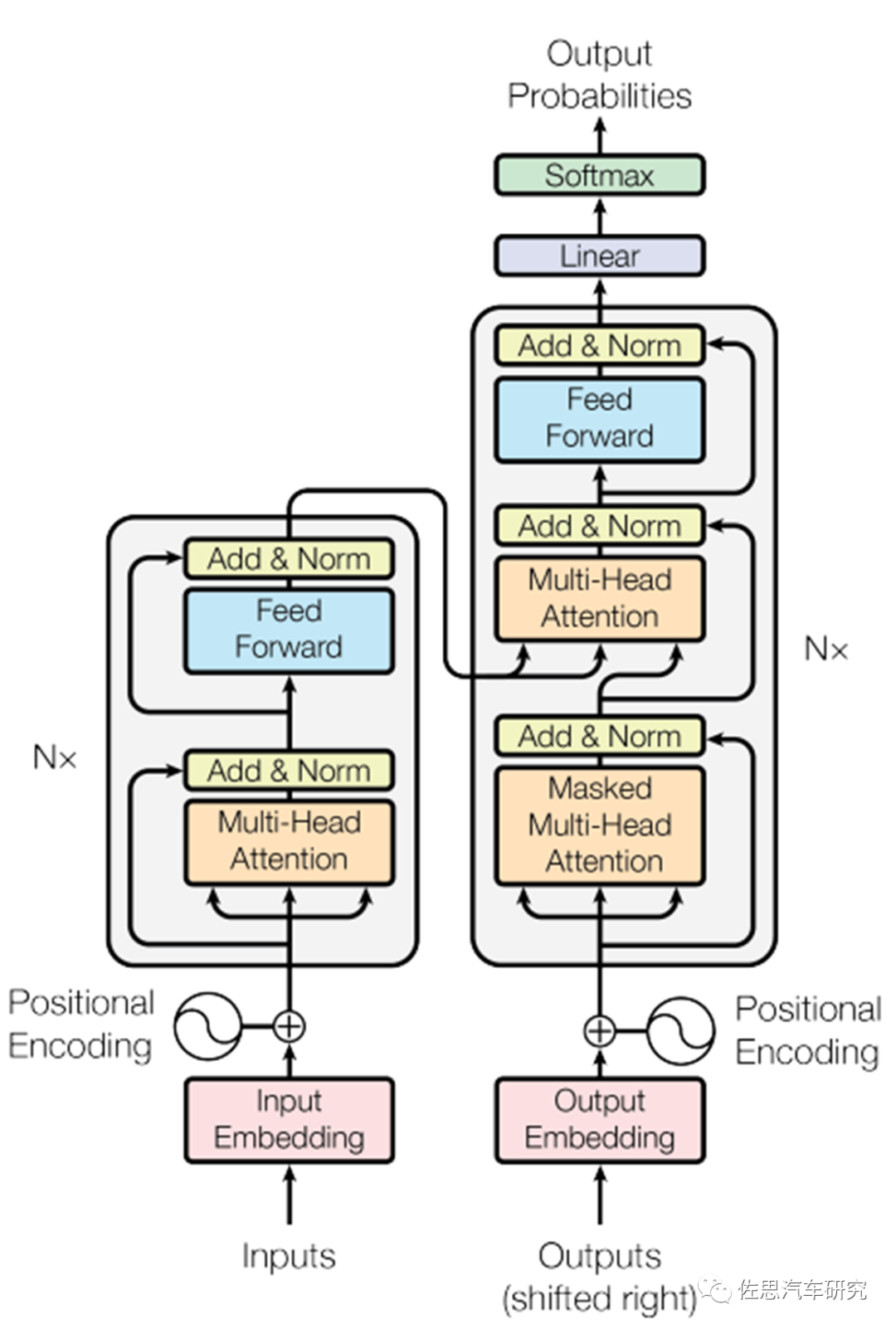
来源:互联网
Transformer由N个相同的层组成,每层包含两部分,一部分为自注意力,另一部分为MLP,每一层最后都有一个归一化。
谷歌的ViT结构
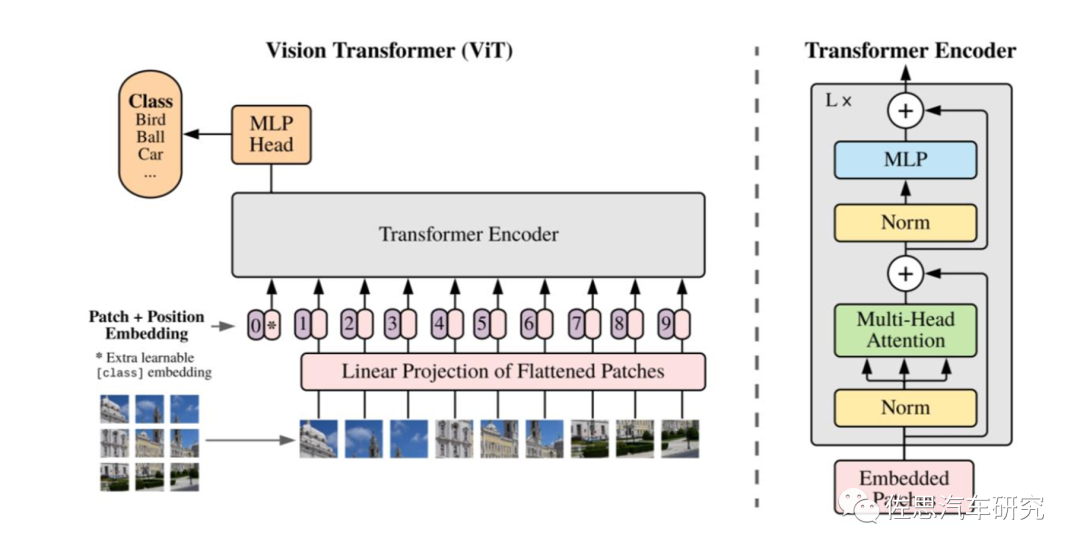
来源:谷歌
视觉领域的Transformer主要是使用了Encoder部分,如上图所示。
微软亚洲研究院提出的Swin Transformer结构
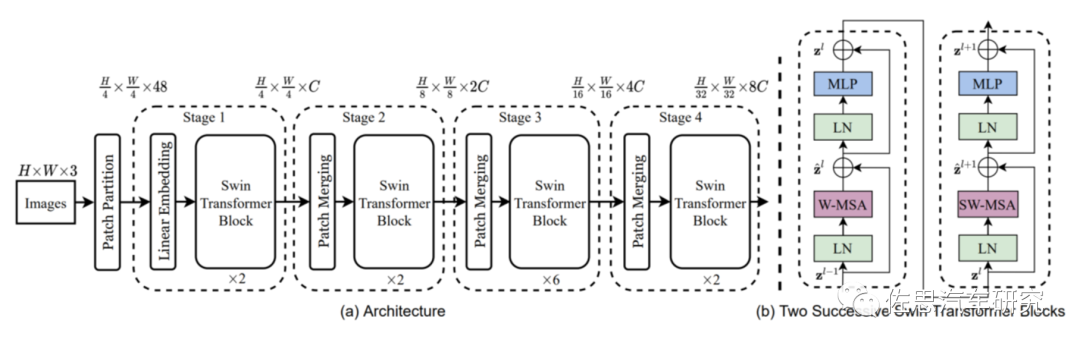
来源:微软亚洲研究院
与谷歌简单地硬切割patch有所不同,微软为了避免太多的token,在token化的过程中下了很多工夫,但实际计算量差不多。
Transformer第一步是将输入图像转换为嵌入矩阵X,同时也有空间位置编码。

位置编码是采用了三角函数算法,这个算法是标量计算,CPU做起来效率最高。
第二步是多头注意力计算。
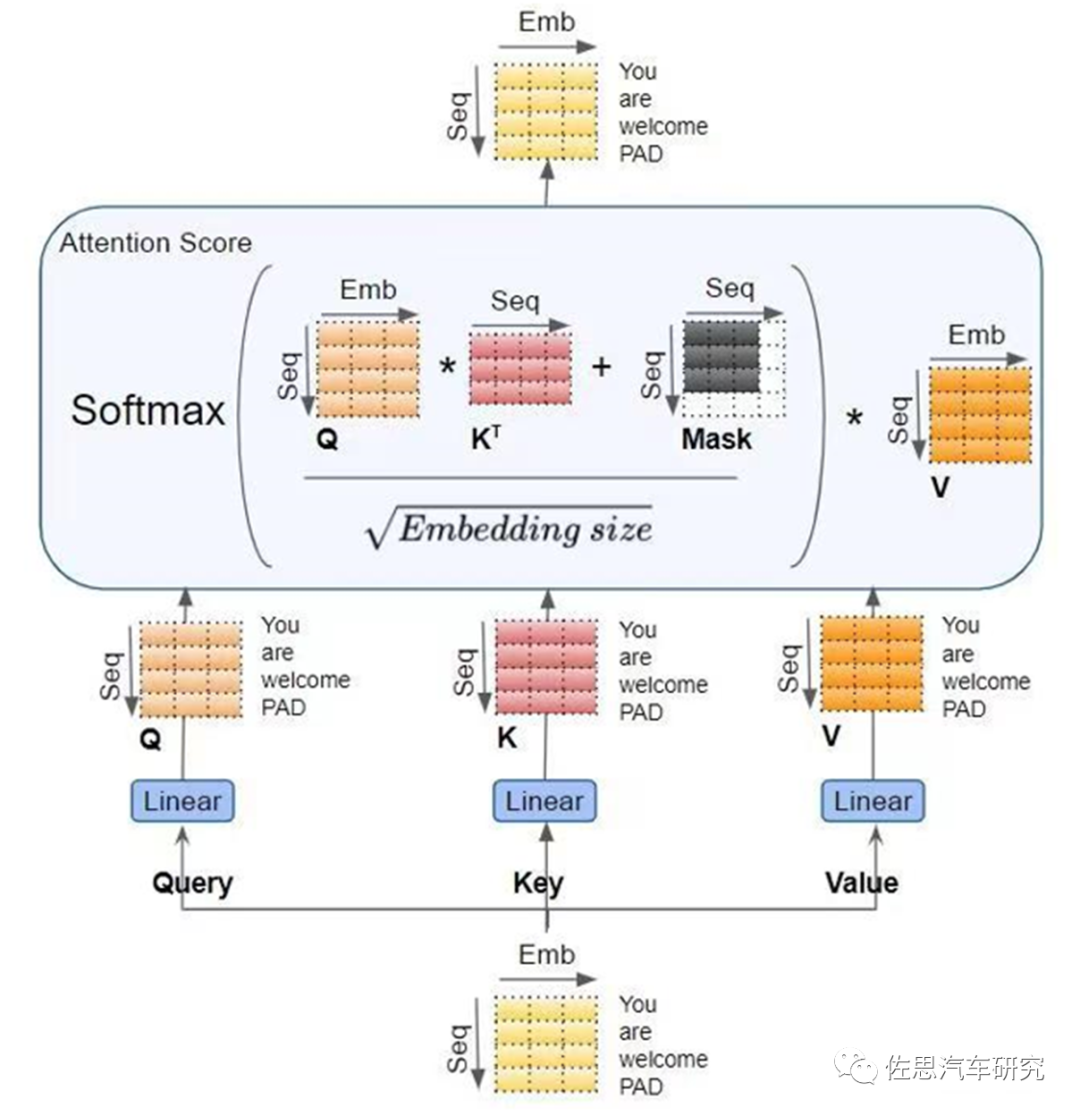
对于一个视频输入序列X,它需要和权重参数模型做矩阵乘法,即和k、v、q的权重矩阵做乘法。然后,计算每个Query(X与q的矩阵乘积)和所有Key(X与k的矩阵乘积)的匹配度,并用这个匹配度来计算Value的加权和:
Attention(Q,K, V) = softmax(Q * K^T / sqrt(d)) * V
这里的Q就是Query,K就是Key,V就是Value(X与v矩阵乘积)。X基本上等同于视频的token数量,k、v、q参数量。总计算量为2*3*网络隐藏层维度h的平方。

把几个head自注意力做Concat。总运算量为2*网络隐藏层维度的平方
接下来是归一化层,最后是前馈层。
