

航天宏图卫星数据进一步提升建筑属性估计精度
描述
一、比赛背景
International Geoscience and Remote Sensing Symposium (IGARSS)是IEEE地球科学和遥感学会的旗舰会议。2023年7月16 ,第46届IGARSS大会在美国帕萨迪纳成功召开,发布了IEEE GRSS DFC 2023国际遥感数据融合大赛的结果和论文。来自中国、美国、瑞典、日本、印度、德国、比利时、泰国、土耳其等全球25个国家和地区的700余支队伍,经过为期三个月的初赛、决赛激烈角逐,航天宏图PIESAT-AI团队在“建筑物实例分割与屋顶细粒度分类”与“面向多任务学习的城市建筑物提取与高度估计”双赛道,均获得第一名的好成绩。
在城市规划与建筑设计领域,建筑屋顶类型和高度是非常重要的元素之一,影响到建筑外观、功能、通风、采光、保温、防水等多个方面。正确的提取建筑的基底、高度、以及屋顶类型(如坡顶、平顶、圆顶、尖顶等),有助于高效地完成实景三维重建,为土地利用、空间分析、数字孪生等方面提供重要的参考数据,同时也可加强环境监测和资源管理,促进城市可持续发展。此外,在城市灾害和救援中,这些信息的准确性也很关键。当城市遭受地震、洪水等自然灾害时,往往会造成建筑物屋顶的破损和崩塌,如果能通过卫星影像快速地确定灾区的屋顶状况,可以为救援行动提供重要的信息和指导。
传统的建筑检测、屋顶分类、高度估计方法往往依赖于地面实地勘测,因为受天气、光照、时间等因素的影响,存在效率低、成本高、精度差等问题,已无法满足现代需求。huang等人[1] 验证代表性的单阶段 (SOLOv2)、两阶段 (Mask-RCNN、Cascade Mask RCNN) 和基于查询 (QueryInst) 的方法,这些方法在类似赛道一的屋顶检测分割数据集 UBC [1] 中无法实现理想的性能。zheng[2]、xing[3]等人提出联合语义信息提高单一高度估计任务的学习,但与高度信息完全匹配的语义标签却难以获得,影响了高度估计的准确性。
基于光学遥感图像的细粒度屋顶检测、分类,高度估计技术主要面临三个挑战:
不同屋顶类型、建筑物高度(低,中,高)的样本呈现不均匀的长尾分布,如图1.1-1.3所示;
在遥感图像中很多建筑属于弱小目标不易分辨;
不同屋顶类别之间视觉特征模糊难以区分;
部分标注数据中,建筑轮廓和高度掩码(nDSM大于0部分)不对齐,如图1.4所示;
实际场景中的云雾干扰、建筑阴影、相互遮挡等,降低了识别精度。
SAR雷达影像因为波长更长,可以穿透云层、雾、灰尘、霾和烟,克服了遥感光学影像受天气、光照、时间等干扰的不足。我们尝试将遥感可见光影像和SAR雷达影像这两种模态数据与深度学习算法相结合,研发全新的多模态建筑基底、屋顶类型、高度估计方法,实现更高精度的建筑属性自动提取方法。

▲图 1.1 IEEE GRSS DFC 2023数据集[4]的12种屋顶类型
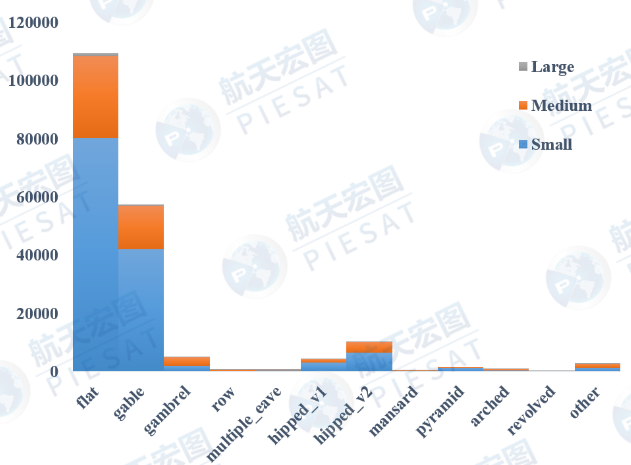
▲图1.2 IEEE DFC 2023数据集,各种屋顶类别实例分布。灰、橙和蓝色分别代表大、中、小实例

