

基于INTEL 11代芯片Tiger Lake 在OPENVINO AI 套件上所开发之LUS.AI即时互动智慧医疗解决方案
描述
提案动机
在肺部的检查上,超音波相较X光或电脑断层扫描,具有无放射性,操作相对方便的优点。但传统超音波具有不可携性,病患须至医疗院所才能做超音波检查,对于偏远或医疗资源匮乏的地区,难以利用。
且超音波在判读上,具有难解释性的缺点,对于超音波影像的判读,往往训练时间长,判读时间也较久,医生与医生间也存在着主观判读的歧异性,在医病沟通上,对于判读过后的结果,医师也较难与病患说明。
基于上述的两项缺点 (不可携性、难解释性),本团队希望能训练AI模型,协助医师做肺部超音波影像的判读,并利用OpenVINO具有最佳化与压缩模型的优点,协助我们最大化利用现有的硬体资源做模型的推论,让AI模型在肺部超音波的判读上更快、更即时,达到即时辅助判读的效果。
另我们也配合可携式的超音波探头做测试,希望往后也能在院外做超音波检测,达到远距医疗的愿景。
解决方案
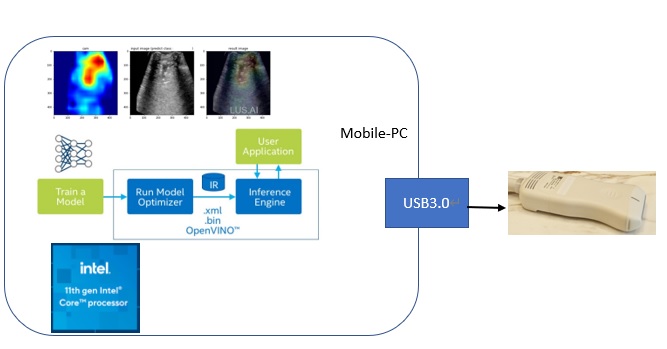
LUS.AI 团队开发的移动式智能超音波方案,只要带著一台笔电和手持超音波机,不用插电源就可以到处移动为病患做检查。
本团队开发用的笔电规格为 Intel® Core™ i7 1165G7 处理器 2.8 GHz,搭配显卡 Intel® Iris Xe Graphics,16G RAM。简单来说这就是一台 Intel 第11代 CPU 的笔电,平常可以作一般使用的用途,比如开视讯会议、分享讨论案例等等,但如果搭配触控笔也能方便对超音波影像做标注。
除了在笔电上导入AI功能可以轻松达成外,即使今天到了收讯不良的地区,因为AI在笔电里面跑,所以不需要额外的网路连线,模型推论也非常迅速,能够即时提供医师第一时间的判读参考。
(目前完成的只有AI肺部异常侦测的模组)
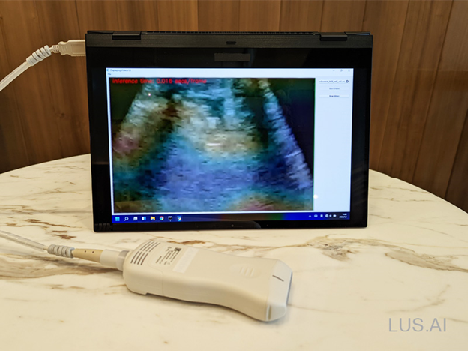
<图一、 智慧超音波解决方案>
成果说明
AI模型的设计训练是使用 Tensorflow 2.6 完成,OpenVINO 则是衔接后续模型布署和推论的部分。以下是本文分享的大钢,分为四个项目,2 3 4 项 是比较少文章提到的部分,将无私与大家分享:
- OpenVINO™ 基础开发流程
- 不同精度模型在不同装置上的推论速度比较
- 不得已的 CAM
- OpenVINO™ Integration with TensorFlow* (new)
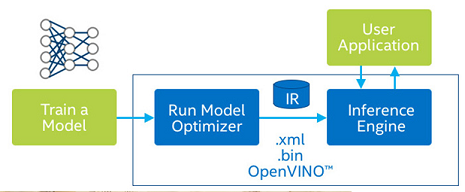
<图二、OpenVINO™ 的应用架构,资料来源:Intel >
OpenVINO™ 基础开发流程
如 图二 所示,最左边是训练好的模型,蓝色的部分是 OpenVINO™ 的区块,推论引擎与应用程式作互动。
- 模型开发的部分,我们选用 Tensorflow 作框架,因为Tensorflow生态系是比较完整的,许多工具都有支援。最后将模型存档为 Saved Model 格式。
