

超强图解Pandas,建议收藏
描述
Pandas是数据挖掘常见的工具,掌握使用过程中的函数是非常重要的。本文将借助可视化的过程,讲解Pandas的各种操作。
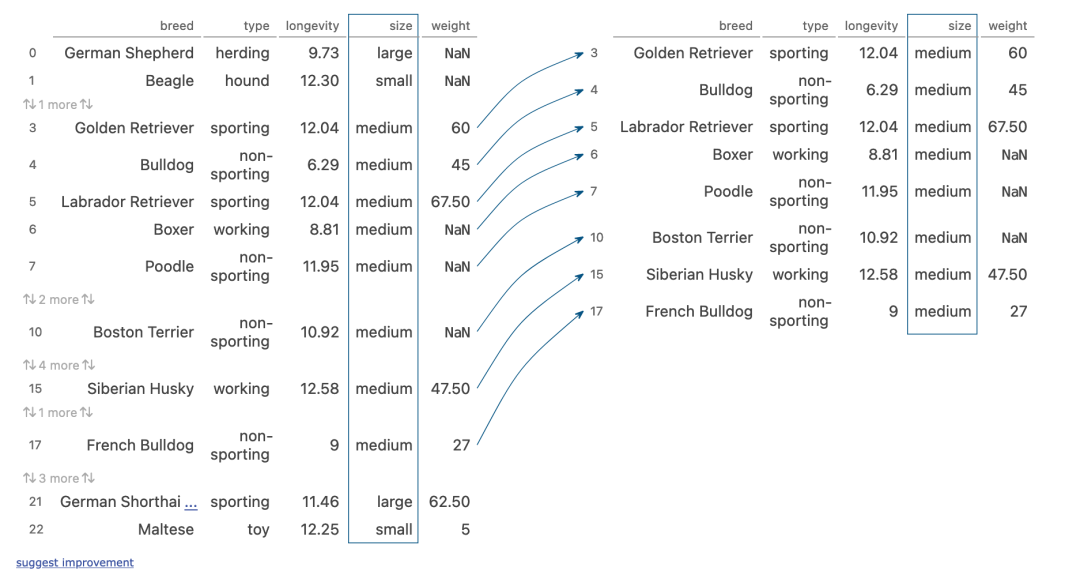
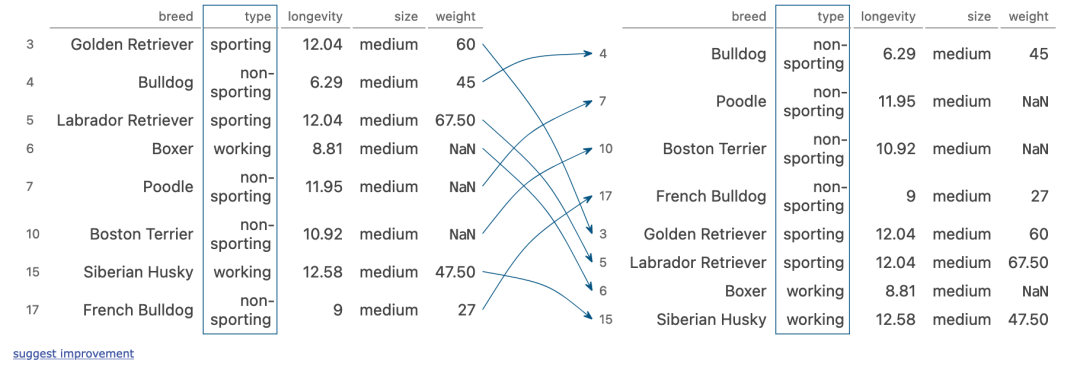
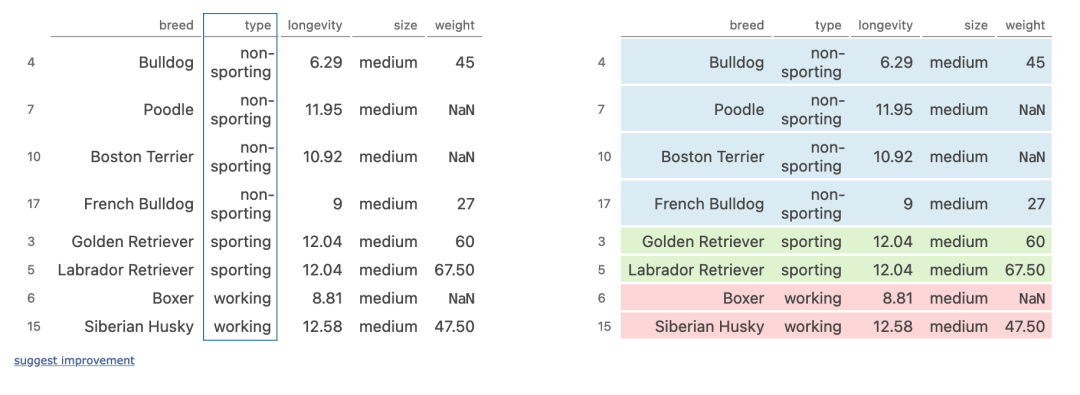
sort_values
(dogs[dogs['size'] == 'medium']
.sort_values('type')
.groupby('type').median()
