

LLaMa量化部署
电子说
描述
本文导论部署 LLaMa 系列模型常用的几种方案,并作速度测试。包括 Huggingface 自带的 LLM.int8(),AutoGPTQ, GPTQ-for-LLaMa, exllama, llama.cpp。
总结来看,对 7B 级别的 LLaMa 系列模型,经过 GPTQ 量化后,在 4090 上可以达到 140+ tokens/s 的推理速度。在 3070 上可以达到 40 tokens/s 的推理速度。
LM.int8()
来自论文:LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
LM.int8() 时 Hugingface 集成的量化策略。能够通过在 .from_pretrain() 时候传递 load_in_8bit 来实现,针对几乎所有的 HF Transformers 模型都有效。大致方法是,在矩阵点积计算过程中, 将其中的 outliers 参数找出来(以行或列为单位),然后用类似 absolute maximum (absmax) quantization 的方法,根据行/列对 Regular 参数做量化处理,outlier 参数仍然做 fp16 计算,最后相加。
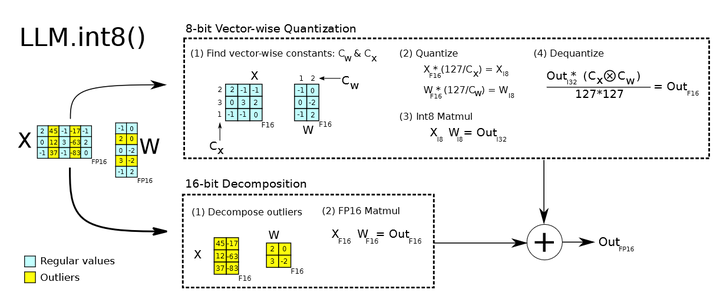
根据 huggingface 的博客, LLM.INT8() 能够再模型性能不影响很多的前提下,让我们能用更少的资源进行 LLM 推理。但 LLM.int8() 普遍的推理速度会比 fp16 慢。博客中指出,对于越小的模型, int8() 会导致更慢的速度。
结合论文中的实验结果,模型越大,int8() 加速越明显,个人猜测是由于非 outlier 数量变多了,更多的参数进行了 int8 计算,抵消了额外的量化转化时间开销?
GPTQ
GPTQ: ACCURATE POST-TRAINING QUANTIZATION FOR GENERATIVE PRE-TRAINED TRANSFORMERS
使用 GPTQ 量化的模型具有很大的速度优势,与 LLM.int8() 不同,GPTQ 要求对模型进行 post-training quantization,来得到量化权重。GPTQ 主要参考了 Optimal Brain Quanization (OBQ),对OBQ 方法进行了提速改进。有网友在 文章 中对 GPTQ, OBQ, OBS 等量化策略进行了整理,这里就不多赘述了。
以下对几个 GPTQ 仓库进行介绍。以下所有测试均在 4090 上进行,模型推理速度采用 oobabooga/text-generation-webui 提供的 UI。
GPTQ-for-LLaMa
专门针对 LLaMa 提供 GPTQ 量化方案的仓库,如果考虑 GPU 部署 LLaMa 模型的话,GPTQ-for-LLaMa 是十分指的参考的一个工具。像 http://huggingface.co 上的 Thebloke 很大部分模型都是采用 GPTQ-for-LLaMa 进行量化的。
Post Training Quantization:GPTQ-for-LLaMa 默认采用 C4 数据集进行量化训练(只采用了 C4 中英文数据的一部分进行量化,而非全部 9TB+的数据):
CUDA_VISIBLE_DEVICES=0 python llama.py /models/vicuna-7b c4
--wbits 4
--true-sequential
--groupsize 128
--save_safetensors vicuna7b-gptq-4bit-128g.safetensors
由于 GPTQ 是 Layer-Wise Quantization,因此进行量化时对内存和显存要求会少一点。在 4090 测试,最高峰显存占用 7000MiB,整个 GPTQ 量化过程需要 10 分钟。量化后进行 PPL 测试,7b 在没有 arc_order 量化下,c4 的 ppl 大概会在 5-6 左右:
CUDA_VISIBLE_DEVICES=0 python llama.py /models/vicuna-7b c4
--wbits 4
--groupsize 128
--load vicuna7b-gptq-4bit-128g.safetensors
--benchmark 2048 --check
对量化模型在 MMLU 任务上测试,量化后 MMLU 为,于 fp16(46.1)稍微有点差距。
