

云网络基础技术演进过程 网络虚拟化技术的高速发展趋势
通信网络
描述
来源 | OSCHINA 社区
作者 | 华为云开发者联盟
本文分享自华为云社区《重识云原生系列(四) —— 硬菜软嚼的云网络》,作者:黄俊 / 招商证券云原生转型项目调研负责人。 在传统 IT 架构中,网络几乎就是指物理网络设备,触手可及,服务器之间的网络通讯也是通过网线或者光纤连接实现,其大部分流量管控与访问控制策略也都是在路由器 / 交换机实现。而到了云计算时代,网络,除了包含传统的物理硬件设备,还包含大量虚拟化的网络设备软件应用,其运行在普通服务器中。而虚拟网络设备的连通,不仅需要底层真实硬件的支持,更需要关注软件形态的虚拟网络设备中的各种 Overlay 层的转发策略与流量监测,这对网络管理员而言也是前所未有的挑战。
伴生于云计算的云网络技术
云计算时代,资源的虚拟化和调配的自动化,为用户提供了可弹性伸缩、灵活配置的计算、存储资源,进而支持快速简便的业务系统发布。作为互联互通的网络基础设施,如何实现网络设备的虚拟化,从而进一步支持业务系统的快速扩缩容和网络通讯策略的自适应调配,为业务系统提供端到端的网络快速响应方案,成为了云计算时代急需解的核心关键问题。本质上讲,云网络技术就是要实现对数据中心底层物理网络设备的抽象,以期能在软件层实现对网络资源的二次切分、整合或者灵活管控,以便快速灵活地满足各种业务场景的网络使用需求,此即是软件定义网络(SDN)技术诞生的初衷。 云网络技术发展至今,就是以云为中心,一方面为支撑数据中心基础设施全面虚拟化而发展出来的网络硬件的虚拟化能力,此方面的能力表现为可标准化快速组网、可按需扩展网络资源容量、可灵活调配网络安全管控策略、支持计量计费、可全栈监控等;另一方面,因为公有云的蓬勃发展,也孕育出了面向企业租户的云上网络类产品与服务,通过对机房级通用网络设备或功能的模拟,以软件产品服务的方式提供给云上用户使用。
云网络基础技术演进
就云网络基础技术而言,其与计算虚拟化技术类似,也走过了一条精彩纷呈的硬件 “软化” 之路。
一切从 Spine-Leaf 架构说起
自从 1876 年电话被发明之后,电话交换网络历经了人工交换机、步进制交换机、纵横制交换机等多个阶段,而随着电话用户数量急剧增加,网络规模快速扩大,基于 crossbar 模型的纵横制交换机在能力和成本上都已无法满足要求。1953 年,贝尔实验室有一位名叫 Charles Clos 的研究员,发表了一篇名为《A Study of Non-blocking Switching Networks》的文章,介绍了一种 “用多级设备来实现无阻塞电话交换” 的方法,著名的 CLOS 网络模型就此诞生,其核心思想是 —— 用多个小规模、低成本的单元,构建复杂、大规模的网络,如下图所示: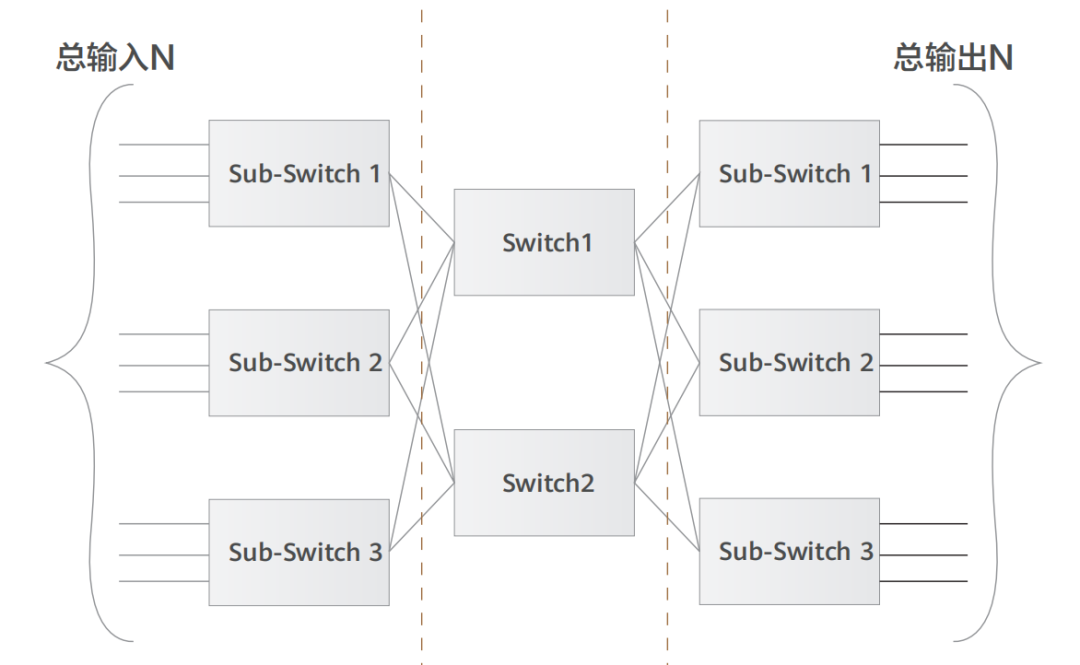 图中的矩形,都是低成本的转发单元。当输入和输出增加时,中间的交叉点并不需要增加很多。而到了 20 世纪 80 年代,随着计算机的大量使用,计算机网络技术也得到了长足的进步,开始出现各种网络拓扑结构,例如星型、链型、环型、树型结构,最终树型网络成为了行业主流架构,不过早期的树型结构网络带宽是收敛的。2000 年之后,互联网从经济危机中复苏,以谷歌和亚马逊为代表的互联网巨头迅速崛起。他们开始推行云计算技术,大量建设数据中心(IDC),甚至超级数据中心。面对日益庞大的计算集群规模,传统树型网络已无法满足要求,便诞生了一种改进型树型网络 —— 胖树(Fat-Tree)架构。相比于传统树型,胖树(Fat-Tree)更像是真实的树,越到树根,枝干越粗(其实是指带宽)。从叶子到树根,网络带宽无须收敛。胖树架构被引入到数据中心之后,数据中心便发展成了传统的三层结构(如下图所示)。
图中的矩形,都是低成本的转发单元。当输入和输出增加时,中间的交叉点并不需要增加很多。而到了 20 世纪 80 年代,随着计算机的大量使用,计算机网络技术也得到了长足的进步,开始出现各种网络拓扑结构,例如星型、链型、环型、树型结构,最终树型网络成为了行业主流架构,不过早期的树型结构网络带宽是收敛的。2000 年之后,互联网从经济危机中复苏,以谷歌和亚马逊为代表的互联网巨头迅速崛起。他们开始推行云计算技术,大量建设数据中心(IDC),甚至超级数据中心。面对日益庞大的计算集群规模,传统树型网络已无法满足要求,便诞生了一种改进型树型网络 —— 胖树(Fat-Tree)架构。相比于传统树型,胖树(Fat-Tree)更像是真实的树,越到树根,枝干越粗(其实是指带宽)。从叶子到树根,网络带宽无须收敛。胖树架构被引入到数据中心之后,数据中心便发展成了传统的三层结构(如下图所示)。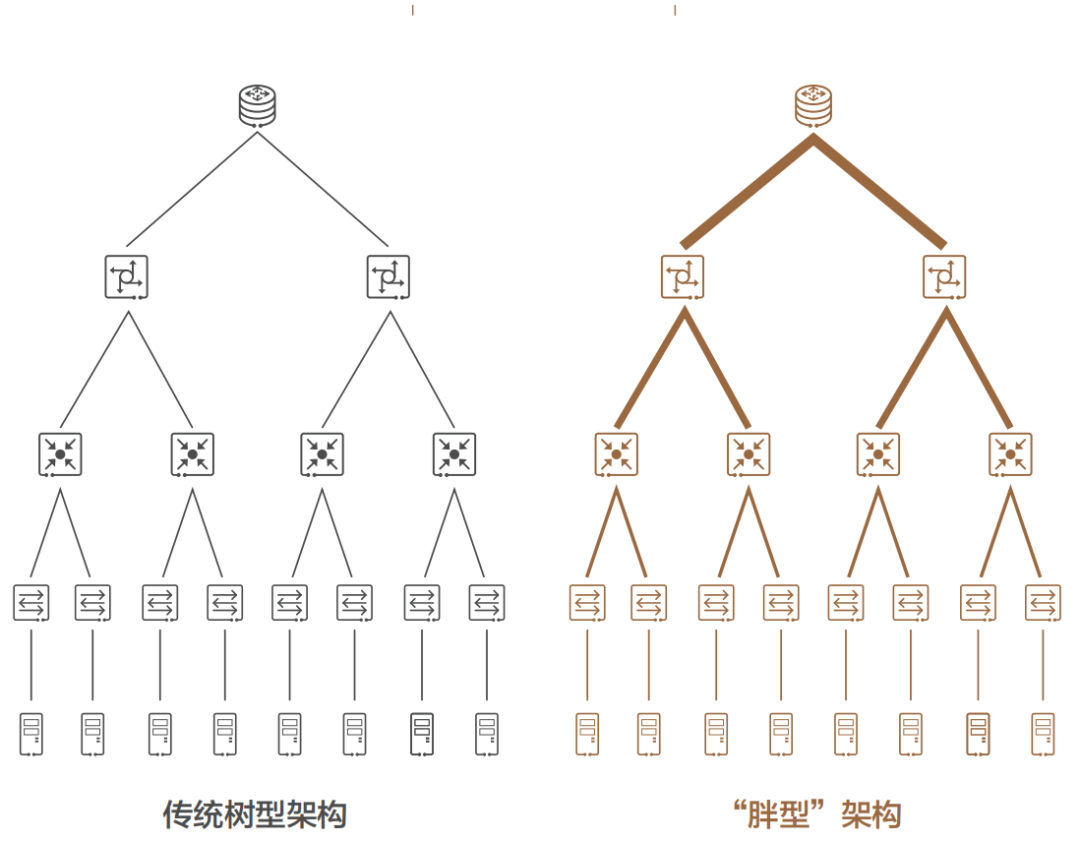 这种架构由核心路由器、聚合路由器(有时叫分发路由器,distribution routers )和接入交换机组成。在很长的一段时间里,三层网络结构在数据中心十分盛行。但在这种网络架构下,依然存在如下一些弊端:» 带宽的浪费,接入交换机的上联链路实际承载流量的只有一条,而其他上行链路则被阻塞(如图中虚线所示);» 故障域较大,在网络拓扑发生变更时 STP 协议需要重新收敛,容易发生故障,从而影响整个 VLAN 的网络;» 此架构原生不支持大二层网络的构建,故难以适应超大规模云平台网络需求,更无法支持虚拟机动态迁移;
