

BEV感知中的Transformer算法介绍
描述
1、Camera only
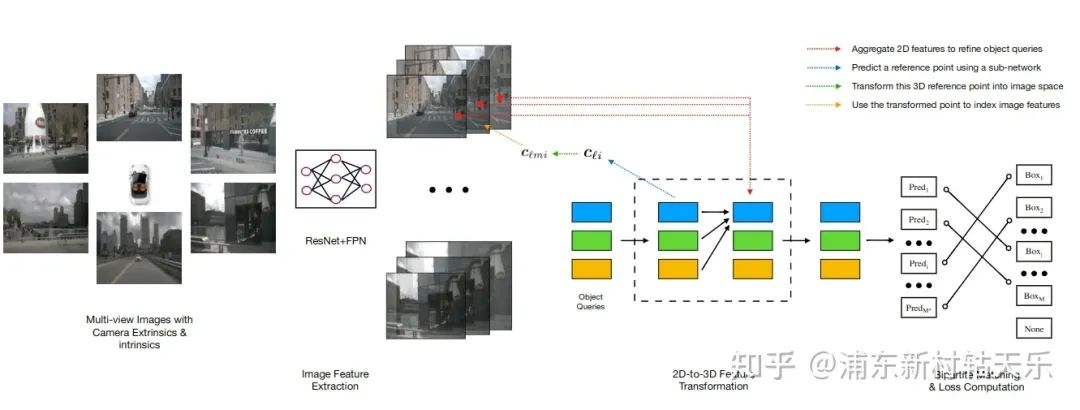
主要思想:固定900个query个数,随机初始化query。每个query对应一个3D reference point,然后反投影到图片上sample对应像素的特征。
缺点:需要预训练模型,且因为是随机初始化,训练收敛较慢
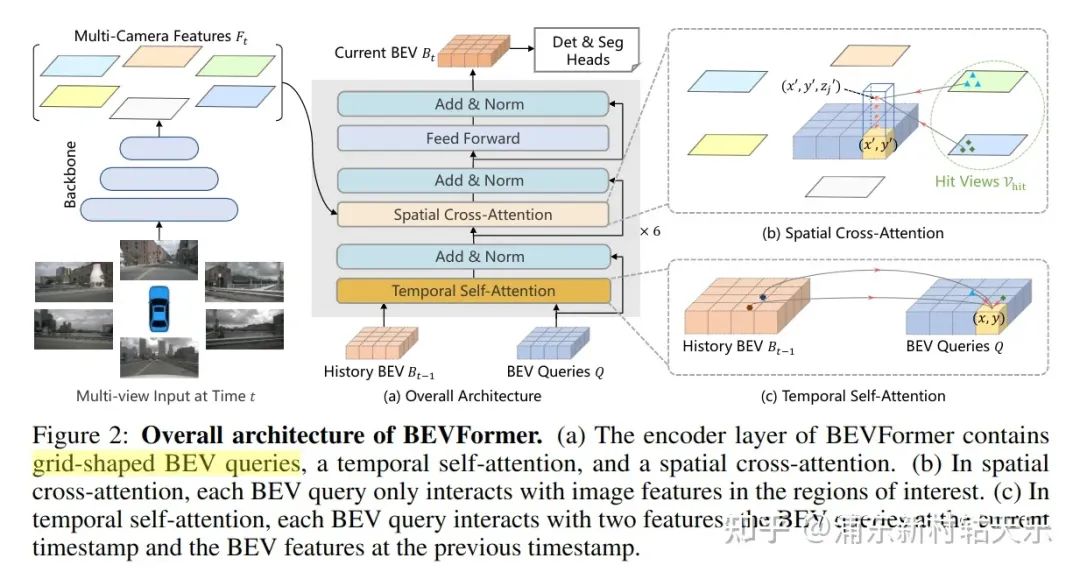
BEV Former
https://arxiv.org/abs/2203.17270
主要思想:将BEV下的每个grid作为query,在高度上采样N个点,投影到图像中sample到对应像素的特征,且利用了空间和时间的信息。并且最终得到的是BEV featrue,在此featrue上做Det和Seg。
Spatial Cross-Attention:将BEV下的每个grid作为query,在高度上采样N个点,投影到图像中获取特征。
Temporal Self-Attention: 通过self-attention代替运动补偿,align上一帧的feature到当前帧的Q
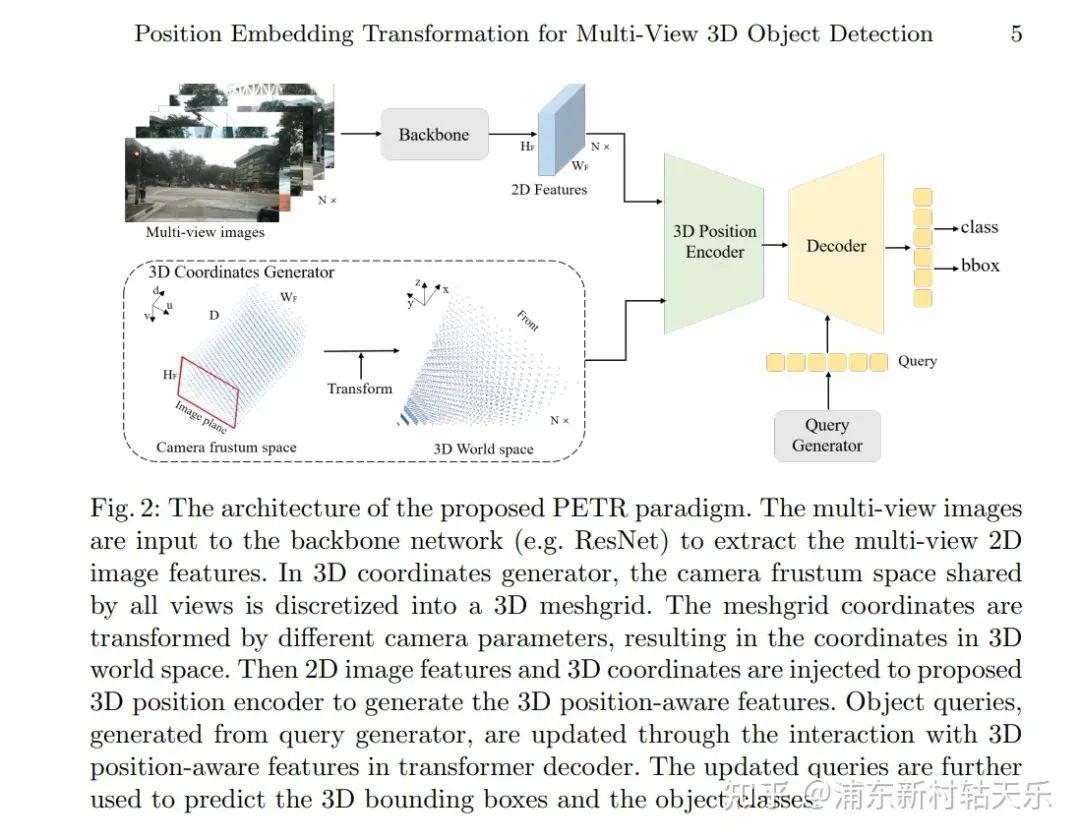
旷视,PETR
https://arxiv.org/pdf/2203.05625.pdf
2、多模态