- OpenVINO™ 在安装上,是比较复杂的部分,网路上有许多文章介绍如何安装,但可能因为 OpenVINO™ 持续改版的关系,所以建议还是参考官网的安装说明,是最没问题的方式。
- 其实如果不想在本机安装的话,其实还有两个选择,都可以完成 Model Optimizer 的步骤(简称 MO)。这个MO步骤,将会把模型转换为 FP32 或 FP16 的 IR 档案(.xml .bin),也就是OpenVINO™的模型档案格式:
[第一个选择]是申请使用 OpenVINO DevCloud 来进行MO,线上的虚拟机器里面都已经安装好相关的工具,很方便上传模型后做转换模型(可以参考 MakerPRO的介绍)。
[第二个选择]是使用 Google CoLab 的环境(Ubuntu 18.04)安装OpenVINO™使用,有一个优点就是:安装失败可以重新开一个 notebook重头开始。最后将转换完成的 IR 档下载下来即可。参考这篇文章(里面有CoLab连结),但连结中的这个范例安装OpenVINO™的版本比较旧,建议参考官方的安装说明作点小修改。
- 推论引擎 Inference Engine 的部分(简称 IE),是正式应用程式要跑的部分,借由它来读取 IR 档,并选择在 OpenVINO™ 支援的硬体上作快速的模型推论。这部分若想体验,其实也可以使用 CoLab notebook 先做测试,只需要pip install openvino就可以使用OpenVINO™的 IE推论引擎了,详细也可参考这篇文章(内有CoLab连结)。
- 使用者界面 User Application,我们使用 pyQt5 来建立 windows的简单程式。其中影像显示、模型推论、热图显示是使用两个平行处理完成。由于模型推论速度已经很快(几十个毫秒),所以速度较慢的反而是资料的前处理、后处理和UI的部分,这方面要加速的话,也许可以做更多的平行化的设计,让应用程式可以更为即时(real-time)。
不同精度模型在不同装置上的推论速度比较
这边使用 OpenVINO™ 的 benchmark 工具,来评估模型推论引擎 (IE) 搭配不同装置的效能,这台笔电包含了两个可用的装置(CPU、iGPU)。
以下 图三 的评估只有考虑到模型推论的部分,资料前处理、后处理、UI等都没有纳入计算。浅蓝色为 MO 转换的 FP16 的模型,深蓝为 FP32 的模型。我们可以看到FP16模型在 GPU 的效能为 CPU 的两倍,同质整合CPU和GPU的模式(MULTI)有更佳的表现。但其实 CPU装置 没有支援 FP16 的资料输入,所以效能比直接使用 FP32 略差。异质整合(HETERO)模式,将模型拆分为 CPU执行的部分和 GPU执行的部分,仅供参考。
最后,其实在 iGPU 上就已经足够快了,我们的应用目标是包含前处理、后处理、UI 达到 30 FPS。所以我们决定使用 高精度(FP32)模型在 iGPU 上做推论,然后将 CPU 留做 前处理、后处理、UI 的运算上使用。
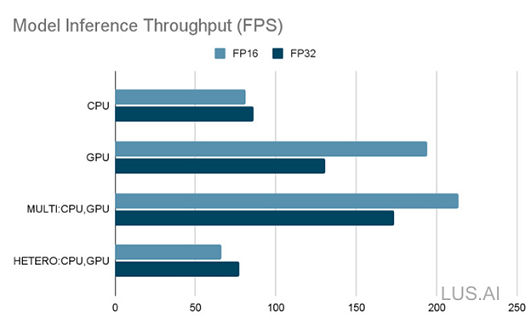
