

中科大&字节提出UniDoc:统一的面向文字场景的多模态大模型
描述
这篇文章是由中科大和字节跳动合作,在2023年8月23日上传到arXiv上的文章。这篇文章提出UniDoc,一个统一的多模态大模型(LMM)。UniDoc主要聚焦于包含文字的图像的多模态理解任务。相比于以往的多模态大模型,UniDoc具备它们所不具备的文字检测、识别、spotting(端到端OCR)的能力。此外,文章中实验表明,这些能力的学习能够彼此促进。
方法框架
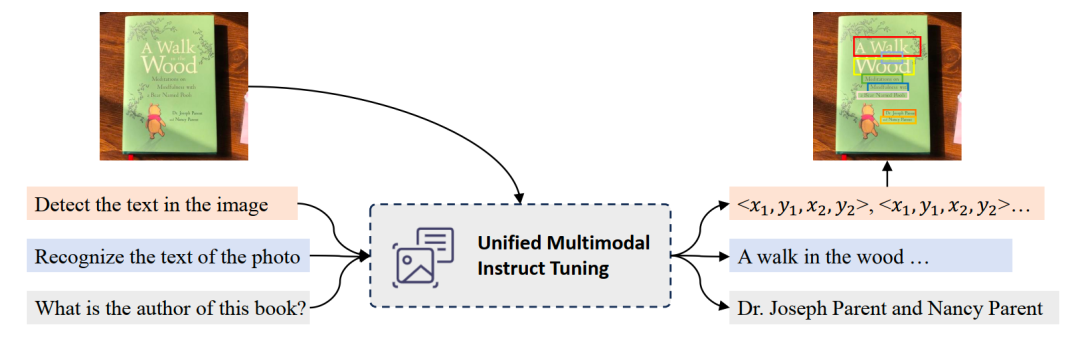
如上图所示,UniDoc基于预训练的视觉大模型及大语言模型,将文字的检测、识别、spotting(图中未画出)、多模态理解等四个任务,通过多模态指令微调的方式,统一到一个框架中。具体地,输入一张图像以及一条指令(可以是检测、识别、spotting、语义理解),UniDoc提取图像中的视觉信息和文字信息,结合自然语言指令以及大语言模型的世界知识,做出相应回答。
训练数据采集

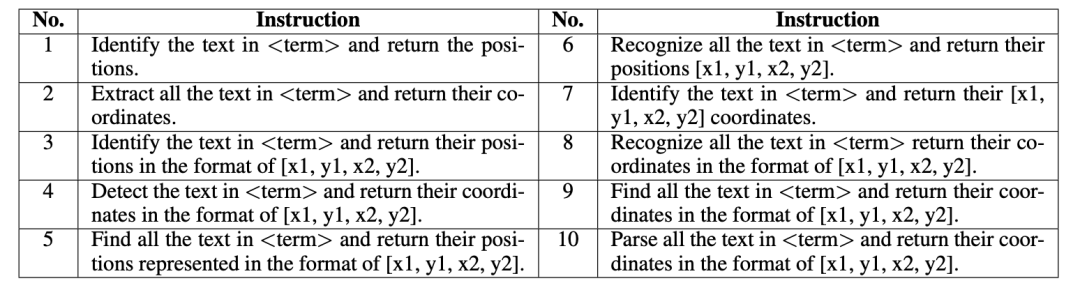
作者团队收集了大量的PPT图像,并提取其中文字实例和对应的bbox。在此基础上构建多任务的指令微调数据集。文章认为,PPT图片中文字具有各种各样的大小、字体、颜色、风格等,且PPT中视觉元素丰富多样,适合用于构建涉及文字图像的多模态任务的训练。以spotting任务为例,其指令如下图所示。其中的 term 表示”imgae“,”photo“等随机名词,以增加指令多样性。
实验结果
多模态理解