▲图1.3 IEEE GRSS DFC 2023数据集建筑高度分布情况,超过50m的约占2%
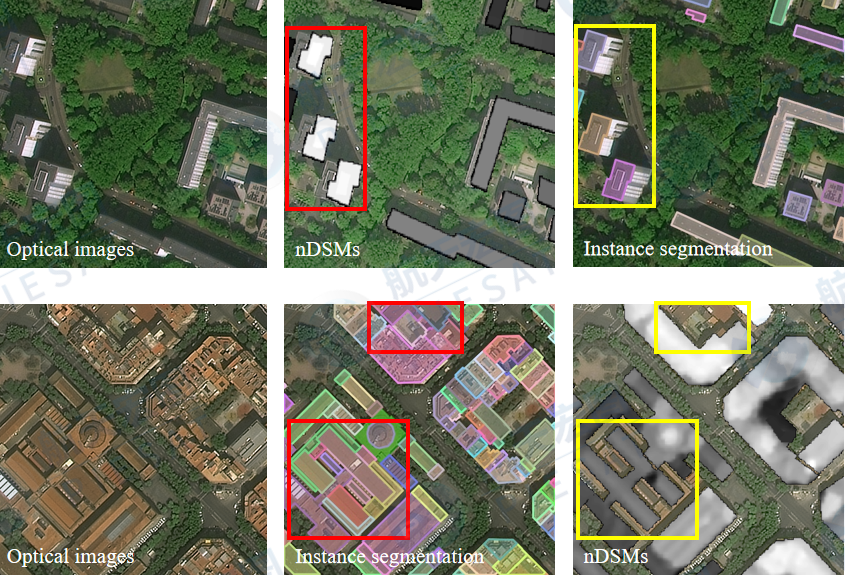
▲图1.4 IEEE GRSS DFC 2023数据集,建筑物轮廓和nDSM图像不对齐样例
二、屋顶检测分类方法
基于遥感多模态AI技术,航天宏图团队使用自监督预训练、双主干网络多模态表征、Modified Copy-Paste数据增强、实例分割多模型融合,抗长尾损失函数SeesawLoss等方法来应对上述挑战并实现高精度的建筑屋顶检测和分类的方法,在DFC 2023赛道一测试集以mAP50 50.6% 取得第一名成绩。
本赛道遥感图像上的建筑屋顶具有目标特征微弱,不同屋顶间的特征边界模糊、不同类别屋顶数量极度不平衡等特点。为了提高模型区分目标前景和背景的能力从而提高模型的召回率,系统架构采用经典的端到端two stage实例分割算法Cascade Mask-RCNN[5]作为基础框架, 网络结构如图2.1所示。相比于one stage的实例分割算法,two stage的RPN结构帮助模型能够更加细致的理解图特征,获得更多前景proposal从而更加有力的应对微弱特征目标。同时为了进一步加强模型特征提取能力,我们基于CBnetV2首次提出将目前的SOTA算法ConvNeXtV2进行dual-ConvNeXtV2结构的构建。为了应对训练数据存在的长尾分布场景,我们将定位损失GIoULoss与分类损失SeesawLoss相结合,有效地缓解了训练过程中占比较小类别的梯度会被头部类别淹没的问题。
“优秀”的模型初始化策略在整个模型训练优化过程中占据了举足轻重的地位,可以让模型赢在起跑线。本次比赛为了进一步提高模型的收敛质量,提供高模型最终的表现,我们未使用以往的Imagenet22K预训练模型,而是在训练模型前对主干网络进行了自监督模型预训练,自监测预训练策略选用与ConvNeXtV2较为契合的FCMAE。
本赛道用于训练的数据集包含数据样本数量为3000+,为了更好的提升模型的泛化能力,我们在数据增强策略上进行创新。基于实例分割提点利器Simple Copy-Paste基础上,我们提出Modified Copy-Paste,从粘贴实例角度喜欢数据增强环节,进一步增强数据增强能。并结合大尺度的图像输入,随机翻转,随机旋转等数据策略大大提升模型泛化到其它场景能力。
模型推理阶段输入光学影像模态和SAR模态,输出建筑物屋顶的检测外接矩形框、屋顶类别及屋顶的多边形轮廓,模型具体表现如图2.2所示。
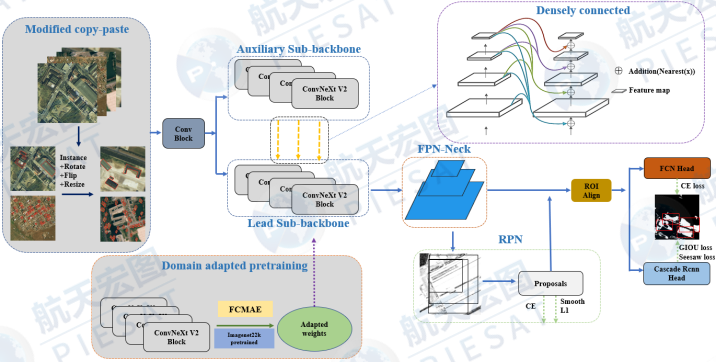
▲图2.1 多模态屋顶检测识别网络结构图
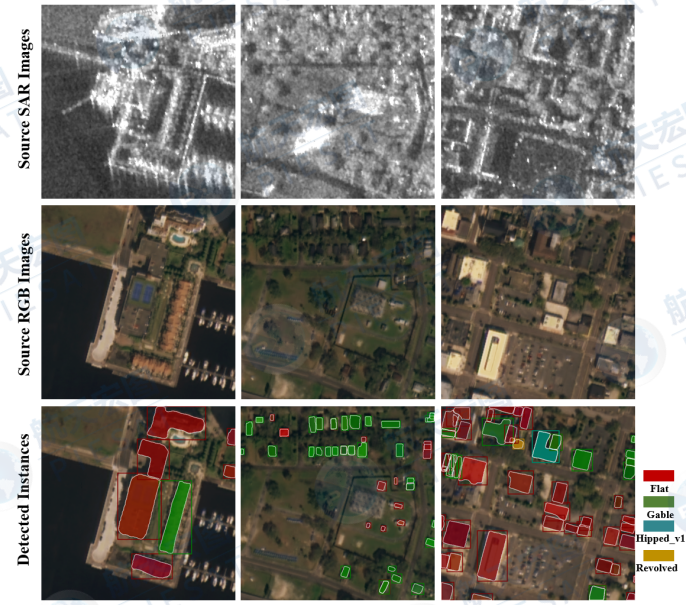
▲图2.2 模型推理结果样例
2.1. 具体方法
屋顶检测与细粒度分类模型训练流程如图2.3所示。第一步进行ConvNeXtV2遥感影像域自适应预训练;第二步使用Modified copy-paste等数据加强进行检测器模型训练;第三步对模型进行去Modified copy-paste的微调;第四步进行SWA训练。接下来文章会根据训练的每个Step为线索,对所涉及的技术细节及创新性方案进行详细阐述。
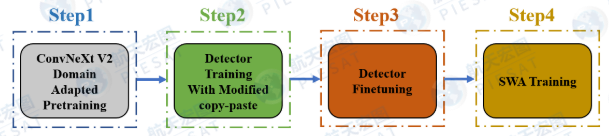
▲图2.3 屋顶检测与细粒度分类模型流程
2.1.1 Step1: 自监督预训练
模型通过自监督预训练在训练正式开始前快速的适应场景数据,为后面的训练打下坚实的基础。该部分主要技术点在ConvNeXtV2及FCMAE。
ConvNeXtV2[6]:该模型采用全卷积架构,模型通过全局特征聚合、特征标准化、特征校准等策略使得模型有着强悍的性能,一经提出就成为CV领域各大竞赛的宠儿。本次项目沿用ConvNeXtV2模型的整体架构,未作修改。
FCMAE[7]:该方法是对于全卷积架构模型进行MIM预训练的方式,该方法引入稀疏卷积实现让卷积神经网络能够通过图像遮挡部位的图像还原来对图像数据进行建模,从而让模型对遥感屋顶建筑该领域的数据进行训练前的domain adaptation。从图2.4中可以看出,模型对与masked部分能通过自己的理解进行一定的合理性还原。

