

内存架构演进:CXL与RDMA的协同发展
描述
随着第一代芯片的发布,围绕CXL的早期炒作逐渐被现实的性能期望所取代。与此同时,关于内存分层的软件支持正在不断发展,借鉴了NUMA和持久内存方面的先前工作。最后,运营商已经部署了RDMA以实现存储分离和高性能工作负载。由于这些进步,主内存分离现在已经成为可能。
分层解决内存危机
随着近期AMD和Intel服务器处理器的推出,内存分层技术正取得重大进展。无论是AMD的新EPYC(代号Genoa)还是Intel的新Xeon Scalable(代号Sapphire Rapids),都引入了CXL,标志着新的内存互连架构的开始。第一代支持CXL的处理器处理的是规范的1.1版本,然而CXL联盟在2022年8月发布了3.0版本的规范。
当CXL推出时,关于主内存分离的夸张言论出现了,忽略了访问和传输延迟的现实情况。随着第一代CXL芯片现已发货,客户需要处理软件适应分层要求的问题。运营商或供应商还必须开发编排软件来管理池化和共享内存。与软件同时进行的是,CXL硬件生态系统将需要数年的时间来充分发展,特别是包括CPU、GPU、交换机和内存扩展器在内的CXL 3.x组件。最终,CXL承诺将演变成一个真正的架构,可以将CPU和GPU连接到共享内存,但网络连接的内存仍然具有一定的作用。
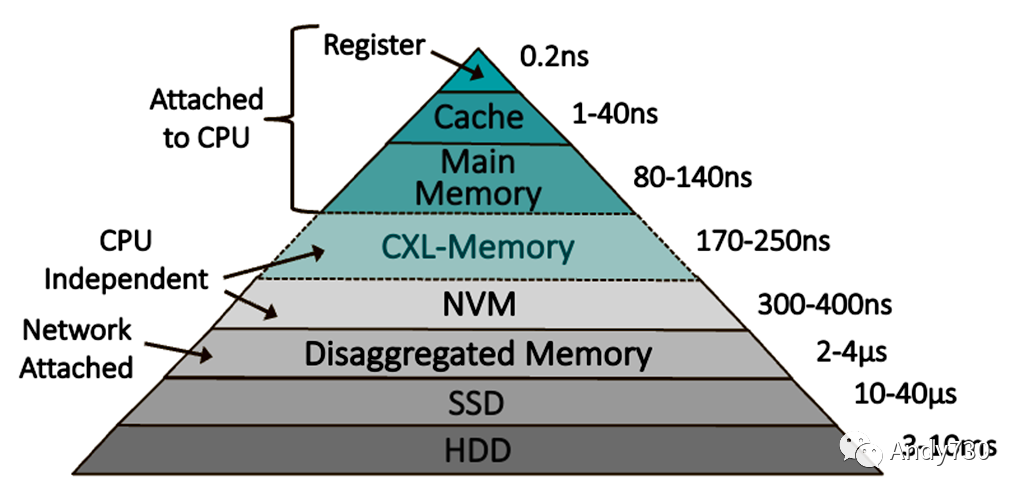
图1. 内存层次结构
正如图1所示,内存层次正在变得更加精细,以换取访问延迟和容量以及灵活性之间的平衡。金字塔的顶部是性能层,需要将热数据存储以获得最大性能。冷数据可以降级为容量层,传统上由存储设备提供服务。然而,在近年来,开发人员已经优化了软件,以在多插槽服务器中不同NUMA域中以及在持久(非易失性)内存(例如Intel的Optane)中存放页面时提高性能。虽然Intel停止了Optane的开发,但其大量的软件投资仍然适用于CXL连接的内存。
将内存页面交换到固态硬盘会引发严重的性能损失,从而为新的基于DRAM的容量层创造了机会。有时被称为“远程内存”,这种DRAM可以存在于另一台服务器或内存设备中。在过去的二十年中,软件开发人员推进了基于网络的交换的概念,该概念使得服务器能够访问网络上另一台服务器中的远程内存。通过使用支持远程DMA(RDMA)的网卡,系统架构师可以将访问网络连接的内存的延迟降低到不到4微秒,如图1所示。因此,与传统的将数据交换到存储进行交换相比,通过网络交换可以显著提高某些工作负载的性能。
