

开放加速规范AI服务器的设计方法
描述
当前语言大模型的参数量已达千亿以上,训练数据集的规模也达到了TB级别。业界典型的自然语言大模型有GPT、LLAMA、PaLM、文心、悟道、源等。如果用“算力当量”(PetaFlops/s-day,PD),即每秒千万亿次的计算机完整运行一天消耗的算力总量来表征大模型的算力需求,具有1750亿参数的GPT-3模型的训练算力需求为3640PetaFlop/s-day。
参数量为2457亿的源1.0大模型训练算力消耗为4095Peta-Flop/s-day。大模型的高效训练通常需要具备千卡以上高算力AI芯片构成的AI服务器集群支撑。在全球科技企业加大投入生成式AI研发和应用的大背景下,配置高算力AI芯片的AI服务器需求也不断高涨。
2019年OCP成立OAI小组,对更适合超大规模深度学习训练的AI加速卡形态进行了定义,目的是为了支持更高功耗、更大互连带宽AI加速卡的物理和电气形态,同时为了解决多元AI加速卡形态和接口不统一的问题。随后,为了进一步促进OAI生态的建立,OAI小组在OAM的基础上统一了AI加速卡基板OAI-UBB设计规范。OAI-UBB规范以8张OAM为一个整体,进一步定义了8xOAM的Baseboard的主机接口、供电方式、散热方式、管理接口、卡间互连拓扑、Scale Out方式。
2019年底,OCP正式发布了OAI-UBB1.0设计规范,并随后推出了基于OAI-UBB1.0规范的开放加速硬件平台,无需硬件修改即可支持不同厂商的OAM产品。
面向生成式AI的大模型算力系统的构建是一项复杂的系统工程,基于上述设计原则,以提高适配部署效率、提高系统稳定性、提高系统可用性为目标,进一步归纳总结出开放加速规范AI服务器的设计方法。
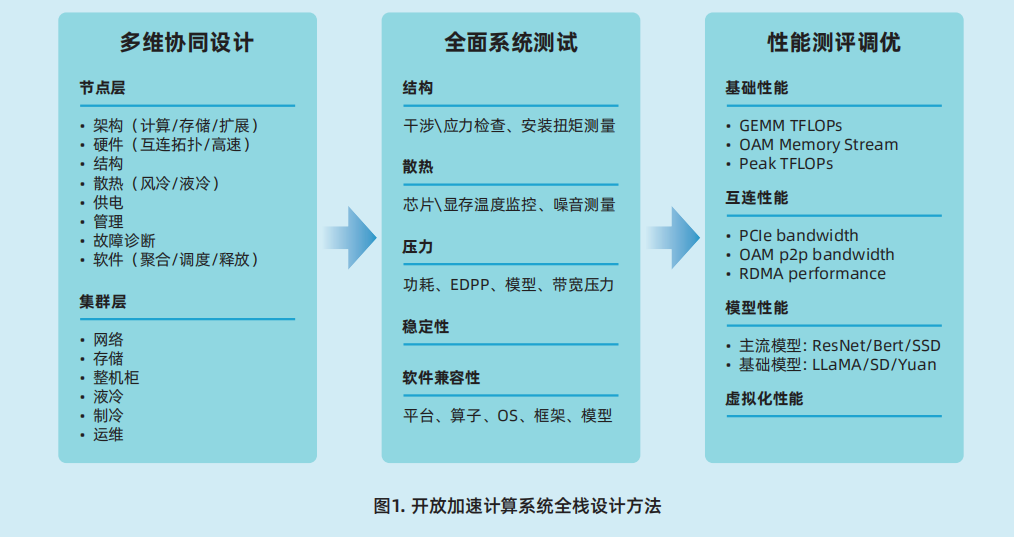
面向AIGC的计算系统交付模式不再是单一服务器,绝大多数情况最终部署的形式是包含计算、存储、网络设备,软件、框架、模型组件,机柜、制冷、供电、液冷基础设施等在内的一体化高集成度算力集群。
(1)系统架构
