

AI芯片 CPU+xPU的异构方案全面解析
人工智能
描述
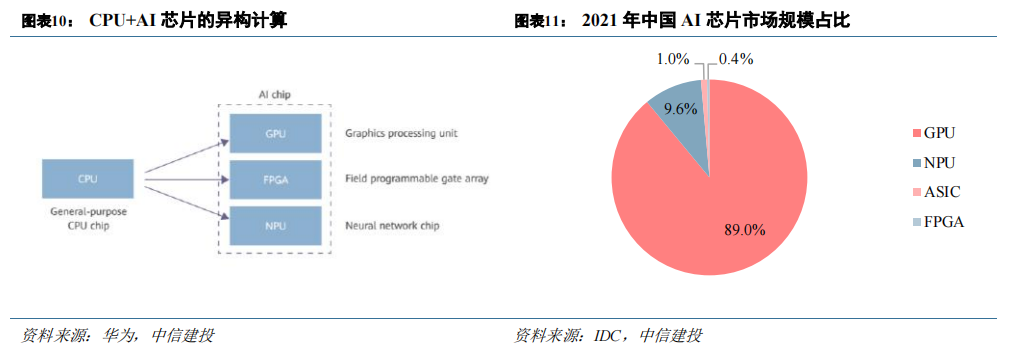
本文来自“算力大时代,AI算力产业链全景梳理(2023)”,从广义上讲,能运行AI 算法的芯片都叫AI 芯片。CPU、GPU、FPGA、NPU、ASIC 都能执行AI 算法,但在执行效率层面上有巨大的差异。CPU 可以快速执行复杂的数学计算,但同时执行多项任务时,CPU 性能开始下降,目前行业内基本确认CPU 不适用于AI 计算。
CPU+xPU 的异构方案成为大算力场景标配,GPU为应用最广泛的 AI 芯片。目前业内广泛认同的AI 芯片类型包括GPU、FPGA、NPU 等。由于 CPU 负责对计算机的硬件资源进行控制调配,也要负责操作系统的运行,在现代计算系统中仍是不可或缺的。GPU、FPGA 等芯片都是作为 CPU 的加速器而存在,因此目前主流的 AI计算系统均为 CPU+xPU 的异构并行。CPU+GPU 是目前最流行的异构计算系统,在 HPC、图形图像处理以及AI 训练/推理等场景为主流选择。IDC 数据显示,2021 年中国 AI 芯片市场中,GPU 市占率为 89%。
在GPU 问世以后,NVIDIA 及其竞争对手 ATI(被 AMD 收购)一直在为他们的显卡包装更多的功能。2006 年 NVIDIA 发布了 CUDA 开发环境,这是最早被广泛应用的 GPU 计算编程模型。CUDA 将 GPU 的能力向科学计算等领域开放,标志着 GPU 成为一种更通用的计算设备 GPGPU(General Purpose GPU)。NVIDIA 也在之后推出了面向数据中心的 GPU 产品线。
