

2.0优化PyTorch推理与AWS引力子处理器
电子说
描述
由来自AWS的苏尼塔·纳坦普alli 校对:Portnoy
新一代的CPU在机器学习(ML)推论中,由于专门的内置指令,其性能显著改善。 这些普通用途处理器加上其灵活性、高速开发和低运作成本,为其他现有硬件解决方案提供了替代 ML 推论解决方案。
AWS、Arm、Meta等帮助优化了PyTorrch 2.0 武器化处理器的性能。 因此,我们高兴地宣布,PyToch 2.0 武器基AWS Graviton案例的推论性能比先前的PyToch 释放速度高达ResNet-50的3.5倍,比BERT速度高达1.4倍,使Graviton案例成为这些模型在AWS上最快速最优化的计算实例(见下图 ) 。
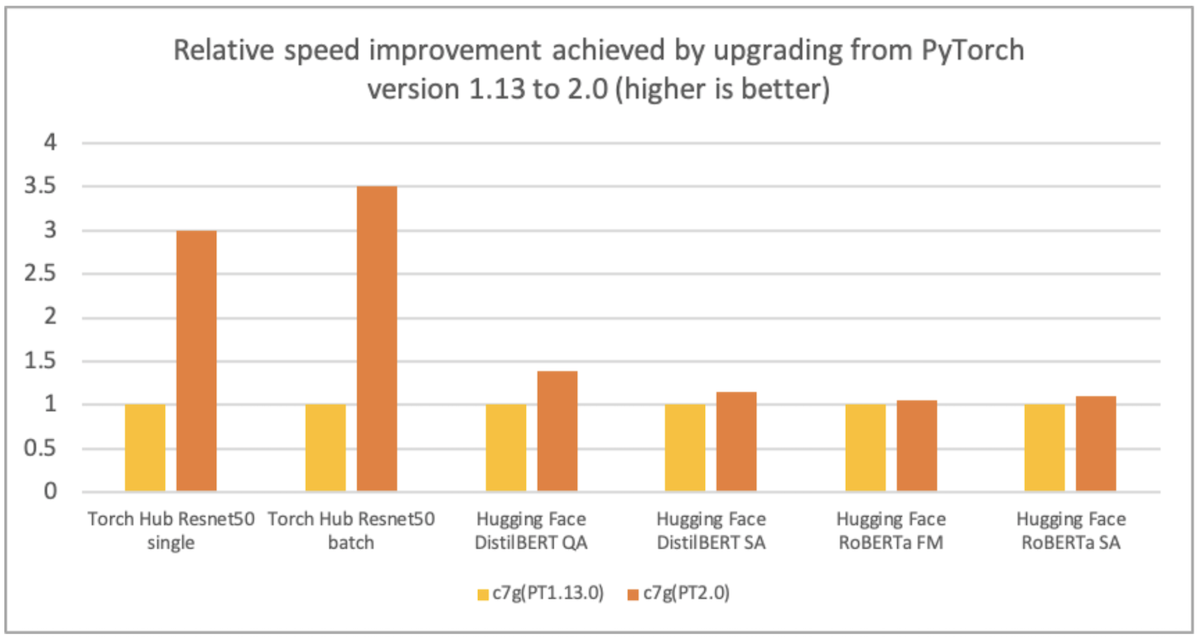
