

【AI简报20230818期】人形机器人问世:大模型加持;用AI微调AI,微软全华班出品!
描述
1. 腾讯云宣布全面支持Llama2等主流开源模型
原文:https://t.cj.sina.com.cn/articles/view/1654203637/629924f5020010xw1?from=tech
腾讯云方面16日宣布,腾讯云TI平台已经全面接入Llama 2、Falcon、Dolly、Vicuna、Bloom、Alpaca等20多个主流模型,这些主流模型支持直接部署调用、应用流程简单、可全程低代码操作。企业、开发者可以根据不同细分场景的业务需求,灵活选择各类大模型,降低大模型使用成本。

2. 稚晖君人形机器人问世:大模型加持,会自己换胳膊,要上生产线造车
原文:https://mp.weixin.qq.com/s/cgfbJgl9enzGXGTb6q6FGA大模型技术的新一波浪潮:具身智能,已经有了重要进展。刚刚,稚晖君的创业公司「智元机器人」开了自己的第一场发布会。



未来也可以成为人们日常生活的助手:
「远征 A1」是模块化的,可以面向不同任务,自己给自己换组件:

自研电机,模块化设计
用两条腿来走路,又能够拥有生产力,这意味着硬件设计要有强大的能力。智元机器人构建了一套自研的硬件系统,包括关节电机、灵巧手等。如果从零部件算,整个机器人的国产化率在 80% 以上。自研核心关节电机 PowerFlow
如果想让人形机器人行动灵敏、准确,它的关节需要满足很多条件,比如体积小、重量轻、功率密度高、能量利用效率高、响应带宽高、耐冲击等等。其中,核心关节不仅是让人形机器人更加灵活、更加自由的关键,也是未来实现规模量产、低成本制造的重要门槛之一,稚晖君在现场解释说。