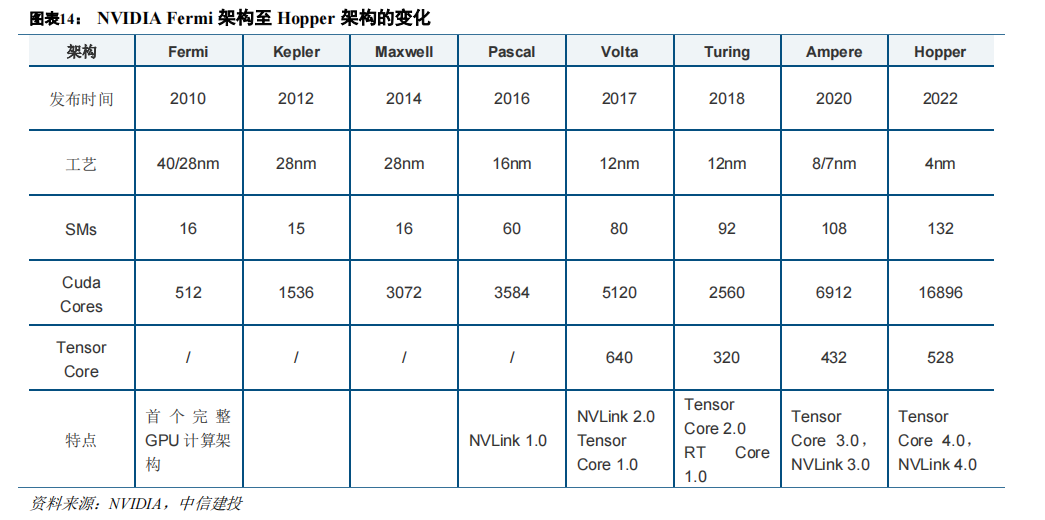
GPU 性能提升与功能丰富逐步满足 AI 运算需要。2010 年 NVIDIA 提出的 Fermi 架构是首个完整的 GPU计算架构,其中提出的许多新概念沿用至今。Kepler 架构在硬件上拥有了双精度计算单元(FP64),并提出 GPUDirect 技术,绕过 CPU/System Memory,与其他 GPU 直接进行数据交互。Pascal 架构应用了第一代 NVLink。
Volta 架构开始应用 Tensor Core,对 AI 计算加速具有重要意义。简要回顾 NVIDIA GPU 硬件变革历程,工艺、计算核心数增加等基础特性的升级持续推动性能提升,同时每一代架构所包含的功能特性也在不断丰富,逐渐更好地适配 AI 运算的需要。
AI 的数据来源广泛,GPU 逐渐实现对各类数据类型的支持。依照精度差异,算力可从 INT8(整数类型)、FP16(半精度)、FP32(单精度)、FP64(双精度)等不同维度对比。AI 应用处理的数据包括文字、图片或视频,数据精度类型差异大。对于数据表征来讲,精度越高,准确性越高;但降低精度可以节省运算时间,减少成本。
总体来看,精度的选择需要在准确度、成本、时间之间取得平衡。目前许多 AI 模型中运行半精度甚至整形计算即可完成符合准确度的推理和训练。随着架构的迭代,NVIDIA GPU 能支持的数据类型持续丰富,例如 Turing架构 T4 开始支持 INT8,Ampere 架构 A100 的 Tensor Core 开始支持TF32。
