

SpringBoot 2种方式快速实现分库分表,轻松拿捏!
电子说
描述
本文将为您介绍 ShardingSphere 的一些基础特性和架构组成,以及在 Springboot 环境下通过 JAVA编码 和 Yml配置 两种方式快速实现分库分表。
一、什么是 ShardingSphere?
shardingsphere 是一款开源的分布式关系型数据库中间件,为 Apache 的顶级项目。其前身是 sharding-jdbc 和 sharding-proxy 的两个独立项目,后来在 2018 年合并成了一个项目,并正式更名为 ShardingSphere。
其中 sharding-jdbc 为整个生态中最为经典和成熟的框架,最早接触分库分表的人应该都知道它,是学习分库分表的最佳入门工具。
如今的 ShardingSphere 已经不再是单纯代指某个框架,而是一个完整的技术生态圈,由三款开源的分布式数据库中间件 sharding-jdbc、sharding-proxy 和 sharding-sidecar 所构成。前两者问世较早,功能较为成熟,是目前广泛应用的两个分布式数据库中间件,因此在后续的文章中,我们将重点介绍它们的特点和使用方法。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
- 项目地址:https://github.com/YunaiV/ruoyi-vue-pro
- 视频教程:https://doc.iocoder.cn/video/
二、为什么选 ShardingSphere?
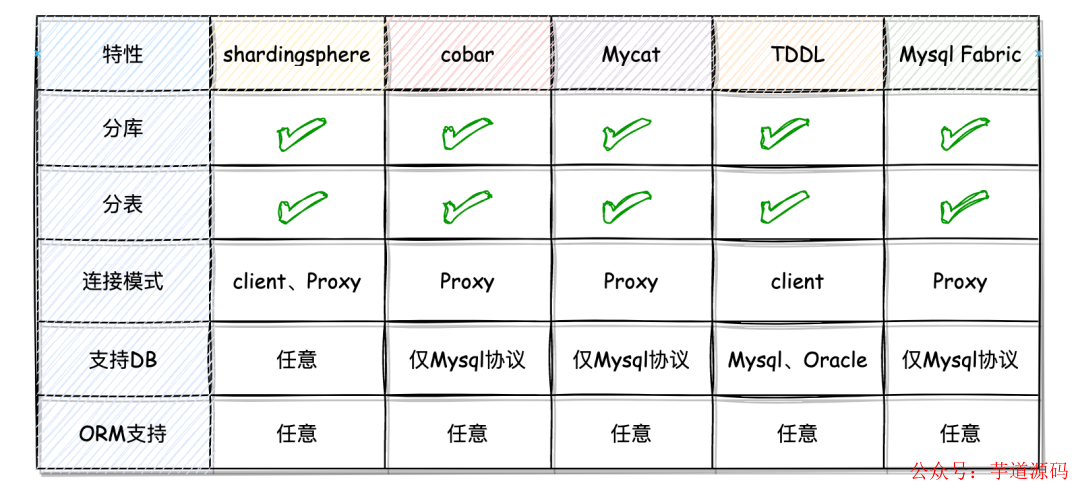
为了回答这个问题,我整理了市面上常见的分库分表工具,包括 ShardingSphere、Cobar、Mycat、TDDL、MySQL Fabric 等,并从多个角度对它们进行了简单的比较。
Cobar
Cobar 是阿里巴巴开源的一款基于MySQL的分布式数据库中间件,提供了分库分表、读写分离和事务管理等功能。它采用轮询算法和哈希算法来进行数据分片,支持分布式分表,但是不支持单库分多表。
它以 Proxy 方式提供服务,在阿里内部被广泛使用已开源,配置比较容易,无需依赖其他东西,只需要有Java环境即可。兼容市面上几乎所有的 ORM 框架,仅支持 MySQL 数据库,且事务支持方面比较麻烦。
MyCAT
Mycat 是社区爱好者在阿里 Cobar 基础上进行二次开发的,也是一款比较经典的分库分表工具。它以 Proxy 方式提供服务,支持分库分表、读写分离、SQL路由、数据分片等功能。
兼容市面上几乎所有的 ORM 框架,包括 Hibernate、MyBatis和 JPA等都兼容,不过,美中不足的是它仅支持 MySQL数据库,目前社区的活跃度相对较低。
TDDL
TDDL 是阿里巴巴集团开源的一款分库分表解决方案,可以自动将SQL路由到相应的库表上。它采用了垂直切分和水平切分两种方式来进行分表分库,并且支持多数据源和读写分离功能。
TDDL 是基于 Java 开发的,支持 MySQL、Oracle 和 SQL Server 数据库,并且可以与市面上 Hibernate、MyBatis等 ORM 框架集成。
不过,TDDL仅支持一些阿里巴巴内部的工具和框架的集成,对于外部公司来说可能相对有些局限性。同时,其文档和社区活跃度相比 ShardingSphere 来说稍显不足。
Mysql Fabric
MySQL Fabric是 MySQL 官方提供的一款分库分表解决方案,同时也支持 MySQL其他功能,如高可用、负载均衡等。它采用了管理节点和代理节点的架构,其中管理节点负责实时管理分片信息,代理节点则负责接收并处理客户端的读写请求。
它仅支持 MySQL 数据库,并且可以与市面上 Hibernate、MyBatis 等 ORM 框架集成。MySQL Fabric 的文档相对来说比较简略,而且由于是官方提供的解决方案,其社区活跃度也相对较低。