这种架构由核心路由器、聚合路由器(有时叫分发路由器,distribution routers )和接入交换机组成。在很长的一段时间里,三层网络结构在数据中心十分盛行。但在这种网络架构下,依然存在如下一些弊端:» 带宽的浪费,接入交换机的上联链路实际承载流量的只有一条,而其他上行链路则被阻塞(如图中虚线所示);» 故障域较大,在网络拓扑发生变更时 STP 协议需要重新收敛,容易发生故障,从而影响整个 VLAN 的网络;» 此架构原生不支持大二层网络的构建,故难以适应超大规模云平台网络需求,更无法支持虚拟机动态迁移;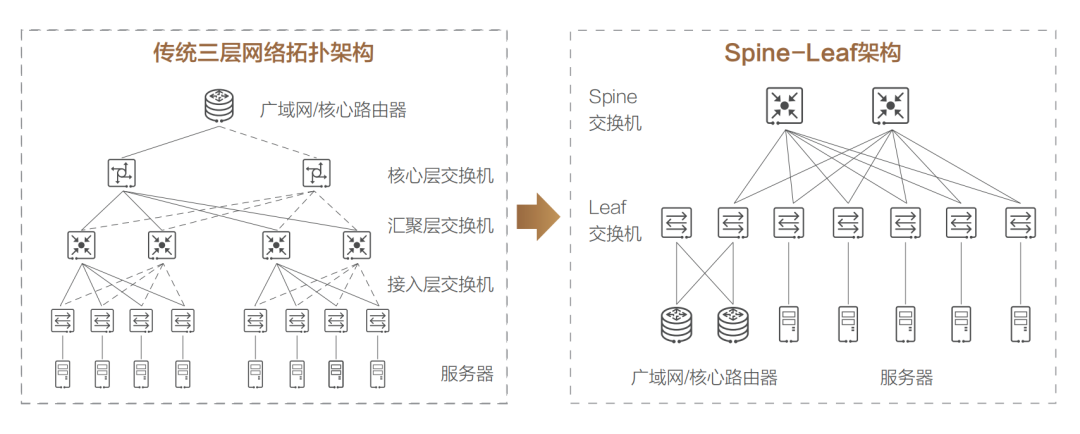 针对以上问题,诞生了一种新的数据中心网络设计方案,称作基于 CLOS 网络的 Spine-Leaf 架构(Clos network-based Spine-and-Leaf architecture,中文也翻译成叶脊网络)。实践已经证明,这种架构可以提供高带宽、低延迟、非阻塞的数据中心级连接服务。相比于三层架构,Spine-Leaf 架构进行了扁平化处理,变成了两层架构,如上图右侧所示。 Spine-Leaf 架构的优势非常明显: 1、带宽利用率高,每个叶交换机的上行链路都可以负载均衡方式工作; 2、网络延迟可预测,叶交换机之间的连通路径均只需经过一台 Spine 交换机,东西向网络延时可预测; 3、扩展性好,当上行带宽不足时,可通过水平扩展方式增加 Spine 交换机数量来快速增加带宽;当服务器数量增加时,则可通过增加 Leaf 交换机数量来快速扩大数据中心机器规模。 4、降低了对交换机的性能要求,东西向流量均衡分布在多条链路上,减少了单价昂贵的高性能高带宽交换机的采购需求。 5、安全性和可用性高,一台设备故障时,不需重新收敛,流量继续在其他正常路径上通过,网络连通性不受影响,带宽也只减少一条路径的带宽,性能影响微乎其微。 基于上述优势,Spine-Leaf 架构从 2013 年一经出现,便很快取代了传统三层网络架构的地位,成为现代数据中心的新标准。
针对以上问题,诞生了一种新的数据中心网络设计方案,称作基于 CLOS 网络的 Spine-Leaf 架构(Clos network-based Spine-and-Leaf architecture,中文也翻译成叶脊网络)。实践已经证明,这种架构可以提供高带宽、低延迟、非阻塞的数据中心级连接服务。相比于三层架构,Spine-Leaf 架构进行了扁平化处理,变成了两层架构,如上图右侧所示。 Spine-Leaf 架构的优势非常明显: 1、带宽利用率高,每个叶交换机的上行链路都可以负载均衡方式工作; 2、网络延迟可预测,叶交换机之间的连通路径均只需经过一台 Spine 交换机,东西向网络延时可预测; 3、扩展性好,当上行带宽不足时,可通过水平扩展方式增加 Spine 交换机数量来快速增加带宽;当服务器数量增加时,则可通过增加 Leaf 交换机数量来快速扩大数据中心机器规模。 4、降低了对交换机的性能要求,东西向流量均衡分布在多条链路上,减少了单价昂贵的高性能高带宽交换机的采购需求。 5、安全性和可用性高,一台设备故障时,不需重新收敛,流量继续在其他正常路径上通过,网络连通性不受影响,带宽也只减少一条路径的带宽,性能影响微乎其微。 基于上述优势,Spine-Leaf 架构从 2013 年一经出现,便很快取代了传统三层网络架构的地位,成为现代数据中心的新标准。
大二层网络的时代召唤
在上一节,我们谈到 Spine-Leaf 架构出现的时候,其实已经点到了大二层网络的出现因由。 云计算技术的出现,使得服务器虚拟化之后,除了使得数据中心的主机规模大幅增长,还伴生了一项新需求 —— 虚拟机的动态迁移。虚拟机迁移时,业务不能中断,这就要求在迁移时,不仅虚拟机的 IP 地址不变,而且虚拟机的运行状态也必须保持原状(例如 TCP 会话状态)。所以虚拟机的动态迁移只能在同一个二层域中进行,而不能跨二层域迁移。而传统的三层网络架构就限制了虚拟机的动态迁移只能在一个较小的 VLAN 范围内进行,应用受到了极大的限制。 为了打破这种限制,实现虚拟机的大范围甚至跨地域的动态迁移,就要求把 VM 迁移可能涉及的所有服务器都纳入同一个二层网络域,这样才能实现 VM 的大范围无障碍迁移。