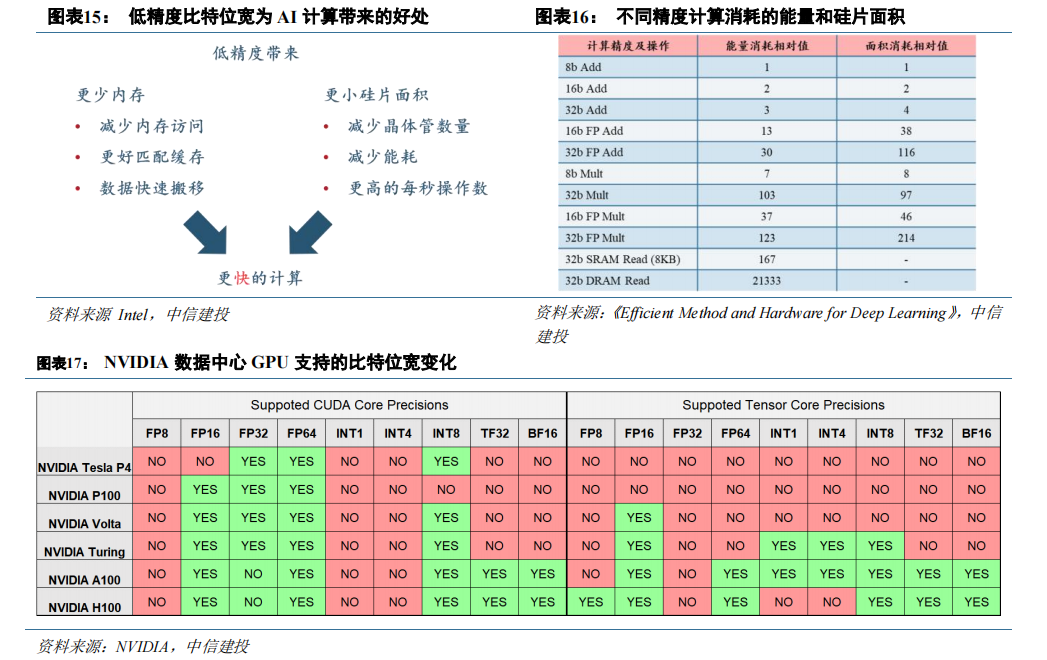
均衡分配资源的前提下,处理低精度的硬件单元数量更多,表现更高的算力性能。GPU 作为加速器得到广泛应用一定程度上得益于它的通用性,为了在不同精度的数据类型上具有良好的性能,以兼顾 AI、科学计算等不同场景的需要,英伟达在分配处理不同数据类型的硬件单元时大体上保持均衡。因为低精度数据类型的计算占用更少的硬件资源,同一款 GPU 中的处理低精度数据类型的硬件单元的数量较多,对应计算能力也较强。以V100 为例,每个 SM 中 FP32 单元的数量都为 FP64 单元的两倍,最终 V100 的 FP32 算力(15.7 TFLOPS)也近似为 FP64(7.8 TFLOPS)的两倍,类似的规律也可以在各代架构旗舰 P100、A100 和 H100 中看到。
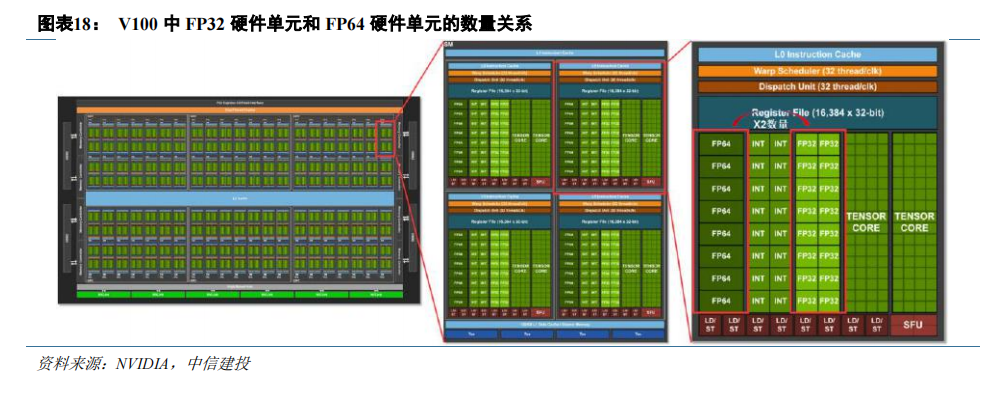
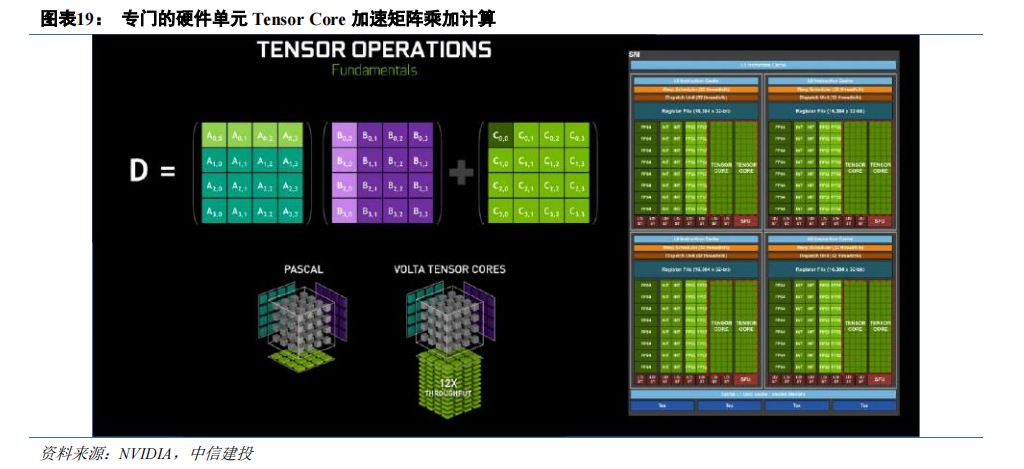
GPU 引入特殊硬件单元加速 AI 的核心运算环节。矩阵-矩阵乘法(GEMM)运算是神经网络训练和推理的核心,本质是在网络互连层中将大矩阵输入数据和权重相乘。矩阵乘积的求解过程需要大量的乘积累加操作,而 FMA(Fused Multiply–accumulate operation,融合乘加)可以消耗更少的时钟周期来完成这一过程。传统 CUDACore 执行 FMA 指令,硬件层面需要将数据按寄存器->ALU->寄存器->ALU->寄存器的方式来回搬运。