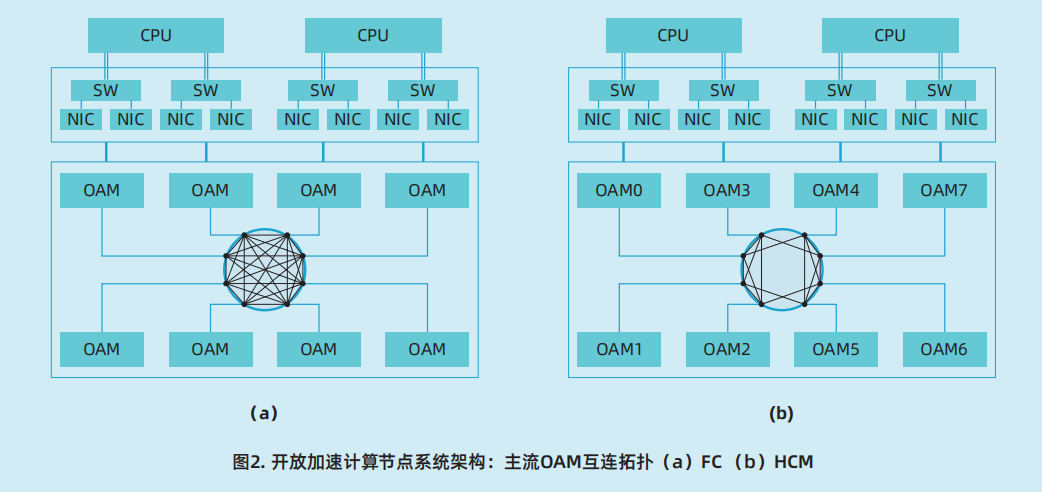
为满足大模型训练模型参数规模的不断增大给模型训练带来的计算、存储、通信等方面的挑战,系统架构设计将赋能AI服务器节点和服务器集群以超大规模集群互连的大模型训练能力。OAM 是 OCP-OAI 小组制定的 AI加速模块接口规范,现已发布 OAM v1.5 规范,OAM 模块承担起单个 GPU 节点的 AI 加速计算能力,通过符合 UBB v1.5 base 规范的基板完成OAM间的 7P × 8 FC(Fully Connect,全互连)、6P × 8 HCM(Hybrid cubic mesh,混合立方互连)等高速互连拓扑实现多OAM数据低延时共享,利用RDMA网络部署等优化通过OSFP/QSFP-DD线缆实现对外拓展完成集群互连,突破了服务器集群在GPU计算资源、通信效率上的瓶颈,最大程度发挥OAM计算性能并降低通信带宽限制。OAM模块透过 PCIe Switch 通过4条PCIe x 16与高性能CPU建立起高速高带宽数据通道,并支持搭配32条RDIMM或LRDIMM内存,以最大程度的保障OAM与CPU之间的数据通信处理需求。
(2)OAM模块
OAM规范由OCP-OAI建立,定义了开放硬件计算加速模块的结构形态及互连接口,简化了OAM模块间高速通信链路互连,以此促进跨加速器通信的可扩展性。CPU与OAM 间的连接是透过 PCIe Switch 上行与CPU 4条PCIe x16带宽完成,极大程度增加CPU与OAM之间的数据通信数量,避免大数据量AI训练场景中CPU与OAM间数据通信出现瓶颈。支持节点内及节点间OAMP2P高速互连,OAM之间全互连拓扑改善了多OAM数据共享的延迟情况,为计算提供更高效的性能。
(3)UBB基板
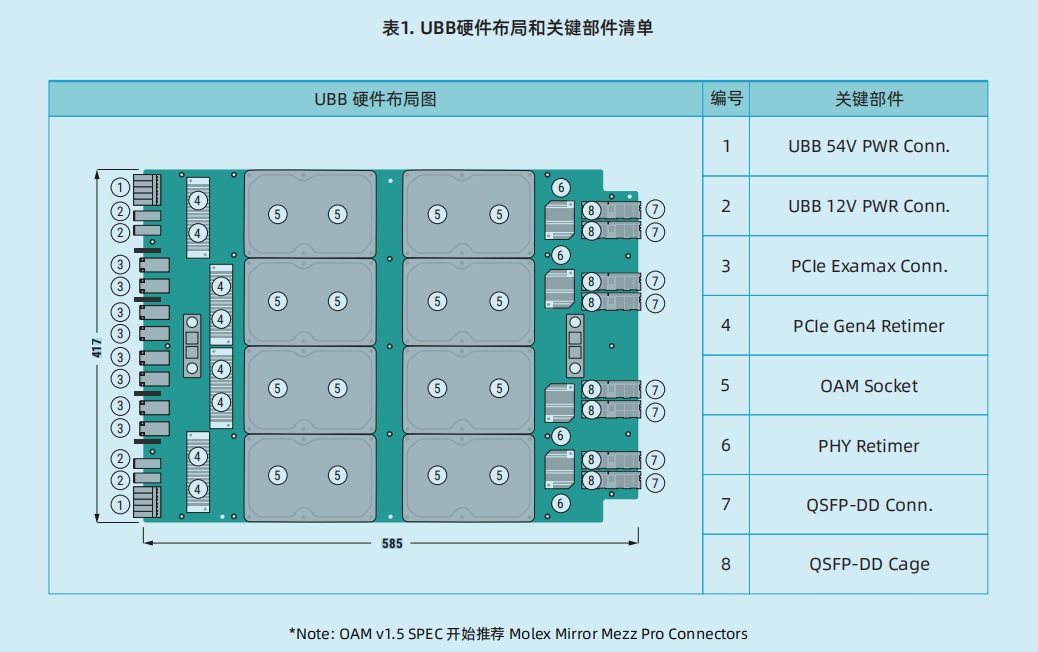
