

大语言模型“书生·浦语”多项专业评测拔头筹
描述
最近,AI大模型测评火热,尤其在大语言模型领域,“聪明”的上限被不断刷新。
“SuperCLUE是由创立于2019年的CLUE学术社区最新发布的中文通用大模型综合性评测基准,包含SuperCLUE-Opt客观题测试、SuperCLUE-Open主观题测试、SuperCLUE-LYB琅琊榜用户投票的匿名对战测试三大基准组成。为更好地反映国内大模型与国际领先大模型间的差距和优势,SuperCLUE选取了多个国内外有代表性的可用模型进行评测,同时由于其数据集保密性高,对大模型来说是‘闭卷考试’,减少了模型训练数据混入评测数据的可能性。此外,SuperCLUE还通过自动化评测方式测试不同模型效果,可一键对大模型进行评测,相对更客观。” “书生·浦语”:不仅善于考试,还是开源大模型中的佼佼者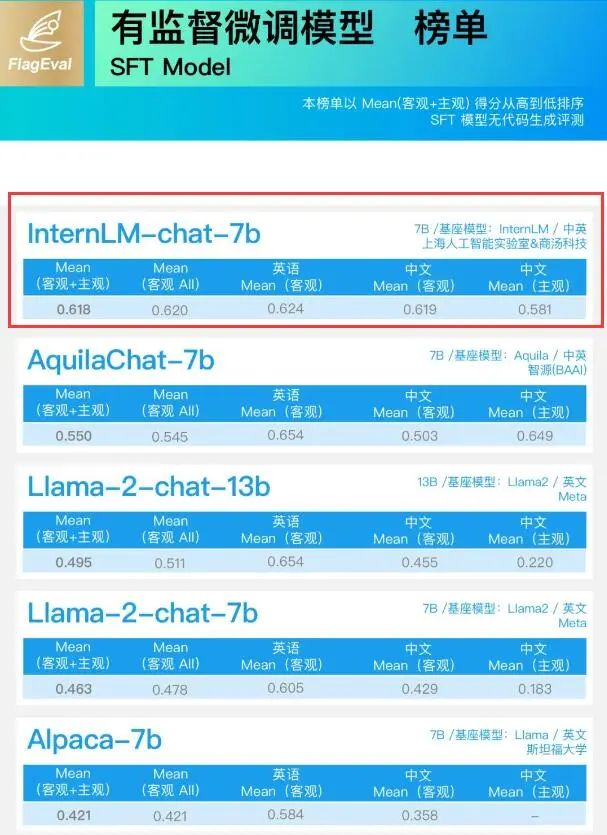

