

一种融合语义不变量的点线立体SLAM系统
描述
作者:鱼骨 | 来源:3D视觉工坊
摘要
传统的同步定位与制图(SLAM)系统使用环境的静态点作为实时定位和制图的特征。当可用的点特征很少时,系统很难实现。一个可行的解决方案是引入线特征。在包含丰富线段的复杂场景中,线段的描述差别不大,这可能导致线段数据的不正确关联,从而将误差引入系统并加剧系统的累积误差。针对这一问题,本文提出了一种结合语义不变量的点线立体视觉SLAM系统。该系统通过融合线特征和图像语义不变信息,提高了线特征匹配的准确性。在定义误差函数时,将语义不变量与重投影误差函数融合,并应用语义约束减少长期跟踪过程中姿态的累积误差。在TartanAir数据集和KITTI数据集的Office序列上的实验表明,该系统在一定程度上提高了直线特征的匹配精度,抑制了SLAM系统的累积误差,平均相对位姿误差(RPE)分别为1.38和0.0593米。
总结:
(1)提出了一种结合语义不变量的点线立体视觉SLAM系统
(2)将语义不变量与重投影误差函数融合定义误差函数,并应用语义约束减少长期跟踪过程中姿态的累积误差
(3)TartanAir数据集和KITTI数据集
引言
自工业4.0推出以来,机器人主导的智能制造产业已成为工业发展的支柱。视觉同步定位和映射(SLAM)系统是允许机器人探索未知环境、自我定位和构建地图的核心组件。视觉SLAM依靠廉价的轻型摄像机,可以有效地感知环境的外观,这使得仅依赖视觉传感器的SLAM系统成为机器人领域的热点问题。视觉SLAM系统的框架正在走向成熟。尽管视觉SLAM的研究领域已经取得了很大的进展,然而真实环境的可变性使得数据关联的准确性不可靠甚至无效。这导致系统的鲁棒性降低,难以满足实际需求。因此,如何提高数据关联的鲁棒性,对于减少视觉SLAM的累积误差,提高系统的整体鲁棒性具有重要意义。根据所采用的跟踪方法,将视觉SLAM系统分为直接跟踪和间接跟踪两种方法。基于直接跟踪的方法,如大尺度直接单目SLAM (LSD-SLAM)、直接稀疏里程计(DSO)和半直接单目视觉里程计(SVO),是基于最小化光度投影误差的姿态估计方法。这些方法对光照变换很敏感,对单个像素的区分很差。相比之下,基于间接跟踪的方法通过跟踪图像的点特征估计相机的姿态。代表性算法有并行跟踪与映射(PTAM)、ORB-SLAM2、RGBD SLAM-v2等。在强纹理场景中,点特征对光照不敏感,易于提取。然而,在低纹理环境或运动模糊的场景中,提取是困难的。影响系统的鲁棒性,严重时可能导致系统失效。在实际环境中,有大量的线特征具有与点特征相同的不变光照和视点特征,且易于提取。因此,可以克服低纹理场景造成的干扰,反映环境结构的完整信息。因此,涉及跟踪线特征的SLAM系统诞生了。线特征对遮挡很敏感,在缺乏纹理或高重复的区域不具有很强的识别能力,这导致匹配失败,比只依赖点特征的SLAM系统更不可靠的位姿求解。直线特征的跟踪非常耗时,不能满足SLAM系统的实时性要求。因此,点和线特征融合被应用到SLAM系统中。
为了减少累积误差的产生,现有的解决方案是通过在短期内建立多帧图像之间的约束,对位姿进行局部优化,减少轨迹漂移。当约束失败时,误差仍然会累积。另一种解决方案是采用闭环来建立一个长期约束来纠正累积误差,但这种解决方案严格依赖闭环检测。