ShardingSphere
ShardingSphere 成员中的 sharding-jdbc 以 JAR 包的形式下提供分库分表、读写分离、分布式事务等功能,但仅支持 Java 应用,在应用扩展上存在局限性。
因此,ShardingSphere 推出了独立的中间件 sharding-proxy,它基于 MySQL协议实现了透明的分片和多数据源功能,支持各种语言和框架的应用程序使用,对接的应用程序几乎无需更改代码,分库分表配置可在代理服务中进行管理。
除了支持 MySQL,ShardingSphere还可以支持 PostgreSQL、SQLServer、Oracle等多种主流数据库,并且可以很好地与 Hibernate、MyBatis、JPA等 ORM 框架集成。重要的是,ShardingSphere的开源社区非常活跃。
如果在使用中出现问题,用户可以在 GitHub 上提交PR并得到快速响应和解决,这为用户提供了足够的安全感。
产品比较
通过对上述的 5 个分库分表工具进行比较,我们不难发现,就整体性能、功能丰富度以及社区支持等方面来看,ShardingSphere 在众多产品中优势还是比较突出的。下边用各个产品的主要指标整理了一个表格,看着更加直观一点。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
- 项目地址:https://github.com/YunaiV/yudao-cloud
- 视频教程:https://doc.iocoder.cn/video/
三、ShardingSphere 成员
ShardingSphere 的主要组成成员为sharding-jdbc、sharding-proxy,它们是实现分库分表的两种不同模式:
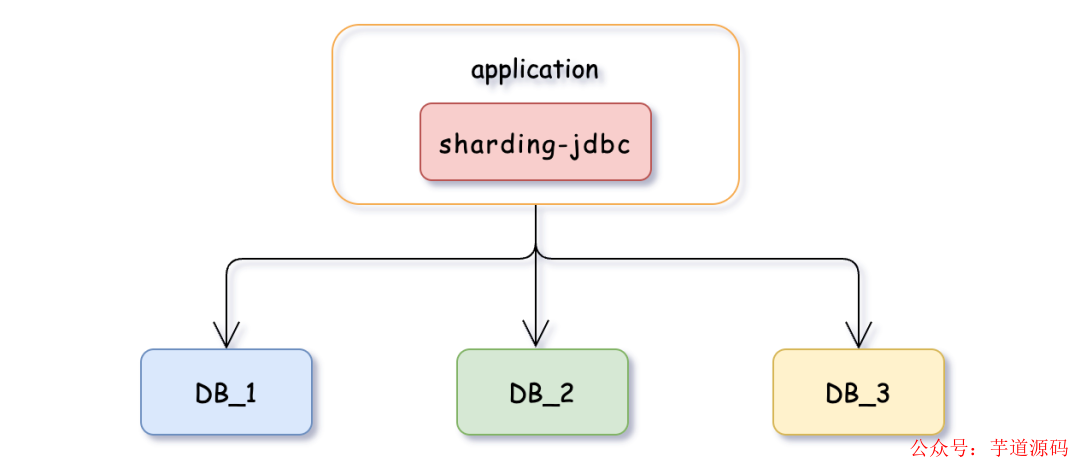
sharding-jdbc
它是一款轻量级Java框架,提供了基于 JDBC 的分库分表功能,为客户端直连模式。使用sharding-jdbc,开发者可以通过简单的配置实现数据的分片,同时无需修改原有的SQL语句。支持多种分片策略和算法,并且可以与各种主流的ORM框架无缝集成。
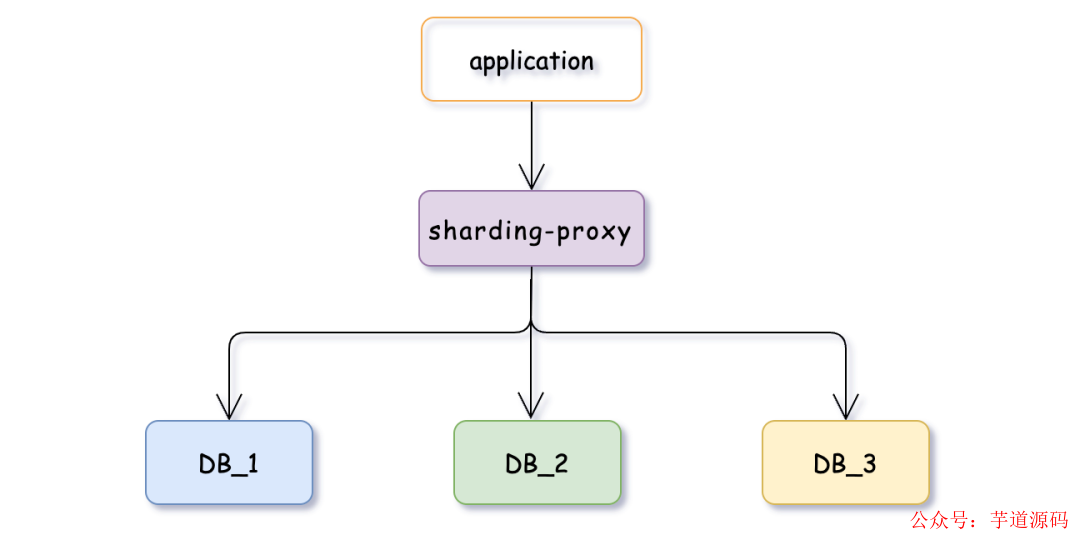
sharding-proxy
它是基于 MySQL 协议的代理服务,提供了透明的分库分表功能。使用 sharding-proxy 开发者可以将分片逻辑从应用程序中解耦出来,无需修改应用代码就能实现分片功能,还支持多数据源和读写分离等高级特性,并且可以作为独立的服务运行。
四、快速实现
我们先使用sharding-jdbc来快速实现分库分表。相比于 sharding-proxy,sharding-jdbc 适用于简单的应用场景,不需要额外的环境搭建等。下边主要基于 SpringBoot 的两种方式来实现分库分表,一种是通过YML配置方式,另一种则是通过纯Java编码方式(不可并存 )。在后续章节中,我们会单独详细介绍如何使用sharding-proxy以及其它高级特性。
ShardingSphere 官网地址:https://shardingsphere.apache.org/
准备工作
在开始实现之前,需要对数据库和表的拆分规则进行明确。以对t_order表进行分库分表拆分为例,具体地,我们将 t_order 表拆分到两个数据库中,分别为db1和db2,每个数据库又将该表拆分为三张表,分别为t_order_1、t_order_2和t_order_3。
db0
├── t_order_0
├── t_order_1
└── t_order_2
db1
├── t_order_0
├── t_order_1
└── t_order_2
JAR包引入