为了实现这些目标,智元团队自研、设计了一款专用关节 ——PowerFlow。这个关节采用了准直驱的方案,它的优点是功率高、不需要传感器(可以用电机电流判断力矩),通过电流直接做力矩控制,价格低。为了增加功率密度,远征 A1 的关节模组还集成了液冷循环散热系统。搭配上自研的一体化矢量驱动控制器,整个关节的峰值扭矩可以达到 350Nm。不过,稚晖君表示,他们还没有测到扭矩的真正上限,估计潜力比想象中高。而且,由于水冷散热的加持,它可以保持更长时间的峰值扭距输出,而重量仅为 1.6 公斤。


自研灵巧手 SkillHand
要想让机器人更好地干活,手是另外一个关键部件,因此智元研发了灵巧手 SkillHand。这个灵巧手有 12 个主动自由度、5 个被动自由度,而且所有驱动都是内置的。考虑到这个灵巧手未来将面对精密制造场景,智元在它的指尖安装了一些传感器。其中,视觉传感器可以分辨操作物的颜色、材质。基于各种算法的数据融合,指尖还可以做到近似的触觉压力传感器效果。由于这些传感器可以帮助机器人实现末端的视觉闭环,整机的电机精度需求得以降低。有意思的是,如果场景需要,这个机器人其实可以自主更换灵巧手,比如把手换成螺丝刀。稚晖君说,这是模块化设计思想在他们机器人中的体现。类似的模块化设计还可以让机器人由腿式变成轮式,「这是它通用性的一个体现」。

全套 AI 框架
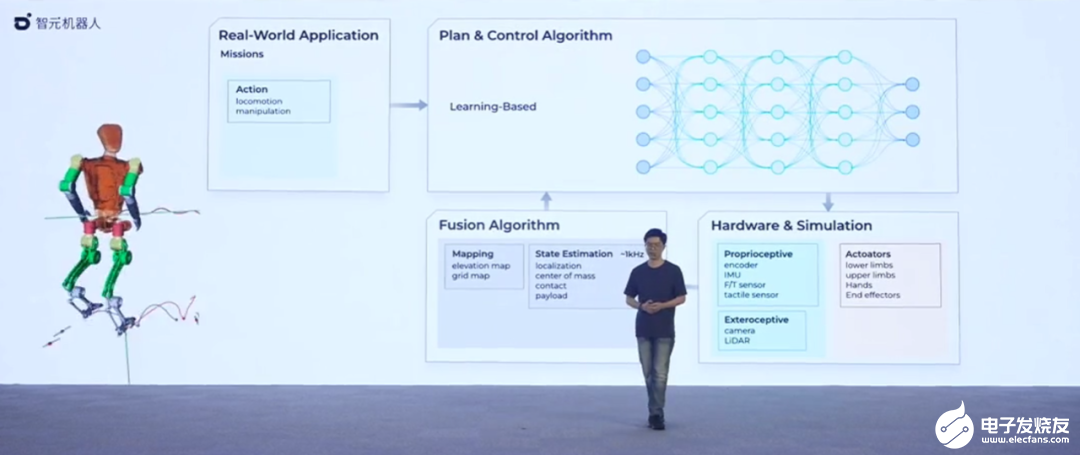