2017 年发布的 Volta 架构首度引入了 Tensor Core(张量核心),是由 NVIDIA 研发的新型处理核心。根据 NVIDIA 数据,Volta Tensor Core 可以在一个 GPU 时钟周期内执行 4×4×4=64 次 FMA操作,吞吐量是 Pascal 架构下 CUDA Core的12 倍。
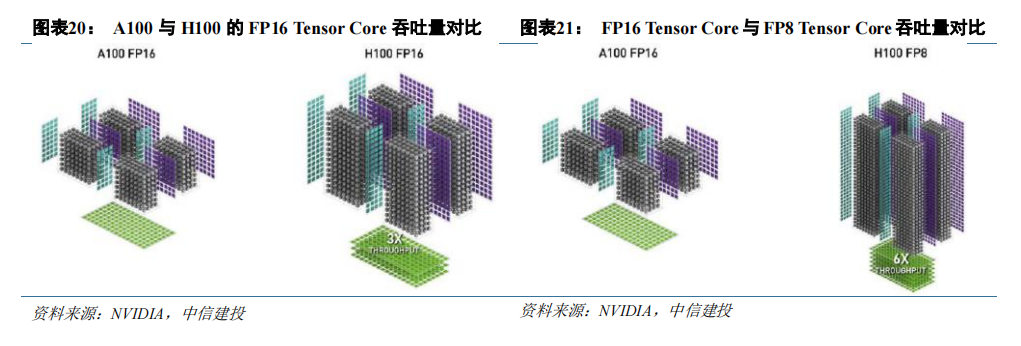
Tensor Core 持续迭代提升其加速能力。Volta 架构引入 Tensor Core 的改动使 GPU 的 AI 算力有了明显提升,后续在每一代的架构升级中,Tensor Core 都有比较大的改进,支持的数据类型也逐渐增多。以 A100 到 H100为例,Tensor Core 由 3.0 迭代至 4.0,H100 在 FP16 Tensor Core 的峰值吞吐量提升至 A100 的 3 倍。同时,H100Tensor Core 支持新的数据类型 FP8,H100 FP8 Tensor Core 的吞吐量是 A100 FP16 Tensor Core 的 6 倍。
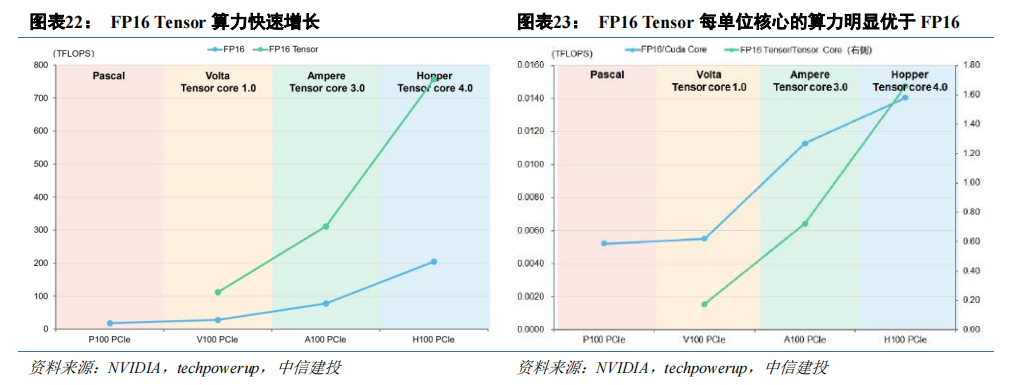
Tensor Core 加速下,低精度比特位宽的算力爆发式增长,契合 AI 计算需要。Tensor Core 的应用使算力快速、高效增长,选取 Pascal 至 Hopper 架构时期每一代的旗舰数据中心显卡,对比经 Tensor Core 加速前后的 FP16算力指标可以得到:(1)经 Tensor Core 加速的 FP16 算力明显高于加速之前。