)
执行步骤:
- size列筛选出部分行
- 然后将行的类型进行转换
- 按照type列进行分组,计算中位数

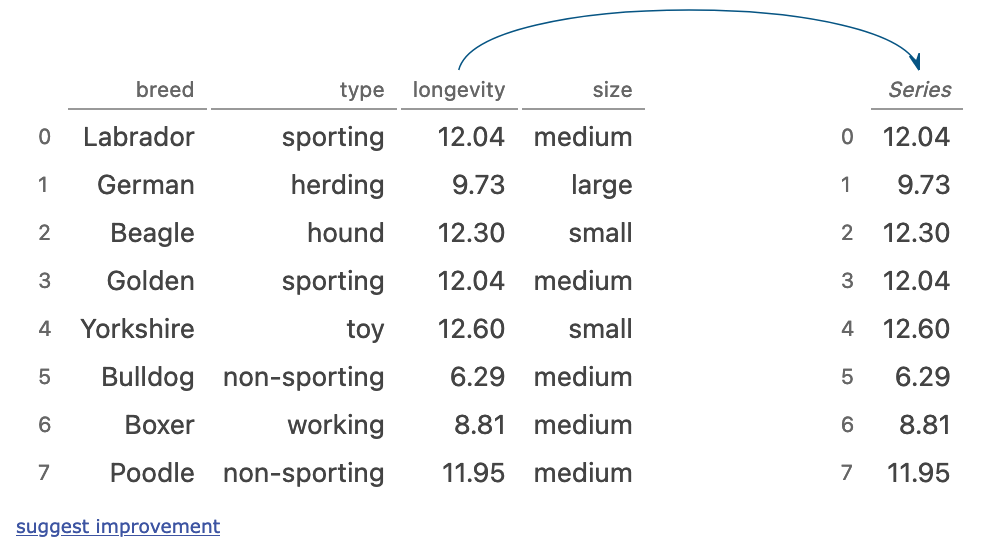
selecting a column
dogs['longevity']
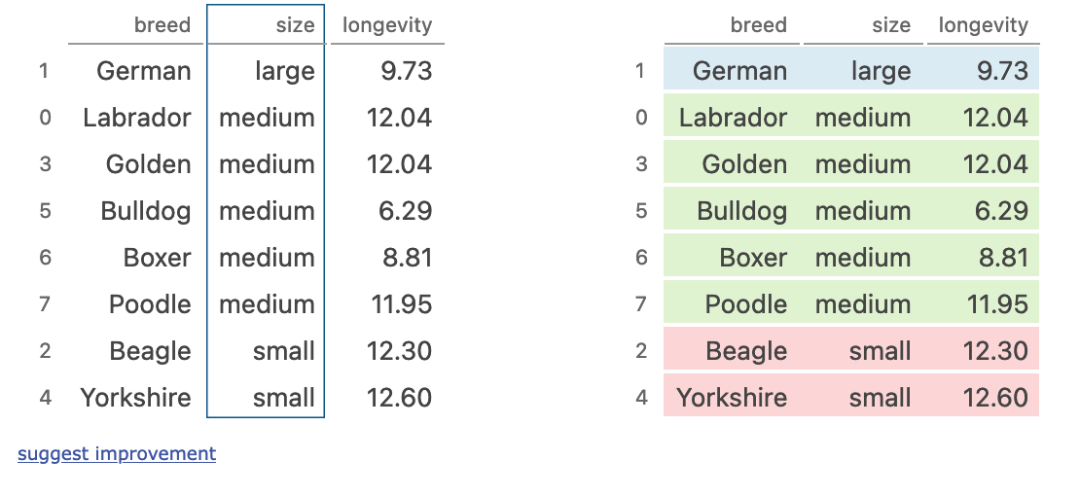
groupby + mean
dogs.groupby('size').mean()
执行步骤:- 将数据按照size进行分组
- 在分组内进行聚合操作

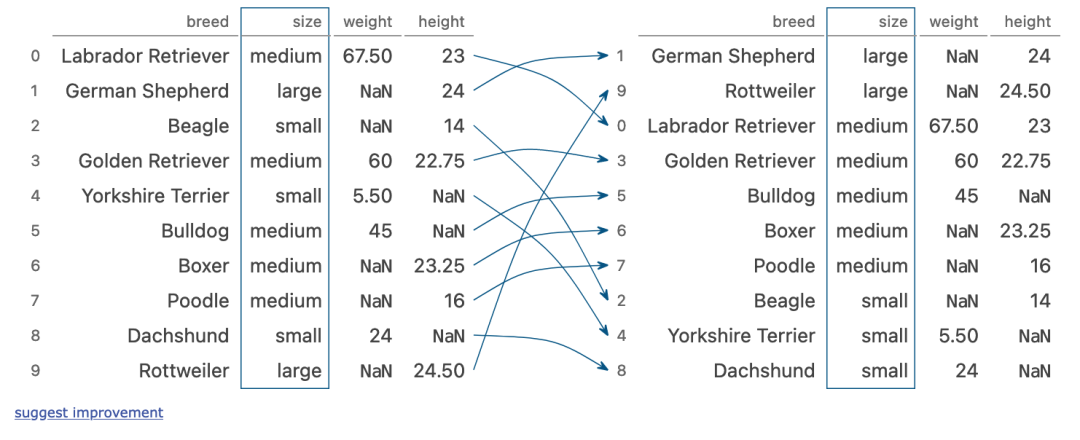