内存扩展推动了CXL的导入
虽然CXL只有三年多的历史,但已经取得了超过之前的相干互连标准(如CCIX、OpenCAPI和HyperTransport)的行业支持。关键是,尽管Intel是原始规范的开发者,但AMD仍然支持并实现了CXL。
不断增长的CXL生态系统包括将DDR4或DDR5 DRAM连接到支持CXL的服务器(或主机)的内存控制器(或扩展器)。CXL早期导入的一个重要因素是它重新使用了PCIe物理层,实现了I/O的灵活性,同时不增加处理器引脚数。这种灵活性延伸到了插卡和模块,这些插卡和模块使用与PCIe设备相同的插槽。对于服务器设计者来说,添加CXL支持只需要最新的EPYC或Xeon处理器,并注意PCIe通道的分配情况。
CXL规范定义了三种不同用例所需的三种设备类型和三种协议。在这里,我们将重点放在用于内存扩展的Type 3设备上,以及用于缓存一致性内存访问的CXL.mem协议上。所有三种设备类型都需要CXL.io协议,但Type 3设备只在配置和控制方面使用它。与CXL.io和PCIe相比,CXL.mem协议栈使用不同的链路和事务层。关键区别在于,CXL.mem(和CXL.cache)采用固定长度的消息,而CXL.io使用类似PCIe的可变长度数据包。在1.1和2.0版本中,CXL.mem使用68字节的流控单元(flit),处理64字节的缓存行。CXL 3.0采用了PCIe 6.0中引入的256字节flit,以适应前向纠错(FEC),但还添加了一个将错误检查(CRC)分成两个128字节块的延迟优化flit。
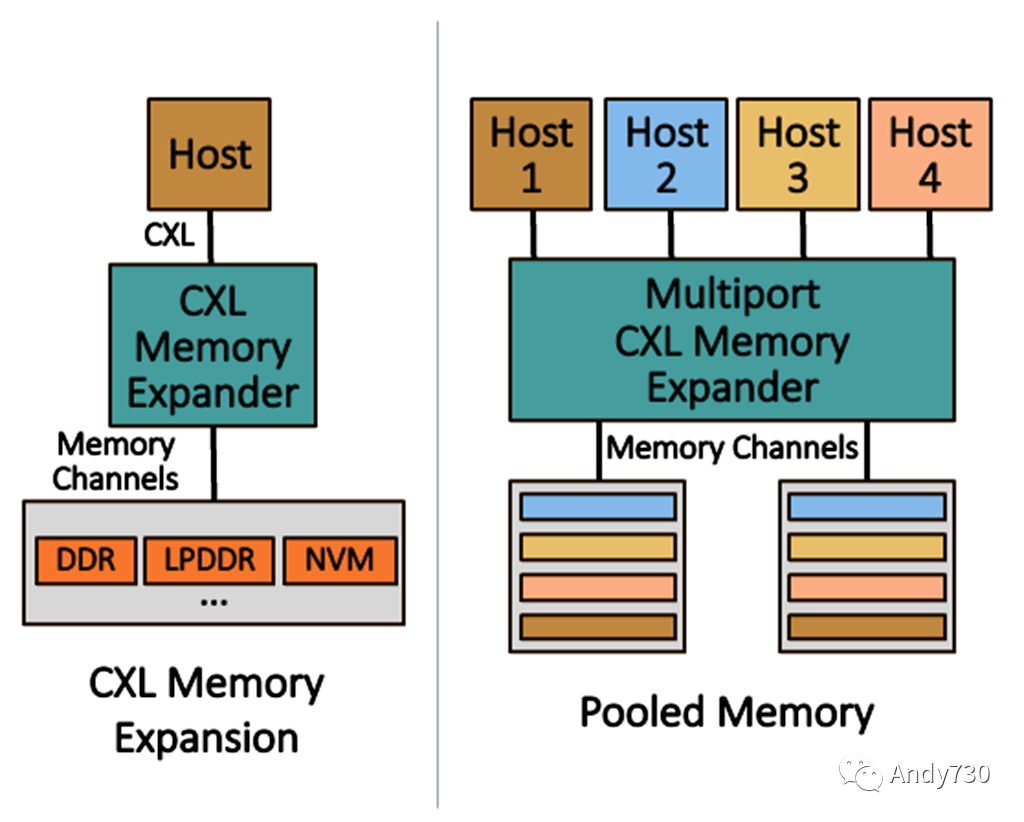
图2. CXL 1.1/2.0 应用案例
从根本上讲,CXL.mem为PCIe接口引入了加载/存储语义,实现了内存带宽和容量的扩展。如图2所示,第一个CXL用例围绕着内存扩展展开,从单主机配置开始。最简单的示例是CXL内存模块,例如Samsung的512GB DDR5内存扩展器,具有一个PCIe Gen5 x8接口,采用EDSFF外形尺寸。该模块使用来自Montage Technology的CXL内存控制器,供应商声称支持CXL 2.0。同样,Astera Labs提供了一个带有CXL 2.0 x16接口的DDR5控制器芯片。该公司开发了一个PCIe插卡,将其Leo控制器芯片与四个RDIMM插槽相结合,处理高达合计2TB的DDR5 DRAM。