图像1:通过从PyTorrch版本1.13升级到2.0(越高越好)实现相对速度的提高。
如下图所示,我们测量到PyTorrch 以 Graviton3 为基础的C7g 案例在火炬枢纽ResNet-50和多个拥抱面模型中产生的成本节约高达50%,而可比的以x86为基础的计算优化了亚马逊EC2案例。对于该图表,我们首先测量了五种案例类型的每百万次计算成本。然后,我们将每百万次计算成本的结果与C5.4x大案例(这是该图表Y轴上的“1”的基线衡量标准)标准化。
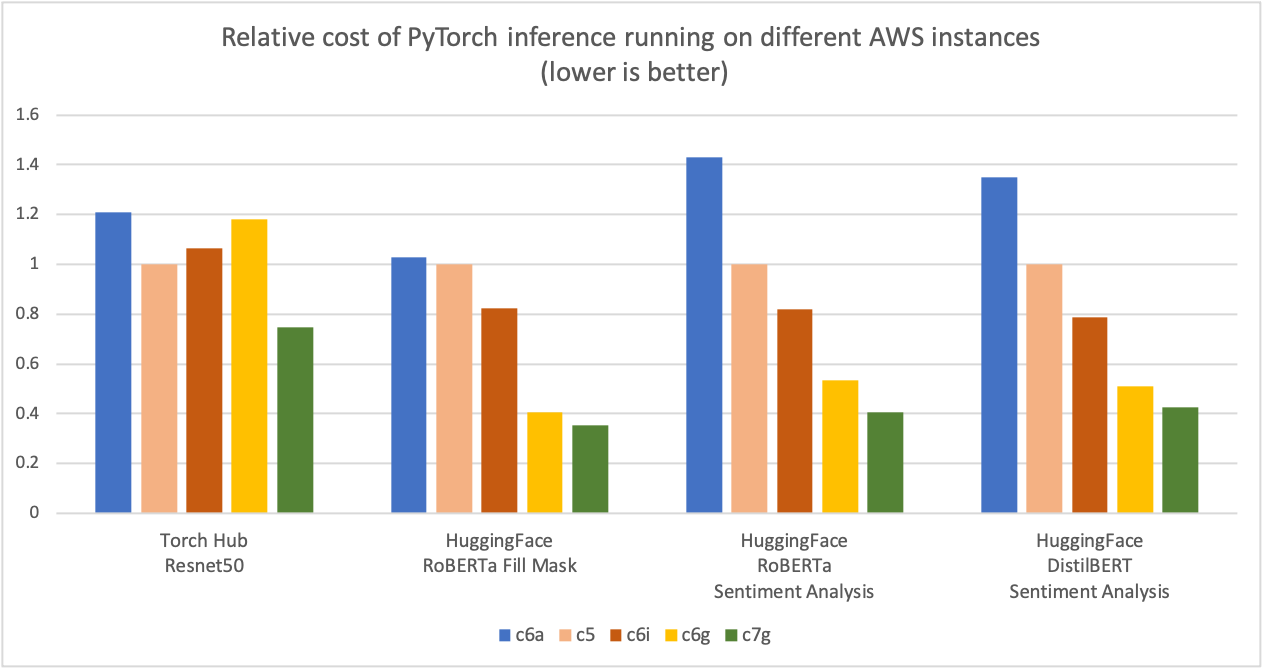
图像2图2:不同AWS实例中的PyTorch推论的相对成本(较低者更好)。
资料来源:AWS ML博客。Graviton PyTerch2.0 推推性能.