从上述六个例子可以看到,UniDoc不仅可以有效提取图像中的视觉信息、文字信息,更可以结合其丰富的世界知识进行合理地回答。

对于无文字的图像,UniDoc同样可以准确地进行问答。
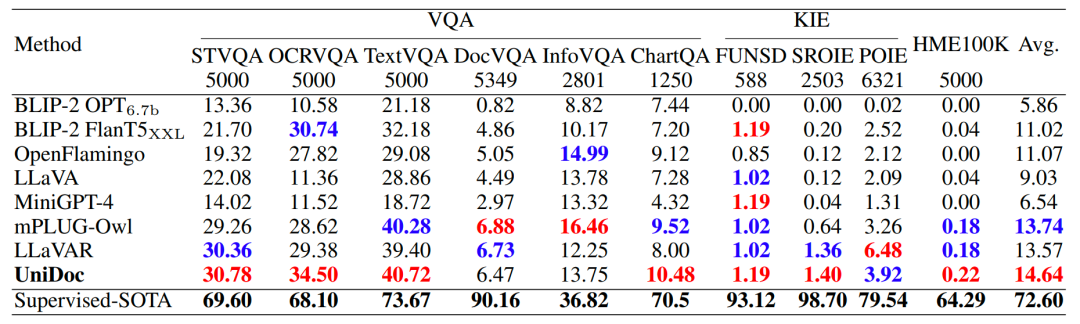
在多个多模态问答基准数据集上,UniDoc实现了优越的性能。
文字检测、识别、spotting

上图中,第一行的四个case来自于WordArt数据集,第二行的四个case来自于TotalText数据集。可以看到,虽然这些行级别的文字图像呈现不同的字体以及不规则的文字分布,UniDoc仍然能够进行准确地识别。

上图中六个case中,文字存在部分的缺失,UniDoc仍然能够进行准确地识别。

上图中四个case展示了UniDoc在TotalText数据集上的检测效果。
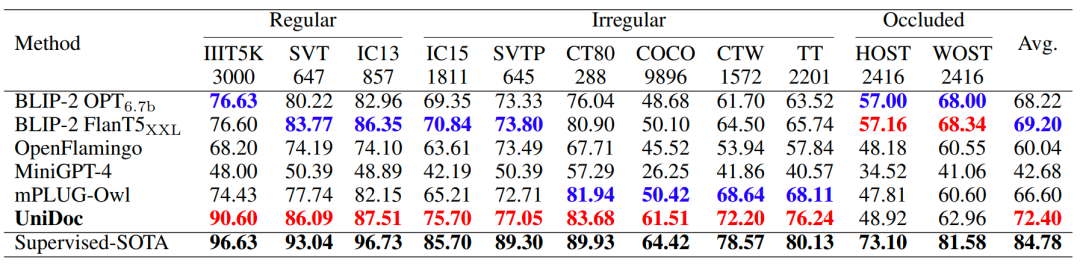
在多个文字识别基准数据集上,UniDoc实现了优越的性能。
消融实验

有趣的消融实验:对于同一张输入图像,spotting指令(右)规避了识别指令(左)的识别遗漏现象。
-
北大&华为提出:多模态基础大模型的高效微调2023-11-08 2638
-
《51单片机C语言编程入门》(中科大编著)2022-01-04 2892
-
在医疗AI领域砥砺前行的中科大学子2021-05-10 6120
-
《日本经济新闻》报道:中科大为何能对中国AI领域产生很的影响?2019-07-18 8405
-
51单片机资料(中科大)2014-06-23 7760
-
溷沌数字通信(中科大出版的)2012-08-16 3491
-
中科大嵌入式课件全集2012-08-14 10947
-
51单片机C语言编程入门(中科大)2012-08-06 7449
-
华中科大发的论文《新一代TSC2046触摸屏控制器》2012-08-03 2584
-
微机原理与接口技术 中科大教材2009-12-07 10320
-
人口模型讲义 (中科大课程)2009-09-15 530
-
中科院中科大2003年量子力学考研试题答案2008-11-25 2131
全部0条评论

快来发表一下你的评论吧 !