这便是大二层网络。 近十年间,就大二层网络的实现,业界先后出现了三类比较典型的实现方案,分别是网络设备虚拟化类方案、L2 over L3 方案、Overlay 方案。所谓网络设备虚拟化技术,就是将相互冗余的两台或多台物理网络设备组合在一起,虚拟化成一台逻辑网络设备,在整个网络中只呈现为一个节点。再配合链路聚合技术,就可以把原来的多节点、多链路的结构变成逻辑上单节点、单链路的结构,环路问题也就顺势而解了。以网络设备虚拟化 + 链路聚合技术构建的二层网络天然没有环路,其规模仅受限于虚拟网络设备所能支持的接入能力,只要虚拟网络设备允许,二层网络想做多大都可以。不过,这类设备虚拟化协议大都是网络设备厂商私有,因此只能使用同一厂商的设备来组网,并且,网络规模最终还是会受限于堆叠系统本身的规模限制,最大规模的堆叠 / 集群大概可以支持接入 1~2 万台主机,对于 10 万级别的超大型数据中心来说,还是显得力不从心。 而 L2 over L3 方案的着眼点不是杜绝或者阻塞环路,而是在有物理环路的情况下,怎样避免逻辑转发路径的环路问题。此类方案通过在二层报文前插入额外的帧头,并且采用路由计算的方式控制整网数据的转发,不仅可以在冗余链路下防止广播风暴,而且可以做 ECMP(等价路由),这样就可以将二层网络的规模扩展到整张网络,而不会受到核心交换机数量的限制。当然,这需要交换机改变传统的基于 MAC 的二层转发行为,而采用新的协议机制来进行二层报文的转发,这些新的协议包括 TRILL、FabricPath、SPB 等。对于 TRILL 协议,CISCO、华为、Broadcom、Juniper 等都是其支持者;而 Avaya、ALU 等则是 SPB 的拥簇;而像 HP 等厂商,则同时支持这两类协议。总体而言,像 TRILL 和 SPB 这类技术都是 CT 厂商主推的大二层网络技术方案,而从事服务器虚拟化技术的 IT 厂商则被晾到了一边,网络话语权大幅削弱。 但伴随着云计算技术迅猛发展的 IT 厂商又岂会坐以待毙,Overlay 方案便是从事服务器虚拟化技术的 IT 厂商主推的大二层网络解决方案。其原理就是通过用隧道封装的方式,将源主机发出的原始二层报文封装后,再在现有网络中进行透传,到达目的地之后再解封为原始报文,转发给目标主机,从而实现主机之间的二层通信。报文的封装 / 解封装都是在服务器内部的虚拟交换机 vSwitch 上进行,外部网络只对封装后的报文进行普通的二层交换和三层转发即可,所以网络技术控制权就都回到了 IT 厂商手里。典型技术实现包括 VXLAN、NVGRE、STT 等。当然,目前 CT 厂商也都积极参与到了 Overlay 方案中来,毕竟云计算是大势所趋。所以当前的 VXLAN 和 NVGRE 技术也可以把 Overlay 网络的接入点部署在 TOR 等网络设备上,由网络接入设备来完成 VXLAN 和 NVGRE 的报文封装。这样的好处是: » 一方面对于虚拟服务器来说,硬件网络设备的性能要比软件形态的 vSwitch 强很多,用 TOR 等设备来进行封装 / 解封装,整体云网络性能自然更好。 » 另一方面,在 TOR 上部署 Overlay 接入点,也便于把非虚拟化的服务器统一纳入 Overlay 网络,目前主流云厂商的裸金属方案基本如此。 如此一来,CT 厂商和 IT 厂商都在大二层网络这个领域实现了和谐共赢,也真因为如此,Overlay 方案成为了当今大二层网络的主流方案。
Underlay 和 Overlay 正式托起 SDN 的太阳
上一节已经提及,Overlay 技术实际上是一种隧道封装技术,主流协议有 VXLAN、NVGRE 等,基本原理都是通过隧道封装的方式将二层报文进行封装后在现有网络中进行透明传输,到达目的地之后再解封装得到原始报文,相当于一个大二层网络叠加(overlay)在现有的网络之上。而 Underlay 层则变成了一张承载网,囊括各类物理网络设备,如 TOR 交换机、汇聚交换机、核心交换机、负载均衡设备、防火墙设备等。由此实现逻辑组网与物理组网的隔离,例如,在华为云 / 阿里云解决方案中,均选用了 VXLAN 技术来构建 Overlay 网络,业务报文运行在 VXLAN Overlay 网络上,与物理承载网络分层、解耦。 而对于当前走红的 SDN 技术,Underlay/Overlay 已经成为了其从理念到实践都不可或缺的一部分。 在数据中心之内或者数据中心互联(DCI)的场景下,运营方会先建立一个底层的 Underlay 网络骨架,通过交换机和路由器将所有硬件单元(比如服务器 / 存储设备 / 监控设备等)相互连接。在这个 Underlay 网络内,通过运行 IP 网络协议比如 ISIS 或者 BGP,来保证各个在网硬件单元之间的可达性。在完成 Underlay 网络构架之后,管理员可以通过部署 SDN 控制器的方式来对整网所有硬件资源进行调控与编排,再建立租户之间的 Overlay 网络连接并承载真正的用户流量。 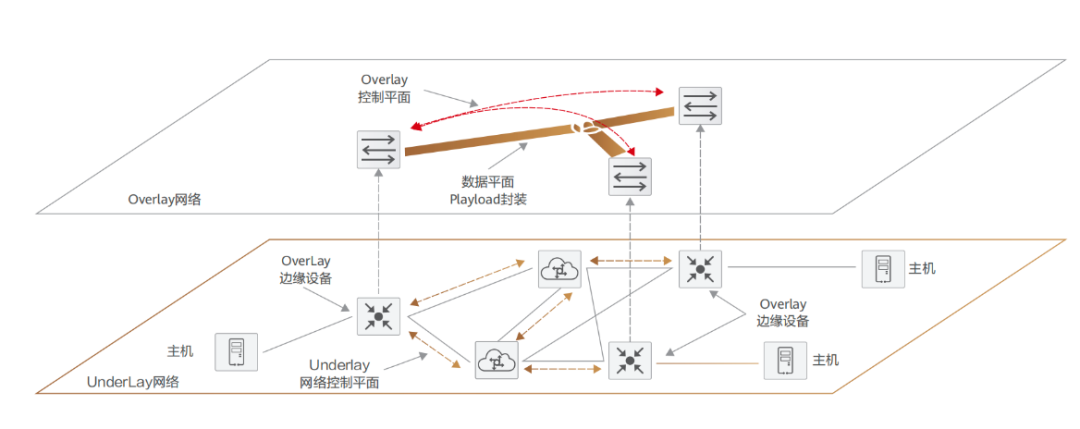