grouping multiple columns
dogs.groupby(['type', 'size'])

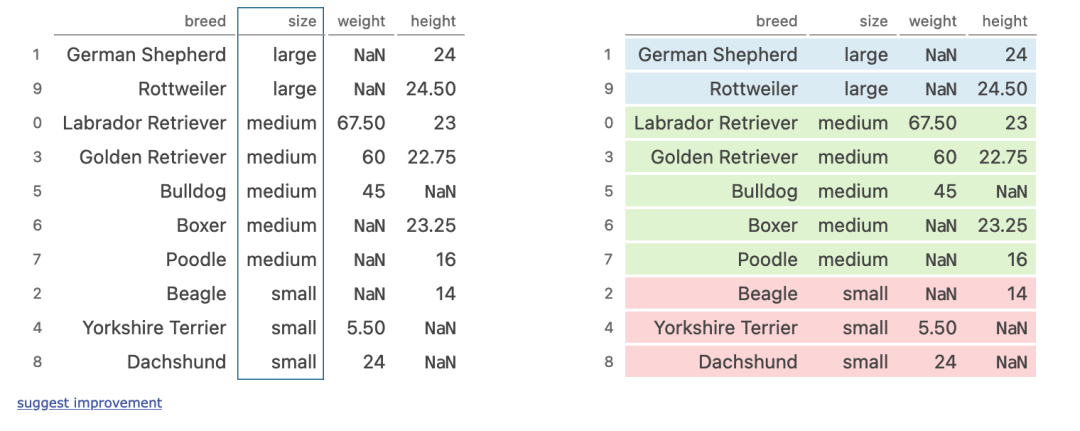
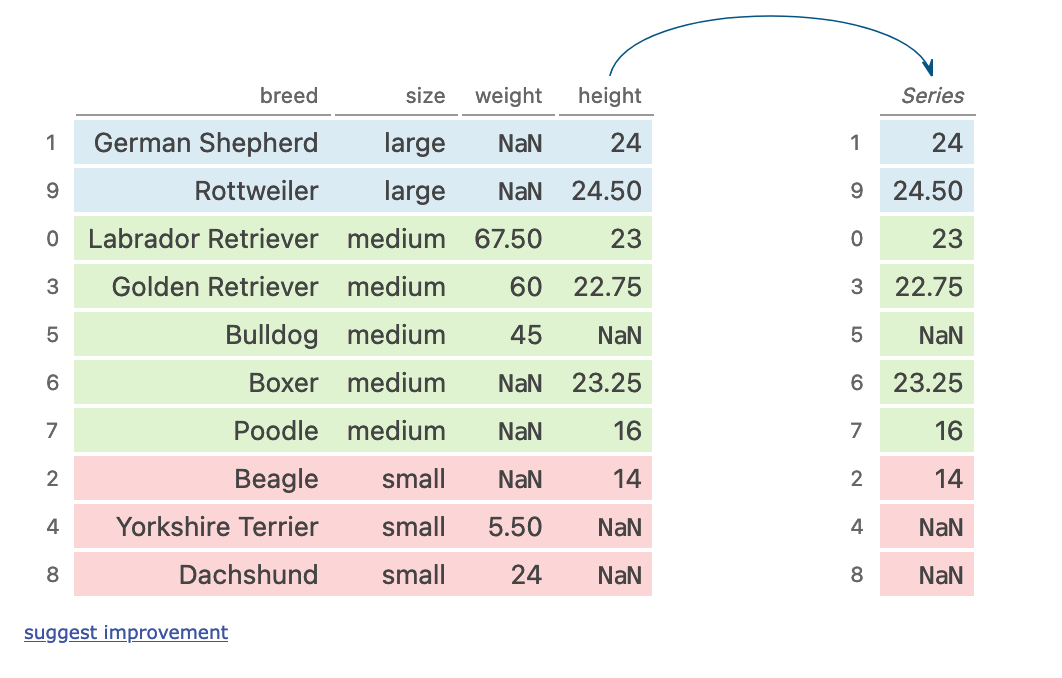
groupby + multi aggregation
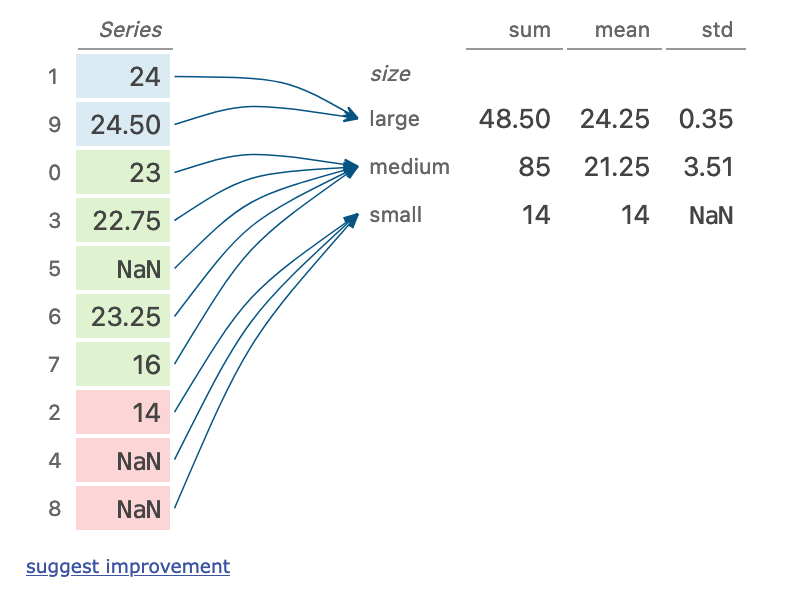
(dogs
.sort_values('size')
.groupby('size')['height']
.agg(['sum', 'mean', 'std'])