Huggingface 上的 TheBloke 发布的大部分 LLaMa GPTQ 模型,都是通过以上方式(C4 数据集 + wbit 4 + group 128 + no arc_order + true-sequential)量化的。若由于 GPTQ-for-LLaMa 及 transformers 仓库不断更新,Huggingface.co 上发布的模型可能存在无法加载或精度误差等问题,可以考虑重新量化,并通过优化量化数据集、添加 arc_order 等操作来提高量化精度。
GPTQ-for-LLaMa 的一些坑:
-
经过测试,问题存在于
llama.py中的quant.make_quant_attn(model)。使用quant_attn能够极大提升模型推理速度。参考这个历史 ISSUE,估计是position_id的推理 cache 在 Attention layer 中的配置存在了问题。left-padding issue
-
模型加载问题:使用 gptq-for-llama 时,因 transformer 版本不同,可能出现模型加载不上问题。如加载 TheBloke/Wizard-Vicuna-30B-Uncensored-GPTQ 时,用最新版的 GPTQ-for-LLaMa 就会出现权重于模型 registry 名称不匹配的情况。
-
left-padding 问题:目前 GPTQ-for-LLaMa 的所有分支(triton, old-cuda 或 fastest-inference-int4)都存在该问题。如果模型对存在 left-padding 的输入进行预测时候,输出结果是混乱的。这导致了 GPTQ-for-LLaMa 目前无法支持正确的 batch inference。
-
GPTQ-for-LLaMa 版本变动大,如果其他仓库有使用 GPTQ-for-LLaMa 依赖的话,需要认真检查以下版本。如 obbabooga fork 了一个单独的 GPTQ-for-LLaMa 为 oobabooga/text-generation-webui 做支持。最新版的 GPTQ-for-LLaMa 在 text-generation-webui 中使用会有 BUG。
AutoGPTQ
AutoGPTQ 使用起来相对容易,它提供了对大多数 Huggingface LLM 模型的量化方案,如 LLaMa 架构系列模型,bloom,moss,falcon,gpt_bigcode 等。(没在支持表中看到 ChatGLM 系列模型)。具体可以参考 官方的 快速上手 和 进阶使用 来进行量化模型训练和部署。
AutoGPTQ 可以直接加载 GPTQ-for-LLaMa 的量化模型:
from auto_gptq import AutoGPTQForCausalLMmodel = AutoGPTQForCausalLM.from_quantized(
model_dir, # 存放模型的文件路径,里面包含 config.json, tokenizer.json 等模型配置文件
model_basename="vicuna7b-gptq-4bit-128g.safetensors",
use_safetensors=True,
device="cuda:0",
use_triton=True, # Batch inference 时候开启 triton 更快
max_memory = {0: "20GIB", "cpu": "20GIB"} # )
AutoGPTQ 提供了更多的量化加载选项,如是否采用 fused_attention,配置 CPU offload 等。用 AutoGPTQ 加载权重会省去很多不必要的麻烦,如 AutoGPTQ 并没有 GPTQ-for-LLaMa 类似的 left-padding bug,对 Huggingface 其他 LLM 模型的兼容性更好。因此如果做 GPTQ-INT4 batch inference 的话,AutoGPTQ 会是首选。
但对于 LLaMa 系列模型,AutoGPTQ 的速度会明显慢于 GPTQ-for-LLaMa。在 4090 上测试,GPTQ-for-LLaMa 的推理速度会块差不多 30%。
exllama
exllama 为了让 LLaMa 的 GPTQ 系列模型在 4090/3090 Ti 显卡上跑更快,推理平均能达到 140+ tokens/s。当然为了实现那么高的性能加速,exllama 中的模型移除了 HF transformers 模型的大部分依赖,这也导致如果在项目中使用 exllama 模型需要额外的适配工作。text-generation-webui 中对 exllama 进行了 HF 适配,使得我们能够像使用 HF 模型一样使用 exllama,代价是牺牲了一些性能,参考 exllama_hf。