引入必要的 JAR 包,其中最重要的是shardingsphere-jdbc-core-spring-boot-starter和mysql-connector-java这两个。为了保证功能的全面性和兼容性,以及避免因低版本包导致的不必要错误和调试工作,我选择的包版本都较高。

shardingsphere-jdbc-core-spring-boot-starter 是 ShardingSphere 框架的核心组件,提供了对 JDBC 的分库分表支持;而 mysql-connector-java 则是 MySQL JDBC 驱动程序的实现,用于连接MySQL数据库。除此之外,我使用了JPA作为持久化工具还引入了相应的依赖包。
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-jpaartifactId>
<version>2.7.6version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.31version>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starterartifactId>
<version>5.2.0version>
dependency>
YML配置
我个人是比较推荐使用YML配置方式来实现 sharding-jdbc 分库分表的,使用YML配置方式不仅可以让分库分表的实现更加简单、高效、可维护,也更符合 SpringBoot的开发规范。
在 src/main/resources/application.yml 路径文件下添加以下完整的配置,即可实现对t_order表的分库分表,接下来拆解看看每个配置模块都做了些什么。
spring:
shardingsphere:
# 数据源配置
datasource:
# 数据源名称,多数据源以逗号分隔
names: db0,db1
db0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc//127.0.0.1:3306/shardingsphere-db1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: 123456
db1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc//127.0.0.1:3306/shardingsphere-db0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: 123456
# 分片规则配置
rules:
sharding:
# 分片算法配置
sharding-algorithms:
database-inline:
# 分片算法类型
type: INLINE
props:
# 分片算法的行表达式(算法自行定义,此处为方便演示效果)
algorithm-expression: db$->{order_id > 4?1:0}
table-inline:
# 分片算法类型
type: INLINE
props:
# 分片算法的行表达式
algorithm-expression: t_order_$->{order_id % 4}
tables:
# 逻辑表名称
t_order:
# 行表达式标识符可以使用 ${...} 或 $->{...},但前者与 Spring 本身的属性文件占位符冲突,因此在 Spring 环境中使用行表达式标识符建议使用 $->{...}
actual-data-nodes: db${0..1}.t_order_${0..3}
# 分库策略
database-strategy:
standard:
# 分片列名称
sharding-column: order_id
# 分片算法名称
sharding-algorithm-name: database-inline