与前面的推论成本比较图相似,下图显示了相同五例类型的模型p90延迟度。我们将延迟值结果与C5.4x大实例(这是图Y轴上的“1”基线测量标准)正常化。 c7g.4x大(AWS Graviton3)模型推导延迟度比C5.4x大、C6i4x大和C6a.4x大的延迟度高出50%。
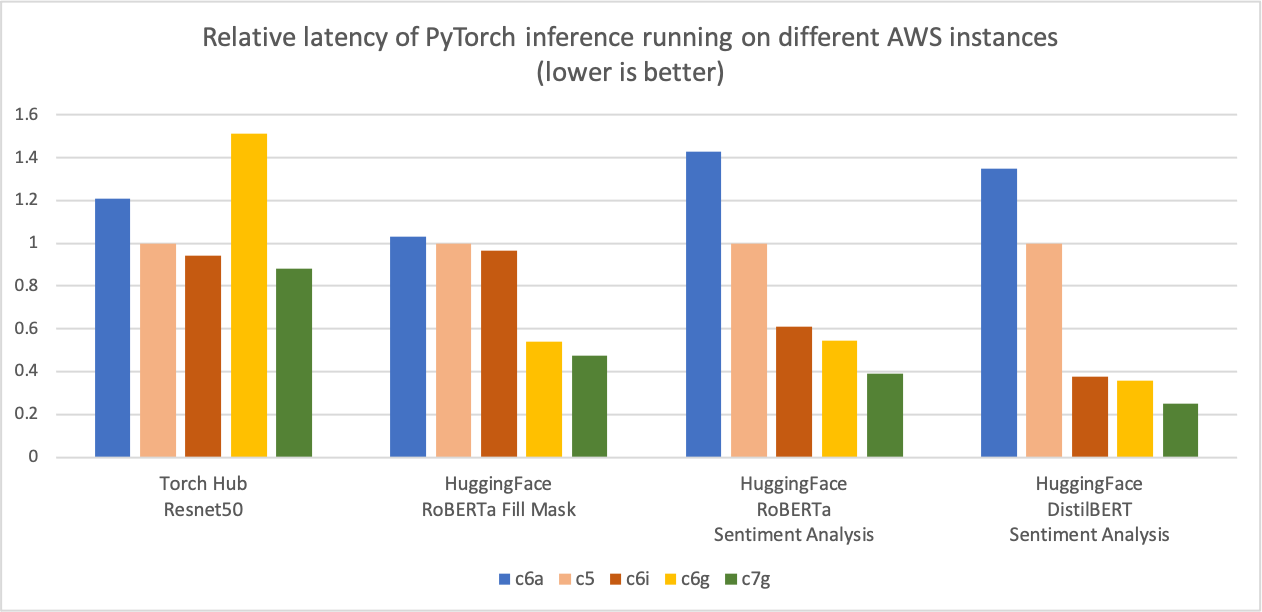
图像 3:不同AWS实例中的PyTocher推论的相对延迟度(第90页)(较低者更好)。
资料来源:AWS ML博客。Graviton PyTerch2.0 推推性能.
优化详情
PyTorrch 支持计算 Armá 建筑(ACL) GEMM 核心库的计算, 通过 AArch64 平台的 oneDNNN 后端( 原称“ MKL- DNN ”) 计算 。 优化主要针对 PyTorrch ATen CPU BLAS 、 fp32 和 bfloat16 的 ACL 内核以及 1DN 原始缓存。 没有前端 API 更改, 因此在应用层面无需修改, 以使这些优化适用于 Graviton3 实例 。
Py火点级优化
我们扩展了ATen CPU BLAS 接口, 通过 anDNN 后端加速 Aarch64 平台的更多操作员和高压配置。 下图突出显示( 橙色) 优化组件, 改善了 Aarch64 平台上的 PyTorrch 推断性能 。
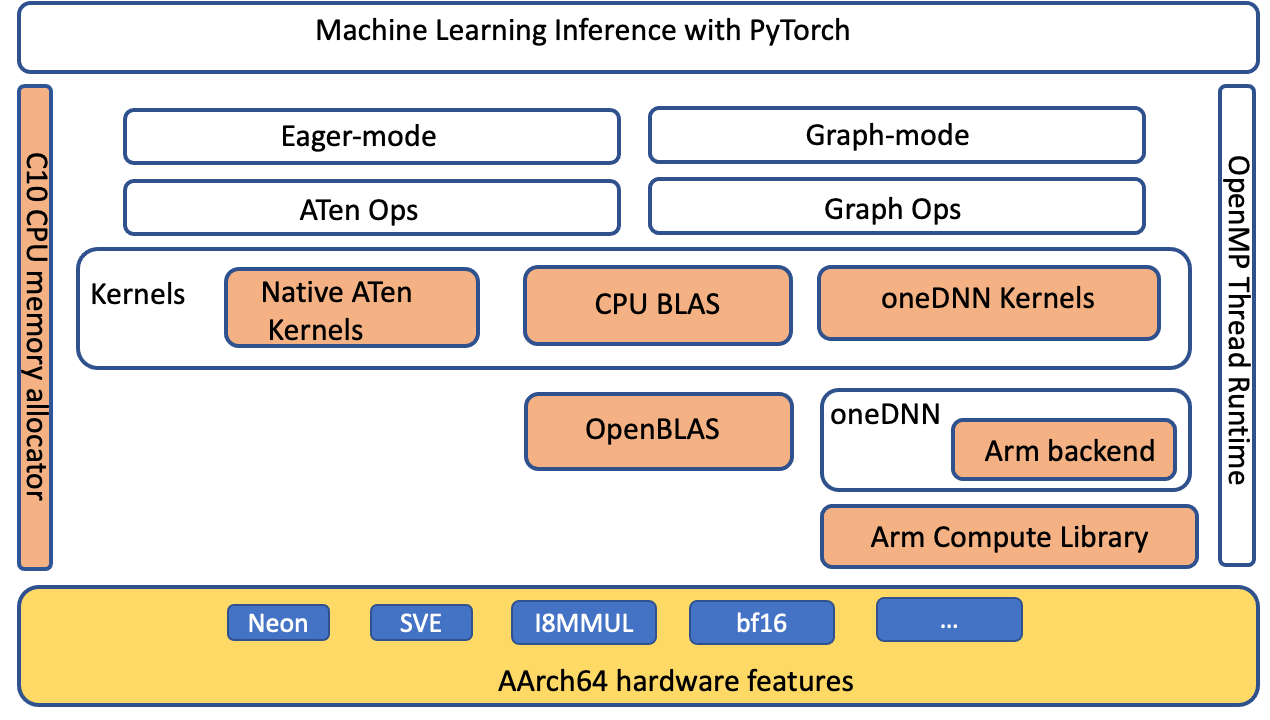