如何让通用机器人实现低成本量产,产生实际应用价值?稚晖君表示,硬件只是前提条件之一,更重要的其实是背后的机器人大脑。在当前的具身智能领域,很多研究都在尝试将大模型作为机器人的大脑,稚晖君也不例外,他也想用多模态大模型的能力赋能智元机器人的行为动作编排。在智元机器人上个月发布的一个视频中,我们已经看到了这个想法的初步实现,比如给出自然语言指令「把离你最近的木块放到紫色的方块右边 3 厘米」,机器人就会按照指示行动。稚晖君把这个机器人背后的大模型叫做 WorkGPT,这是一个百亿级参数的大模型。

 在稚晖君看来,语言和图像大模型对于机器人领域应用最大的价值在于两个方面,一是庞大的先验知识库和强大的通识理解能力,比如你不用告诉它什么是垃圾,它就能自己分辨出来;二是复杂的语义多级推理能力,即所谓的「思维链」,这体现在它可以把复杂的指令分成一个一个的步骤。「在大模型时代到来之前,机器人都是专用设备,我们需要针对性地对每一个任务进行调试和部署。现在利用大模型的各种通识能力和举一反三的推理能力,我们可以看到解决这些问题,然后最终走向通用机器人的一道曙光。」稚晖君说。所以,在智元,他们打造了一个名为 EI-Brain 的具身智脑框架。在框架中,机器人系统被分为不同层级,包括部署在云端的超脑,部署在端侧的大脑、小脑以及脑干,分别对应机器人任务不同级别的技能,包括技能级、指令级、伺服级等。具体来说,「大脑」负责跟我们人类一样进行抽象思考、多级推理,「小脑」负责运动控制方面的一些指令生成,「脑干」负责电机控制、伺服等硬件底层任务。
在稚晖君看来,语言和图像大模型对于机器人领域应用最大的价值在于两个方面,一是庞大的先验知识库和强大的通识理解能力,比如你不用告诉它什么是垃圾,它就能自己分辨出来;二是复杂的语义多级推理能力,即所谓的「思维链」,这体现在它可以把复杂的指令分成一个一个的步骤。「在大模型时代到来之前,机器人都是专用设备,我们需要针对性地对每一个任务进行调试和部署。