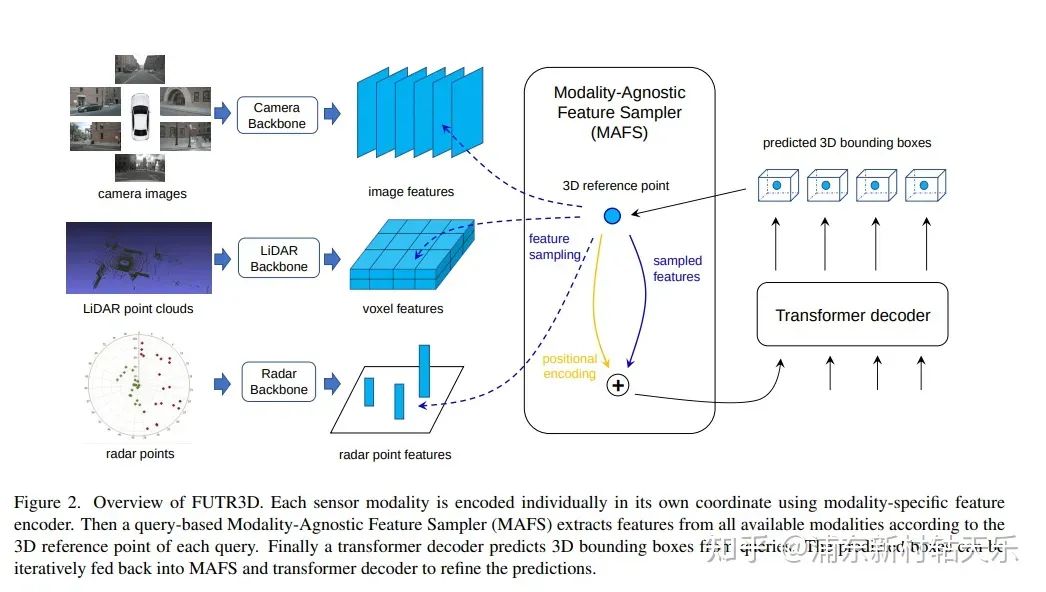
清华,FUTR3D
https://arxiv.org/pdf/2203.10642.pdf
在DETR的基础上,将3D reference point投影到Lidar voxel特征和radar point 特征上。
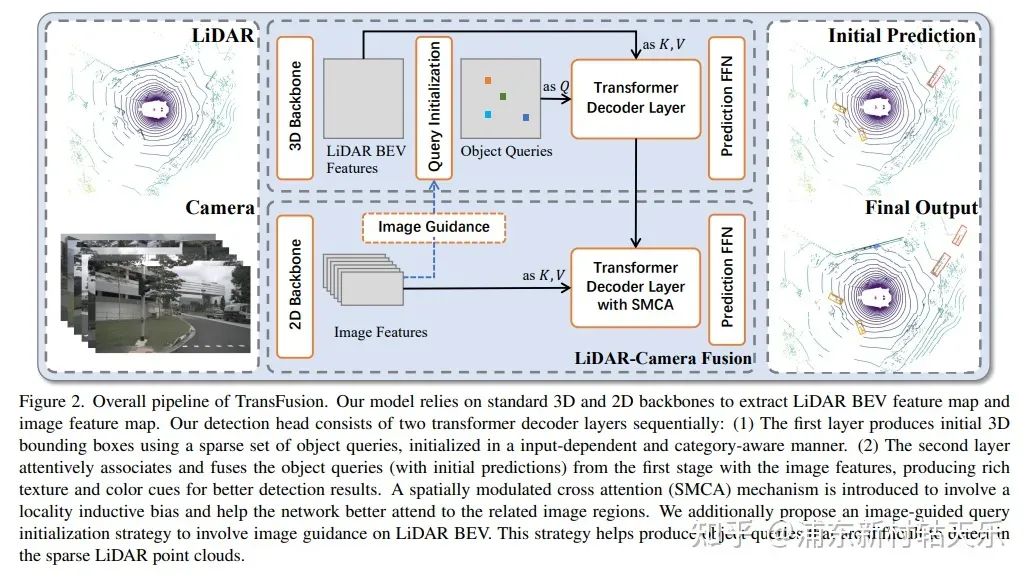
香港科技大学,Transfusion
https://arxiv.org/pdf/2203.11496.pdf
利用CenterPoint在heatmap上获取Top K个点作为Query(这K个点可以看做是通过lidar网络初始化了每个目标的位置,这比DETR用随机点作为Qurey收敛要快),先经过Lidar Transformer得到proposal,把这个proposal作为Query,再和image feature做cross attention。
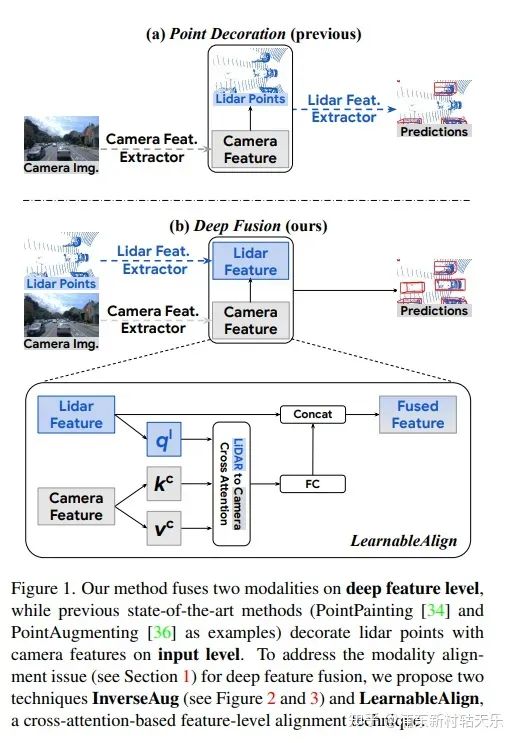
Google,DeepFusion
https://arxiv.org/abs/2203.08195
直接将Lidar feature和Camera feature做cross attention,这个思路牛逼,我不看到这篇论文是绝对想不到还能这么搞的。
编辑:黄飞
- 相关推荐
- 热点推荐
- 算法
- 感知
- Transformer
-