)
执行步骤
- 按照size列对数据进行排序
- 按照size进行分组
- 对分组内的height进行计算
filtering for columns
df.loc[:, df.loc['two'] <= 20]

filtering for rows
dogs.loc[(dogs['size'] == 'medium') & (dogs['longevity'] > 12), 'breed']

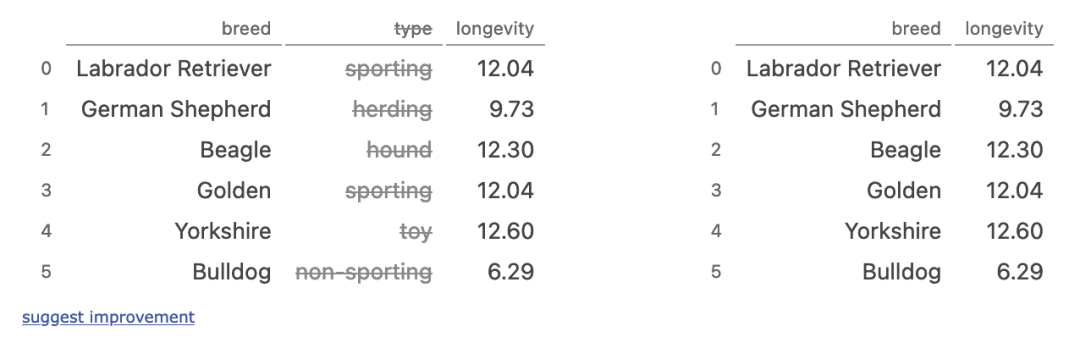
dropping columns
dogs.drop(columns=['type'])
