

监控Kafka集群的常用的方法和工具介绍
安全设备/系统
描述
说完Kafka在企业级应用中的使用之后,接下来避免不了的话题就是故障监控和恢复了,今天咱们也来聊聊这个话题
监控Kafka集群
Kafka集群的监控是确保其正常运行和性能优化的关键步骤。下面列出了一些常用的方法和工具来监控Kafka集群:
JMX监控:Kafka提供了JMX(Java Management Extensions)接口,可以通过JMX来监控和管理Kafka集群。您可以使用JConsole、Java Mission Control等工具连接到Kafka Broker的JMX端口,并监控各种关键指标,如吞吐量、延迟、磁盘使用率、网络连接数等。
第三方监控工具:有许多开源和商业的监控工具可以用来监控Kafka集群。一些知名的工具包括:
Prometheus:一个流行的开源监控解决方案,可用于收集和存储Kafka的指标数据,配合Grafana进行展示和报警。
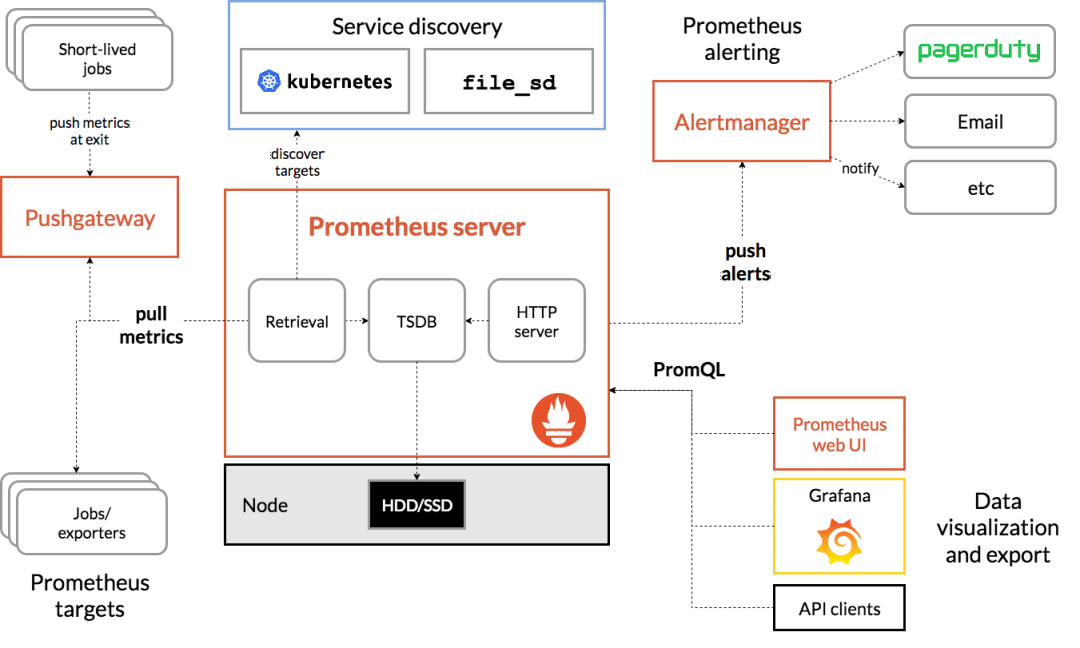
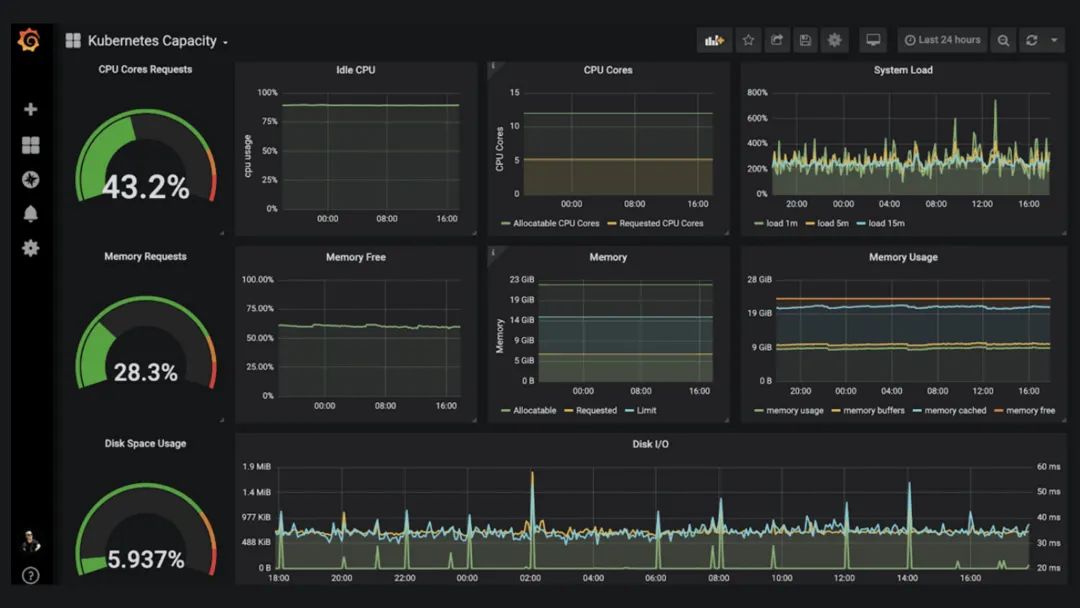
Grafana:一个功能强大的数据可视化平台,可与Prometheus等数据源集成,帮助您创建自定义的Kafka监控仪表盘。
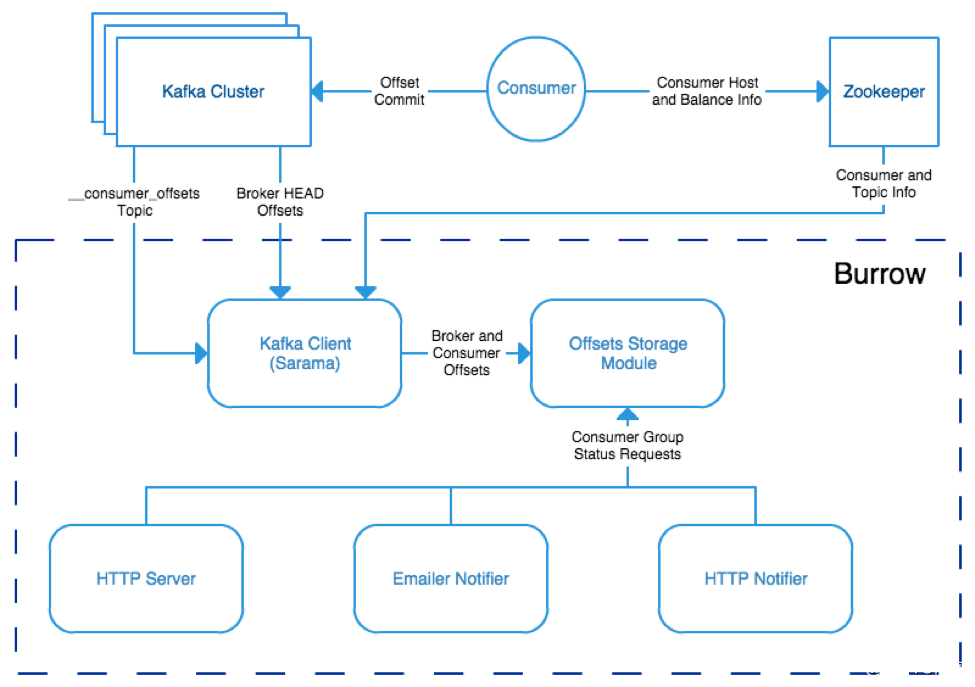
Burrow:一个专门用于监控Kafka消费者偏移量的工具,可及时检测消费者组的偏移量情况,发现消费者延迟和偏移量超限等问题。
Confluent Control Center:由Confluent官方提供的商业监控工具,提供了集中化的Kafka集群监控、性能指标和报警功能。
自定义监控脚本:您还可以编写自定义的脚本来监控Kafka集群。通过使用Kafka的Java客户端,您可以编写Java或Shell脚本来抓取和分析Kafka的相关指标数据,并进行报警或日志记录。
集群监控指标:关注以下关键指标可以帮助您深入了解Kafka集群的健康状况和性能表现:
Broker级别:吞吐量、延迟、磁盘使用率、网络连接数、日志大小等。
主题和分区级别:消息堆积数量、副本状态、ISR(In-Sync Replicas)数量、Leader选举次数等。
消费者组级别:消费者组的消费速率、偏移量的提交情况、延迟等。
通过综合使用多种监控工具和方法,您可以全面了解Kafka集群的状况,及时检测并解决潜在的问题,确保Kafka的稳定和高性能运行。
处理故障和实现恢复
高可用性设计 为确保Kafka集群对故障具有高可用性,推荐采用以下策略:
使用多个Kafka Broker来分散故障风险,并使用副本机制来保障数据的可靠性。