连接到CXL的DRAM的未加载访问延迟应该比连接到处理器集成内存控制器的DRAM大约100纳秒。内存通道显示为单一逻辑设备(SLD),可以分配给一个单一的主机。使用单个处理器和SLD进行内存扩展代表了CXL内存性能的最佳情况,假设直接连接,没有中间设备或层,如重定时器和交换机。
下一个用例是池化内存,它可以将内存区域灵活地分配给特定的主机。在池化中,内存只分配给并且只能被单一主机访问,即一个内存区域不会被多个主机同时共享。当将多个处理器或服务器连接到内存池时,CXL可以采用两种方法。原始方法是在主机和一个或多个扩展器(Type 3设备)之间添加CXL交换组件。这种方法的缺点是交换机会增加延迟,我们估计大约为80纳秒。尽管客户可以设计这样的系统,但我们不认为这种用例会取得高量级的采用,因为增加的延迟会降低系统性能。
相反,另一种方法是使用多头(MH)扩展器将少量主机直接连接到内存池,如图2中央所示。例如,初创公司Tanzanite Silicon Solutions在被Marvell收购之前展示了一个基于FPGA的原型,拥有四个头部,后来披露将推出具有8个x8主机端口的芯片。这些多头控制器可以成为一个内存设备的核心,为少量服务器提供一池DRAM。然而,直到CXL 3.0之前,管理MH扩展器的命令接口并没有标准化,这意味着早期的演示使用了专有的结构管理。
CXL 3.x实现了共享内存结构
尽管CXL 2.0可以实现小规模的内存池,但它有许多限制。在拓扑结构方面,它仅限于16个主机和单层交换器层次结构。对于连接GPU和其它加速器来说更重要的是,每个主机只支持一个Type 2设备,这意味着CXL 2.0不能用于构建一个一致性GPU服务器。CXL 3.0允许每个主机支持多达16个加速器,使其成为用于GPU的标准一致性互连。它还增加了点对点(P2P)通信、多级交换和最多4,096个节点的结构。
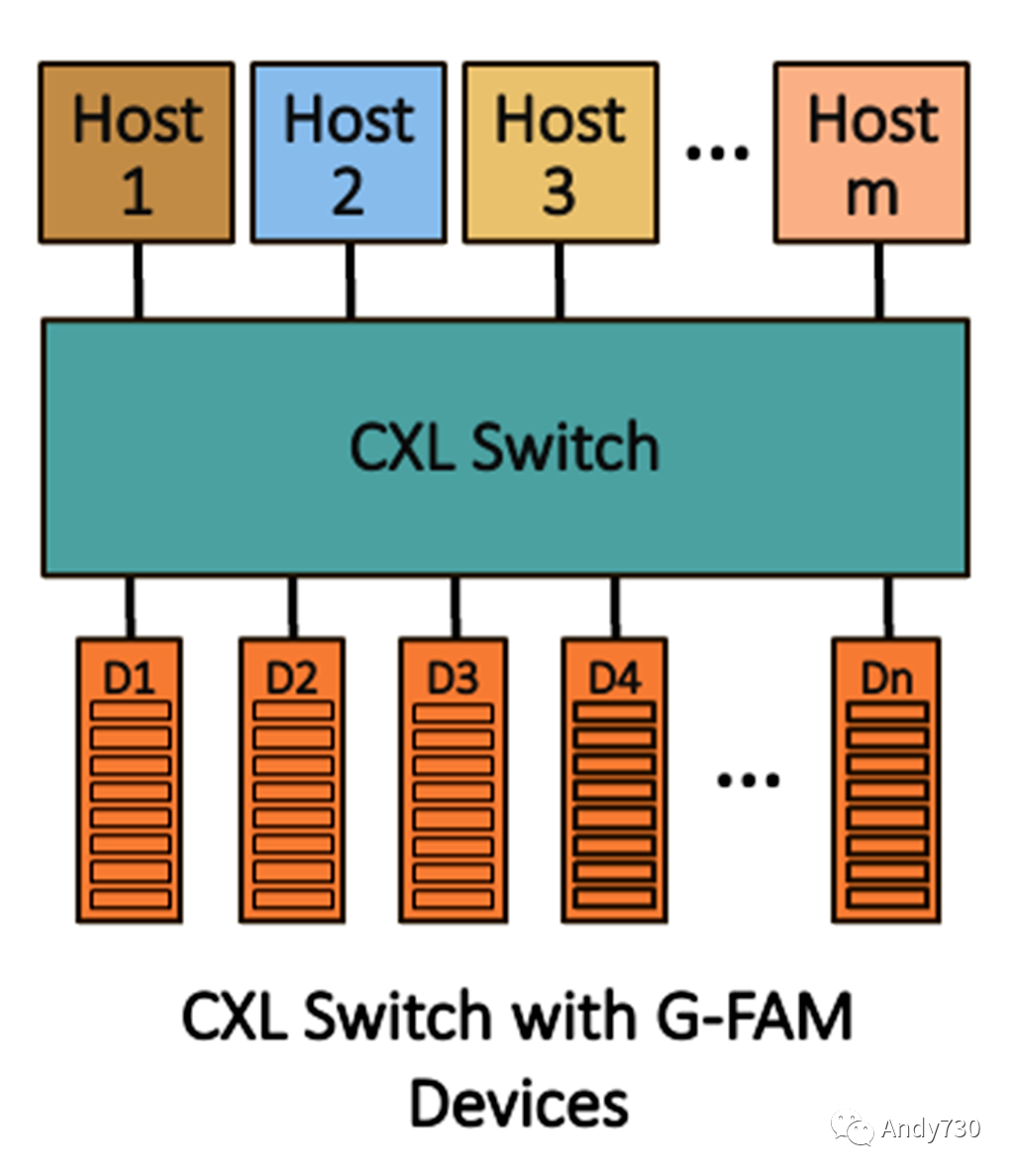
图3. CXL 3.X 共享内存
虽然内存池化可以实现将DRAM灵活分配给服务器,但CXL 3.0可以实现真正的共享内存。共享内存扩展器被称为全局布局附加内存(G-FAM)设备,它允许多个主机或加速器共同共享内存区域。3.0规范还为更精细的内存分配添加了最多8个动态容量(DC)区域。图3展示了一个简单的示例,使用单个交换机将任意数量的主机连接到共享内存。在这种情况下,主机或设备可能会管理缓存一致性。