图像 4 图像 4:PyTorrch软件堆加亮(橙色)AArch64平台上为改进推论性能而优化的组件
ACL 内核和 BFloat16 FFmatath 模式
ACL 图书馆为 fp32 和 bfloat 16 格式提供 Neon 和 SVE 优化的 GEMM 内核: 这些内核提高了SIMD 硬件的利用率,并将结束时间缩短到最终推导延迟。 Graviton 3 的 bloat 16 支持使使用 bfloat 16 fp32 和 自动混合精密( AMP) 培训的模型得到有效部署。 标准的 fp32 模型通过 oneDNN FPmath 模式使用 bfloat 16 内核,而没有模型量化。 这些内核的性能比现有的 fp32 模型推力快两倍,没有 bfloat16 FPmath 支持。 关于ACL GEM 内核支持的更多细节,请参见 ACL GEMM 内核支持。Arm 计算库 Github.
原始缓存
以下调序图显示了ACL运算符是如何融入 oneDNN 后端的。 如图所示, ACL 对象以 oneDNN 资源而不是原始对象来处理 ACL 对象。 这是因为 ACL 对象是明确和可变的 。 由于 ACL 对象是作为资源对象处理的, 因而无法以 oneDNN 支持的默认原始缓冲特性来缓存 。 我们用“ 递增”、“ 配制” 和“ 内制产品” 运算符在 ideep 操作员级别上进行原始的递归, 以避免 GEMM 内核启动和 Exronor 分配管理 。
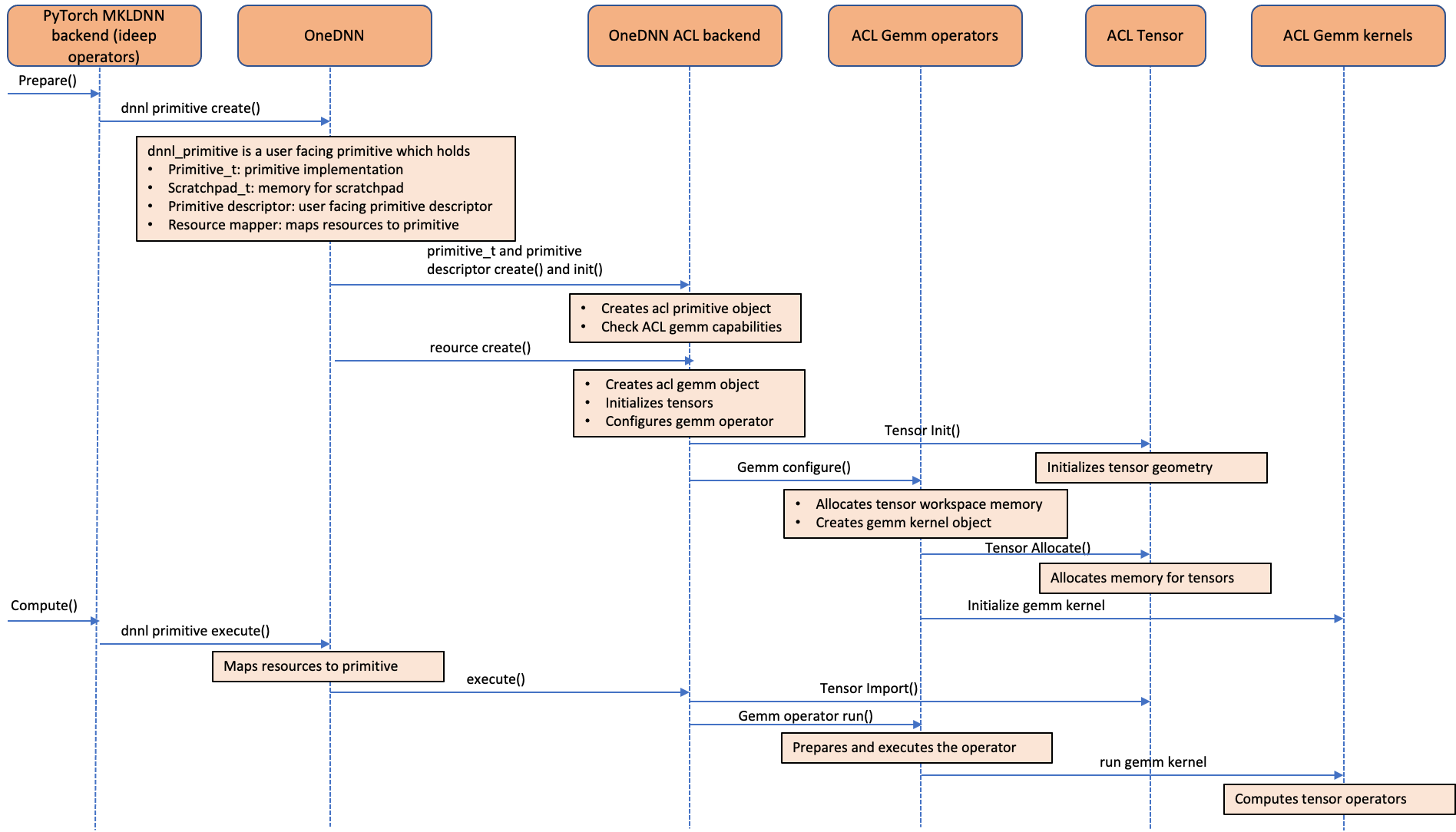