(2)每单位 Tensor core 支持的算力明显高于每单位 Cuda Core 支持的算力。同时,Tensor Core 从 2017 年推出以来首先完善了对低精度数据类型的支持,顺应了 AI 发展的需要。
数据访问支配着计算能力利用率。AI 运算涉及到大量数据的存储与处理,根据 Cadence 数据,与一般工作负载相比,每台 AI 训练服务器需要 6 倍的内存容量。而在过去几十年中,处理器的运行速度随着摩尔定律高速提升,而 DRAM 的性能提升速度远远慢于处理器速度。目前 DRAM 的性能已经成为了整体计算机性能的一个重要瓶颈,即所谓阻碍性能提升的“内存墙”。除了性能之外,内存对于能效比的限制也成为一个瓶颈,Cadence数据显示,在自然语言类 AI 负载中,存储消耗的能量占比达到 82%。
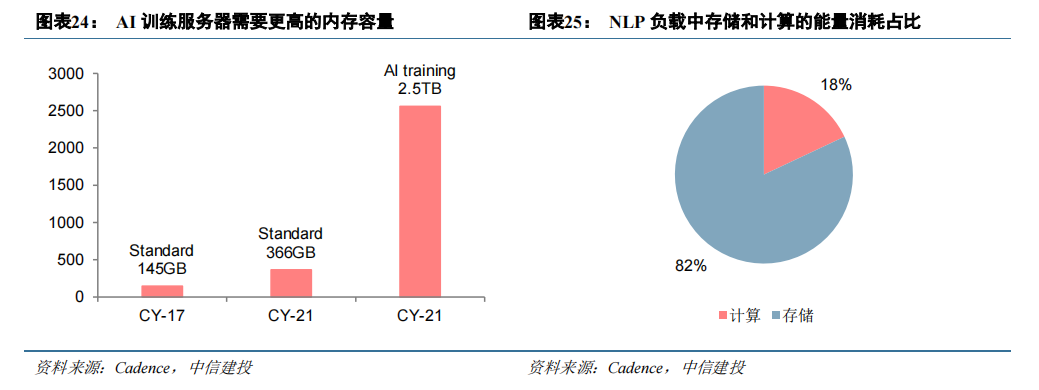
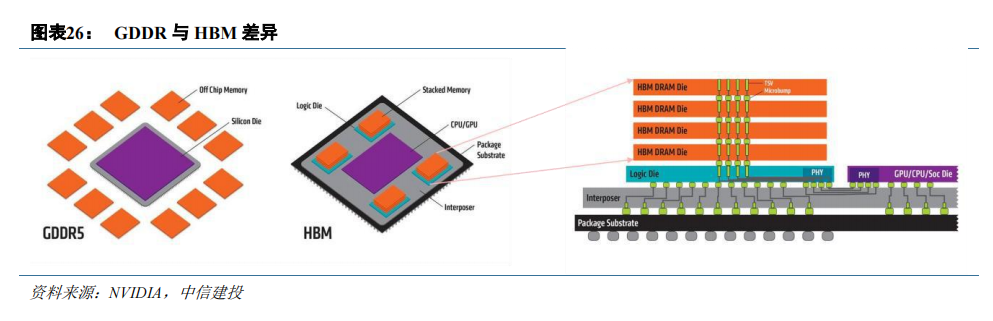
GPU 采用高带宽 HBM 降低“内存墙”影响。为防止占用系统内存并提供较高的带宽和较低的延时,GPU均配备有独立的的内存。常规的 GDDR 焊接在 GPU 芯片周边的 PCB 板上,与处理器之间的数据传输速率慢,并且存储容量小,成为运算速度提升的瓶颈。HBM 裸片通过 TSV 进行堆叠,然后 HBM 整体与 GPU 核心通过中介层互连,因此 HBM 获得了极高的带宽,并节省了 PCB 面积。目前,GDDR 显存仍是消费级 GPU 的行业标准,HBM 则成为数据中心 GPU 的主流选择。