现在利用大模型的各种通识能力和举一反三的推理能力,我们可以看到解决这些问题,然后最终走向通用机器人的一道曙光。」稚晖君说。所以,在智元,他们打造了一个名为 EI-Brain 的具身智脑框架。在框架中,机器人系统被分为不同层级,包括部署在云端的超脑,部署在端侧的大脑、小脑以及脑干,分别对应机器人任务不同级别的技能,包括技能级、指令级、伺服级等。具体来说,「大脑」负责跟我们人类一样进行抽象思考、多级推理,「小脑」负责运动控制方面的一些指令生成,「脑干」负责电机控制、伺服等硬件底层任务。



未来要卖 20 万以内
公司成立半年不到就发布第一款样机,还具备完整的体系,让人们不由得感叹现在 AI 领域创业公司速度之快。更重要的是,智元机器人并不是一味在追求前沿技术探索,而是「所有产品都在为商业落地服务」。发布会上稚晖君表示,希望能把整机成本控制在 20 万元以内,使其具备落地的条件,并计划在远征 A1 发布后,以此为基础马上推出第一代商用产品。商业化也已经有了相对具体的方向:基于当前的人形机器人技术,公司已在与国内新能源头部车企商讨合作。希望在汽车制造总装线、分装线等场景上进行商用化落地的尝试,另外也在和 3C 制造的大厂研究合作。智元机器人还计划在未来几年里把人形机器人推广到更多领域。在消费级市场,人形机器人预计可适用的方式包含烹饪、家政、家庭护理、康复训练等。智元机器人(AGIBOT)成立于 2023 年 2 月,目前融资已经完成了四轮,投资方包括高领、百度等风投机构。说到公司未来的发展,智元计划逐步开放开发平台,在未来以每年一代的速度迭代新的样机产品,并不断进行商用验证。稚晖君也表示,为了支持计划,公司即将开启秋招。 