▲图2.4 FCMAE方法预训练过程数据破坏及重建可视化,original:数据原图,masked:被破坏后输入模型的数据形态,reconstruction:模型重建后的数据形态。
2.1.2 Step2: 模型训练
模型的训练过程采用丰富的数据增强策略对构建起的检测器进行训练,我们使用的检测器是经典的Cacsace Mask Rcnn架构,并为了对抗长尾分布的训练数据集采用seesaw loss对分类头进行监督。这一部分我们主要侧重的技术点Dual-Backbone、Modified Copy-Paste及损失的使用。
Dual-Backbone: 方案参考CBNet[8]网络结构,设计出两个稠密连接的Dual-ConvNeXtV2结构,如图2.5所示。两个子主干网络均为ConvNeXtV2-base网络,二者通过稠密连接的方式增强高维度低维度信息的融合及两个子主干网络间特征信息的融合。
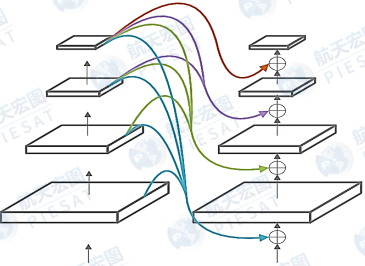
▲图2.5. Dual-Backbone的网络结构
Modified Copy-Paste: 在检测器训练过程中,有效的数据增强策略能够提高检测器的鲁棒性。Simple Copy-Paste[9]是实例分割检测器的重要数据增强手段之一。Modified Copy-Paste对Simple Copy-Paste剪切下的实例进行旋转、翻转、缩放后再粘贴到目标图片数据上合成新的数据。因为遥感数据的特殊性,俯视拍摄的数据不会因为实例的旋转、翻转而破坏整个场景数据的语义信息。合成数据可见图2.6所示。