总计算量是2*8*网络隐藏层维度的平方。
最后累加这三层的总计算量为(6+2+16=24)*网络层数*网络隐藏层维度的平方。
假设一个网络有520亿参数,64层隐藏层,隐藏层的维度是8192,那么每个token的推理计算量就是64*24*(8192的平方)=103079215104次运算,这个数值除以2就是515亿,基本等同于网络的总参数量,实际就是每个token,推理时需要两次运算,一次矩阵乘法,一次是累加。
最终计算量为token数量*2*网络参数总量。
目前,Transformer视觉模型仍然远远落后于语言模型。具体而言,SwinTransformer二代参数大约30亿, ViT-E有 40亿参数,而入门级语言模型通常超过 100亿 参数,更别说具有5400亿参数的大型语言模型。值得注意的是,谷歌于2023年2月推出了220亿参数的ViT-22B。
假设我们使用ViT-E模型,输入八百万像素的视频,采用16*16的patch,那么token数大约是4.08万个,通常自动驾驶帧率是每秒30帧(即每秒计算30次),那么每秒运算量就是30*4.08万*40亿*2=2400万亿次,即4896TOPS。如果是200万像素,那么token约为1万个,算力需要1200TOPS。
显然,这个算力需求太高,需要降级,视觉Transformer参数最小为10亿个,特斯拉AI日上就写了其参数是10亿个。不过,大模型参数越多,效果越好,然后再降低帧率到15Hz。有人会说乘积累加如果设计的非常好,勉强来说一次计算也可以完成,即我们常说MAC运算。
不过,Transformer每层最后都有非线性的归一化运算,它在每一层之外是串行结构,层内是并行结构,难以实现一次计算完成乘积累加;如果是CNN网络,全并行结构,是可以实现,更何况还有位置编码等标量计算。