 作为SuperCLUE综合性三大基准之一,SuperCLUE-Opt评测基准每期有3700+道客观题(选择题),由基础能力(10个子任务)、中文特性能力(10个子任务)、学术专业能力(50+子任务)组成,采用封闭域测试方式。
相比第二名ChatGLM2-6B,InternLM-chat-7B主要在学术专业方面取得较大领先,同时全面领先于第三名Baichuan-13B-Chat。
作为SuperCLUE综合性三大基准之一,SuperCLUE-Opt评测基准每期有3700+道客观题(选择题),由基础能力(10个子任务)、中文特性能力(10个子任务)、学术专业能力(50+子任务)组成,采用封闭域测试方式。
相比第二名ChatGLM2-6B,InternLM-chat-7B主要在学术专业方面取得较大领先,同时全面领先于第三名Baichuan-13B-Chat。
商汤与上海AI实验室等联合打造的大语言模型“书生·浦语”(InternLM)也表现出色,分别在智源FlagEval大语言模型评测8月排行榜和中文通用大模型综合性评测基准SuperCLUE 7月评测榜两项业内权威大模型评测榜单中获得优异成绩。 “FlagEval是知名人工智能新型研发机构北京智源人工智能研究院推出的大模型评测体系及开放平台。FlagEval大模型评测体系构建了“能力-任务-指标”三维评测框架,可视化呈现评测结果,总计600+评测维度,包括22个主观、客观评测数据集,84433道评测题目。除知名的公开数据集 HellaSwag、MMLU、C-Eval外,FlagEval还集成了包括智源自建的主观评测数据集Chinese Linguistics & Cognition Challenge (CLCC),北京大学等单位共建的词汇级别语义关系判断、句子级别语义关系判断、多义词理解、修辞手法判断评测数据集。”
“SuperCLUE是由创立于2019年的CLUE学术社区最新发布的中文通用大模型综合性评测基准,包含SuperCLUE-Opt客观题测试、SuperCLUE-Open主观题测试、SuperCLUE-LYB琅琊榜用户投票的匿名对战测试三大基准组成。为更好地反映国内大模型与国际领先大模型间的差距和优势,SuperCLUE选取了多个国内外有代表性的可用模型进行评测,同时由于其数据集保密性高,对大模型来说是‘闭卷考试’,减少了模型训练数据混入评测数据的可能性。此外,SuperCLUE还通过自动化评测方式测试不同模型效果,可一键对大模型进行评测,相对更客观。” “书生·浦语”:不仅善于考试,还是开源大模型中的佼佼者
“书生·浦语”,是商汤科技、上海AI实验室联合香港中文大学、复旦大学及上海交通大学打造的大语言模型,具有千亿参数,在包含1.8万亿token的高质量语料上训练而成。
今年6月,“书生·浦语”联合团队曾选取20余项评测进行检验,包括全球最具影响力的四个综合性考试评测。结果显示,“书生·浦语”在综合性考试中表现突出,在多项中文考试中超越ChatGPT。(详情可参考「AI考生今日抵达,商汤与上海AI实验室等发布“书生·浦语”大模型」报道) 7月,“书生·浦语”正式开源70亿参数的轻量级版本InternLM-7B。(https://github.com/InternLM/InternLM)
后续又推出升级版对话模型InternLM-Chat-7B v1.1,成为首个具有代码解释能力的开源对话模型,能根据需要灵活调用Python解释器等外部工具,解决复杂数学计算等任务的能力显著提升。
此外,该模型还可通过搜索引擎获取实时信息,提供具有时效性的回答。
在北京智源人工智能研究院FlagEval大语言模型评测体系8月最新排行榜中, “InternLM-chat-7B”和“InternLM-7B”分别在监督微调模型(SFT Model)榜单、基座模型(Base Model)榜单中取得第一和第二名。
“InternLM-chat-7B”还刷新中英客观评测记录。 「什么是“基座模型”、“有监督微调模型”?」 基座模型(Base Model)是经过海量数据预训练(Pre-train)得到的,它具备一定的通用能力,比如:GPT-3。 有监督微调模型(SFT Model)则是经过指令微调数据(包含了各种与人类行为及情感相关的指令和任务的数据集)训练后得到的,具备了与人类流畅对话的能力,如:ChatGPT。 普遍的观点认为,基座模型在很大程度上决定了微调模型的能力。 因此,FlagEval大语言模型评测体系针对基座模型的评测主要从“提示学习评测”和“适配评测”两方面进行;针对有监督微调模型的评测则从“复用针对基座模型的客观评测” 进一步增加“引入主观评测”。 此次两个榜单中,“InternLM-chat-7B”和“InternLM-7B”均表现出优异的综合性能,超越备受关注的Llama2-chat-13B/7B和Llama2-13B/7B。 特别在SFT Model测试中,InternLM-chat-7B中文能力大幅领先同时,英文能力也与对手保持在相近水平,展现出更强的实用性能。
SuperCLUE评测从基础能力、专业能力、中文特性能力三个不同维度对国内外通用大模型产品进行评价,考察大模型在70余个任务上的综合表现。
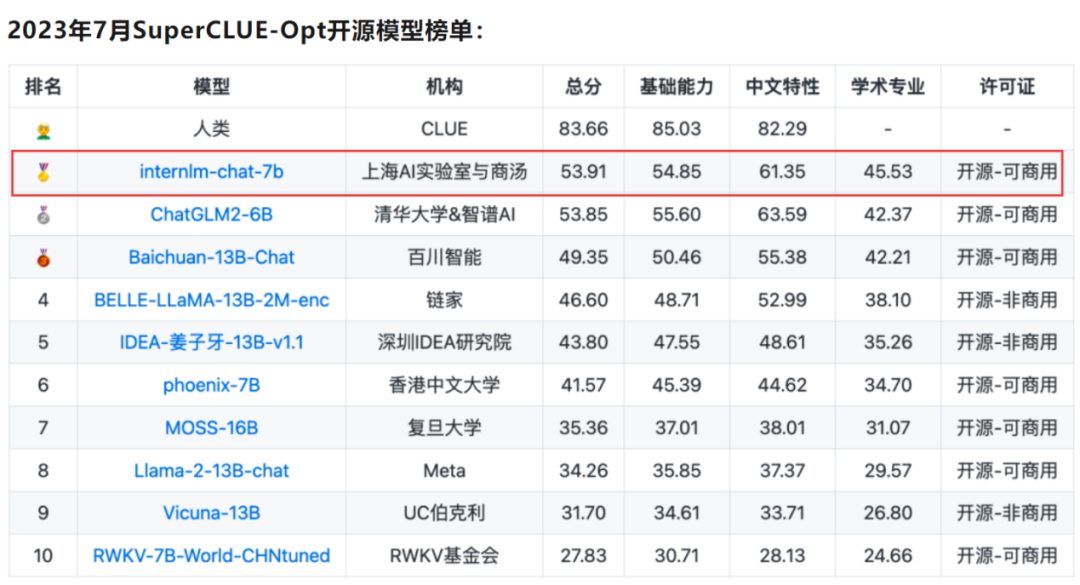
“书生·浦语”InternLM-chat-7B在7月公布SuperCLUE评测榜单中表现出色,在SuperCLUE-Opt开源大模型榜单拔得头筹。
作为SuperCLUE综合性三大基准之一,SuperCLUE-Opt评测基准每期有3700+道客观题(选择题),由基础能力(10个子任务)、中文特性能力(10个子任务)、学术专业能力(50+子任务)组成,采用封闭域测试方式。
相比第二名ChatGLM2-6B,InternLM-chat-7B主要在学术专业方面取得较大领先,同时全面领先于第三名Baichuan-13B-Chat。