近年来计算机图像技术的快速发展,如深度学习、目标检测、语义分割等,为机器人提高场景理解提供了更多的可能性。语义分割是一种像素级分类技术。图像中的每个像素被划分为相应的类别。在SLAM系统中应用语义分割来提高数据关联的鲁棒性是一个比较热门的研究课题。在SLAM系统中,随着时间的推移,相机的运动会导致视点、尺度和光照等特征的变化,但语义描述不会发生变化。比如在汽车上跟踪线段时,由于距离的变化,线段周围的像素发生了剧烈的变化,这导致跟踪失败。但是这条线段的语义描述属于汽车类,不受尺度和光照变化的影响。然后将线段的语义描述视为不变的,通过线段语义标签的一致性约束及其重投影特征建立线段的中期跟踪。
目前,线段相关的理论发展还不够成熟,主要表现在线段描述不够准确,这可能导致在包含许多线段的复杂场景中出现错误的数据关联。这就导致了在基于点-线特征的SLAM系统中引入线段后,线段的匹配精度较低,导致系统误差积累。
•本文提出了一种结合语义不变量的点和线特征的鲁棒立体SLAM系统。
•提出了一种改进的线段匹配方法。将语义分割的结果应用到线段匹配中,提高了线段的数据关联。
•定义线段的语义重投影误差函数,并将其应用于位姿优化过程,以提高数据关联的鲁棒性。实现了线段的中期跟踪,减少了轨迹漂移问题。
系统概述
本文以立体点线SLAM系统为基础,针对线段引入后,线段的不匹配直接影响数据关联的准确性,加剧了系统的累积误差的问题。提出了一种有效的改进方法。该方法使用语义不变量为线段匹配提供约束,减少了线段特征失配的产生。定义了线段的语义重投影误差函数,实现了线段的中期跟踪,有效地减少了轨迹漂移,提高了系统的鲁棒性。如下图所示为提出的系统的总体结构。该系统遵循ORB-SLAM2框架,整个SLAM任务按照可视化里程计、局部映射和闭环三个线程并行运行。
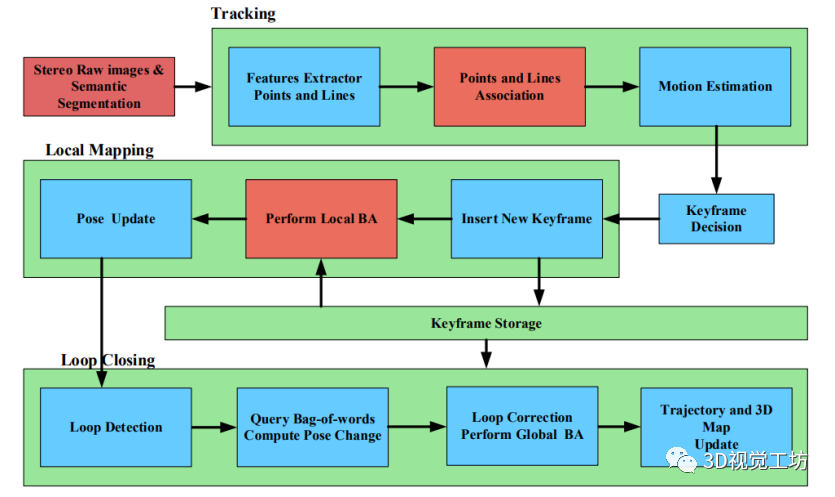
在本文中,语义分割的结果主要应用于视觉里程测量和局部姿态优化。如下图所示,系统接收到图像序列,然后进行点和线特征的提取和匹配。由于点特征的提取和匹配方法比线段更完备,语义分割结果只适用于线段的关联。在现有线段关联方法的基础上,利用语义分割的结果对线段进行语义分类。这提供了线段关联的语义不变约束,减少了不正确的数据关联。当获得点特征和线特征的关联结果时,将局部地图中的地标(点和线段)分别投影到当前帧及其对应的语义分割图像中。然后,通过最小化重投影误差项和重投影误差项的联合语义不变量来进行姿态优化。
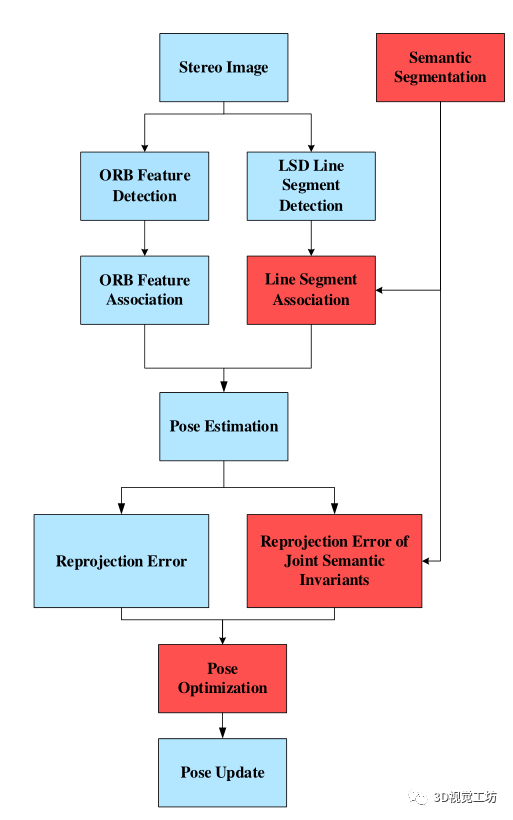
方法
在本节中,我们首先介绍LSD算法提取线段的预处理细节,以及如何应用语义分割的结果约束线段的数据关联。然后描述了利用语义不变量建立点、线特征的中期数据关联后,如何进行位姿优化的问题。
1、线段的预处理与关联
线段提取采用LSD算法。LSD算法是一种局部直线检测算法,可以在不调整参数的情况下快速提取图像的局部直线轮廓。然而,由于遮挡或部分模糊等原因,线段被分割成几条直线。为了解决这一问题,本文采用[18]文献中的方法对折线段进行合并。折线段是否满足合并条件由端点之间的距离和线段之间的距离共同决定。删除合并后不符合长度阈值的线段。当预处理完成后,该方法对线段进行语义分类。线段是否属于语义范畴的判定原则如下:
(1)检测到的线段在类别区域的长度大于阈值d;
(2)如果检测到的线段位于多个语义类别的边界,则将其标记为概率最高的类别。
利用Detectron2对图像进行语义分割预测。预测由地面和非地面组成。然后,根据上述规则对线段进行分类。分类结果如图5所示。