最低下限就是15*1万*10亿*2=300万亿次,即300TOPS。特斯拉一代FSD的算力不过144TOPS。
实际上,无论是GPU还是AI加速器,其利用率都是很低的,特别是transformer其独特的网络结构,它是源自串行的RNN网络,AI加速器或者说AI专用芯片基本上都是针对矩阵并行计算设计的,几乎没考虑过串行。GPU略微好点,CPU的效率最高,奈何CPU核心数太少。
一般GPU的利用率是45%,低的只有30%,最高一般不超过55%,而AI专用芯片估计只有20-30%。https://arxiv.org/pdf/2104.04473.pdf,这篇文章里有详细数据,由英伟达、微软和斯坦福大学联合完成的论文,采用的是1024个英伟达A100的运算体系,典型的运算效率是45%,谷歌的TPV4针对Transformer做了优化,增加了稀疏核,最终的利用率略高,也只是50%,没做过优化的AI专用芯片,最低甚至是0%,完全无法运行。
这样一来,最低下限又要增加了,按50%的利用率,最低下限是600TOPS。然而这只是两百万像素,现在国内基本都是800万像素,且不止一个摄像头是800万像素。现在我们建设Transformer只用在一个800万像素摄像头上,并且AI处理器只负责这一个摄像头,即便如此算力还需要2400TOPS,需要10个Orin-X级联,还需要一个近千美元的PCIe交换机。实际上即便是在学术领域,目前最高的视觉Transformer的分辨率是1536*1536=236万像素,这可是在1024个A100显卡上运行的。
除了处理器本身,还有一个瓶颈,那就是存储带宽。在算力需求不高的时代,处理器的延迟主要来自存储系统,因为处理器运算力很强,但到了1000TOPS时代,处理器的延迟成了最主要的构成。
CPU控制GPU工作的流程
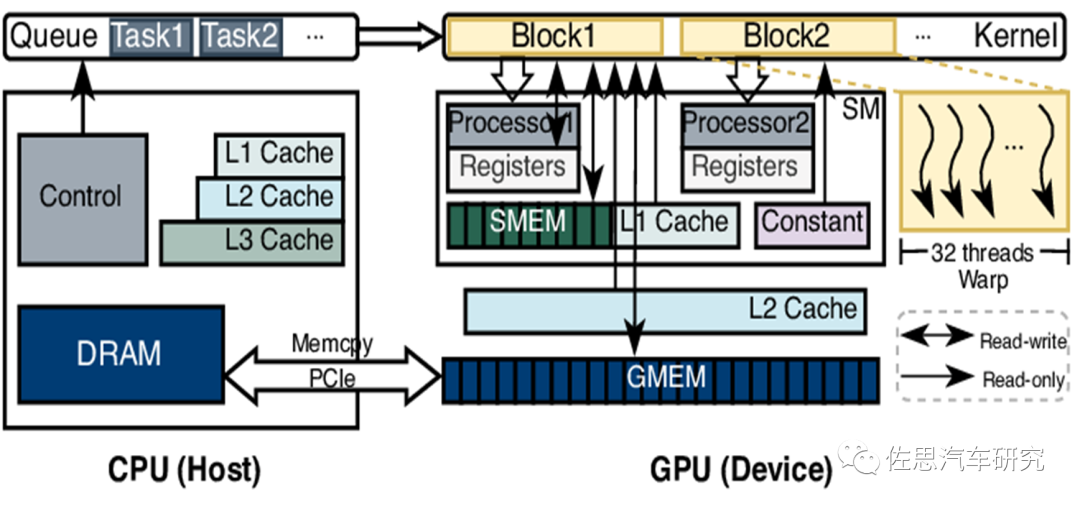