相关阅读,戳这里
《让大模型“百花齐放”,商汤大装置SenseCore提供一片沃土》《商汤发布多模态多任务通用大模型“书生2.5”》
《商汤联合发布通才AI智能体通关<我的世界>》

原文标题:大语言模型“书生·浦语”多项专业评测拔头筹
文章出处:【微信公众号:商汤科技SenseTime】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 热点推荐
- 商汤科技
-
名单公布!【书籍评测活动NO.30】大规模语言模型:从理论到实践2024-03-11 16169
-
【大语言模型:原理与工程实践】大语言模型的评测2024-05-07 1941
-
大语言模型:原理与工程时间+小白初识大语言模型2024-05-12 1485
-
各大品牌精彩对决 谷歌Nexus One拔得头筹2010-01-16 872
-
唇语识别中的话题相关语言模型研究_王渊2017-03-19 811
-
图普科技在MegaFace百万级人脸识别测试中拔得头筹2018-07-11 5348
-
蔚来汽车在造车新势力中实现突围 拔得头筹2019-04-12 1513
-
三星5G手机市场拔得头筹,但整体营收却不尽人意2020-01-07 2611
-
阿拉伯语自然语言处理模型NOOR的详细介绍2022-04-12 2990
-
中译语通展示格物多语言大模型技术和工业实践2023-07-27 1278
-
性能超越开源模型标杆Llama2-70B,书生·浦语大模型InternLM-20B开源发布2023-09-20 1858
-
商汤科技发布新一代大语言模型书生·浦语2.02024-01-17 1896
-
书生・浦语 2.0(InternLM2)大语言模型开源2024-01-19 750
-
云知声山海大模型多项评测名列前茅2024-12-24 1152
-
书生大模型实战营沐曦魔乐专场MeetUP精彩回顾2025-08-20 1401
全部0条评论

快来发表一下你的评论吧 !