图像5:呼叫序列图表,显示如何将 Armatia 建筑(ACL) GEMM GEMM 内核计算库整合到一个 DNN 后端
如何利用优化
从官方回购中安装 PyTorrch 2. 0 轮, 并设置环境变量, 以允许额外优化 。
调
正在运行一种推论
您可以使用 PyTork火炬燃烧以测量 CPU 推断性能改进,或比较不同实例类型。
调
业绩分析
现在, 我们将使用 PyTorrch 配置器分析 ResNet- 50 在 Graviton3 的 c7g 实例上的 ResNet- 50 的推论性能 。 我们用 PyTorrch 1. 13 和 PyTorrch 2. 0 运行下面的代码, 并在测量性能之前将几处迭代的推论进行 。
调
从火炬进口模型样本中导入的点火炬 样本_input = [火炬.rand(1, 3, 224, 224)] 热度_ 模型 = 模型.resnet50 (重量=模型.ResNet50_Weights.DEFAULAT) 模型 = 火炬.jit. stat. stript.jet.no_grad () 模型 = 模型.eval () 模型 = 火炬.jit.optimize_ for_ inference () 模型 :
我们用电压仪查看剖面仪的结果,分析模型性能。
安装以下 PyTollch 配置配置程序 Tensorboard 插件插件
pip 安装火炬_ tb_ 色彩描述器
使用电压板启动
色色板 -- logdir=./logs