# 分表策略
table-strategy:
standard:
# 分片列名称
sharding-column: order_id
# 分片算法名称
sharding-algorithm-name: table-inline
# 属性配置
props:
# 展示修改以后的sql语句
sql-show: true
以下是 shardingsphere 多数据源信息的配置,其中的 names 表示需要连接的数据库别名列表,每添加一个数据库名就需要新增一份对应的数据库连接配置。
spring:
shardingsphere:
# 数据源配置
datasource:
# 数据源名称,多数据源以逗号分隔
names: db0,db1
db0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc//127.0.0.1:3306/shardingsphere-db1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: 123456
db1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc//127.0.0.1:3306/shardingsphere-db0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
username: root
password: 123456
rules节点下为分片规则的配置,sharding-algorithms 节点为自定义的分片算法模块,分片算法可以在后边配置表的分片规则时被引用,其中:
-
database-inline:自定义的分片算法名称; -
type:该分片算法的类型,这里先以 inline 为例,后续会有详细章节介绍; -
props:指定该分片算法的具体内容,其中algorithm-expression是该分片算法的表达式,即根据分片键值计算出要访问的真实数据库名或表名,。
db$->{order_id % 2}这种为 Groovy 语言表达式,表示对分片键order_id进行取模,根据取模结果计算出db0、db1,分表的表达式同理。
spring:
shardingsphere:
# 规则配置
rules:
sharding:
# 分片算法配置
sharding-algorithms:
database-inline:
# 分片算法类型
type: INLINE
props:
# 分片算法的行表达式(算法自行定义,此处为方便演示效果)
algorithm-expression: db$->{order_id % 2}
table-inline:
# 分片算法类型
type: INLINE
props:
# 分片算法的行表达式
algorithm-expression: t_order_$->{order_id % 3}
tables节点定义了逻辑表名t_order的分库分表规则。actual-data-nodes 用于设置物理数据节点的数量。
db${0..1}.t_order_${0..3} 表达式意思此逻辑表在不同数据库实例中的分布情况,如果只想单纯的分库或者分表,可以调整表达式,分库db${0..1}、分表t_order_${0..3}。
db0
├── t_order_0
├── t_order_1
└── t_order_2
db1
├── t_order_0
├── t_order_1
└── t_order_2
spring:
shardingsphere:
# 规则配置
rules:
sharding:
tables:
# 逻辑表名称
t_order:
# 行表达式标识符可以使用 ${...} 或 $->{...},但前者与 Spring 本身的属性文件占位符冲突,因此在 Spring 环境中使用行表达式标识符建议使用 $->{...}
actual-data-nodes: db${0..1}.t_order_${0..3}