SDN 技术让封闭硬件 “软化” 开放
软件定义网络(Software Define Network,SDN)技术是对传统网络架构的一次重构,其核心思想是通过控制面(Control Plane)与数据面(Data Plane)的分离,将网络的管理权限交给控制层的控制器软件,在通过 OpenFlow 协议通道,统一下达指令给数据转发层设备,从而实现网络控制与数据转发的充分解耦,一举破除传统网络设备的封闭性。 由于 OpenFlow 协议的开放性,第三方也可以开发相应的应用置于控制层内,从而使得网络资源的调配更加灵活、更能满足企业个性化场景。而网络管理人员只需通过控制器下达指令至数据层设备即可,无需一一登录设备,从而大幅提高了网络管理效率,节省了人力成本。可以说,SDN 技术极大地推动了网络虚拟化的发展进程,也因此,其网络架构设计思想在当今各大云平台均得到了充分实现与落地。SDN 有过三种主流实现方式,分别是 OpenFlow 组织主导的开源软件(包括 Google,IBM,Citrix 等公司支持),思科主导的应用中心基础设施技术(Application Centric Infrastructure,ACI),以及 VMware 主导的 NSX。显而易见,开源的 OpenFlow 成为了事实上的行业标准。 
SDN 的价值
支撑网络业务快速创新
SDN 的可编程性和开放性,使得我们可以快速开发新的网络业务和加速业务创新。如果希望在网络上部署新业务,可以通过针对 SDN 软件的修改实现网络快速编程,业务快速上线。SDN 架构下,底层硬件只需关注转发和存储能力,与业务特性彻底解耦。而网络设备的种类及功能由软件配置而定,对网络的操作控制和运行也由控制层服务器完成,故而对业务响应相对更快,可以定制各种网络参数(如路由、安全策略、QoS 等),并实时配置到网络中。如此,新业务的上线周期可从传统网络的几年提升到几个月甚至更快。
简化网络协议结构
SDN 的网络架构简化了网络拓扑结构,可消除很多 IETF 协议。协议的去除,意味着运维学习门槛的下降、运行维护复杂度的降低,进而使业务部署效率提升。因为 SDN 网络架构下的网络集中控制,所以被 SDN 控制器所控制的网络内部很多协议基本就不需要了,比如 RSVP 协议、LDP 协议、MBGP 协议、PIM 组播协议等等。网络内部的路径计算和建立全部在控制器完成,控制器计算出流表,直接下发给转发器就行,并不需要其他协议。
网络设备白牌化
SDN 架 构 下,控 制 器 和 转 发器 之间 的 接口协议 逐 渐标 准 化(比 如 OpenFlow 协议),使得网络设备的 白 牌 化 成 为可 能,比 如 专 门 的 OpenFlow 转发芯片供应商,控制器厂商等,这也正是所谓的系统从垂直集成开发走向水平集成开发。垂直集成是指由一个厂家提供从软件到硬件到服务的一体化产品服务,水平集成则是把系统水平分工,每个厂家都完成产品的一个部件,再由集成商把他们集成起来销售。水平分工有利于系统各个部分的独立演进和更新,快速迭代优化,促进良性竞争,从而使各个部件的采购单价下降,最终使得整机产品的采购成本大幅降低。
业务自动化
SDN 网络架构下,由于整个网络由 SDN 控制器控制,故 SDN 控制器可以自主完成网络业务部署,并提供各种网络个性化配置服务,比如 L2VPN、L3VPN 等,对外屏蔽网络内部细节,提供网络业务自动化能力。网络路径流量智能优化传统网络中,网络路径的选择依据是通过各类路由协议计算得出所谓 “最优” 路径,但此结果反而可能会导致 “最优” 路径上的流量拥塞,其他非 “最优” 路径带宽空闲。而采用 SDN 网络架构时,SDN 控制器可以根据各链路上网络流量的状态智能调整网络流量路径,从整网角度出发,整体性提升网络传输效率。
SDN 催化的网络虚拟技术狂飙
接下来,我们分别从网络设备虚拟化、链路虚拟化和虚拟网络三个层面来看看网络虚拟化技术的高速发展。
网络设备虚拟化