gptq
GPTQ 的官方仓库。以上大部分仓库都是基于官方仓库开发的,感谢 GPTQ 的开源,让单卡 24G 显存也能跑上 33B 的大模型。
GGML
GGML 是一个机械学习架构,使用 C 编写,支持 Integer quantization(4-bit, 5-bit, 8-bit) 以及 16-bit float。同时也对部分硬件架构进行了加速优化。本章中讨论到的 LLaMa 量化加速方案来源于 LLaMa.cpp 。LLaMa.cpp 有很多周边产品,如 llama-cpp-python 等,在下文中,我们以 GGML 称呼这类模型量化方案。
llama.cpp 在一个月前支持了全面 GPU 加速(在推理的时候,可以把整个模型放在 GPU 上推理)。参考后文的测试,LLaMa.cpp 比 AutoGPTQ 有更快的推理速度,但是还是比 exllama 慢很多。
GGML 有不同的量化策略(具体量化类型参考),以下使用 Q4_0 对 LLaMa-2-13B-chat-hf 进行量化和测试。
此处采用 docker with cuda 部署,为方便自定义,先注释掉 .devops/full-cuda.Dockerfile 中的 EntryPoint。而后构建镜像:
docker build -t local/llama.cpp:full-cuda -f .devops/full-cuda.Dockerfile .
构建成功后开启容器(models 映射到模型文件路径):
docker run -it --name ggml --gpus all -p 8080:8080 -v /home/kevin/models:/models local/llama.cpp:full-cuda bash
参考官方文档,进行权重转换即量化:
# 转换 ggml 权重python3 convert.py /models/Llama-2-13b-chat-hf/# 量化./quantize /models/Llama-2-13b-chat-hf/ggml-model-f16.bin /models/Llama-2-13b-chat-GGML_q4_0/ggml-model-q4_0.bin q4_0
完成后开启server 测试
./server -m /models/Llama-2-13b-chat-GGML_q4_0/ggml-model-q4_0.bin --host 0.0.0.0 --ctx-size 2048 --n-gpu-layers 128
发送请求测试:
curl --request POST --url http://localhost:8080/completion --header "Content-Type: application/json" --data '{"prompt": "Once a upon time,","n_predict": 200}'
使用 llama.cpp server 时,具体参数解释参考官方文档。主要参数有:
-
--ctx-size: 上下文长度。 -
--n-gpu-layers:在 GPU 上放多少模型 layer,我们选择将整个模型放在 GPU 上。 -
--batch-size:处理 prompt 时候的 batch size。
使用 llama.cpp 部署的请求,速度与 llama-cpp-python 差不多。对于上述例子中,发送 Once a upon time, 并返回 200 个字符,两者完成时间都在 2400 ms 左右(约 80 tokens/秒)。
推理部署
记得在bert 时代,部署 Pytorch 模型时可能会考虑一些方面,比如动态图转静态图,将模型导出到 onnx,torch jit 等,混合精度推理,量化,剪枝,蒸馏等。对于这些推理加速方案,我们可能需要自己手动应用到训练好的模型上。但在 LLaMa 时代,感受到最大的变化就是,一些开源的框架似乎为你做好了一切,只需要把你训练好的模型权重放上去就能实现比 HF 模型快 n 倍的推理速度。
以下对比这些推理加速方案:HF 官方 float16(基线), vllm,llm.int8(),GPTQ-for-LLaMa,AUTOGPTQ,exllama, llama.cpp。
| Model_name | tool | tokens/s |
|---|---|---|
| vicuna 7b | float16 | 43.27 |
| vicuna 7b | load-in-8bit (HF) | 19.21 |
| vicuna 7b | load-in-4bit (HF) | 28.25 |
| vicuna7b-gptq-4bit-128g | AUTOGPTQ | 79.8 |