▲图2.6 Modified Copy-Paste合成数据
SeesawLoss[10]: 降低检测器在长尾分布数据上性能的一个关键原因是施加在尾部类别上的正负样本梯度的比例是不均衡的,而 SeesawLoss 通过动态地抑制尾部类别上过量的负样本梯度,同时补充对误分类样本的惩罚,显著改进了尾部类别的分类准确率,进而提升检测器在长尾数据集上的整体性能。
2.1.3 Step3: 模型微调
训练过程中,丰富的数据增强策略是把双刃剑,它不仅可以扩充数据集增强模型的泛化能力也可以从一定程度导致整体训练数据的domain shift,从而影响模型最终的能力。为了最大程度利用数据增强策略,弱化其负面影响,我们在实验中发现,经过多轮次训练后的模型可以通过关闭数据增强并使用小学习率进行微调来达到进一步提高精度的效果,精度提升效果具体可见表2.1。
2.1.4 Step4: SWA训练
SWA(Stochastic Weights Averaging)[11]: 机器学习模型权重一般会收敛到一组最佳权重集合的边缘部分,而使用随机权重平均可以收敛到这个最佳权重集合的更中心位置,一般具有更好的平均表现和泛化水平。该策略可以对训练好的模型进行稳定,有助于比赛最终模型效果的稳定。
2.2. 实验结果
表2.1 给出消融实验结果。我们在DFC2023赛道1复赛成绩 mAP50 50.6% 是通过不同超参数和骨干网下训练的多个强大检测器进行WSF 融合而获得的。从实验中,可以发现SeesawLoss带来0.18的提升;SCP可以在此基础上提点0.008;主干网络变为ConvNeXtV2并使用自监督域自适应预训练又有0.007个点的提升;SWA和MCP的使用分别有0.009和0.02的提升。但是, SAR 数据并没有增强模型性能,如表 2.1.* 所示,与单一光学模态输入相比,精度下降0.072,主要原因是提供的SAR数据没有与光学影像准确的对齐。

▲表2.1.消融实验结果,其中CMR,SCP,MCP,db,DAP,CNV2分别是Cascade Mask-Rcnn,Simple Copy-Paste,Modified Copy-Paste,DUal-Backbone,Domain Adapted Pretraining,ConvNeXtV2, Weighted Segmentation Fusion的缩写
三、建筑高度估计
基于单张卫星影像的建筑提取和高度估计是基于规则大规模城市3D重建和空间分析的关键数据。PopNet[2] 使用双解码器机制,同时 SCENet[3] 引入了分离-合并机制和注意力机制,用于同时处理语义分割和高度估计的任务。但是这些方法都强依赖于对齐的语义标签和高度标签。
为了应对前述挑战部分标注数据建筑轮廓和高度掩码不对齐的问题,以及建筑高度的长尾分布问题,我们提出了一种联合建筑层级提取和高度估计的HGDNET方法。在DFC 2023赛道2数据集上的大量实验和消融研究证明了该方法在建筑高度估计(δ1:0.8012)、实例提取(AP50:0.7730)方面的优越性以及最终平均得分0.7871在测试阶段排名第一, 部分效果如图3.1所示。

