

人工智能之传统机器学习
人工智能
描述
人工智能之传统机器学习
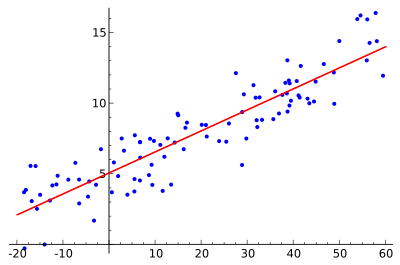
• 线性回归(Liner Regression)
o 线性回归就是找到一条直线,使用数据点来寻找最佳拟合线。它试图通过将直线方程与该数据拟合来表示自变量(x值)和数值结果(y值)。如公式,y=kx+b,y是因变量,x是自变量,利用给定的数据集求k和c的值。
• 逻辑回归(Logistic Regression)
o 逻辑回归与线性回归类似,但它用于输出二元分类情况(即,输出结果只有两个可能值),对最终输出的预测是一个非线性的S型函数。
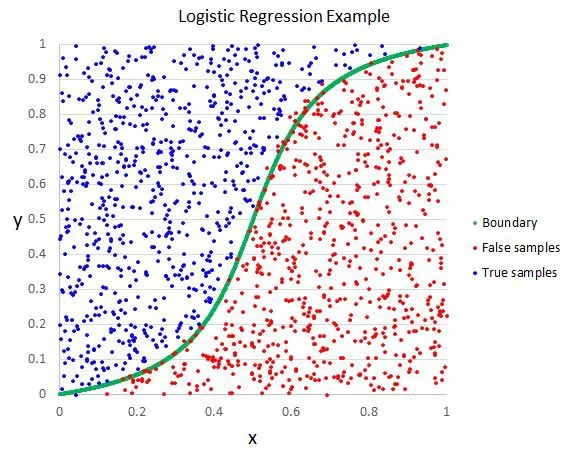
这个逻辑函数将中间结果映射到结果变量y,其值范围在0和1之间。这些值是y出现的概率。S型逻辑函数的性质让逻辑回归更适合用于分类问题。
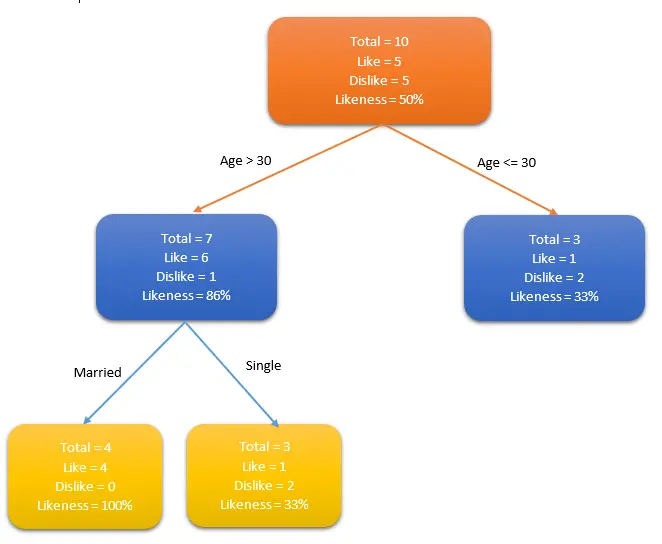
• 决策树(Decision Tree)
o 决策树用于回归和分类问题。训练模型通过学习树表示的决策规则来学习预测目标变量的值。树是具有相应属性的节点组成的。在每个节点上,根据可用的特征询问有关数据问题,左右分支表示可能的答案,最终节点(叶节点)对应一个预测值。每个特征的重要性是通过自顶而下方法确定的,节点越高,其属性越重要。如下图人群中谁喜欢使用信用卡例子中,如果一个人结婚了,他超过30岁,他们更有可能拥有信用卡(100%偏好)。测试数据用于生成决策树。
• 朴素贝叶斯(Naïve Bayes)
o 朴素贝叶斯基于贝叶斯定理。它测量每个类的概率,每个类的条件概率给出x值。这个算法用于分类问题,得到一个二进制”是/非”的结果。

