

单片机的程序优化方案有哪些
控制/MCU
描述
01 程序结构优化
1、程序的书写结构 虽然书写格式并不会影响生成的代码质量,但是在实际编写程序时还是应该遵循一定的书写规则,一个书写清晰、明了的程序,有利于以后的维护。在书写程序时,特别是对于While、for、do…while、if…else、switch…case 等语句或这些语句嵌套组合时,应采用“缩格”的书写形式。
2、标识符 程序中使用的用户标识符除要遵循标识符的命名规则以外,一般不要用代数符号(如a、b、x1、y1)作为变量名,应选取具有相关含义的英文单词(或缩写)或汉语拼音作为标识符,以增加程序的可读性,如:count、number1、red、work 等。
3、程序结构 C 语言是一种高级程序设计语言,提供了十分完备的规范化流程控制结构。因此在采用C 语言设计单片机应用系统程序时,首先要注意尽可能采用结构化的程序设计方法,这样可使整个应用系统程序结构清晰,便于调试和维护。
对于一个较大的应用程序,通常将整个程序按功能分成若干个模块,不同模块完成不同的功能。各个模块可以分别编写,甚至还可以由不同的程序员编写,一般单个模块完成的功能较为简单,设计和调试也相对容易一些。在C 语言中,一个函数就可以认为是一个模块。
所谓程序模块化,不仅是要将整个程序划分成若干个功能模块,更重要的是,还应该注意保持各个模块之间变量的相对独立性,即保持模块的独立性,尽量少使用全局变量等。对于一些常用的功能模块,还可以封装为一个应用程序库,以便需要时可以直接调用。但是在使用模块化时,如果将模块分成太细太小,又会导致程序的执行效率变低(进入和退出一个函数时保护和恢复寄存器占用了一些时间)。
4、定义常数 在程序化设计过程中,对于经常使用的一些常数,如果将它直接写到程序中去,一旦常数的数值发生变化,就必须逐个找出程序中所有的常数,并逐一进行修改,这样必然会降低程序的可维护性。因此,应尽量当采用预处理命令方式来定义常数,而且还可以避免输入错误。
5、减少判断语句 能够使用条件编译(ifdef)的地方就使用条件编译而不使用if 语句,有利于减少编译生成的代码的长度。
6、表达式 对于一个表达式中各种运算执行的优先顺序不太明确或容易混淆的地方,应当采用圆括号明确指定它们的优先顺序。一个表达式通常不能写得太复杂,如果表达式太复杂,时间久了以后,自己也不容易看得懂,不利于以后的维护。
7、函数 对于程序中的函数,在使用之前,应对函数的类型进行说明,对函数类型的说明必须保证它与原来定义的函数类型一致,对于没有参数和没有返回值类型的函数应加上“void”说明。如果果需要缩短代码的长度,可以将程序中一些公共的程序段定义为函数。如果需要缩短程序的执行时间,在程序调试结束后,将部分函数用宏定义来代替。注意,应该在程序调试结束后再定义宏,因为大多数编译系统在宏展开之后才会报错,这样会增加排错的难度。
8、尽量少用全局变量,多用局部变量 因为全局变量是放在数据存储器中,定义一个全局变量,MCU 就少一个可以利用的数据存储器空间,如果定义了太多的全局变量,会导致编译器无足够的内存可以分配;而局部变量大多定位于MCU 内部的寄存器中,在绝大多数MCU 中,使用寄存器操作速度比数据存储器快,指令也更多更灵活,有利于生成质量更高的代码,而且局部变量所能占用的寄存器和数据存储器在不同的模块中可以重复利用。
9、设定合适的编译程序选项 许多编译程序有几种不同的优化选项,在使用前应理解各优化选项的含义,然后选用最合适的一种优化方式。通常情况下一旦选用最高级优化,编译程序会近乎病态地追求代码优化,可能会影响程序的正确性,导致程序运行出错。因此应熟悉所使用的编译器,应知道哪些参数在优化时会受到影响,哪些参数不会受到影响。
02 代码的优化
1、选择合适的算法和数据结构 应熟悉算法语言。将比较慢的顺序查找法用较快的二分查找法或乱序查找法代替,插入排序或冒泡排序法用快速排序、合并排序或根排序代替,这样可以大大提高程序执行的效率。
选择一种合适的数据结构也很重要,比如在一堆随机存放的数据中使用了大量的插入和删除指令,比使用链表要快得多。数组与指针具有十分密切的关系,一般来说指针比较灵活简洁,而数组则比较直观,容易理解。对于大部分分的编译器,使用指针比使用数组生成的代码更短,执行效率更高。
但是在Keil 中则相反,使用数组比使用的指针生成的代码更短。
2、使用尽量小的数据类型 能够使用字符型(char)定义的变量,就不要使用整型(int)变量来定义;能够使用整型变量定义的变量就不要用长整型(long int),能不使用浮点型(float)变量就不要使用浮点型变量。当然,在定义变量后不要超过变量的作用范围,如果超过变量的范围赋值,C 编译器并不报错,但程序运行结果却错了,而且这样的错误很难发现。