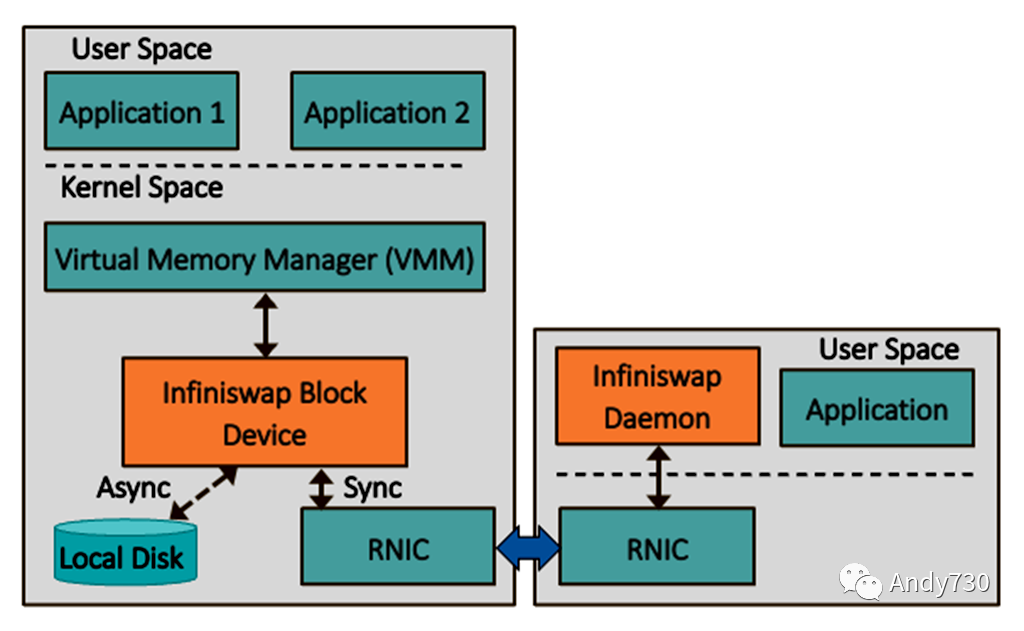
图4. 以太网上的内存交换
然而,为了使加速器可以直接访问共享内存,扩展器必须实现带有回收失效的一致性(HDM-DB),这是3.0规范中新增的。换句话说,要使CXL连接的GPU可以共享内存,扩展器必须实现包含性嗅探过滤器。这种方法引入了潜在的阻塞,因为规范对某些CXL.mem事务强制执行严格的顺序。共享内存结构会出现拥塞,导致不太可预测的延迟和更大的尾延迟的可能性。尽管规范包括QoS遥测功能,基于主机的速率限制是可选的,而且这些能力在实践中尚未得到验证。
RDMA实现远程内存
随着CXL结构在规模和异构性上的增长,性能问题也在扩大。例如,在解耦式机架的每个架子上放置一个交换机是一种优雅的方法,但它会在不同资源(计算、内存、存储和网络)之间的每次事务中增加一个交换机跳数。扩展到集群和更大规模会增加链路延迟的挑战,甚至传输延迟也变得有意义。当多个因素导致延迟超过600纳秒时,系统可能会出现错误。最后,尽管对于小事务而言,加载/存储语义很有吸引力,但对于页面交换或虚拟机迁移等大规模数据传输来说,DMA通常更高效。
最终,一致性域的范围只需要扩展到一定程度。超出CXL的实际限制,以太网可以满足对高容量分离内存的需求。从数据中心的角度来看,以太网的覆盖范围是无限的,超大规模的超大规模企业已经将RDMA-over-Ethernet(RoCE)网络扩展到数千个服务器节点。然而,运营商已经部署了这些大型RoCE网络,用于使用SSD进行存储分离,而不是DRAM。
图3展示了内存RDMA交换的一个示例实现,即密歇根大学的Infiniswap设计。研究人员的目标是将闲置内存在服务器之间进行分离,解决内存未充分利用的问题,也称为闲置。他们的方法使用现成的RDMA硬件(RNIC),避免了应用程序的修改。系统软件使用Infiniswap块设备,对虚拟内存管理器(VMM)而言,它类似于传统存储。VMM将Infiniswap设备处理为交换分区,就像使用本地SSD分区进行页面交换一样。
目标服务器在用户空间运行一个Infiniswap守护进程,仅处理将本地内存映射到远程块设备。一旦内存被映射,读写请求将绕过目标服务器的CPU,使用RDMA进行传输,从而实现零开销的数据平面。在研究人员的系统中,每个服务器都加载了两个软件组件,以便它们可以同时充当请求方和目标方,但这个概念也可以扩展到仅充当目标方的内存设备。