网络设备虚拟化技术是云网络技术发展最为迅猛且影响最大的领域,其 主要包括网卡虚拟化(NIC Virtualization)与常规网络设备虚拟化两大方向。 一、网卡虚拟化 网卡虚拟化技术演进路线与我们在《重识云原生第三篇:软饭硬吃的计算》一文中对于 I/O 虚拟化的演进路线基本一致,也是经历了纯软虚拟化(即 Qemu、VMware Workstation 虚拟网卡实现方案)、半虚拟化(Virtio、Vhost-net、Vhost-user 系列方案),再到硬件直通方案(SR-IOV),最后到硬件卸载(vPDA、DPU 等)。 网卡虚拟化的产品形态即是公有云常见的虚拟网卡,其主要通过软件控制各个虚拟机共享同一块物理网卡实现,虚拟网卡可以有单独的 MAC 地址、IP 地址,早期结构如下图所示。所有虚拟机的虚拟网卡通过虚拟交换机以及物理网卡连接至物理交换机。虚拟交换机负责将虚拟机上的数据报文从物理网口转发出去。根据需要,虚拟交换机还可以支持安全控制等功能。 虚拟网卡包括 e1000、Virtio 等实现技术。Virtio 是目前最为通用的技术框架,其提供了虚拟机和物理服务器数据交换的通用方案,得到了大多数 Hypervisor 的支持,成为事实上的标准。 Virtio 是一种半虚拟化的解决方案,在半虚拟化方案中,Guest OS 知道自己是虚拟机,通过前端驱动和后端模拟设备互相配合实现 IO 虚拟化。这种方式与全虚拟化相比,可以大幅度提高虚拟机的 IO 性能。 最初的 Virtio 通信机制中,Guest 与用户空间的 Hypervisor 通信,会有多次数据拷贝和 CPU 特权级的切换。Guest 发包给外部网络,需要切换到内核态的 KVM,然后 KVM 通知用户空间的 QEMU 处理 Guest 网络请求。很显然,这种通信方式效率并不高。很快,Virtio 技术演进中便出现了内核态卸载的方案 Vhost-net。 Vhost-net 是 Virtio 的一种后端实现方案,与之相匹配的是一套新的 Vhost 协议。Vhost 协议允许 VMM 将 Virtio 的数据面 Offload 到另一个组件上,而这个组件是 Vhost-net。Vhost-net 在 OS 内核中实现,其与 Guest 直接通信,旁路了 KVM 和 QEMU。QEMU 和 Vhostnet 使用 ioctl 来交换 Vhost 消息,并且用 eventfd 来实现前后端的事件通知。当 Vhost-net 内核驱动加载后,它会暴露一个字符设备标识在 /dev/Vhost-net, 而 QEMU 会打开并初始化这个字符设备,并调用 ioctl 来与 Vhost-net 进行控制面通信,其内容包含 Virtio 的特性协商、将虚拟机内存映射传递给 Vhost-net 等。对比最原始的 Virtio 网络实现,控制平面在原有执行基础上转变为 Vhost 协议定义的 ioctl 操作(对于前端而言仍是通过 PCI 传输层协议暴露的接口),基于共享内存实现的 Vring 数据传递转变为 Virtio-net 与 Vhost-net 共享;数据平面的另一方转变则为 Vhost-net,前后端通知方式也转为基于 eventfd 来实现。 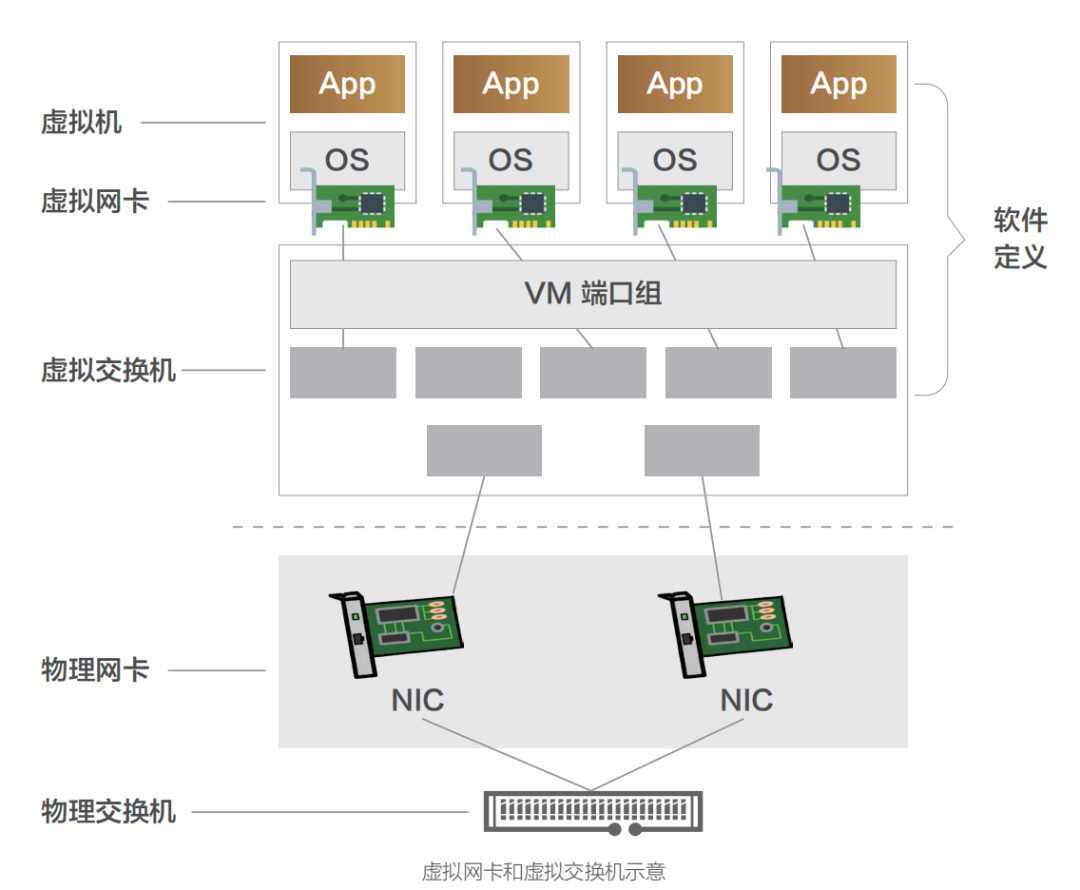
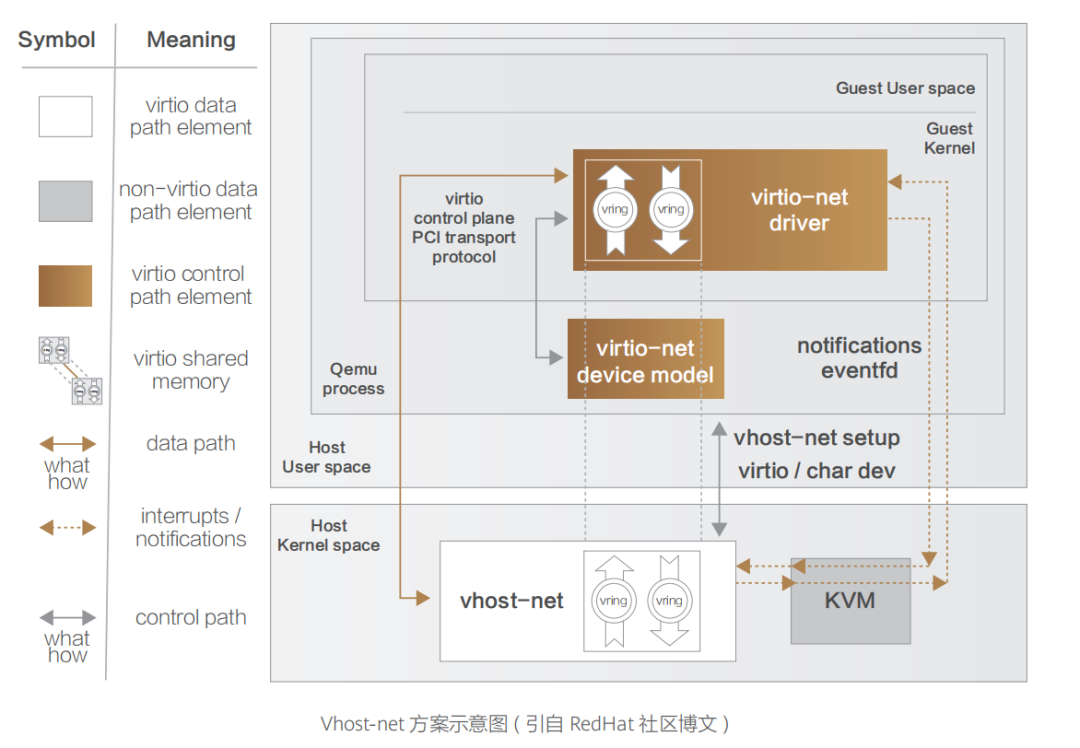 在单次收发的过程中,数据通道减少了两次用户态与内核态的上下文切换过程,实现了数据通道在内核态的卸载,从而较大程度提升了数据传输效率。 但是,对于某些用户态进程间的通信,比如数据面的通信方案(例如 Open vSwitch 和与之类似的 SDN 解决方案),Guest 仍需要和 Host 用户态的 vSwitch 进行数据交换,如果采用 Vhost-net 方案,Guest 和 Host 之间还是存在多次上下文切换和数据拷贝,为了避免这种情况,业界就想出将 Vhost-net 从内核态移到用户态的方案,这就是 Vhost-user 方案的实现思路。
在单次收发的过程中,数据通道减少了两次用户态与内核态的上下文切换过程,实现了数据通道在内核态的卸载,从而较大程度提升了数据传输效率。 但是,对于某些用户态进程间的通信,比如数据面的通信方案(例如 Open vSwitch 和与之类似的 SDN 解决方案),Guest 仍需要和 Host 用户态的 vSwitch 进行数据交换,如果采用 Vhost-net 方案,Guest 和 Host 之间还是存在多次上下文切换和数据拷贝,为了避免这种情况,业界就想出将 Vhost-net 从内核态移到用户态的方案,这就是 Vhost-user 方案的实现思路。 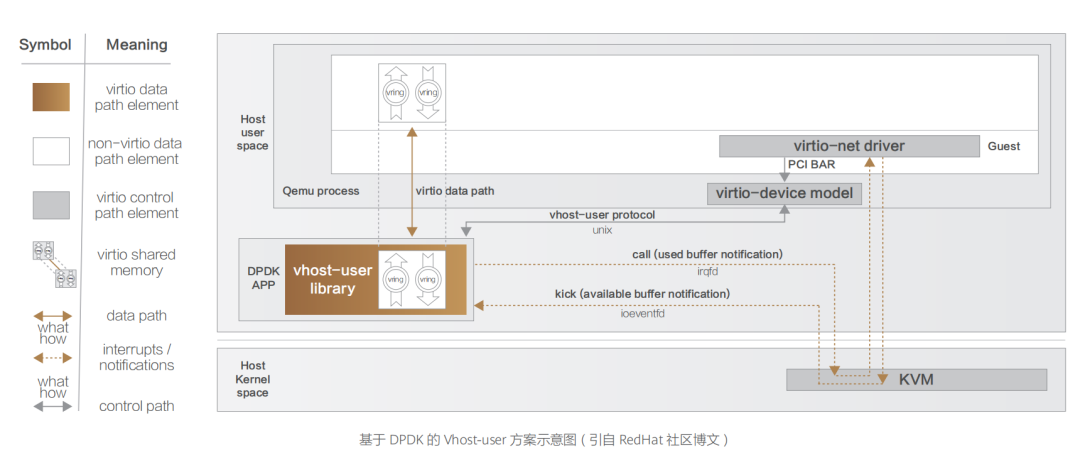 基于 Vhost 协议,DPDK 设计了一套新的用户态协议 ——Vhost-user。该协议将网络包处理(数据平面)卸载到用户态的 DPDK 应用中,控制平面仍然由 QEMU 来配置 Vhost-user。除此之外,DPDK 优化实现了处理器亲和性管理、NUMA 调度、使用大页内存代替普通内存、采用无锁技术解决资源竞争问题、轮询模式驱动等技术,由此,大名鼎鼎的 DPDK 网络卸载方案蔚然成型。 纵如此,技术迭代演进是永无止境的,虽然上述方案对网络性能的提升非常显著,但总体而言,Virtio 网络虚拟化方案一直都聚焦在软件层实现,在 Host 上因软件虚拟化而产生的额外开销始终无法避免。