# 分库策略
database-strategy:
standard:
# 分片列名称
sharding-column: order_id
# 分片算法名称
sharding-algorithm-name: database-inline
# 分表策略
table-strategy:
standard:
# 分片列名称
sharding-column: order_id
# 分片算法名称
sharding-algorithm-name: table-inline
database-strategy 和 table-strategy分别设置了分库和分表策略;
sharding-column表示根据表的哪个列(分片键)进行计算分片路由到哪个库、表中;
sharding-algorithm-name 表示使用哪种分片算法对分片键进行运算处理,这里可以引用刚才自定义的分片算法名称使用。
props节点用于设置其他的属性配置,比如:sql-show表示是否在控制台输出解析改造后真实执行的 SQL语句以便进行调试。
spring:
shardingsphere:
# 属性配置
props:
# 展示修改以后的sql语句
sql-show: true
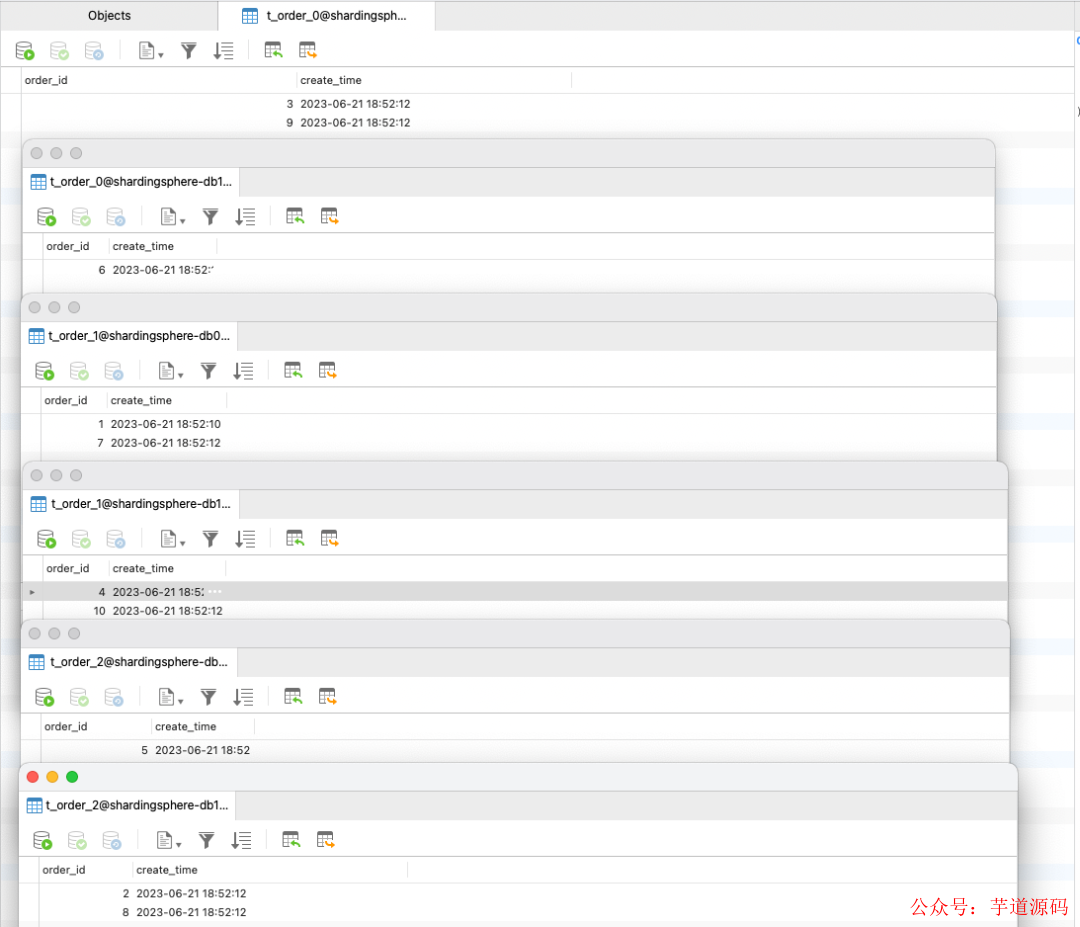
跑个单测在向数据库中插入 10 条数据时,发现数据已经相对均匀地插入到了各个分片中。
JAVA 编码
如果您不想通过 yml 配置文件实现自动装配,也可以使用 ShardingSphere 的 API 实现相同的功能。使用 API 完成分片规则和数据源的配置,优势在于更加灵活、可定制性强的特点,方便进行二次开发和扩展。
下边是纯JAVA编码方式实现分库分表的完整代码。
@Configuration
public class ShardingConfiguration {
/**
* 配置分片数据源
*/
@Bean
public DataSource getShardingDataSource() throws SQLException {
Map dataSourceMap = new HashMap<>();
dataSourceMap.put("db0", dataSource1());
dataSourceMap.put("db1", dataSource2());
// 分片rules规则配置
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.setShardingAlgorithms(getShardingAlgorithms());
// 配置 t_order 表分片规则
ShardingTableRuleConfiguration orderTableRuleConfig = new ShardingTableRuleConfiguration("t_order", "db${0..1}.t_order_${0..2}");
orderTableRuleConfig.setTableShardingStrategy(new StandardShardingStrategyConfiguration("order_id", "table-inline"));
orderTableRuleConfig.setDatabaseShardingStrategy(new StandardShardingStrategyConfiguration("order_id", "database-inline"));
shardingRuleConfig.getTables().add(orderTableRuleConfig);
// 是否在控制台输出解析改造后真实执行的 SQL