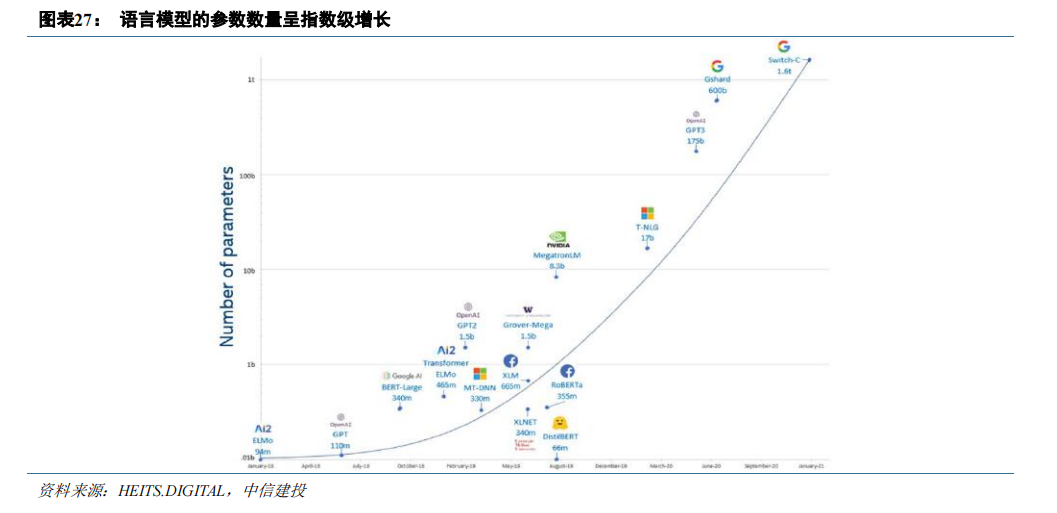
硬件单元的改进与显存升级增强了单张 GPU 算力的释放,然而,随着 Transformer 模型的大规模发展和应
用,模型参数量呈爆炸式增长,GPT-3 参数量达到了 1750 亿,相比 GPT 增长了近 1500 倍,预训练数据量更是
从 5GB 提升到了 45TB。大模型参数量的指数级增长带来的诸多问题使 GPU 集群化运算成为必须:
(1)即使最先进的 GPU,也不再可能将模型参数拟合到主内存中。
(2)即使模型可以安装在单个 GPU 中(例如,通过在主机和设备内存之间交换参数),所需的大量计算操作也可能导致在没有并行化的情况下不切实际地延长训练时间。根据 NVIDIA 数据,在 8 个 V100 GPU 上训练一个具有 1750 亿个参数的 GPT-3 模型需要 36 年,而在 512 个 V100 GPU 上训练需要 7 个月。
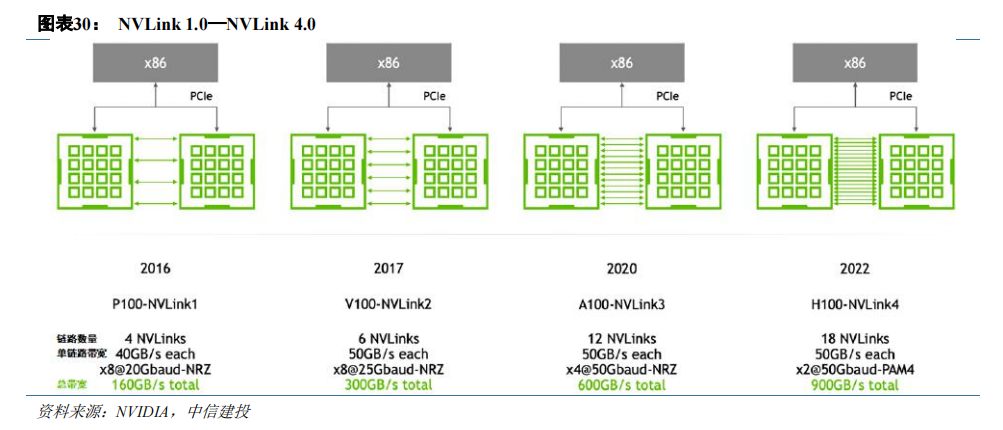
NVIDIA 开发 NVLink 技术解决 GPU 集群通信。在硬件端,GPU 之间稳定、高速的通信是实现集群运算所必须的条件。传统 x86 服务器的互连通道 PCIe 的互连带宽由其代际与结构决定,例如 x16 PCIe 4.0 双向带宽仅为 64GB/s。除此之外,GPU 之间通过 PCIe 交互还会与总线上的 CPU 操作竞争,甚至进一步占用可用带宽。