线段的数据关联应保证线段属于同一语义类,具有较高的相关性。线段的相关性由线段的局部外观描述确定,该描述由LBD描述符提供。
2、点和线重投影误差函数的语义不变量融合
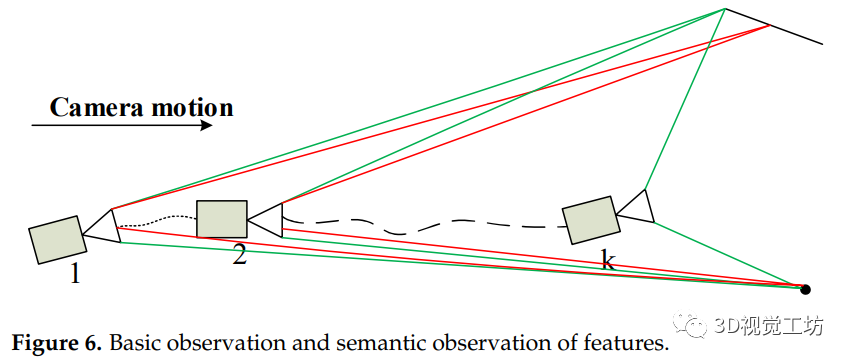
在SLAM系统中,减少轨迹累积误差主要有两种方法。一是通过帧间数据关联优化姿态,减少轨迹漂移,这是一个短期约束。另一种方法依靠闭环检测进行位姿校正,在图像框架中建立长期约束。VSO利用图像的语义分割信息建立点对的中期数据关联。线段也具有语义不变性。因此,我们的方法利用这一性质来建立线段上的中期数据关联。图6给出了摄像机运动过程中点与线特征的数据关联过程。红线表示视觉里程计框架中基于外观的特性约束,绿线表示基于语义的约束。摄像头1和摄像头2可以建立基于外观的特征约束和基于语义的特征约束。在摄像机移动过程中,由于对特征外观的描述发生了剧烈的变化,在第k个摄像机中只能观察到特征的语义约束。与基于外观的约束相比,这种语义约束可以为特征数据关联提供更长期的约束,这被称为特征的中期跟踪。
我们将语义不变量与重投影误差结合起来定义了一个误差函数:
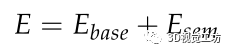
其中Ebase是重投影误差,Esem是融合语义不变量的误差函数。通过最小化误差函数,实现了点特征和线特征的中期跟踪,减少了轨迹的漂移。
(1)Ebase的定义
基于点线特征的立体SLAM系统通常通过最小化重投影误差,给定输入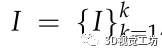 ,对应的位姿
,对应的位姿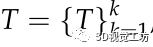 ,三维点
,三维点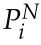 ,三维线段
,三维线段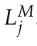 来实现局部姿态优化。重投影误差函数Ebase定义如下:
来实现局部姿态优化。重投影误差函数Ebase定义如下:
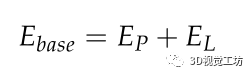
其中Ep和EL分别表示点特征和线段的重投影误差,Ep是第i个三维点的观测值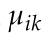 与其在第k个关键帧上的投影之间的距离为:
与其在第k个关键帧上的投影之间的距离为:
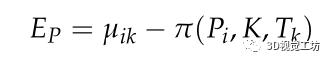
其中π(·)为三维点Pi的重投影坐标,k为摄像机的本征矩阵,Tk是相对运动矩阵。
由于遮挡或其他原因,线段的端点出现了不确定性。因此,线段的重投影误差函数不能简单地用观测线与其重投影之间的坐标距离来定义。更精确的方法是使用文献[19]中的方法,其中线段的重投影误差定义为投影线段的端点与被测直线之间的垂直距离之和。如图7所示,lo表示线段的观测值,lp表示三维线段的重投影,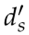 和表示直线重投影误差。因此,EL定义为:
和表示直线重投影误差。因此,EL定义为:
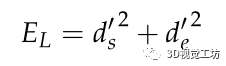
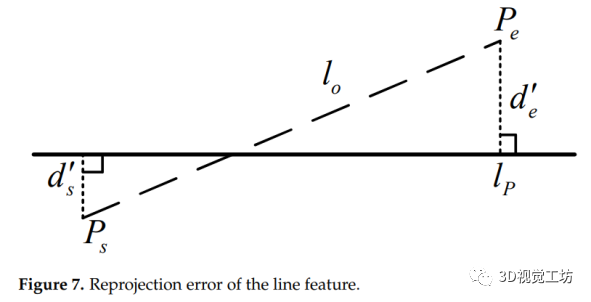