在浏览器中启动以下内容以查看剖析器输出。 剖析器支持“ 概览” 、 “ 操作器” 、 “ 跟踪” 和“ 模块” 的观点, 以洞察推论执行 。
http://localhost:6006/
下图是剖析器“ Trace” 视图, 显示调用堆和每个函数的执行时间。 在剖析器中, 我们选择了前方() 函数以获得整个推算时间。 如图所示, 以 Graviton3 为基础的 7g 实例 ResNet- 50 模型的推算时间比 PyTorch 1. 13 高出 PyTorrch 2. 0 的三倍左右。
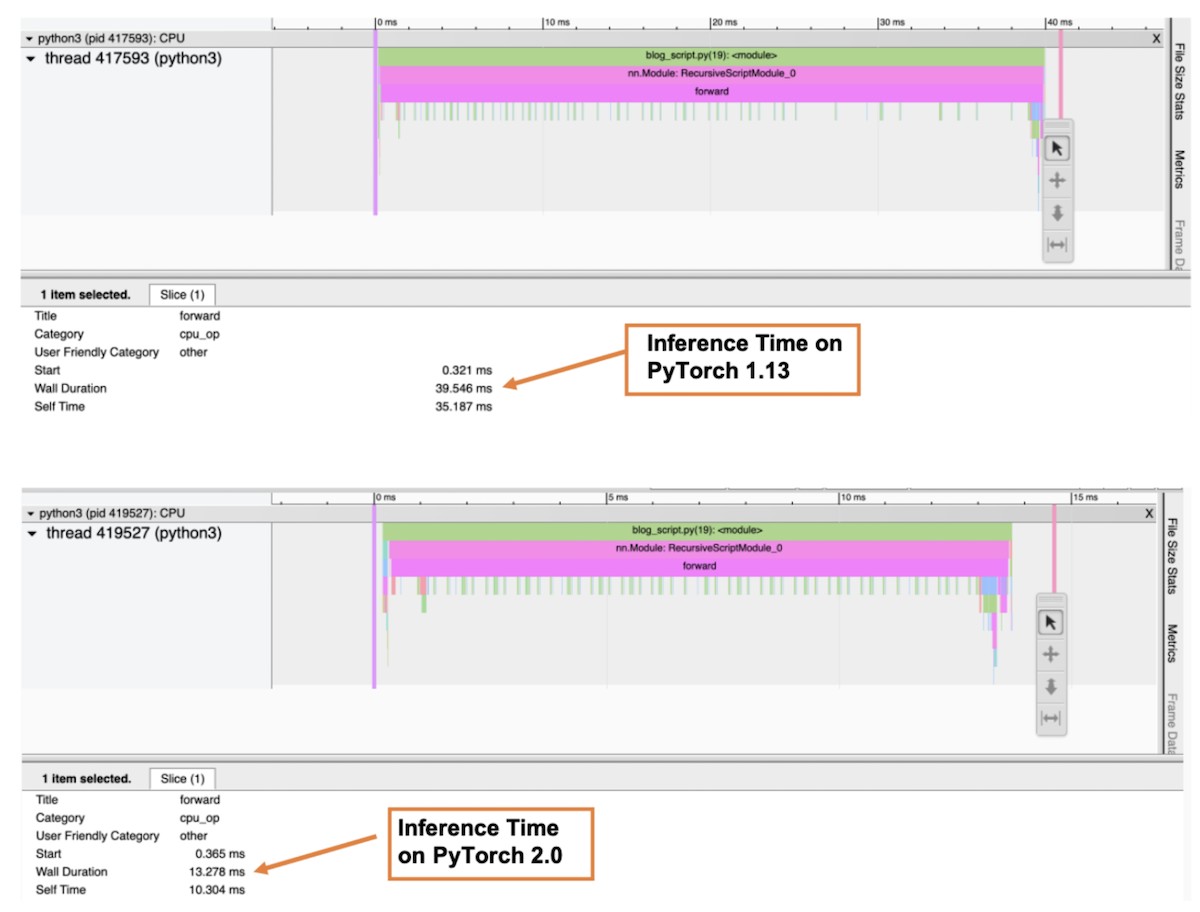
图像 6: 剖析器跟踪视图: PyTorch 1. 13 和 PyTorch 2. 0 上的前穿墙长度
下一个图表是“ 操作器” 视图, 该视图显示 PyTorrch 操作器及其执行时间列表。 与前面的 Trace 视图类似, 操作器视图显示, 以 Graviton3 为基础的 c7g 实例 ResNet- 50 模型的操作器主机运行时间比 PyTorrch 1. 13 高出 3 倍左右 。
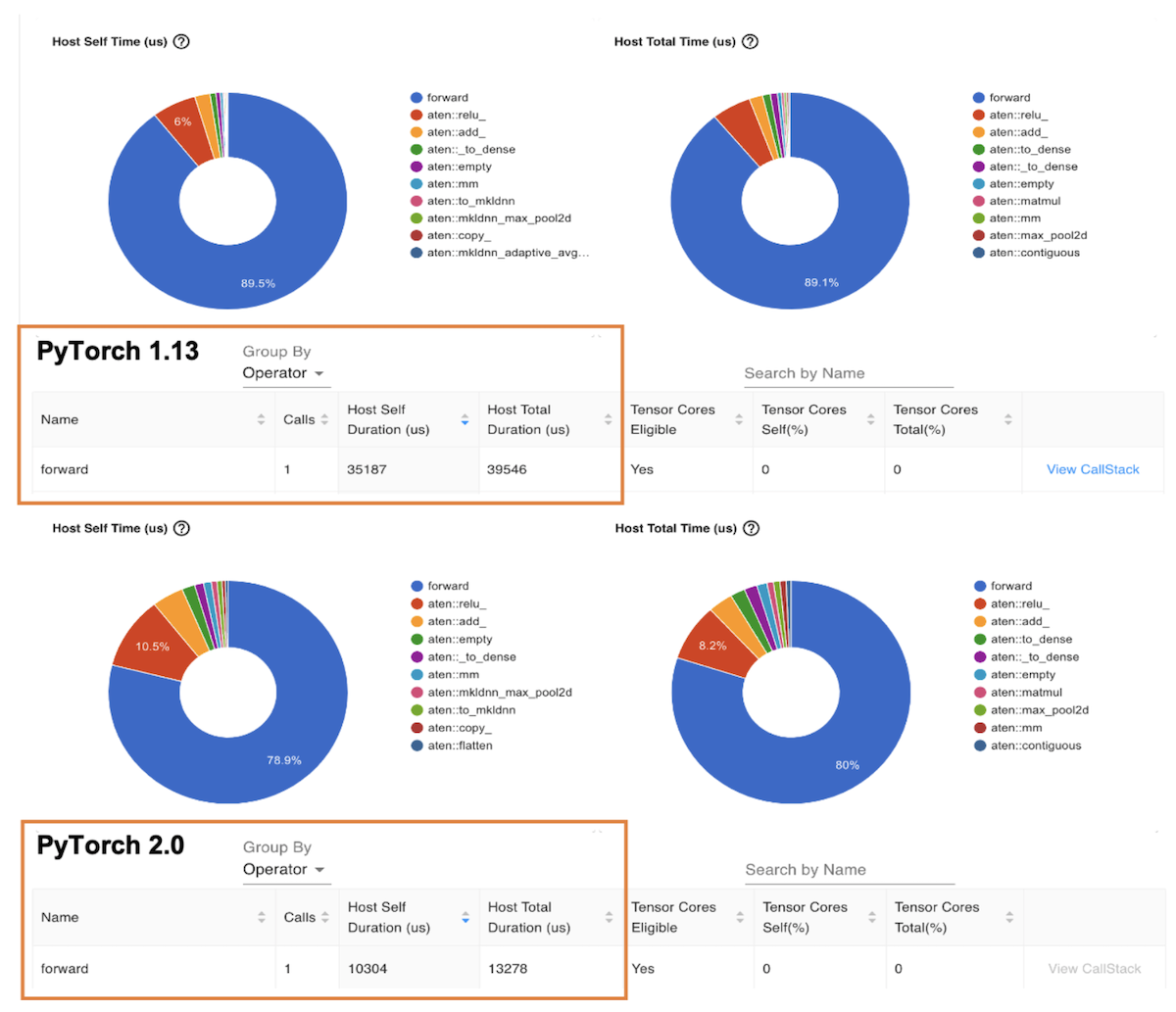
图像 7PyTorch 1. 13 和 PyTorch 2. 0 的主机时间
B. 基准制定 " 拥抱模型 " 的基准