▲图3.1. 高度估计的效果图,(a)是光学影像,(b)(c)分别是真值和模型预测结果,最后一列(d)diff=pred-gt,颜色越深差异越大,红色和绿色分别表示相对真值,预测结果偏高和偏低
通过综合调研与实验对比,最后我们提出了一种新的双解码器高度估计模型(Height-hierarchy Guided Dual-decoder Network,HGDNet),集成了辅助分支-建筑物高度层级的分割分支,以缓解不同高度建筑物直接高度估计的困难,网络结构如图3.2 所示。其中,高度估计的分支(左)直接通过像素级推理,逐像素回归nDSM值;而辅助分支则进行离散的建筑高度层级分类,即通过对nDSM值进行聚类,将建筑分为不同高度层级,以生成新合成的建筑分割指导图。高度估计分支和辅助分支(建筑高度层级分类)之间形成隐式约束,促进模型的训练速度与最终模型对高度的估计的准确性。

▲图3.2. 高度估计网络HGDNet的结构
3.1. 具体方法
基于高度层次引导的双解码高度估计网络HGDNet的架构如图3.2所示。采用ConvNeXt V2-Base作为编码器模块提取遥感影像的主干特征,同时采用了双解码器的结构分别进行高度估计与建筑数高度层级分割的联合估计任务,不同分支的解码器对不同任务分别进行回归学习。解码器采用UperNet [12]的结构, 通过上-下的通路和跳跃连接实现不同尺度的特征融合。两个分支共享同样的主干网络权重进行特征提取,从而不同分支通过不同方向的损失进行权重的回归迭代,共同约束模型学习,加速训练速度,提高训练精度。
3.1.1 高度估计分支
由于建筑物高度分布不均匀,见图1.2, 集中在0-50m,甚至0-10m。因此,我们对nDSM 使用对数函数进行处理,使其分布更接近正态。然后,执行最大归一化以促进更快的模型收敛。标准化 nDSM 计算如下:
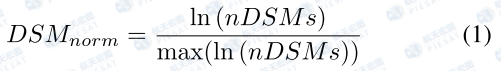
采用UperNet 作为解码器框架。通过低层、高层的神经通路和横向连接增强了主干的多尺度特征。所有增强的特征都被上采样到一定的规模并随后融合,作为高度估计的最终特征。此外,在高度分支的末尾添加了一个额外的 1 通道卷积层和一个 Sigmoid 层进行最后的激活。
3.1.2 辅助分支-建筑高度层级分割
为了提高高度估计的准确性,在网络中加入了一个额外的高度分层分割分支。在此分支中,使用与高度估计分支相同的 UPerNet 解码器。然而,融合特征只需要一个 n 通道卷积层,其中 n 等于高度层次的数量。我们将 nDSM 划分为几个离散的高度层级,而不是直接使用仅具有单个类的实例分割标签,这有助于通过不同的高度层级加强模型的特征提取能力。通过分析nDSM的分布并使用聚类算法,将nDSM分为n类作为建筑高度层级的类别标签, 这些离散的类别标签用于指导建筑物高度的估计,解决了通用方法中与nDSM对齐的语义标签不足的问题。
3.1.3 加权损失函数
建筑高度层级分割分支是一个n分类的学习,使用交叉熵(CE)损失,而高度分支是一个像素级的回归分支,所以使用SmoothL1损失,由于两个损失的量级不同,在两个分支中应用不同的损失权重。最终损失函数如下:
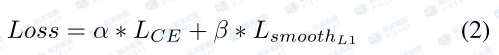
3.1.4 高度的校正过程
在训练中,辅助分支由于与高度估计分支共享主干网络、特征,二者通过隐式约束互相促进,但辅助分支作用不至于此。在推理过程,辅助分支还有额外的作用。辅助分支学习的是建筑高度层级的分类结果,这也就意味着辅助分支分类为0的地方即地面区域(无高度),于是,利用辅助分支结果对HGDNet估计的建筑高度进行后处理,将辅助预测为地面类型的且高度预测不到一定阈值的高度修正为0。
3.2 实验结果
3.2.1 对比实验
在HGDNet的高度层次分割分支中,建筑物根据高度分为地面、低、中、高4个层次类别。如表3.1所示,通过与其他模型的对比,在DFC中验证集上,HGDNet取得了δ1=0.7966的最好结果,比次优的SCENet高0.02。
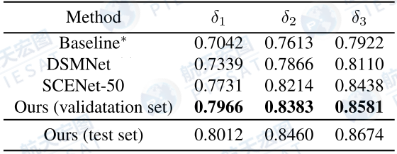
▲表3.1 DFC 2023赛道2测试集上高度估计的结果,其中Baseline是官方发布的基于Deeplabv3的回归结果
3.2.2 消融实验
表3.2,3.3分别对HGDNet的分层分割结果分支和高度特征表征主干网络进行了消融实验,可以发现ConvNeXtV2 Base是相对最好的特征提取器,尤其是增加了建筑层级分割分支进一步提升了分割精度,同结构下,没有建筑层级分割分支的模型精度(δ1)要低6个百分点。