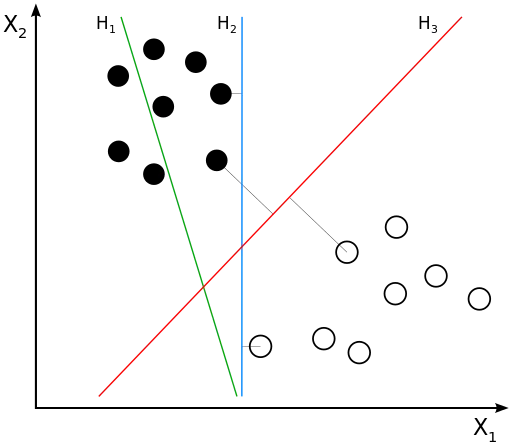
• 支持向量机(Support Vector Machine/SVM)
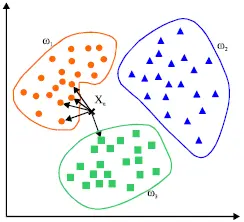
o 支持向量机是一种用来解决二分类问题的机器学习算法,它通过在样本空间中找到一个划分超平面,将不同类别的样本分开,同时使得两个点集到此平面的最小距离最大,两个点集中的边缘点到此平面的距离最大。如下图所示,图中有黑点和白点两类样本,支持向量机的目标就是找到一条直线(H3),将黑点和白点分开,同时所有黑点和白点到这条直线(H3)的距离加起来的值最大。
• K-最近邻算法(K-Nearest Neighbors/KNN)
o KNN算法是一种基于实例的学习,或者是局部近似和将所有计算推迟到分类之后的惰性学习。用最近的邻居(k)来预测未知数据点。k值是预测精度的一个关键因素,无论是分类还是回归,衡量邻居的权重都非常有用,较近邻居的权重比较远邻居的权重大。KNN算法的缺点是对数据的局部结构非常敏感。计算量大,需要对数据进行规范化处理,使每个数据点都在相同的范围。
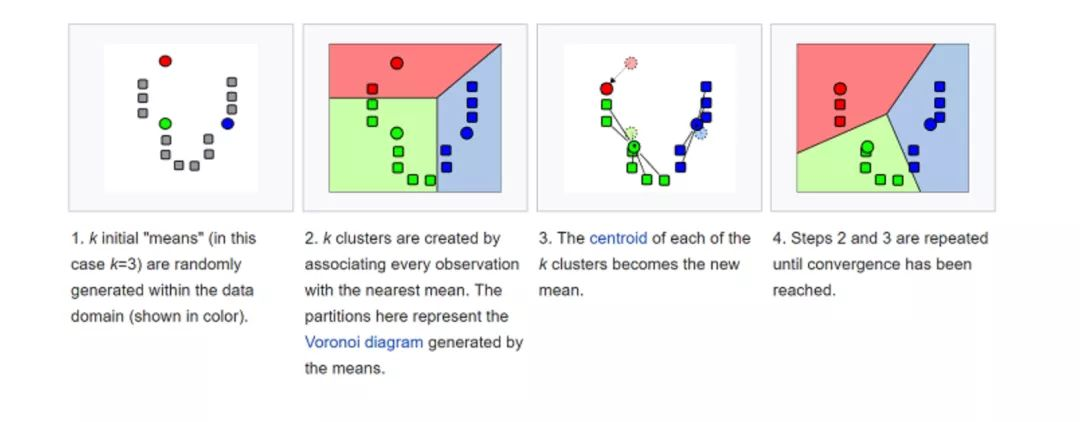
• K均值(K-Means)
o k-平均算法(K-Means)是一种无监督学习算法,为聚类问题提供了一种解决方案。K-Means算法把n个点(可以是样本的一次观察或一个实例)划分到k个集群(cluster),使得每个点都属于离他最近的均值(即聚类中心,centroid)对应的集群。重复上述过程一直持续到重心不改变。
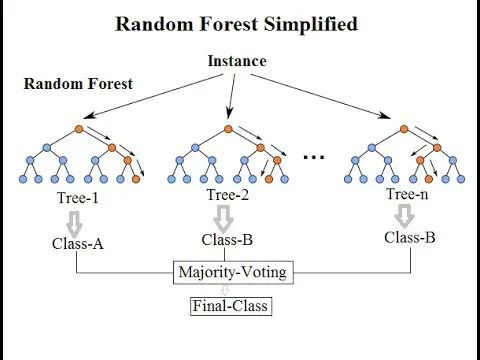
• 随机森林(Random Forest)
o 随机森林(Random Forest)是一种非常流行的集成机器学习算法。这个算法的基本思想是,许多人的意见要比个人的意见更准确。在随机森林中,我们使用决策树集成(参见决策树)。为了对新对象进行分类,我们从每个决策树中进行投票,并结合结果,然后根据多数投票做出最终决定。
• 降维(Dimensional Reduction)
o 降维是指在限定条件下,降低随机变量个数,得到一组“不相关”主变量的过程,并可进一步细分为特征选择和特征提取两大方法。
审核编辑:汤梓红
-
人工智能是什么?2015-09-16 6432
-
分享:人工智能算法将带领机器人走向何方?2017-08-16 6072
-
人工智能和机器学习的前世今生2018-08-27 3595
-
【专辑精选】人工智能之Python教程与资料2019-05-06 4081
-
人工智能:超越炒作2019-05-29 5030
-
人工智能、数据挖掘、机器学习和深度学习的关系2020-03-16 2848
-
python人工智能/机器学习基础是什么2020-04-28 3235
-
人工智能、机器学习、数据挖掘有什么区别2020-05-14 3557
-
人工智能和机器学习技术在2021年的五个发展趋势2021-01-27 4868
-
人工智能基本概念机器学习算法2021-09-06 2781
-
物联网人工智能是什么?2021-09-09 5344
-
什么是人工智能、机器学习、深度学习和自然语言处理?2022-03-22 4695
-
嵌入式人工智能学习路线2022-09-16 4530
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 2372
-
机器学习和人工智能有什么区别?2023-04-12 1242
全部0条评论

快来发表一下你的评论吧 !