UBB基板能够承载支持8个OAM模块,形成一个AI加速计算子系统。UBB尺寸为16.7×21英寸,搭配UBB的机型可以放置于19英寸或21英寸机柜之中。UBB基板上的8个OAM模块通过可以通过OAM设计规范中的不同互连拓扑进行互连。UBB链路可以被拆分为×8链路,如果所有7个端口对配置成×16将无法完成对外拓展,因此为实现节点对外拓展形成互连集群,UBB基板将互连链路限制在×8以内,并默认设计端口1的后半部分(×8,通常称为1H端口)被用作对外拓展端口。
4)硬件设计
UBB基板及OAM硬件设计应遵从UBB规范及OAM规范中的各项硬件规范、电气规范、时序规范等。遵从UBB规范中对OAM布局的规范。
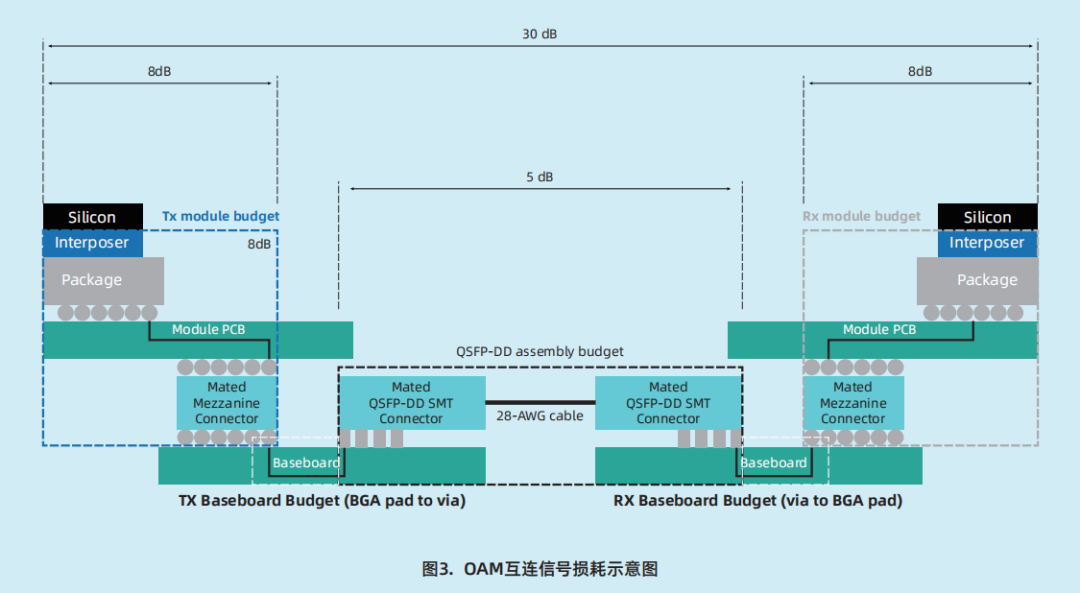
OAM 互连拓扑损耗评估标准。对 OAM 互连所涉及的56Gbps PAM信号进行信号完整性设计,包括高速走线参考平面设计、高噪声电源区域走线、过孔stub及层面规划、走线间距、过孔间串扰控制等。OAM之间互连信号,整体损耗在基频处要求在30dB 以内,其中OAM 的 TX & RX 模组损耗需 控 制 在 8dB 以 内 , C a b l e 拓 扑 要 求QSFP-DD assembly 线缆损耗在5dB以内,PCB 损耗根据拓扑具体计算即可。
(5)散热设计
风冷散热:服务器节点风冷散热使用高效能风扇墙设计,并采用侧边防回流设计以增大相同风扇转速下的系统风量。采用导风罩设计的基础上增加OAM、CPU区域多风道隔离设计,能够结合区域感温能力实现分区散热。风扇全部支持热插拔,支持N+1转子冗余,支持风扇速度智能调节。针对UBB基板及OAM模块,进行散热器性能的热阻值参数设计。
(6)系统管理
OAM模块的系统管理方面的设计包含提供资产信息、规范寄存器,并支持满足FW更新、带外监控要求功能。资产信息提供对OAM模块PN、SN、FW版本等信息的访问;寄存器信息提供对电压、功耗、温度、ECC状态及错误、外设错误、PCIe错误、Memory错误等信息的访问;带外监控提供温度、功耗、OAM模块信息、异常告警、OAM状态、卡复位等功能。
(7)故障诊断
故障诊断功能包含OAM卡内部Uncorrect able Error、PCIe 总线错误、ESL 连接异常、卡丢失等功能。通过BMC可监控系统PCIeSwitch模块、UBB基板及OAM模块的ECC状态及错误、外设错误、PCIe错误、Memory错误等。支持链路级别的高级故障诊断功能,通过全时监测PCIe Switch运行日志获取OAM卡故障信息。