Properties properties = new Properties();
properties.setProperty("sql-show", "true");
// 创建 ShardingSphere 数据源
return ShardingSphereDataSourceFactory.createDataSource(dataSourceMap, Collections.singleton(shardingRuleConfig), properties);
}
/**
* 配置数据源1
*/
public DataSource dataSource1() {
HikariDataSource dataSource = new HikariDataSource();
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
dataSource.setJdbcUrl("jdbc//127.0.0.1:3306/shardingsphere-db1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true");
dataSource.setUsername("root");
dataSource.setPassword("123456");
return dataSource;
}
/**
* 配置数据源2
*/
public DataSource dataSource2() {
HikariDataSource dataSource = new HikariDataSource();
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
dataSource.setJdbcUrl("jdbc//127.0.0.1:3306/shardingsphere-db0?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true");
dataSource.setUsername("root");
dataSource.setPassword("123456");
return dataSource;
}
/**
* 配置分片算法
*/
private Map getShardingAlgorithms() {
Map shardingAlgorithms = new LinkedHashMap<>();
// 自定义分库算法
Properties databaseAlgorithms = new Properties();
databaseAlgorithms.setProperty("algorithm-expression", "db$->{order_id % 2}");
shardingAlgorithms.put("database-inline", new AlgorithmConfiguration("INLINE", databaseAlgorithms));
// 自定义分表算法
Properties tableAlgorithms = new Properties();
tableAlgorithms.setProperty("algorithm-expression", "t_order_$->{order_id % 3}");
shardingAlgorithms.put("table-inline", new AlgorithmConfiguration("INLINE", tableAlgorithms));
return shardingAlgorithms;
}
}
ShardingSphere 的分片核心配置类 ShardingRuleConfiguration,它主要用来加载分片规则、分片算法、主键生成规则、绑定表、广播表等核心配置。我们将相关的配置信息 set到配置类,并通过createDataSource创建并覆盖 DataSource,最后注入Bean。