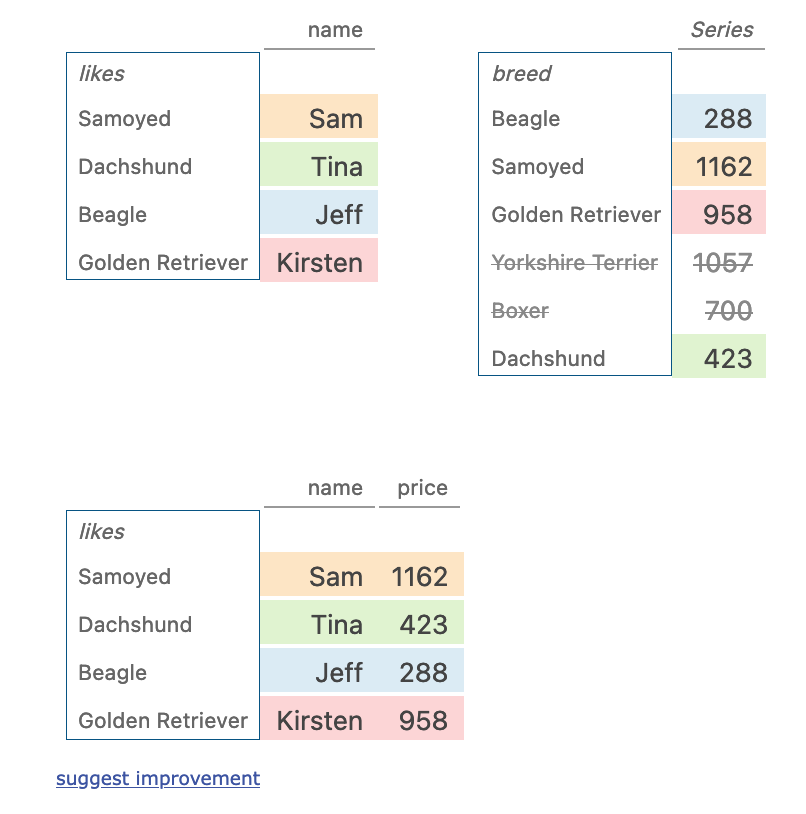
joining
ppl.join(dogs)
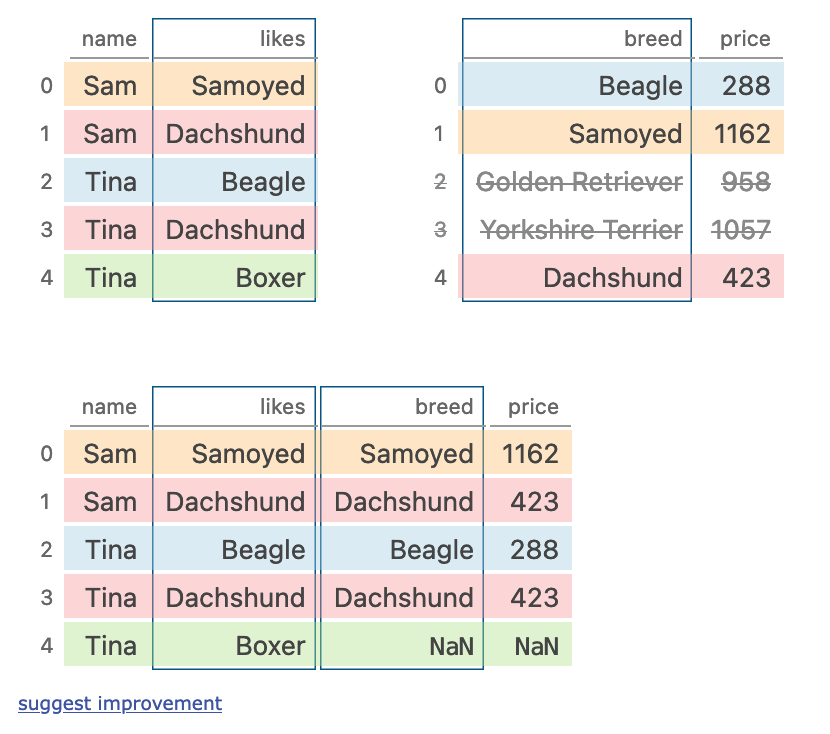
merging
ppl.merge(dogs, left_on='likes', right_on='breed', how='left')
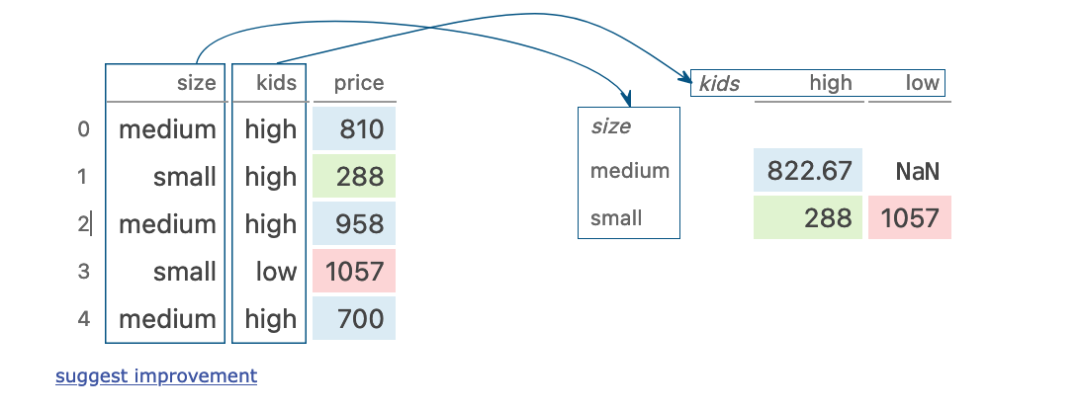
pivot table
dogs.pivot_table(index='size', columns='kids', values='price')