智元机器人投身的具身智能当前是一个热门领域。谷歌、斯坦福、英伟达等国际科技机构都在这方面展开了研究,并在近期展示了他们的具身智能机器人成果。今年 3 月份,一家名为 1X 的具身智能机器人公司还拿到了 OpenAI 的投资。随着稚晖君等国内外优秀人才的快速进场,或许我们很快就能看到行业内出现颠覆性的应用。「我的梦想是有一天能够真正造出科幻电影中的智能机器人,它不再是简单的机械装置,而是拥有自主思考和学习能力的智能伙伴,能够感知、理解我们的世界,并与我们深入沟通,」稚晖君说道。「远征 A1 的发布,只是我们追求的起点。」
智元机器人投身的具身智能当前是一个热门领域。谷歌、斯坦福、英伟达等国际科技机构都在这方面展开了研究,并在近期展示了他们的具身智能机器人成果。今年 3 月份,一家名为 1X 的具身智能机器人公司还拿到了 OpenAI 的投资。随着稚晖君等国内外优秀人才的快速进场,或许我们很快就能看到行业内出现颠覆性的应用。「我的梦想是有一天能够真正造出科幻电影中的智能机器人,它不再是简单的机械装置,而是拥有自主思考和学习能力的智能伙伴,能够感知、理解我们的世界,并与我们深入沟通,」稚晖君说道。「远征 A1 的发布,只是我们追求的起点。」3. 钉钉个人版开放内测:无打卡、无已读 提供一站式AI服务
原文:https://news.mydrivers.com/1/929/929366.htm快科技8月16日消息,根据钉钉官网显示,全新的钉钉个人版已经正式启动内测,所有用户都可在官网申请加入内测。据了解,钉钉个人版,主要面向小团队、个人用户、高校大学生等人群,旨在探索每个个体、每个团队的数字生产力工具,让智能化变革普惠每一个个体,AI人人可用。