为了进一步提升云端网络服务的性能,RedHat 的技术专家们提出可以将 Virtio 功能 Offload 到专用硬件,将与业务无关的任务 Bypass 操作系统和 CPU,转而直接交给专用硬件执行,从而进一步提升网络性能,这便是 vDPA 硬件卸载方案的设计初衷,也是 Virtio 半硬件虚拟化方案的早期硬件方案实现思路。 该框架由 Redhat 提出,实现了 Virtio 数据平面的硬件卸载。控制平面仍然采用原来的控制平面协议,当控制信息被传递到硬件中,硬件完成数据平面的配置之后,数据通信过程由硬件设备 SmartNIC(即智能网卡)完成,Guest 虚拟机与网卡之间直接通信。中断信息也由网卡直接发送至 Guest 而不需要 Host 主机的干预。这种方式在性能方面能够接近 SR-IOV 硬件直通方案,同时能够继续使用 Virtio 标准接口,保持云服务的兼容性与灵活性。但是其控制面处理逻辑比较复杂,通过 OVS 转发的流量首包依然需要由主机上的 OVS 转发平面处理,对应数据流的后续报文才能由硬件网卡直接转发,硬件实现难度较大。 不过,随着越来越多的硬件厂商开始原生支持 Virtio 协议,将网络虚拟化功能 Offload 到硬件上,把嵌入式 CPU 集成到 SmartNIC(即智能网卡)中,网卡能处理所有网络数据,而嵌入式 CPU 负责控制路径的初始化并处理异常情况。这种具有硬件 Offload 能力的 SmartNIC 就是如今越来越火的 DPU。
基于 Vhost 协议,DPDK 设计了一套新的用户态协议 ——Vhost-user。该协议将网络包处理(数据平面)卸载到用户态的 DPDK 应用中,控制平面仍然由 QEMU 来配置 Vhost-user。除此之外,DPDK 优化实现了处理器亲和性管理、NUMA 调度、使用大页内存代替普通内存、采用无锁技术解决资源竞争问题、轮询模式驱动等技术,由此,大名鼎鼎的 DPDK 网络卸载方案蔚然成型。 纵如此,技术迭代演进是永无止境的,虽然上述方案对网络性能的提升非常显著,但总体而言,Virtio 网络虚拟化方案一直都聚焦在软件层实现,在 Host 上因软件虚拟化而产生的额外开销始终无法避免。为了进一步提升云端网络服务的性能,RedHat 的技术专家们提出可以将 Virtio 功能 Offload 到专用硬件,将与业务无关的任务 Bypass 操作系统和 CPU,转而直接交给专用硬件执行,从而进一步提升网络性能,这便是 vDPA 硬件卸载方案的设计初衷,也是 Virtio 半硬件虚拟化方案的早期硬件方案实现思路。 该框架由 Redhat 提出,实现了 Virtio 数据平面的硬件卸载。控制平面仍然采用原来的控制平面协议,当控制信息被传递到硬件中,硬件完成数据平面的配置之后,数据通信过程由硬件设备 SmartNIC(即智能网卡)完成,Guest 虚拟机与网卡之间直接通信。中断信息也由网卡直接发送至 Guest 而不需要 Host 主机的干预。这种方式在性能方面能够接近 SR-IOV 硬件直通方案,同时能够继续使用 Virtio 标准接口,保持云服务的兼容性与灵活性。但是其控制面处理逻辑比较复杂,通过 OVS 转发的流量首包依然需要由主机上的 OVS 转发平面处理,对应数据流的后续报文才能由硬件网卡直接转发,硬件实现难度较大。 不过,随着越来越多的硬件厂商开始原生支持 Virtio 协议,将网络虚拟化功能 Offload 到硬件上,把嵌入式 CPU 集成到 SmartNIC(即智能网卡)中,网卡能处理所有网络数据,而嵌入式 CPU 负责控制路径的初始化并处理异常情况。这种具有硬件 Offload 能力的 SmartNIC 就是如今越来越火的 DPU。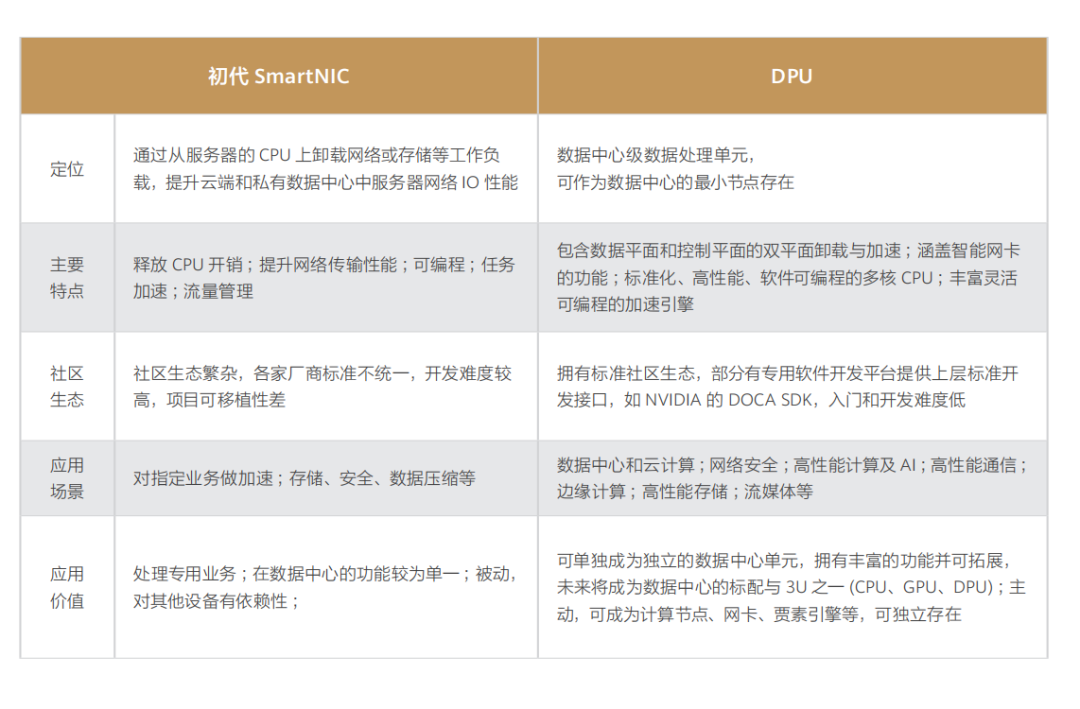 二、网络设备虚拟化 硬件设备虚拟化主要有两个方向:在传统的基于 x86 架构机器上安装特定操作系统来实现路由功能。 前者的早期典型产品是 Mikrotik 公司开发的 RouterOS,其基于 Linux 内核开发,可以安装在标准的 x86 架构的机器上,从而使普通 Linux 服务器也可以当成路由器使用。此类设备以其低廉的价格和不受硬件平台约束等特性,占据了不少低端路由器市场。现如今,国内外主流云厂商对于 SDN 控制面的实现思路大抵都是如此。 而后者主要是应第一代云计算技术的市场需求催生,在计算虚拟化之后,数据中心通讯规模大幅增长,传统路由器中的单张路由表已经不能满足需求,因此催生了虚拟路由转发(Virtual Routing and Forwarding,VRF)技 术,即 是 将 路 由 信 息 库(Forwarding Information Base,FIB)虚拟化成多个路由转发表。此技术诞生背景主要为增加大型通讯设备的端口利用率,减少设备成本投入,将一台物理设备虚拟化成多台虚拟设备,每台虚拟设备仅维护自身的路由转发表即可,比如思科的 N7K 系列交换机可以虚拟化成多台 VDC。所有 VDC 共享物理机箱的计算资源,但又各自独立工作,互不影响。此外,为了便于维护、管理和控制,将多台物理设备虚拟化成一台虚拟设备的融合虚拟化技术也有一定市场,比如 H3C 公司的 IRF 技术。