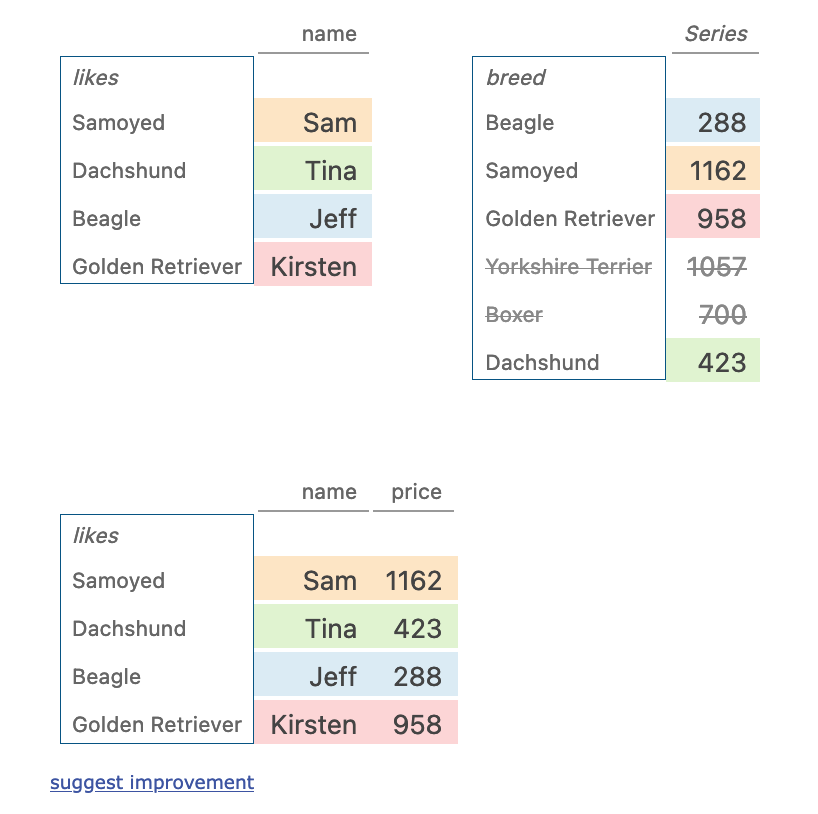
melting
dogs.melt()

pivoting
dogs.pivot(index='size', columns='kids')
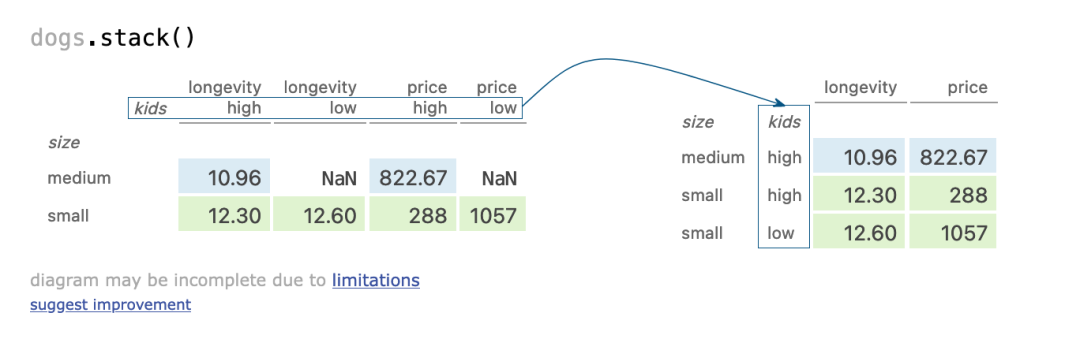
stacking column index
dogs.stack()
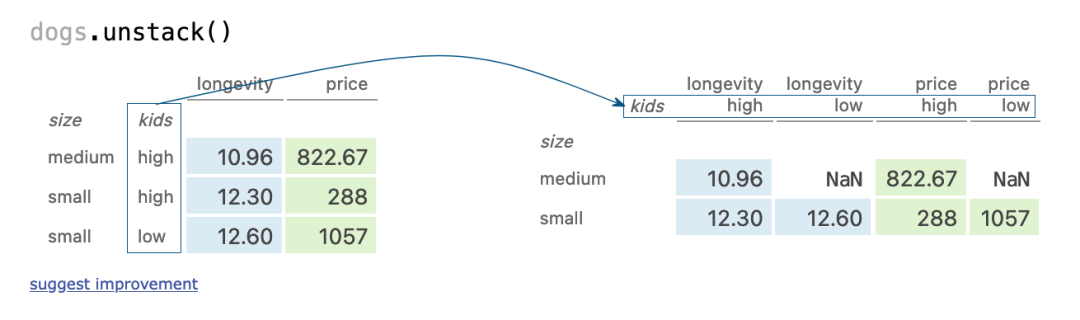
unstacking row index
dogs.unstack()
resetting index