加入内测后,用户可抢先体验各类AI服务,目前文生文、文生图、角色化对话以及AI创作等服务均限时免费。值得一提的是,钉钉个人版并没有常规的打卡和消息已读显示功能,对个人用户来说更加友好。

4. GPT-4数学再提30分,代码解析器任督二脉被打开,网友:像大脑的工作方式
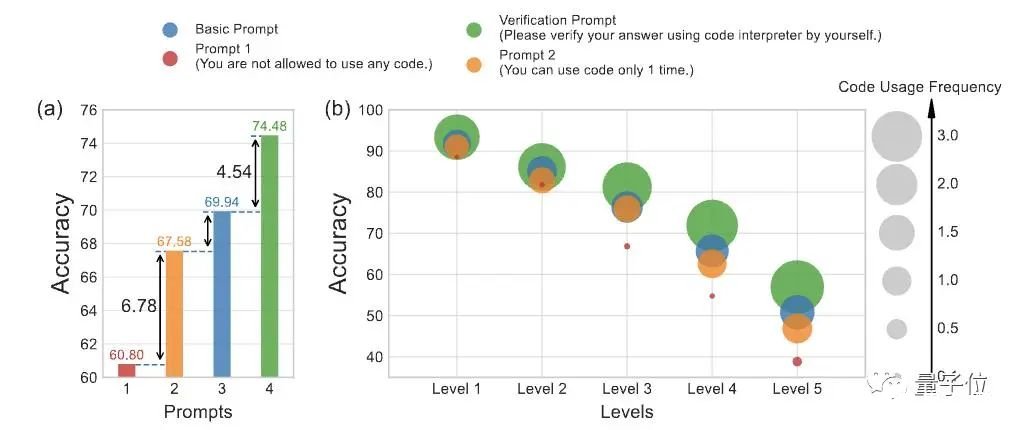
原文:https://www.thepaper.cn/newsDetail_forward_24270135GPT-4数学能力还能更强!新研究发现GPT-4代码解释器做题准确率与其使用代码的频率有关。为此,研究人员提出新方法对症下药,直接将其数学能力拔至新SOTA:在MATH数据集上,做题准确率从53.9%增加到了84.3%。
你没听错,就是前段时间被称为ChatGPT推出后最强模式的那个代码解析器(Code Interpreter)。研究人员窥探了其代码生成和执行机制,使用自我验证、验证引导加权多数投票的方法,直接打开其做数学题的任督二脉。好奇网友随即而来:还想看他们做高数。



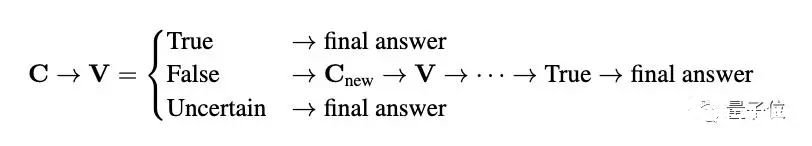

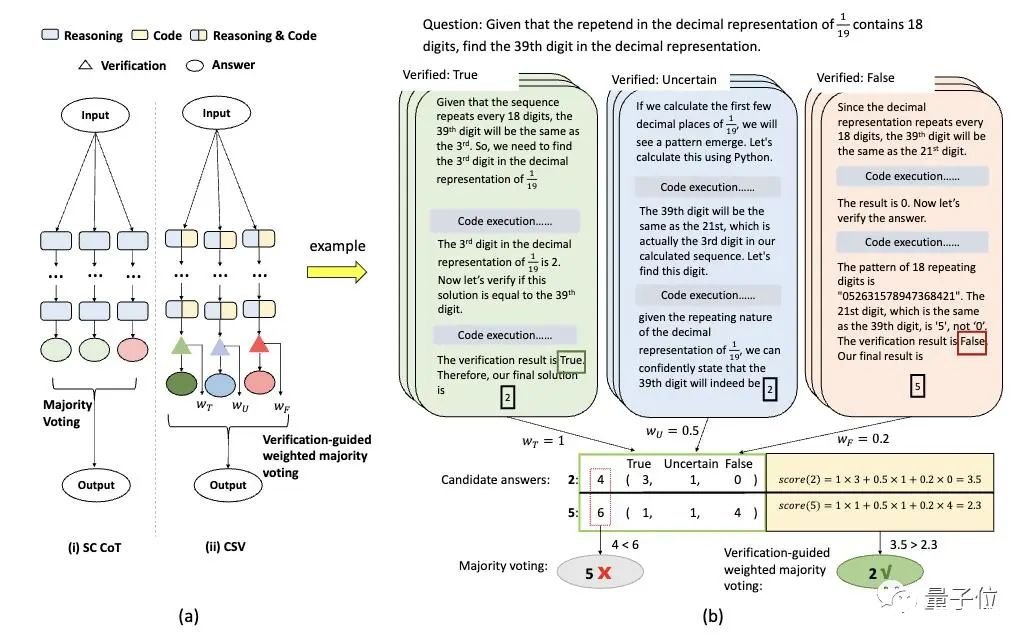
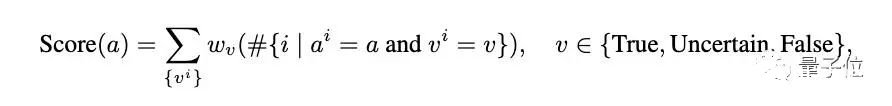
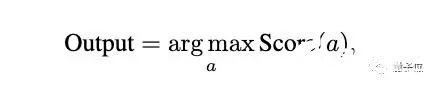
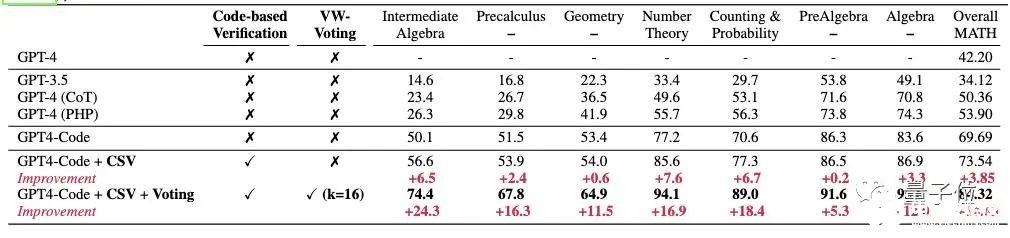
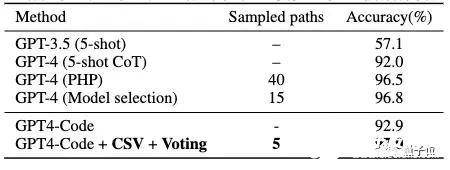
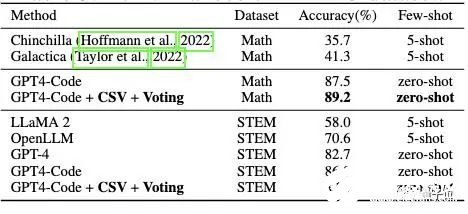