(2)Eseg的定义
融合语义不变量的误差函数描述了点和线特征在重投影后属于C类的概率。与VSO中阐述的现象一致,在摄像机运动过程中,由于周围的像素信息,特征会发生剧烈变化。因此,在数据关联中,特征的这一部分的约束就消失了。相比之下,特征的语义描述在尺度变化时保持不变。因此,将这种语义不变性应用到数据关联中,建立特征约束,延长特征的有效跟踪时间,减少累积误差的产生。
对于输入的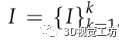 ,进行语义分割,对应的语义分割图像是
,进行语义分割,对应的语义分割图像是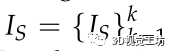 。对于Is中的每一个像素有一个类别C。然后,对于投影到Isk的一个三维点P i ,投影坐标为µ i ,投影坐标有一个语义类别µ i ∈c,其中c是C的一个子类别。在VSO中定义了基于点特征的语义观测概率模型:
。对于Is中的每一个像素有一个类别C。然后,对于投影到Isk的一个三维点P i ,投影坐标为µ i ,投影坐标有一个语义类别µ i ∈c,其中c是C的一个子类别。在VSO中定义了基于点特征的语义观测概率模型:
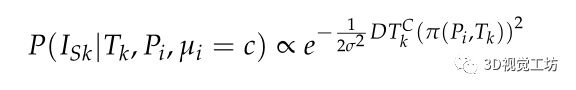
其中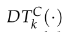 表示从投影坐标µi到语义类别C最近边界的距离。σ描述语义类别C的不确定性,则点特征融合语义不变量上的误差函数可定义为:
表示从投影坐标µi到语义类别C最近边界的距离。σ描述语义类别C的不确定性,则点特征融合语义不变量上的误差函数可定义为:
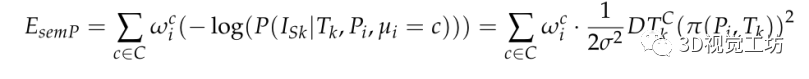
其中,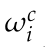 为类别概率向量,描述了Pi被一系列摄像机观测到的情况,并且类别属于C。这将导致:
为类别概率向量,描述了Pi被一系列摄像机观测到的情况,并且类别属于C。这将导致:
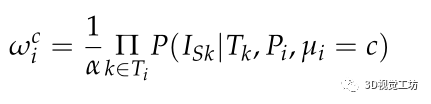
其中α是用于保证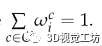 的常数。
的常数。
同样,对于一个三维线段L j ,它在Isk的投影也会使所投影的线段Lj具有一个语义类别j∈C。通过计算投影线段的两个端点以及线段中点到语义类C最近边界的距离来描述重投影线段属于语义类C的概率。可以确定线段中点离C最近边界的距离越小,线段属于C类的可能性越大。为了确保大多数线段属于C类,到语义区域最近边界距离最小的端点也应该被联合考虑。
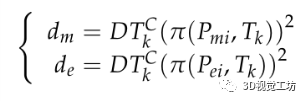
其中,dm和de分别表示从中点和端点到边界的距离。
因此,投影线段属于C类的概率用投影线段的中点和端点到C类边界的距离来描述。线段的语义似然模型定义如下:
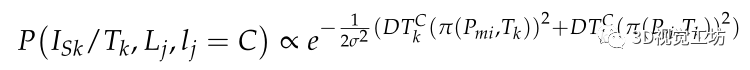
线段融合语义不变量的误差可定义为:
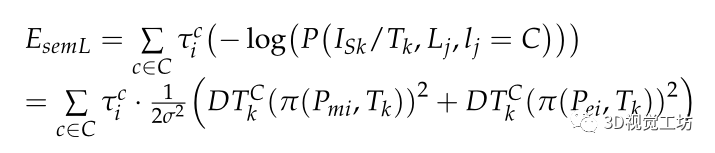
其中为类别概率向量,描述一系列摄像机观测到的线段L j ,类别属于C的情况:
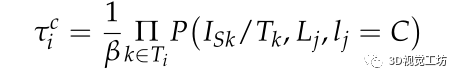