dogs.reset_index()

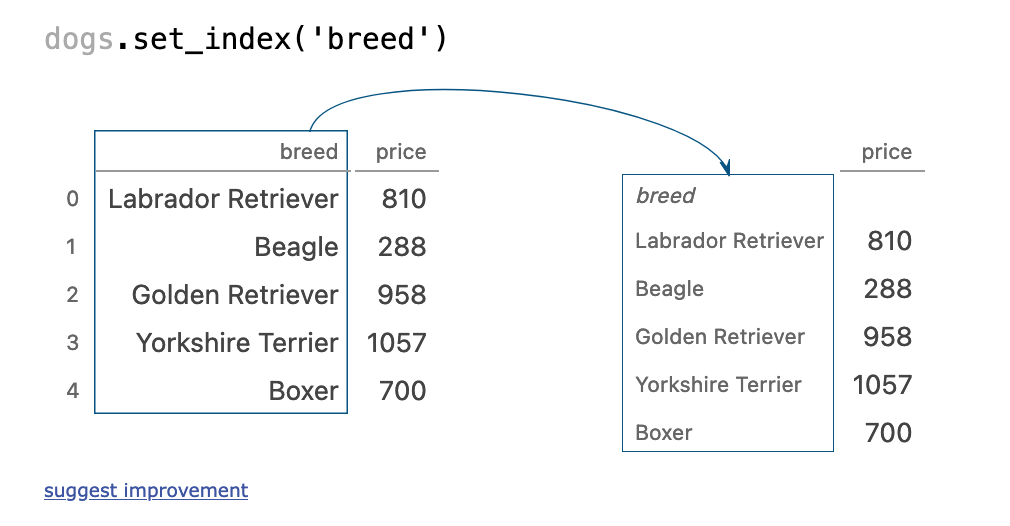
setting index
dogs.set_index('breed')
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
Microchip无感BLDC资料合集,强烈建议收藏2025-03-12 3670
-
最新!智慧灯杆在水域中的应用案例汇总(建议收藏)2025-01-07 1077
-
Linux 命令大全建议收藏2023-05-12 1788
-
图解Pandas常用操作!2023-04-25 1843
-
年度爆款技术好文Top 10,建议收藏!2023-01-19 1302
-
【CC2530授课笔记】课程列表汇总 【超级干货】【建议收藏】2021-11-29 852
-
探究pandas与GUI界面的超强结合2021-11-09 2330
-
pandas使用步骤2021-08-10 1292
-
pandas是什么2021-08-09 1374
-
pandas是什么?2021-07-14 743
-
关于“收藏”设置的建议2014-06-12 3625
-
无线路由器设置图解2011-11-10 8068
全部0条评论

快来发表一下你的评论吧 !