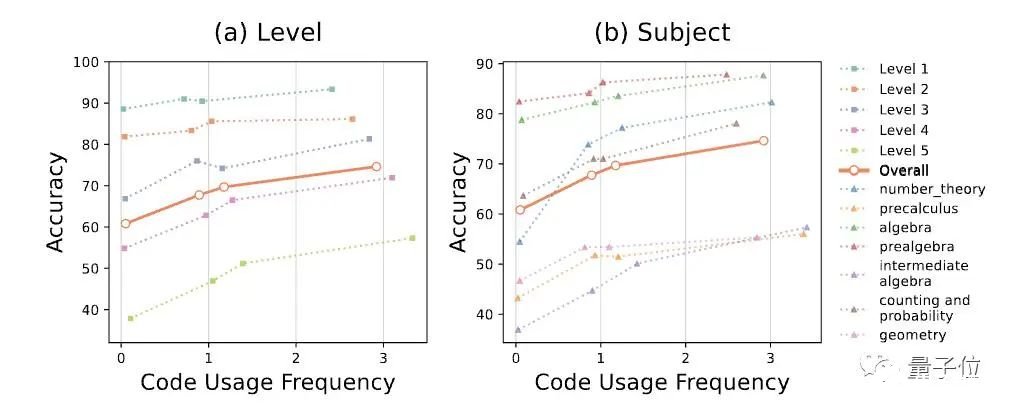
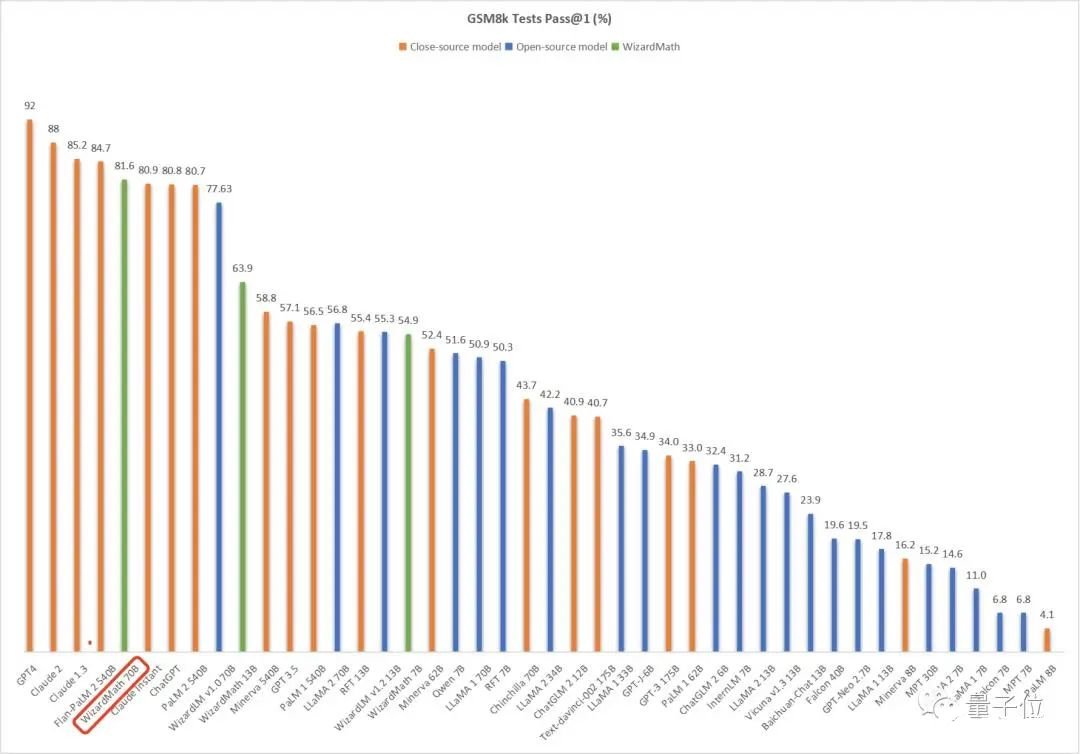
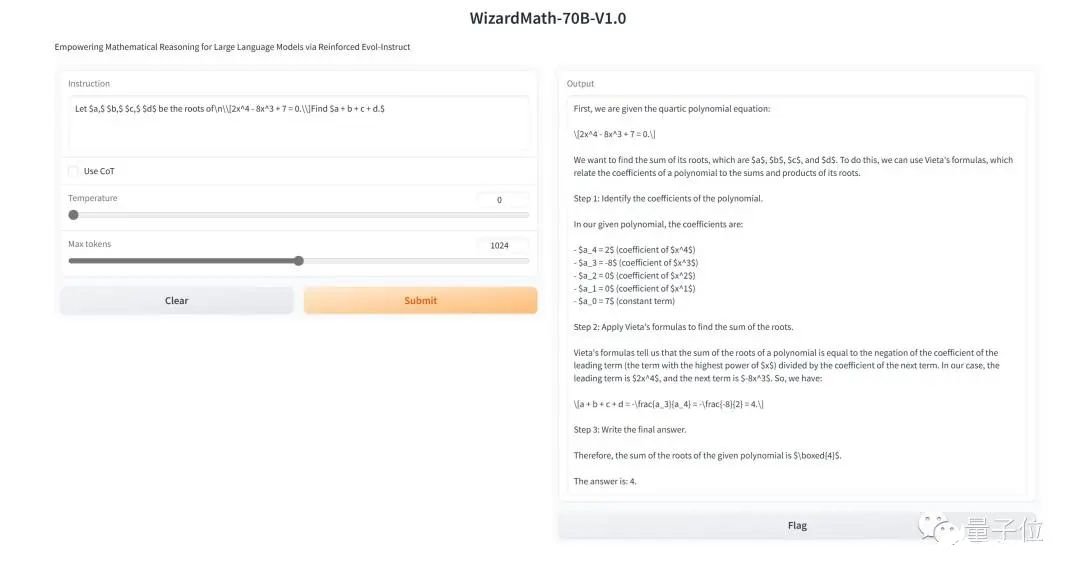
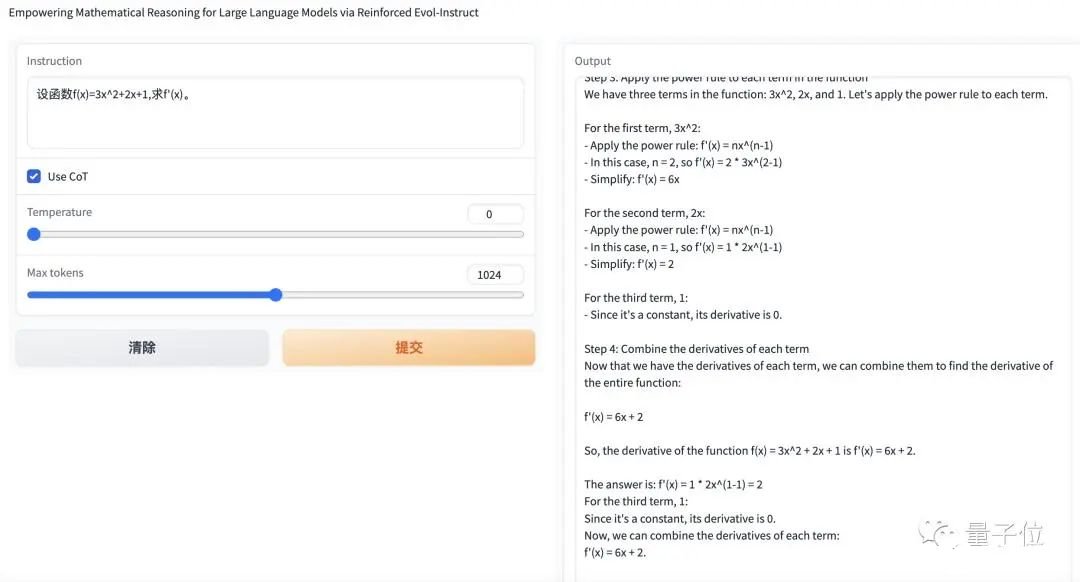
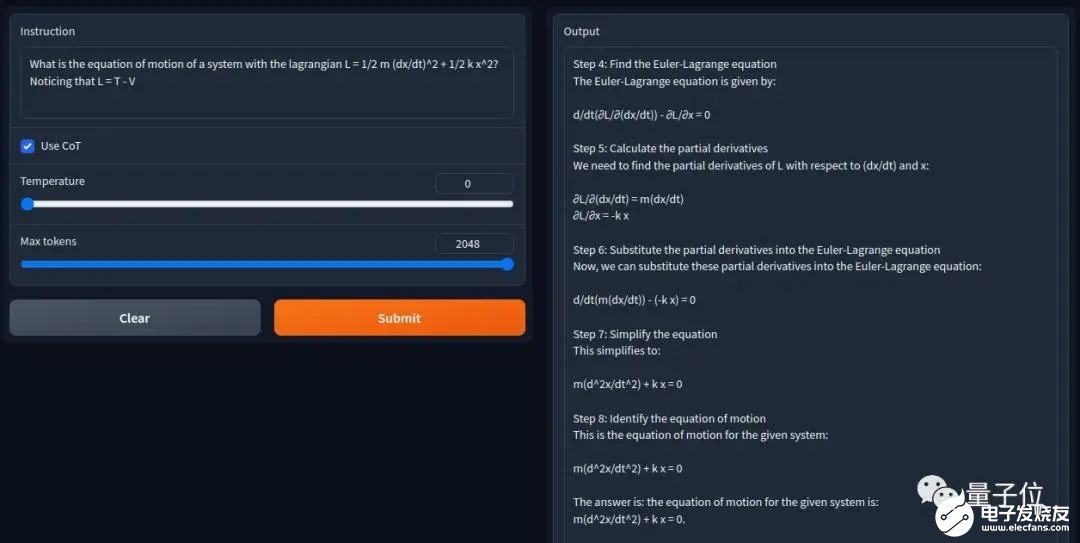
5. 数学能力超ChatGPT,70B开源大模型火了:用AI微调AI,微软全华班出品
原文:https://www.thepaper.cn/newsDetail_forward_24224649用AI生成的指令微调羊驼大模型,数学能力超ChatGPT——微软最新开源大模型WizardMath来了。


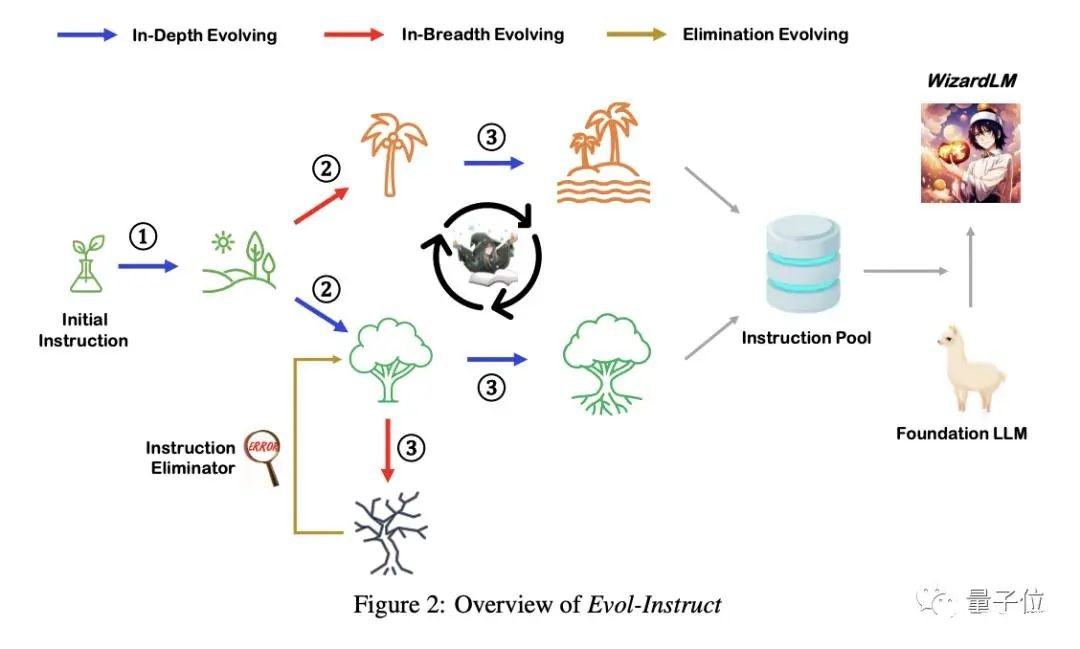
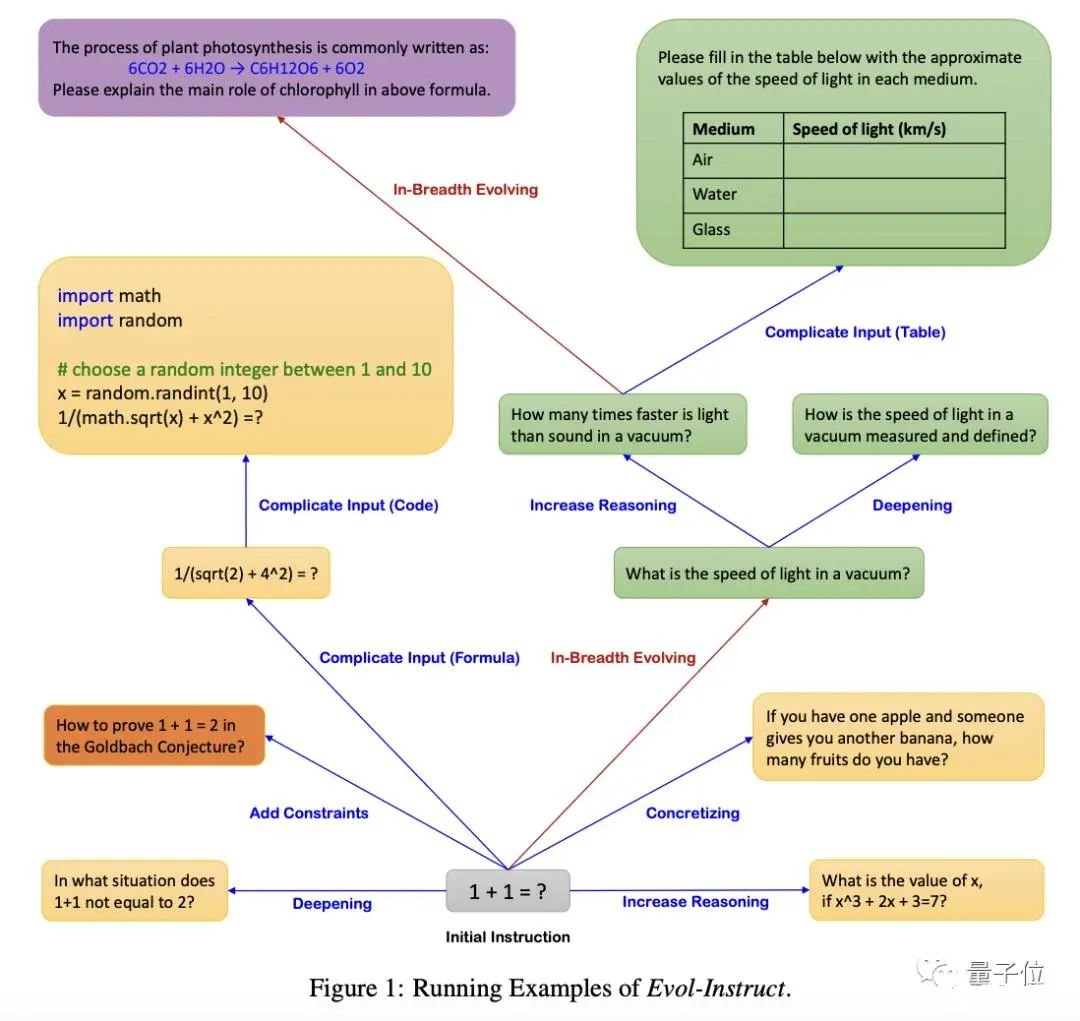
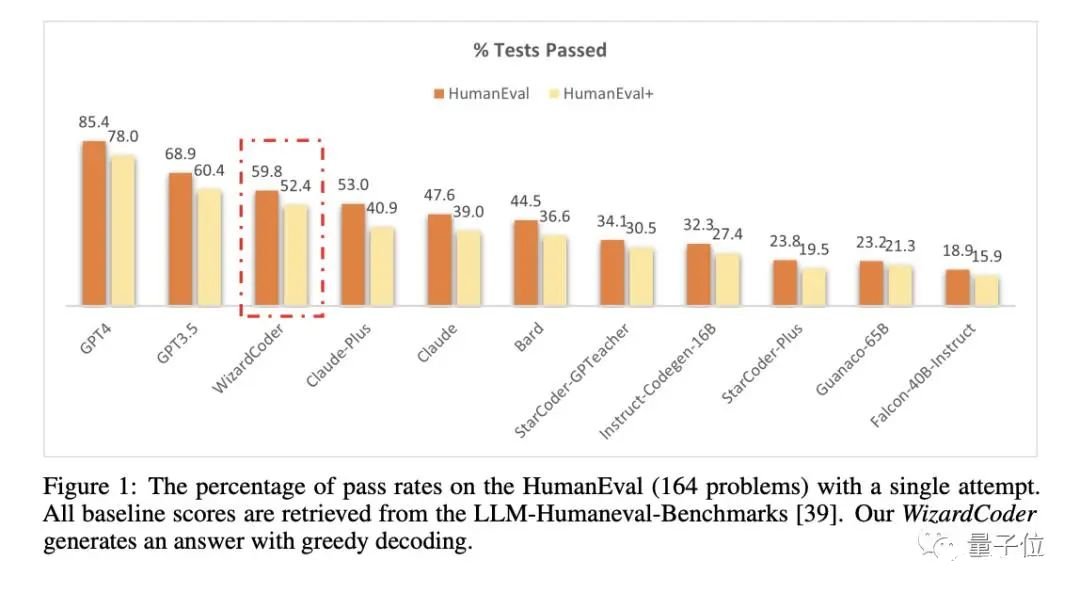

通讯作者为姜大昕,微软全球合伙人、副总裁、前微软亚洲研究院首席科学家,在微软工作16年有余、曾作为微软必应搜索引擎和Cortana智能助手自然语言理解负责人,。
另还有一位作者Jiazhan Feng,是北大学生,这篇合著论文是TA在微软实习时产出的。项目主页:https://github.com/nlpxucan/WizardLM/tree/main/WizardMath论文地址:https://arxiv.org/abs/2304.12244(WizardLM)https://arxiv.org/abs/2306.08568(WizardCoder) ———————End———————