联合语义不变量的误差函数定义如下:
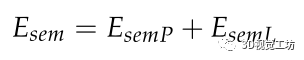
实验
本节通过一系列的实验来验证本文提出的系统的有效性。利用彩色图像进行语义分割是十分必要的。因此,使用公开可用的TartanAir数据集和KITTI数据集执行验证,这两个数据集都提供了ground-truth的颜色序列。TartanAir数据集是一个室内场景数据集,KITTI数据集是一个室外场景数据集。我们将我们的方法与几种最先进的方法进行了比较,包括ORB-SLAM2和PL-SLAM。所有实验都是在一台CPU为Intel i5-4200U、内存为4GB、操作系统为Ubuntu 16.04的笔记本电脑上进行的。语义分割结果是使用Facebook AI Research推出的Detectron2算法得到的。实验结果表明:
(1)添加语义不变量后,线段之间的不匹配明显降低,线段匹配的准确率提高。
(2)在没有动态目标干扰的室内场景中,该方法能较好地抑制轨迹漂移
(3)将语义不变性的结果应用于户外场景的SLAM系统并不一定能有效地减少系统的轨迹漂移。产生这种结果的原因可能是室外场景的语义分割精度不够高,语义类别划分不够精细,以及受到动态对象的影响。
(4)我们的系统基本能够满足实时性的要求。
结论
本文提出了一种融合语义不变量的点线立体SLAM系统。为了提高线段数据关联的准确性,给出了线段的语义类别标签。通过联合语义不变量定义线段上的重投影误差函数,实现线段的中期跟踪,使系统在进行局部优化时获得更好的结果,减少了轨迹中累积误差的产生。在TartanAir数据集和KITTI数据集上验证了该方法的有效性。将实验结果与ORB-SLAM2和PL-SLAM系统进行了比较。结果表明,该算法能有效地提高系统的鲁棒性,减少大部分序列的轨迹漂移。但是,由于对语义分割信息进行了预处理,在系统中没有对原始图像进行直接的实时分割。因此,后续将考虑实时语义分割的应用,进一步提高系统的完整性。
审核编辑:汤梓红
-
基于多模态语义SLAM框架2022-08-31 2898
-
一种自动的轮毂识别分类方法2010-02-21 876
-
一种多径环境下的调制识别算法2010-07-17 528
-
基于不变量的软错误检测方法2018-01-17 930
-
高仙SLAM具体的技术是什么?SLAM2.0有哪些优势?2018-05-15 10106
-
一种融合语义模型的二分网络推荐算法2021-04-28 877
-
基于视觉传感器的ORB-SLAM系统的学习2022-11-02 1965
-
一种快速的激光视觉惯导融合的slam系统2022-11-09 2817
-
基于视觉传感器的SLAM系统学习2022-11-29 1375
-
一个动态环境下的实时语义RGB-D SLAM系统2023-08-25 1758
-
一种基于RGB-D图像序列的协同隐式神经同步定位与建图(SLAM)系统2023-11-29 1849
-
一种完全分布式的点线协同视觉惯性导航系统2024-09-30 1979
-
利用VLM和MLLMs实现SLAM语义增强2024-12-05 2837
-
一种基于MASt3R的实时稠密SLAM系统2024-12-27 3514
-
一种基于点、线和消失点特征的单目SLAM系统设计2025-03-21 1289
全部0条评论

快来发表一下你的评论吧 !