使用Java编码方式只是将 ShardingSphere 预知的加载配置逻辑自己手动实现了一遍,两种实现方式比较下来,还是推荐使用YML配置方式来实现 ShardingSphere的分库分表功能,相比于Java编码,YML配置更加直观和易于理解,开发者可以更加专注于业务逻辑的实现,而不需要过多关注底层技术细节。
@Getter
@Setter
public final class ShardingRuleConfiguration implements DatabaseRuleConfiguration, DistributedRuleConfiguration {
// 分表配置配置
private Collection tables = new LinkedList<>();
// 自动分片规则配置
private Collection autoTables = new LinkedList<>();
// 绑定表配置
private Collection bindingTableGroups = new LinkedList<>();
// 广播表配置
private Collection broadcastTables = new LinkedList<>();
// 默认的分库策略配置
private ShardingStrategyConfiguration defaultDatabaseShardingStrategy;
// 默认的分表策略配置
private ShardingStrategyConfiguration defaultTableShardingStrategy;
// 主键生成策略配置
private KeyGenerateStrategyConfiguration defaultKeyGenerateStrategy;
private ShardingAuditStrategyConfiguration defaultAuditStrategy;
// 默认的分片键
private String defaultShardingColumn;
// 自定义的分片算法
private Map shardingAlgorithms = new LinkedHashMap<>();
// 主键生成算法
private Map keyGenerators = new LinkedHashMap<>();
private Map auditors = new LinkedHashMap<>();
}
经过查看控制台打印的真实 SQL日志,发现在使用 ShardingSphere 进行数据插入时,其内部实现会先根据分片键 order_id 查询记录是否存在。如果记录不存在,则执行插入操作;如果记录已存在,则进行更新操作。看似只会执行10条插入SQL,但实际上需要执行20条SQL语句,多少会对数据库的性能产生一定的影响。
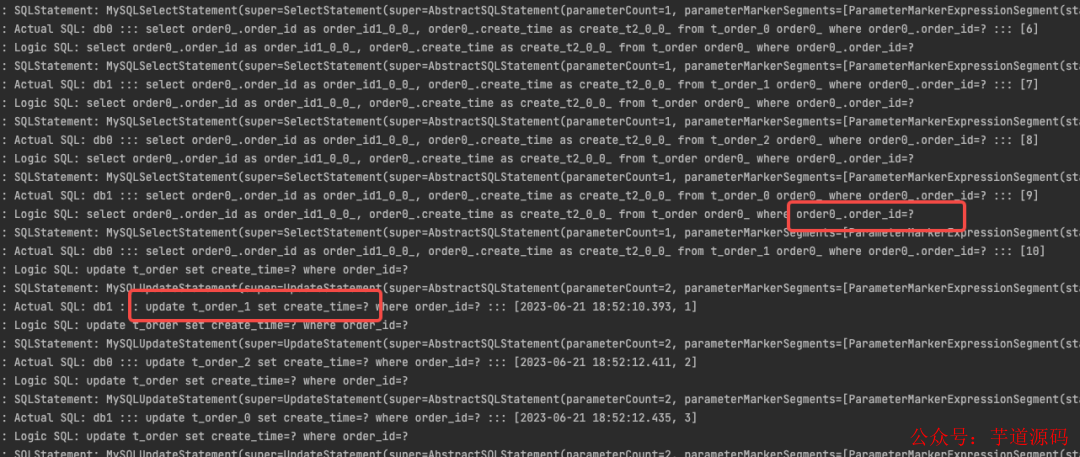
功能挺简单的,但由于不同版本的 ShardingSphere 的 API 变化较大 ,网上类似的资料太不靠谱,本来想着借助 GPT 快点实现这段代码,结果差点和它干起来,最后还是扒了扒看了源码完成的。
默认数据源
可能有些小伙伴会有疑问,对于已经设置了分片规则的t_order表可以正常操作数据,如果我们的t_user表没有配置分库分表规则,那么在执行插入操作时会发生什么呢?
仔细看了下官方的技术文档,其实已经回答了小伙伴这个问题,如果只有部分数据库分库分表,是否需要将不分库分表的表也配置在分片规则中?官方回答:不需要 。

我们创建一张t_user表,并且不对其进行任何分片规则的配置。在我的印象中没有通过设置 default-data-source-name 默认的数据源,操作未分片的表应该会报错的!