二、网络设备虚拟化 硬件设备虚拟化主要有两个方向:在传统的基于 x86 架构机器上安装特定操作系统来实现路由功能。 前者的早期典型产品是 Mikrotik 公司开发的 RouterOS,其基于 Linux 内核开发,可以安装在标准的 x86 架构的机器上,从而使普通 Linux 服务器也可以当成路由器使用。此类设备以其低廉的价格和不受硬件平台约束等特性,占据了不少低端路由器市场。现如今,国内外主流云厂商对于 SDN 控制面的实现思路大抵都是如此。 而后者主要是应第一代云计算技术的市场需求催生,在计算虚拟化之后,数据中心通讯规模大幅增长,传统路由器中的单张路由表已经不能满足需求,因此催生了虚拟路由转发(Virtual Routing and Forwarding,VRF)技 术,即 是 将 路 由 信 息 库(Forwarding Information Base,FIB)虚拟化成多个路由转发表。此技术诞生背景主要为增加大型通讯设备的端口利用率,减少设备成本投入,将一台物理设备虚拟化成多台虚拟设备,每台虚拟设备仅维护自身的路由转发表即可,比如思科的 N7K 系列交换机可以虚拟化成多台 VDC。所有 VDC 共享物理机箱的计算资源,但又各自独立工作,互不影响。此外,为了便于维护、管理和控制,将多台物理设备虚拟化成一台虚拟设备的融合虚拟化技术也有一定市场,比如 H3C 公司的 IRF 技术。
链路虚拟化
链路虚拟化是日常使用最多的网络虚拟化技术之一,增强了网络的可靠性与便利性。常见的链路虚拟化技术有链路聚合和隧道协议,此部分内容在《第四篇 - 硬菜软嚼的网络 (上)》篇已有详细阐述,此处只简单提一下。 链路聚合(Port Channel)是最常见的二层虚拟化技术。链路聚合将多个物理端口捆绑在一起,虚拟成为一个逻辑端口。当交换机检测到其中一个物理端口链路发生故障时,就停止在此端口上发送报文,根据负载分担策略在余下的物理链路中选择报文发送的端口。链路聚合可以增加链路带宽、实现链路层的高可用性。 隧道协议(Tunneling Protocol)指一种技术 / 协议的两个或多个子网穿过另一种技术 / 协议的网络实现互联。隧道协议将其他协议的数据帧或包重新封装然后通过隧道发送。新的帧头提供路由信息,以便通过网络传递被封装的负载数据。隧道可以将数据流强制送到特定的地址,并隐藏中间节点的网络地址,还可根据需要,提供对数据加密的功能。当前典型的隧道的协议便是 VXLAN、GRE 和 IPsec。当今各大云厂商的云平台的网络实现方案莫不基于此。
虚拟网络
虚拟网络(Virtual Network)是由虚拟链路组成的网络。虚拟网络节点之间的连接并不使用物理线缆连接,而是依靠特定的虚拟化链路相连。典型的虚拟网络包括在数据中心使用较多的虚拟二层延伸网络、虚拟专用网络以及 Overlay 网络。 虚 拟 二 层 延伸网络(V i r t u a l L 2 Extended Network)其实也可以算是 Overlay 网络的早期解决方案。为满足虚拟机动态迁移需求,传统的 VPL(MPLS L2VPN)技术,以及新兴的 Cisco OTV、H3C EVI 技术,都借助隧道的方式,将二层数据报文封装在三层报文中,跨越中间的三层网络,来实现两地二层数据的互通。 而虚拟专用网(VPN,全称 Virtual Private Network),是一种应用非常久远,常用于连接中、大型企业或团体与团体间的私人网络的通信方法。虚拟专用网通过公用的网络架构(比如互联网)来传送内联网的信息。利用已加密的隧道协议来达到保密、终端认证、信息准确性等安全效果。这种技术可以在不安全的网络上传送可靠的、安全的信息,总体而言早于云计算技术在企业中落地。 而 Overlay 网络也已在上篇有详细阐述,此处就不再复述了。
云网络产品的发展
云网络产品整体而言,主要经过了三次大的演进,从最初的经典云网络,到私有网络(Virtual Private Cloud),再到连接范围更大的云联网。云网络技术的发展也是企业数字化、全球化发展的一个缩影。
经典(基础)云网络
从 2006 年 AWS 推出 s3 和 ec2 云服务,开始为公有云用户提供云上服务开始,到 2010 年,阿里云正式推出 Classic 经典云网络方案,实现了对云计算用户的网络支持,再后续腾讯云、华为云也提供过类似的基础网络产品。 这些都是公有云早期的云产品,当时用户对云网络的主要需求是提供公网接入能力。经典云网络的产品特点是云上所有用户共享公共网络资源池,所有云服务器的内网 IP 地址都由云厂商统一分配,无法自定义网段划分、IP 地址。