| vicuna7b-gptq-4bit-128g | GPTQ-for-LLaMa | 80.0 |
| vicuna7b-gptq-4bit-128g | exllama | 143.0 |
| Llama-2-7B-Chat-GGML (q4_0) | llama.cpp | 111.25 |
| Llama-2-13B-Chat-GGML (q4_0) | llama.cpp | 72.69 |
| Wizard-Vicuna-13B-GPTQ | exllama | 90 |
| Wizard-Vicuna-30B-uncensored-GPTQ | exllama | 43.1 |
| Wizard-Vicuna-30B-uncensored-GGML (q4_0) | llama.cpp | 34.03 |
| Wizard-Vicuna-30B-uncensored-GPTQ | AUTOGPTQ | 31 |
以上所有测试均在 4090 + Inter i9-13900K上进行,模型推理速度采用 oobabooga/text-generation-webui 提供的 UI(text-generation-webui 的推理速度会比实际 API 部署慢一点)。这边只做速度测试,关于精度测试,可以查看 GPT-for-LLaMa result 和 exllama results。
一些备注
-
模型推理的速度受 GPU 即 CPU 的影响最大。有网友指出 link,同样对于 4090,在 CPU 不同的情况下,7B LLaMa fp16 快的时候有 50 tokens/s,慢的时候能达到 23 tokens/s。
-
对于 stable diffusion,torch cuda118 能比 torch cuda 117 速度快上1倍。但对于 LLaMa 来说,cuda 117 和 118 差别不大。
-
量化 batch inference 首选 AUTOGPTQ (TRITON),尽管 AutoGPTQ 速度慢点,但目前版本的 GPTQ-for-LLaMa 存在 left-padding 问题,无法使用 batch inference;batch size = 1 时,首选 exllama 或者 GPTQ-for-LLaMa。
-
vllm 部署 fp16 的模型速度也不错(80+ tokens/s),同时也做了内存优化;如果设备资源够的话,可以考虑下 vllm,毕竟采用 GPTQ 还是有一点精度偏差的。
-
TheBloke 早期发布的一些模型可能无法加载到 exllama 当中,可以使用最新版本的 GPTQ-for-LLaMa 训练一个新模型。
-
当显卡容量无法加载整个模型时(比如在单卡 4090 上加载 llama-2-70B-chat),llama.cpp 比 GPTQ 速度更快(参考)。
-
解读大模型FP量化的解决方案2023-11-24 1736
-
[技术] 【飞凌嵌入式OK3576-C开发板体验】llama2.c部署2024-09-18 14383
-
使用 NPU 插件对量化的 Llama 3.1 8b 模型进行推理时出现“从 __Int64 转换为无符号 int 的错误”,怎么解决?2025-06-25 611
-
【CIE全国RISC-V创新应用大赛】基于 K1 AI CPU 的大模型部署落地2025-11-27 1684
-
基于LLAMA的魔改部署2023-05-23 6565
-
Yolo系列模型的部署、精度对齐与int8量化加速2023-11-23 2860
-
LLaMA 2是什么?LLaMA 2背后的研究工作2024-02-21 2561
-
Llama 3 王者归来,Airbox 率先支持部署2024-04-22 1641
-
Optimum Intel三步完成Llama3在算力魔方的本地量化和部署2024-05-10 2213
-
【AIBOX上手指南】快速部署Llama32024-06-06 2068
-
如何将Llama3.1模型部署在英特尔酷睿Ultra处理器2024-07-26 4402
-
源2.0-M32大模型发布量化版 运行显存仅需23GB 性能可媲美LLaMA32024-08-25 1278
-
使用OpenVINO 2024.4在算力魔方上部署Llama-3.2-1B-Instruct模型2024-10-12 2572
-
Meta发布Llama 3.2量化版模型2024-10-29 1488
-
用Ollama轻松搞定Llama 3.2 Vision模型本地部署2024-11-23 5016
全部0条评论

快来发表一下你的评论吧 !