密歇根大学团队使用56Gbps InfiniBand RNIC构建了一个32节点集群,尽管以太网RNIC应该可以完全运行。他们测试了几个内存密集型应用程序,包括运行TPC-C基准测试的VoltDB和运行Facebook工作负载的Memcached。在只有50%的工作集存储在本地DRAM中,其余由网络交换提供支持的情况下,VoltDB和Memcached分别提供了66%和77%的性能,与完整工作集存储在本地DRAM中的性能相比。
通往内存网络的漫长道路
云数据中心成功地将存储和网络功能从CPU分离出来,但主内存的分离仍然难以实现。十年前,Intel的机架规模架构路线图上有关于内存池化的计划,但从未实现。Gen-Z联盟于2016年成立,追求内存为中心的结构架构,但系统设计仅达到了原型阶段。历史告诉我们,随着行业标准增加复杂性和可选功能,它们被大规模采用的可能性降低。CXL提供了沿着架构演进路径的增量步骤,允许技术迅速发展,同时提供未来迭代,承诺实现真正的可组合系统。
从内存扩展中受益的工作负载包括SAP HANA和Redis等内存数据库、Memcached等内存缓存、大型虚拟机,以及必须处理日益增长的大型语言模型的AI训练和推断。当这些工作负载的工作集不能完全适应本地DRAM时,它们的性能会急剧下降。内存池化可以缓解闲置内存问题,这影响了超大规模数据中心运营商的资本支出。微软在2022年3月的一篇论文中详细介绍的研究发现,在高度利用的Azure集群中,高达25%的服务器DRAM被闲置。该公司对不同数量的CPU插槽进行了内存池化建模,并估计它可以将整体DRAM需求减少约10%。
在目前的GPU市场动态下,纯粹采用CXL 3.x结构的情况不太具有说服力,部分原因是GPU市场的动态。目前来自Nvidia、AMD和Intel的数据中心GPU在GPU与GPU之间的通信中实现了专有的一致性互连,同时还使用PCIe与主机进行连接。Nvidia的顶级Tesla GPU已经支持通过专有的NVLink接口进行内存池化,解决了高带宽内存(HBM)的闲置内存问题。市场领导者可能会更青睐NVLink,但它也可能通过共享(serdes)的方式支持CXL。类似地,AMD和Intel未来的GPU可能会在Infinity和Xe-Link之外采用CXL。然而,由于没有公开的GPU支持,对于CXL 3.0先进功能的采用存在不确定性,而对于现有用例转向PCIe Gen6通道速率是无争议的。无论如何,我们预计在2027年之前,CXL 3.x共享内存扩展器将实现大规模出货。