▲表3.2 HGDNet增加分层分割结果的对比实验

▲表3.3 HGDNet的高度估计特征表征主干网络对比实验
总结与展望
经过大量的实验,我们利用光学卫星图像作为输入,采用域自适应预训练和双主干特征提取,构建了一个鲁棒的建筑屋顶实例分割模型。同时,我们提出了一种高度层次引导的双解码高度估计网络HGDNet用于建筑高度属性估计。此外,基于我们提出的两类高性能算法模型,我们可以准确地提取得到建筑物轮廓、类别、高度、地理位置等多种属性信息,来高效构建建筑实体,实现大规模的城市级三维建模。我们基于单张影像的完成的三维城市规则化建模结果如图4.1,4.2所示。该技术能够在城市规划、灾害防护、城市孪生等等多方面应用中发挥重要作用,让城市实景三维建设更高效、让信息更直观被人所理解。
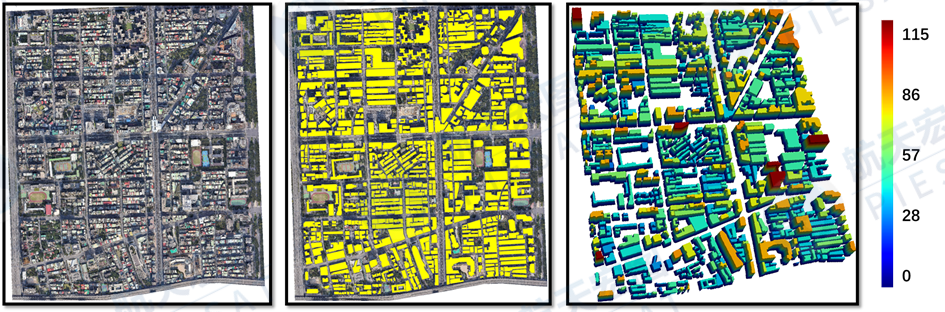
▲图4.1. 语义分析成果示意图
(从左至右:光学卫星影像、建筑轮廓、建筑高度估计)
▲图4.2基于单张卫星影像的快速建模video demo
航天宏图“女娲星座”首发4颗InSAR卫星于2023年3月30日成功发射。一期工程计划于2023年至2025年共发射38颗业务星,包括28颗雷达卫星组成的雷达遥感星座和10颗光学遥感卫星,将提供更丰富、更高分辨率的卫星数据。本次DFC2023比赛,光学影像与SAR影像之间的错位和异构性给多模数据融合带来了困难。后续,我们将结合航天宏图卫星数据进一步提升建筑属性估计精度,利用光学影像和SAR数据进行多模态融合更多的探索。
审核编辑:彭菁
-
手机射频元件如何进一步集成?2019-08-27 3500
-
进一步理解量子力学经典 多方面丰富相关图表2020-08-02 2290
-
如何进一步加强对RFID的安全隐私保护?2021-05-26 2417
-
如何让计算机视觉更进一步接近人类视觉?2021-06-01 1853
-
怎样去进一步提高NTP的授时精度呢2021-11-01 2841
-
如何进一步提高1302精度?2022-12-29 1467
-
STM8在待机模式如何进一步降低功耗?2023-10-12 731
-
请问如何进一步减小DTC控制系统的转矩脉动?2023-10-18 869
-
对进一步规范招投标行为的几点思考2009-12-24 925
-
NI产品整合Windows 7,进一步提升应用的效能与传输量2009-12-22 1454
-
ST进一步扩大抗辐射航天模拟芯片产品阵容2011-09-29 1152
-
松下将进一步提升超级工厂产能,电池产量可到54 GWh2020-01-02 6408
-
5G进一步助力社会经济的数字转型2020-07-13 993
-
导航系统随着技术的进一步提升,在智能交通的发展势头强劲2020-08-19 1583
-
通过展频进一步优化EMI2024-09-04 756
全部0条评论

快来发表一下你的评论吧 !