NVIDIA 为突破 PCIe 互连的带宽限制,在 P100 上搭载了首项高速 GPU 互连技术 NVLink(一种总线及通讯协议),GPU 之间无需再通过 PCIe 进行交互。
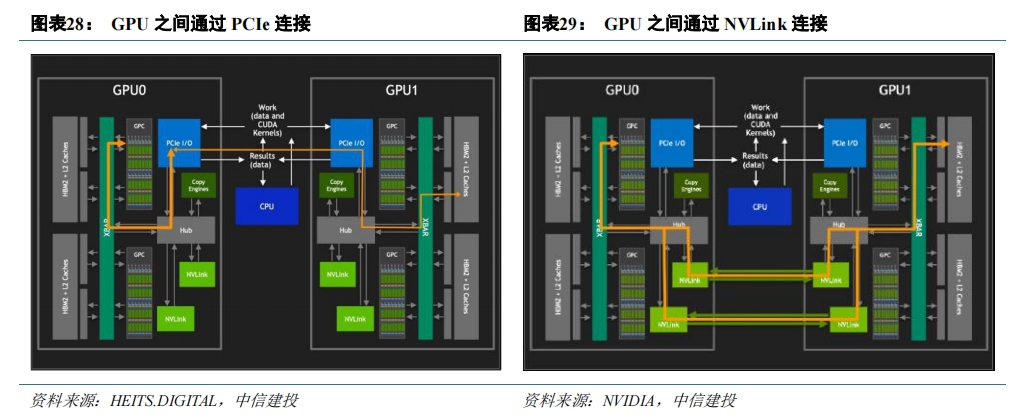
NVLink 继续与 NVIDIA GPU 架构同步发展,每一种新架构都伴随着新一代 NVLink。第四代 NVLink 为每个 GPU 提供 900 GB/s 的双向带宽,比上一代高 1.5 倍,比第一代 NVLink 高 5.6 倍。
NVDIA 开发基于 NVLink 的芯片 NVSwitch,作为 GPU 集群数据通信的“枢纽”。NVLink 1.0 技术使用时,一台服务器中的 8 个 GPU 无法全部实现直接互连。同时,当 GPU 数量增加时,仅依靠 NVLink 技术,需要众多数量的总线。为解决上述问题,NVIDIA 在 NVLink 2.0 时期发布了 NVSwitch,实现了 NVLink 的全连接。
NVSwitch 是一款 GPU 桥接芯片,可提供所需的 NVLink 交叉网络,在 GPU 之间的通信中发挥“枢纽”作用。借助于 NVswitch,每颗 GPU 都能以相同的延迟和速度访问其它的 GPU。就程序来看,16 个 GPU 都被视为一个 GPU,系统效率得到了最大化,大大降低了多 GPU 系统的优化难度。
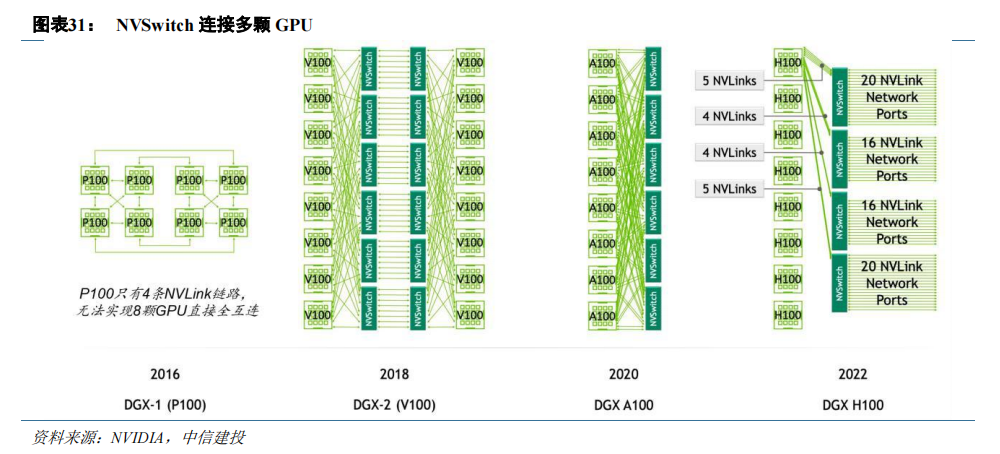
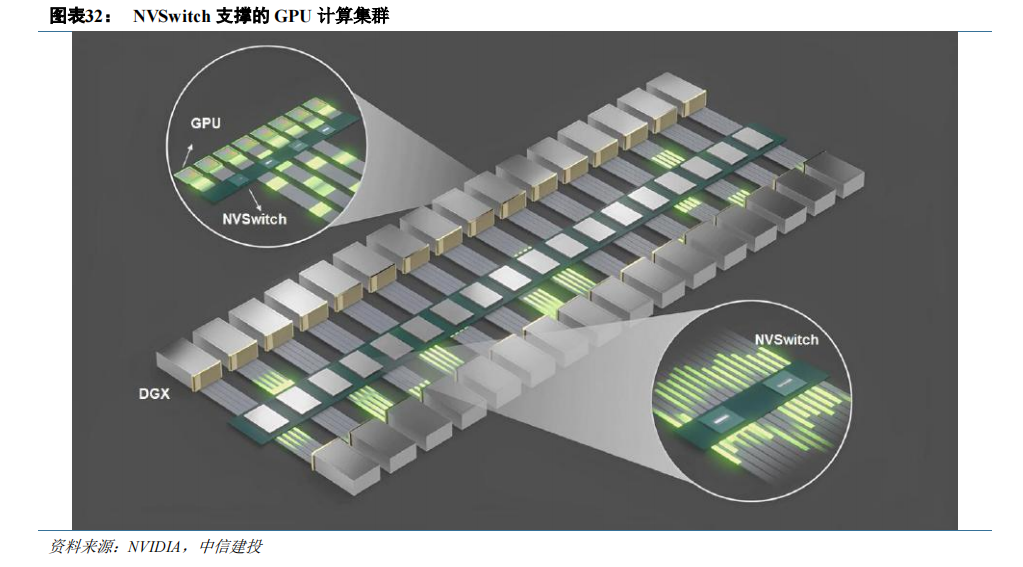