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 热点推荐
- RT-Thread
-
AI大模型微调企业项目实战课2026-04-16 891
-
大象机器人携手进迭时空推出 RISC-V 全栈开源六轴机械臂产品2025-04-25 7393
-
人形之外,AI机器人的多元未来2025-01-21 4670
-
王耀南院士:AI大模型赋能人形机器人及未来趋势2024-11-08 2448
-
Al大模型机器人2024-07-05 2462
-
人形机器人初创公司Figure AI与微软和OpenAI展开融资谈判2024-02-04 1649
-
机器人拥抱AI大模型已成共识!2023-12-22 818
-
AI智能电销外呼机器人-自动拨打电话2021-09-02 1655
-
如何把AI(智能)移植到手机或机器人上?2020-11-25 2899
-
【HarmonyOS HiSpark AI Camera】厅堂机器人2020-11-19 903
-
【HarmonyOS HiSpark AI Camera】基于HiSpark AI Camera HarmonyOS 智能巡检机器人开发2020-11-18 2453
-
AI语音智能机器人开发实战2019-01-04 6579
-
如果有一台AI机器人,你希望它每天帮你做哪些事?2018-10-23 4472
-
年轻人,以后让AI给你升职加薪吧2018-08-28 5903
全部0条评论

快来发表一下你的评论吧 !