与此同时,多个超大规模数据中心运营商采用RDMA来处理存储分离以及高性能计算。尽管在大规模部署RoCE方面存在挑战,但这些大客户有能力解决性能和可靠性问题。他们可以将这种已部署和理解的技术扩展到新的场景,如基于网络的内存解耦。研究已经证明,连接到网络的容量层在将其应用于适当的工作负载时可以提供强大的性能。
我们将CXL和RDMA视为互补的技术,前者提供最大的带宽和最低的延迟,而后者提供更大的规模。Enfabrica开发了一种称为Accelerated Compute Fabric (ACF)的架构,将CXL/PCIe交换和RNIC功能合并为一个单一的设备。当在多太位(multi-terabit)芯片中实例化时,ACF可以连接一致性本地内存,同时使用高达800G以太网端口跨机箱和机架进行扩展。关键是,这种方法消除了对将来需要多年才能进入市场的高级CXL功能的依赖。
数据中心运营商将采用多种路径来实现内存分离,因为每个运营商有不同的优先事项和独特的工作负载。那些有明确定义内部工作负载的运营商可能会领先,而那些优先考虑公有云实例的运营商可能会更加保守。早期使用者为那些可以解决特定客户最迫切需求的供应商创造了机会。
-
SMART Modular CXL AIC内存扩充卡获CXL联盟认证2025-02-14 1134
-
内存扩展CXL加速发展,繁荣AI存储2024-08-18 7423
-
什么是内存语义?CXL是如何划分语义的2024-04-08 12097
-
利用CXL技术重构基于RDMA的内存解耦合2024-02-29 8275
-
多网协同发展探讨2023-11-10 594
-
陈海波:OpenHarmony技术领先,产学研深度协同,生态蓬勃发展2023-11-06 1027
-
访问CXL 2.0设备中的内存映射寄存器2023-05-25 3915
-
数字产业协同发展的意义和作用2023-04-24 6988
-
DirectCXL内存分解原型设计实现2022-11-15 1345
-
CXL内存协议介绍2022-11-01 3208
-
基于CXL的直接访问高性能内存分解框架2022-09-23 2044
-
一文解析CXL系统架构2022-09-14 3789
-
一窥CXL协议2022-09-09 4592
-
“5G+车联网”的车路协同发展模式促进智能汽车与智慧城市协同发展2020-10-28 3679
全部0条评论

快来发表一下你的评论吧 !