<图三、推论引擎使用不同装置的效能,每秒推论几个样本(FPS) >
不得已的 CAM
CAM (Class Activation Mapping) 是作为分类依据的可视化方法,也是 图一 相片中的热区图。CAM(没有Grad) 的实作上,我们参考了这篇范例(pneumonia-classification)。如果有使用 DevCloud 的话,也可以在 Sample Applications 当中找到这范例。
但这个范例方法没有办法计算模型的梯度(Gradient),所以没有办法算出比较好的热图(Grad-CAM等)。分析无法得到模型梯度是因为 OpenVINO™ 专注在模型布署和推论上(Forward pass);所以如果要监看梯度等进阶需求,可能还是得回到 Tensorflow 的功能来实现。
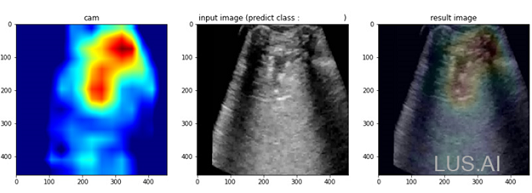
<图四、Tensorflow 实现的 Grad-CAM 热区显示比较精确>
OpenVINO™ Integration with TensorFlow* (new)
因为要做到 Grad-CAM,所以需要进阶地使用到 Tensorflow。但如何让 Tensorflow 可以使用到Intel的内显(iGPU) 就需要用到:OpenVINO™ integration with TensorFlow (GitHub repo) 。它跟上面提到的 OpenVINO™ 运作方式上不太一样,这个工具提供的是一个 整合的后端(backend) 让 Tensorflow 可以直接使用到 Intel® 的装置 CPU、iGPU、VPU,如图五所示。
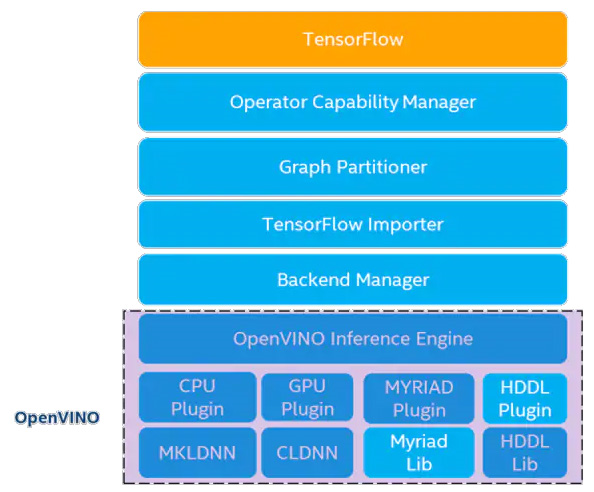
<图五、OpenVINO™ Integration with TensorFlow 应用架构,资料来源:Intel >
在笔者撰写此篇的时候,它在 Windows 上还是 Beta版 (其他作业系统已经是正式版了)。但我们还是依照 互动安装指引 来安装这个工具,如 图六 所示,Windows版 当前只支援 Python3.9。

<图六、互动安装指引,资料来源:Intel >
在使用上,出奇的简单!如 图七 的简单范例,在定义完 后端(backend) 之后,就继续正常使用 Tensorflow 。
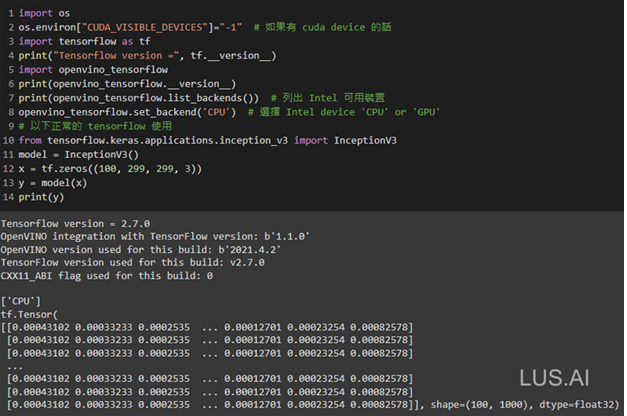
结论
目前尝试的 OpenVINO™ Integration with TensorFlow 在windows上的beta版,后端可以看出有使用到新一代的 Intel oneAPI 的 oneDNN,在硬体的整合运用上很值得期待。虽然目前 openvino_tensorflow 在我们模型上的推论效能为 25.27 FPS 表现较为普通,但期待日后正式版的发布,届时若能与 iGPU 整合得更好,想必会有更佳的体验。
#LUS.AI 团队
►场景应用图
►产品实体图

►展示板照片


►方案方块图
►Intel 11 Gen Tiger Lake Spec.