设置适当的复制因子,确保每个分区都有足够数量的副本。
配置适当的ISR(In-Sync Replicas)大小,以确保分区的可用性和数据一致性。
监控和错误日志 通过监控工具实时监测Kafka集群,并定期检查错误日志。如果发现错误和异常情况,可以根据日志信息进行故障定位和处理。同时,推荐开启Kafka集群的错误日志记录,以便更好地跟踪和分析故障问题。
快速故障恢复 当Kafka集群出现故障时,快速而可靠地进行故障恢复是至关重要的。下面是一些故障恢复的关键策略:
关注集群中的Leader选举过程,确保每个分区都有有效的Leader Broker。
注意分区副本的同步状态,当ISR(In-Sync Replicas)发生变化时及时采取措施。
针对不同类型的故障,根据实际情况执行恢复步骤,例如Broker故障、网络故障等。
测试和演练 持续对Kafka集群进行测试和演练,特别是故障恢复方面的测试。通过模拟不同类型的故障情况,验证集群的可用性和恢复能力,并及时修复潜在的问题。
总结:Kafka是一个强大的分布式消息中间件平台,但在运维和故障处理方面需要特别注意。通过监控Kafka集群的各项指标及时发现预警防止故障发生。
编辑:黄飞
-
基于kafka和zookeeper高可用集群的shell脚本使用步骤2019-03-11 2010
-
kafka架构与集群搭建2019-04-29 2029
-
基于闪存存储的Apache Kafka性能提升方法2019-07-24 1295
-
EFK63+kafka+logstash架构解读2019-08-15 1722
-
kafka集群设置shell脚本一键启动经验总结2019-09-18 2798
-
Kafka基础入门文档2020-03-12 1281
-
Kafka集群环境的搭建2021-01-05 1290
-
InfiniBand集群监控工具CLS的设计与实现2009-08-15 1268
-
Java数组的常用方法_Java:数组工具类Arrays类的常用方法的用法及代码2018-01-29 3243
-
如何将物联网数据从设备连接到Kafka集群?2020-07-28 1717
-
Kafka万亿级消息实战2022-11-25 1495
-
想要kafka好用你就得知道这些工具2023-05-22 2069
-
物通博联5G-kafka工业网关实现kafka协议对接到云平台2023-07-11 1587
-
kafka相关命令详解2023-10-20 2272
-
Kafka生产环境应用方案2025-07-09 771
全部0条评论

快来发表一下你的评论吧 !