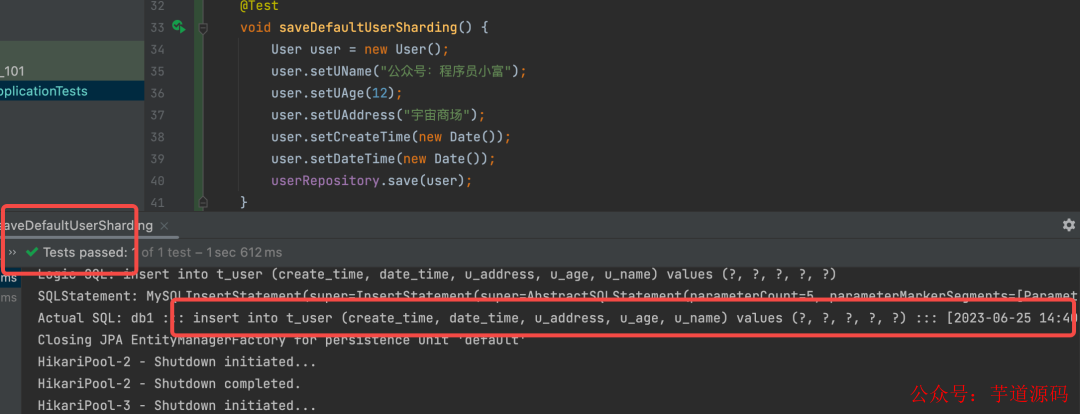
我们向t_user尝试插入一条数据,结果居然成功了?翻了翻库表发现数据只被插在了 db1 库里,说明没有走广播路由。
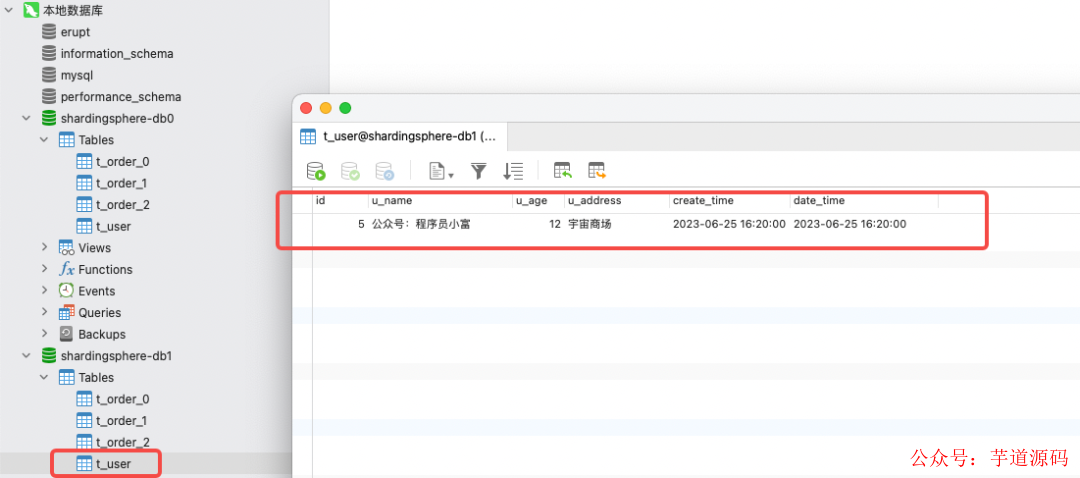
shardingsphere-jdbc 5.x版本移除了原本的默认数据源配置,自动使用了默认数据源的规则,为验证我多增加了数据源,尝试性的调整了db2、db0、db1的顺序,再次插入数据,这回记录被插在了 db2 库,反复试验初步得出结论。
未分片的表默认会使用第一个数据源作为默认数据源,也就是 datasource.names 第一个。
spring:
shardingsphere:
# 数据源配置
datasource:
# 数据源名称,多数据源以逗号分隔
names: db2 , db1 , db0
总结
本期我们对 shardingsphere 做了简单的介绍,并使用 yml 和 Java编码的方式快速实现了分库分表功能。
- 相关推荐
- 热点推荐
- 数据库
- 架构
- MySQL
- SpringBoot
-
新版架构师系列-ShardingJDBC分库分表mysql数据库实战2026-05-18 61
-
软件系统数据库的分库分表设计2024-08-22 1379
-
分库分表后复杂查询的应对之道:基于DTS实时性ES宽表构建技术实践2024-06-25 1885
-
数据库分区、分库和分表2023-09-30 4476
-
分库分表的21条法则速来码住(上)2023-05-26 1190
-
什么是分库分表?为什么分库分表?什么情况下会用分库分表呢?2022-11-30 8751
-
你是否知道分库分表需要哪些要素?2022-10-12 1610
-
优化MySQL数据库中朴实无华的分表和花里胡哨的分库2021-08-26 1832
-
你们知道为什么要分库分表吗2021-08-16 2168
-
分库分表是什么?怎么实现?2019-10-25 1796
-
基于SpringBoot mybatis方式的增删改查实现2019-06-18 2093
-
数据库分库分表基础和实践2018-09-05 567
-
谈分布式数据库中间件之分库分表2018-08-02 2404
-
利用Mycat实现MySQL读写分离、分库分表最佳实践2017-09-08 1285
全部0条评论

快来发表一下你的评论吧 !