来源:互联网
GPU和AI芯片都是协处理器,也就是Device,CPU才是Host主机。GPU和AI芯片与鼠标、键盘、显示器、打印机一样都算是外设,任务的分派和调度,数据流的控制以及数据的读取与写入均受CPU控制。数据首先是在CPU指令调度下才读取的,数据整形(如果AI芯片或GPU内部有标量运算单元也可以做)后再交给GPU,计算完后再传输给CPU写入内存。
某些系统会有DMA如MCU,DMA是指无需经过CPU的直接存储,但需经过数据总线,数据总线带宽未必有内存宽;DMA主要是缓解CPU的工作压力,因为MCU内部的CPU性能很弱。数据中心也有一些基于通讯协议的DMA,通常只用于数据中心的多显卡系统。
AI运算的过程由CPU发起,取指令、译码、读取数据、运算、写入结果。由于Transformer的权重模型太大,至少1GB以上,所以无法放进芯片内部,只能放在DRAM内部,每一次运算都需要调取权重模型一次,计算完的结果还要写入存储DRAM。
前面我们看到,由于Transfomer需要超高算力,处理器本身计算消耗的时间已经是延迟的最低下限,没有留给读取和写入存储系统的时间,冯诺依曼架构又是数据和指令是分开存储的,无法同时读取。换言之,存储系统读取权重模型和写入结果的时间必须快到可以忽略不计。即便我们假设写入结果的时间可以忽略,但是高达1GB权重的读取时间要做到可以忽略不计,那么需要存储带宽达到1TB/s,那么每次读取权重模型的时间可以接近1毫秒,可以忽略不计。实际存储带宽也是有利用率,通常不会到80%。
最新的GDDR6X最高可以做到1TB/s的带宽,但这只是最小10亿的参数量,典型视觉transformer的参数量是30-40亿,存储带宽需要3-4TB/s,英伟达4万美元的H100PCIe的带宽不过2.04TB/s。