私有网络 VPC
而从 2011 年左右开始,随着移动互联网的发展,越来越多企业选择上云,企业对云上网络安全隔离能力、互访能力、企业自建数据中心与云上网络互联并构建混合云的能力,以及在云上实现多地域部署后的多地域网络互联能力都提出了很多需求。此时,经典网络方案已经无法满足这些需求,AWS 适时推出云上 VPC 产品服务 (即私有专用网络服务,全称 Virtual Private Cloud),VPC 是企业用户在云上建立的一块逻辑隔离的网络空间 —— 在 VPC 内,用户可以自由定义网段划分、自由分配网段内 IP 地址、自定义路由策略。而后又陆续推出 NAT 网关、VPN 网关、对等连接等云网络产品,极大地丰富了云网络的连接能力,基本实现了私有网络方案最初的设计目标。 当前,以 VPC 为核心的云网络产品体系依然在不断发展壮大,又陆续诞生了负载均衡器、弹性网卡、弹性公网 IP、云防火墙等配套类衍生网络产品。
云联网
而近几年,随着经济全球化高速发展,大数据与 AI 类应用异军突起,需要云平台网络提供更广泛灵活的接入能力与分发能力,便催生了私网连接、云企业网、云连接器、云联网等各类场景的接入类云网产品,以此来满足企业全球化场景下的各类复杂互联互通需求。 与此同时,传统的 CDN 分发服务,经过与云联网的深度融合,也焕发了第二春,如今各大云厂商均有推出 CDN 全球内容分发服务与应用加速服务。同时 SD-WAN 接入服务的不断完善,也使得企业信息架构一体化的物理边际向着全球大踏步迈进。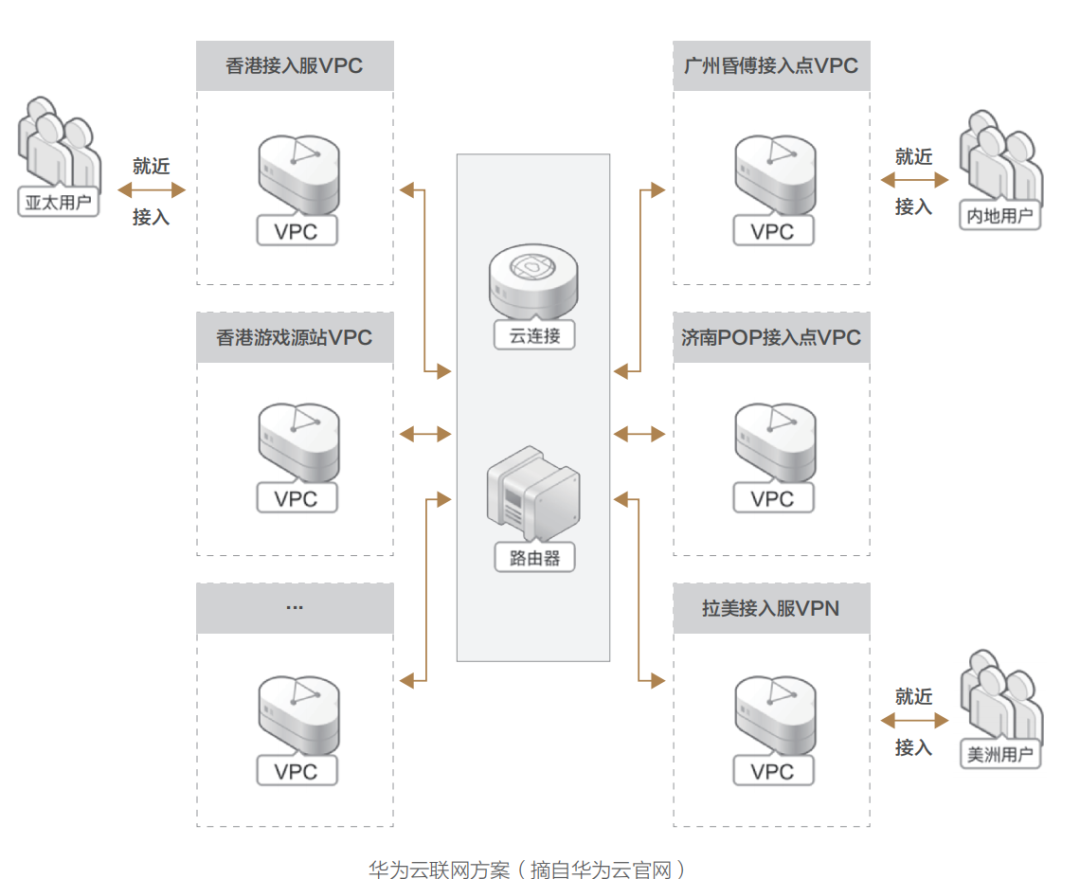
云网络技术后续演进展望
云网络从基础核心技术的演进来看,是对网络编址灵活性和网络传输性能提升的持续优化过程:经典云网络和 VPC 网络在编址方案上,都使用了 Overlay 技术,在物理网络之上叠加了一个支持多租户的虚拟网络层,从而有效支持了云上租户间的网络隔离安全性、租户内应用的互联互通灵活性诉求;而在网络性能提升方面, 通过重构网络设备形态,在不丧失转发控制灵活性基础上,来持续持续提升数据转发性能是为当今主流技术演进方向,以虚拟交换机为例,伴随着硬件服务器网络带宽从 10G 升级到 25G,乃至到 100G,vSwitch 技术经历了经典网络的 Linux 内核态数据交换、DPDK 用户态数据交换、硬件直通、再到智能网卡硬件卸载(vPDA、DPU 等)等演进历程。 而从产品层面看,云网产品经过经典网络,VPC 网络,云联网三代产品的发展,云网络产品的能力范围得到了极大延展 —— 从聚焦数据中心内部网络虚拟化,到聚焦数据中心之间的互联互通,再进一步通过 sd-wan 接入能力把企业的网络接入能力进行虚拟化从而支持各类场景接入。云网络产品已不仅仅用于连接云内的计算与存储资源,云下接入范围也逐渐扩展到连接企业的总部 / 分支网络以及云外各类终端,以期最终使企业能在云上构建完整的 IT 信息服务生态体系。 而在云计算技术发展到第三代云原生时代的当下,随着各类虚拟化技术的成熟,各类软件定义硬件的云能力得以落地运用,伴随着容器技术的大规模商用,终会使业务研发与基础运维一体化协作的技术隔阂会彻底破除,业务应用的全栈可观测性述求必将使业务服务监控下钻到基础网络层,让网络流量监测带上业务属性,从而使业务全链路监控真正具备生产力价值。而这又都将取决于容器网络与云网络技术的融合深度与应用广度,这一领域也必将成为今后各大云厂商决胜云原生时代的战略制高点!
编辑:黄飞
-
网络摄像机应用技术的发展趋势2008-09-19 4129
-
TPMS技术与发展趋势2009-10-06 20809
-
谈谈机电一体化技术的现状及发展趋势2012-10-16 5306
-
数字图像与视频压缩编码技术发展趋势2013-09-25 2528
-
阿里云携领先SDN能力,亮相全球网络技术盛会ONS2018-04-17 2537
-
蓝牙技术未来的发展趋势2019-03-29 4042
-
半导体工艺技术的发展趋势2019-07-05 4691
-
新兴的半导体技术发展趋势2019-07-24 3137
-
WIFI技术原理及发展趋势2020-08-27 11529
-
自动化测试技术发展趋势展望分析,不看肯定后悔2021-05-14 2605
-
汽车电子技术的发展趋势是什么?2021-05-17 7293
-
高速球是什么?有什么技术发展趋势?2021-05-31 2055
-
WCDMA技术演进过程2009-06-16 1483
-
网络虚拟化的未来发展趋势分析2016-12-06 4033
-
虚拟化技术的发展趋势2019-01-02 10252
全部0条评论

快来发表一下你的评论吧 !