(8)软件平台
针对大模型开发过程中存在的调度难、部署慢、效率低、集群异常等问题,构建具备高性能、高可靠、可扩展的AI算力资源统一管理和人工智能作业调度平台,通过计算资源池化和容器化技术,屏蔽底层硬件差异,以标准算力模式面向用户直接提供计算资源,并通过适应性策略及敏捷框架对算力进行精准调度配给。
本文来自“ 开放加速规范AI服务器设计指南(2023) ”,以上分享了系统架构、OAM模块、UBB基板、硬件设计、散热设计、系统管理、故障诊断、软件平台;集群网络与存储、整机柜、液冷、制冷、运维等相关规范详情,请下指南原文。
审核编辑:汤梓红
-
RISC-V走向开放服务器规范2023-08-10 1791
-
ChatGPT热潮引发AI服务器爆单2023-02-22 3628
-
OPC服务器开发的几种方法2010-07-20 966
-
浅析AI服务器与普通服务器的区别2020-01-23 5334
-
服务器的开关电源规范设计标准2020-12-24 1905
-
AI服务器的应用场景有哪些?2023-01-30 4411
-
一文解析AI服务器技术 AI服务器和传统通用服务器的区别2023-04-14 13753
-
AI服务器与传统服务器的区别是什么?2023-06-21 3348
-
《开放加速规范AI服务器设计指南》发布,应对生成式AI算力挑战2023-08-14 1759
-
使用NVIDIA Triton推理服务器来加速AI预测2024-02-29 1894
-
ai服务器是什么架构类型2024-07-02 3877
-
AI服务器的特点和关键技术2024-07-17 6336
-
什么是AI服务器?AI服务器的优势是什么?2024-09-21 3825
-
GPU加速云服务器怎么用的2024-12-26 1361
-
云服务器端口怎么开放?2025-11-11 1271
全部0条评论

快来发表一下你的评论吧 !