通过添加更多 NVSwitch 来支持更多 GPU,集群分布式运算得以实现。当训练大型语言模型时,NVLink网络也可以提供显著的提升。NVSwitch 已成为高性能计算(HPC)和 AI 训练应用中不可或缺的一部分。
编辑:黄飞
-
AI时代的xPU“心脏”与“神经”:xPU硅后验证难点与应对方案2026-06-16 2164
-
安谋科技重磅发布!以超域架构定义全新XPU,为智能计算提供“核芯动力”2021-08-28 4882
-
异构集成的三个层次解析2020-07-07 3156
-
HSA----CPU+GPU异构系统架构详解2021-02-03 2939
-
异构计算的前世今生2021-12-26 3355
-
超异构芯片TDA4内核解析2022-12-09 2443
-
北极雄芯开发的首款基于Chiplet异构集成的智能处理芯片“启明930”2023-02-21 1545
-
异构计算场景下构建可信执行环境2023-08-15 1133
-
高通拓展终端人工智能 异构AI平台为AI手机带来AI引擎2018-07-20 1511
-
Intel付得起xPU的巨额尾款吗?2020-11-24 2648
-
芯片巨头们的“异构”大战已经开启2021-01-08 2416
-
Chiplet加剧XPU之争,英伟达为何迟迟不出手?2023-06-15 2653
-
CPU+xPU的异构方案解析 cpu和gpu有啥区别2023-09-03 3756
-
异构专用AI芯片的黄金时代2023-12-04 1719
-
商汤大装置发布基于DeepLink的异构混合调度方案2025-08-05 1337
全部0条评论

快来发表一下你的评论吧 !