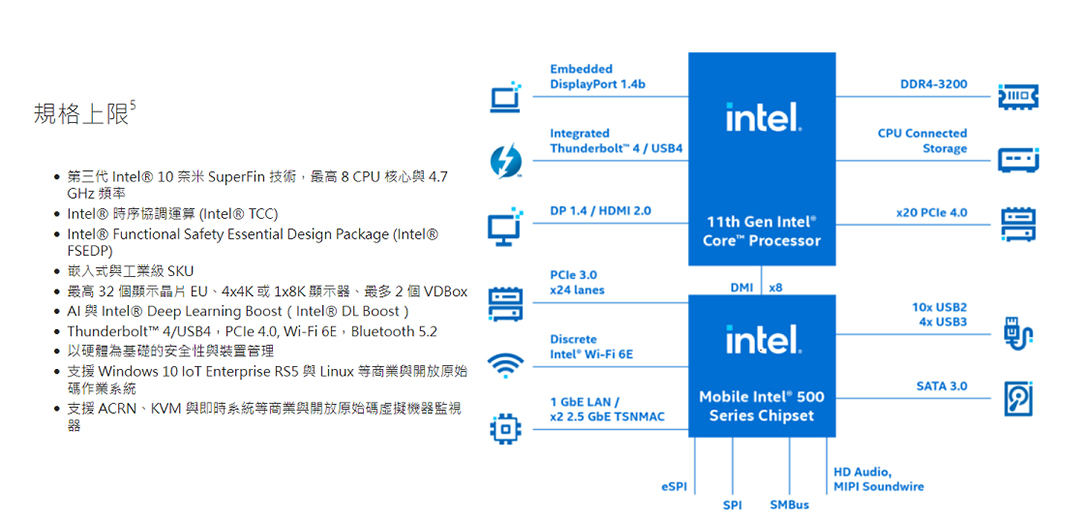
►核心技术优势
1. 高效能 CPU 与 GPU 结合 AI 和深度学习功能,能够在各种用途整合工作负载,例如电脑数值控制 (CNC) 机器、即时控制、人机界面、工具应用、医疗成像与诊断(在超音波这类用途),以及需要具备 AI 功能高分辨率 HDR 输出的其他用途。
2. 显示芯片、媒体与显示器引擎可输出达 4x4k60 HDR 或 2x8K60 SDR,搭载两个 VDBOX,可以用 1080p 和每秒 30 个影格的方式,解码超过 40 个传入的视讯串流。引擎支援各种用途,例如数位招牌与智能零售(包括专为分析强化的 AI),以及具备推断功能的电脑视觉,适用于网路视讯录制器或机器视觉与检测这类用途。
3. 利用在 CPU 向量神经网路指令集 (VNNI) 执行的 Intel® DL Boost,或是利用在 GPU (Int8) 执行的 8 位元整数指令集,即可实现 AI 与推断加速。
4. 全新的物联网导向软硬体,实现了需要提供及时效能的各种应用。适用于可程式化逻辑控制器与机器人这类用途的快速周期时间与低延迟。
►方案规格
* 频率最高可达 4.4 GHz
*搭载达 96 个 EU 的 Intel® Iris® Xe 显示芯片
*最高支援 4x4k60 HDR 或 2x8K60 SDR
*Intel® Deep Learning Boost
*最高 DDR4-3200 / LPDDR4x-4267
*Thunderbolt™ 4/USB4 与 PCIe
* 4.0 (CPU)
*Intel® Time Coordinated Computing(在精选的 SKU)
*频内 ECC 与延伸温度(在精选的 SKU)
*Intel® Functional Safety Essential Design Package (Intel® FSEDP)(在精选的 SKU)
-
AI医疗不能盈利,谁的锅?2018-12-01 0
-
AI芯片格局最全分析 精选资料分享2021-07-23 0
-
标准系统开发套件:九联科技 Unionpi Tiger 开发板套件介绍2022-04-21 0
-
新一代AI ISP视频处理模组,对标Hi3559A、Hi3519A平台性能2022-06-07 0
-
嘉楠勘智K510开发板简介——高精度AI边缘推理芯片及应用2022-11-22 0
-
新思科技发布业界首款全栈式AI驱动型EDA解决方案Synopsys.ai2023-04-03 0
-
Intel首次亮相Tiger Lake晶圆 基于增强版10nm+工艺2020-01-14 2148
-
英特尔下一代移动平台Tiger Lake的AI性能提升2020-02-26 2650
-
Intel桌面酷睿技术发展,已跳过11代将推出12代2020-10-28 2018
-
10nm变相登陆桌面:Intel+戴尔打造Tiger Lake 11代酷睿台式机2020-12-07 1906
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8分类模型2023-05-05 1053
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8目标检测模型2023-05-12 1314
-
AI爱克斯开发板上使用OpenVINO加速YOLOv8目标检测模型2023-05-26 1242
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8-seg实例分割模型2023-06-05 1005
全部0条评论

快来发表一下你的评论吧 !