基于LSS范式的BEV感知算法优化部署详解2024-01-02 7947
-
BEV感知算法:下一代自动驾驶的核心技术2024-01-25 5499
-
未来已来,多传感器融合感知是自动驾驶破局的关键2024-04-11 2422
-
BEV+Transformer对智能驾驶硬件系统有着什么样的影响?2023-02-16 4119
-
黑芝麻智能在BEV感知方面的研发进展2023-05-15 2649
-
基于几何变换器的2D-to-BEV视图转换学习2023-06-06 2683
-
基于Transformer的目标检测算法2023-08-16 1206
-
BEV人工智能transformer2023-08-22 1699
-
CVPR上的新顶流:BEV自动驾驶感知新范式2023-08-23 1953
-
利用Transformer BEV解决自动驾驶Corner Case的技术原理2023-10-11 2170
-
智能驾驶感知算法梳理 高阶自动驾驶落地关键分析2023-10-19 1042
-
BEV感知的二维特征点2023-11-14 1566
-
基于Transformer的多模态BEV融合方案2024-01-23 4326
-
黑芝麻智能开发多重亮点的BEV算法技术 助力车企高阶自动驾驶落地2024-03-29 3211
-
自动驾驶中一直说的BEV+Transformer到底是个啥?2024-11-07 2855
全部0条评论

快来发表一下你的评论吧 !