最后我们来简单计算一下训练所需要的计算量,语言大模型的训练量30000亿个Token,换算成800万像素就是681小时左右的视频,训练需要一次前向反馈和一次反向传播,还需要一次中间激活,大约是推理运算量的4倍。
我们将参数量取30亿,训练681小时的运算量为3万亿*30亿*8=720万亿亿,假设用128个英伟达A100(FP16算力是312TOPS)做训练,GPU利用效率是45%,那么需要大约4.7天训练完成。128个英伟达A100,目前价格大约是128*50万人民币=6400万人民币,从训练的角度看,大型车企还是撑的住的。
审核编辑:刘清
- 相关推荐
- 热点推荐
- 处理器
- FSD
- Transformer
- AI芯片
- MLP
-
边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值2026-03-10 957
-
Transformer 入门:从零理解 AI 大模型的核心原理2026-02-10 364
-
将AI算力送上太空,是终极方案还是疯狂幻想?评论区说出你的阵营!江苏易安联 2026-01-06
-
什么是AI算力模组?2025-09-19 1269
-
一文看懂AI算力集群2025-07-23 2180
-
企业AI算力租赁模式的好处2024-12-24 2223
-
企业AI算力租赁是什么2024-11-14 3593
-
如何定义AI算力中心新实践2022-09-05 1772
-
MXM 算力平台在边缘计算领域的应用2022-05-18 37180
-
全面拥抱Transformer:NLP三大特征抽取器(CNNRNNTF)比较2020-05-29 2813
-
寒武纪、科大讯飞频出新品,推动AI算力,AI应用落地2017-11-14 2443
全部0条评论

快来发表一下你的评论吧 !