您可以使用Amazon Sage-Maker 推断建议在不同实例中自动设定性能基准参数的实用性, 在不同实例中自动设定性能基准。 使用推推建议, 您可以找到实时推论端点, 该端点以给定 ML 模型的最低成本提供最佳性能。 我们通过在生产端点上部署模型, 收集了上述数据 。 关于推论建议方的更多细节, 请参考亚马孙 -- -- 种植者 -- -- 实例GitHub repo。我们为这个职位设定了以下模式基准:ResNet50 图像分类,发盘感应分析,RoBERTA 填充遮罩, 和RoBERTATA情绪分析.
结 结 结 结
对于PyTorrch 2. 0, 以 Graviton3为基础的C7g实例是计算最符合成本效益的最优化亚马逊EC2案例的推论。师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师 师和亚马逊 EC2。AWS 重力技术指南提供最佳图书馆和最佳做法清单,帮助您在不同工作量中利用Graviton案例实现成本效益。
如果您发现在Graviton没有观察到类似的绩效收益的使用情况,请就Graviton的绩效收益提出问题。启动 aws -graviton - greviton - 启动我们将继续进一步改进性能,使以AWS Graviton为基础的案例成为使用PyTorrch进行推论的最具成本效益和效率的通用处理器。
收到确认
我们还要感谢AWS的Ali Saidi(首席工程师)和Csaba Csoma(软件开发经理)、Ashok Bhat(产品经理)、Nathan Sircombe(工程经理)和Milos Puzovic(首席软件工程师)在Graviton PyTorch推论优化工作中的支持。 我们还要感谢Meta的Geeta Chauhan(应用AI工程师领袖)在博客上提供的指导。
关于提交人
苏尼塔·纳坦普alli系AWS的ML工程师和软件开发经理。
安基思·古纳帕在Meta(PyTorrch)是AI合伙人工程师。
审核编辑:汤梓红
-
在AWS Graviton4处理器上运行大语言模型的性能评估2025-02-24 1786
-
利用Arm Kleidi技术实现PyTorch优化2024-12-23 2122
-
INT8量子化PyTorch x86处理器2023-08-31 2009
-
PyTorch教程18.3之高斯过程推理2023-06-05 667
-
使用AWS Graviton处理器优化的PyTorch 2.0推理2023-05-28 1613
-
通过Cortex来非常方便的部署PyTorch模型2022-11-01 2447
-
在AWS云中使用Arm处理器设计Arm处理器2022-09-02 4858
-
Arm Neoverse V1的AWS Graviton3在深度学习推理工作负载方面的作用2022-08-31 3940
-
AWS基于Arm架构的Graviton 2处理器落地中国2021-02-01 3888
-
Blackfin处理器性能优化2009-09-02 532
-
地球引力位函数在流处理器上的实现与分析2009-03-30 928
全部0条评论

快来发表一下你的评论吧 !