3、使用自加、自减指令 通常使用自加、自减指令和复合赋值表达式(如a-=1 及a+=1 等)都能够生成高质量的程序代码,编译器通常都能够生成inc 和dec 之类的指令,而使用a=a+1 或a=a-1之类的指令,有很多C 编译器都会生成2~3个字节的指令。
4、减少运算的强度 可以使用运算量小但功能相同的表达式替换原来复杂的的表达式。如下:
(1)求余运算
a=a%8;
可以改为:
a=a&7;
说明:位操作只需一个指令周期即可完成,而大部分的C 编译器的“%”运算均是调用子程序来完成,代码长、执行速度慢。通常,只要求是求2n 方的余数,均可使用位操作的方法来代替。
(2)平方运算
a=pow(a,2.0);
可以改为:
a=a*a; 说明:在有内置硬件乘法器的单片机中(如51 系列),乘法运算比求平方运算快得多,因为浮点数的求平方是通过调用子程序来实现的,在自带硬件乘法器的AVR 单片机中,如ATMega163 中,乘法运算只需2 个时钟周期就可以完成。即使是在没有内置硬件乘法器的AVR单片机中,乘法运算的子程序比平方运算的子程序代码短,执行速度快。如果是求3 次方,如: a=pow(a,3.0);
更改为:
a=a*a*a; 则效率的改善更明显。
(3)用移位实现乘除法运算
a=a*4;
b=b/4;
可以改为:
a=a《《2;
b=b》》2; 说明:通常如果需要乘以或除以2n,都可以用移位的方法代替。在ICCAVR 中,如果乘以2n,都可以生成左移的代码,而乘以其它的整数或除以任何数,均调用乘除法子程序。用移位的方法得到代码比调用乘除法子程序生成的代码效率高。实际上,只要是乘以或除以一个整数,均可以用移位的方法得到结果,如:
a=a*9
可以改为:
a=(a《《3)+a
5、循环
(1)循环语对于一些不需要循环变量参加运算的任务可以把它们放到循环外面,这里的任务包括表达式、函数的调用、指针运算、数组访问等,应该将没有必要执行多次的操作全部集合在一起,放到一个init 的初始化程序中进行。
(2)延时函数 通常使用的延时函数均采用自加的形式:
void delay (void){unsigned int i;for (i=0;i《1000;i++); }将其改为自减延时函数:void delay (void){unsigned int i;for (i=1000;i》0;i--); }
两个函数的延时效果相似,但几乎所有的C 编译对后一种函数生成的代码均比前一种代码少1~3 个字节,因为几乎所有的MCU 均有为0转移的指令,采用后一种方式能够生成这类指令。在使用while 循环时也一样,使用自减指令控制循环会比使用自加指令控制循环生成的代码更少1~3 个字母。
但是在循环中有通过循环变量“i”读写数组的指令时,使用预减循环时有可能使数组超界,要引起注意。
(3)while 循环和do…while 循环 用while 循环时有以下两种循环形式:
unsigned int i;i=0;while (i《1000){i++; //用户程序}或:unsigned int i;i=1000;do{i--; //用户程序}while (i》0);
在这两种循环中,使用do…while循环编译后生成的代码的长度短于while循环。
6、查表 在程序中一般不进行非常复杂的运算,如浮点数的乘除及开方等,以及一些复杂的数学模型的插补运算,对这些即消耗时间又消费资源的运算,应尽量使用查表的方式,并且将数据表置于程序存储区。如果直接生成所需的表比较困难,也尽量在启动时先计算,然后在数据存储器中生成所需的表,后面在程序运行直接查表就可以了,减少了程序执行过程中重复计算的工作量。
7、其它 比如使用在线汇编及将字符串和一些常量保存在程序存储器中,均有利于优化。
03 乘除法优化
目前单片机的市场竞争很激烈,许多应用出于性价比的考虑,选择使用程序存储空间较小(如1K,2K)的小资源8位MCU芯片进行开发。一般情况下,这类MCU没有硬件乘法、除法指令,在程序必须使用乘除法运算时,如果单纯依靠编译器调用内部函数库来实现,常常会有代码量偏大、执行效率偏低的缺点。
上海晟矽微电子推出的MC30、MC32系列MCU,采用了RISC架构,在小资源8位MCU领域有广大的用户群和广泛的应用,本文就以晟矽微电的这两个系列产品的指令集为例,结合汇编与C编译平台,给大家介绍一种即省时又节约资源的乘除法算法。
1、乘法篇 单片机中的乘法是二进制的乘法,也就是把乘数的各个位与被乘数相乘,然后再相加得出,因为乘数和被乘数都是二进制,所以实际编程时每一步的乘法可以用移位实现。
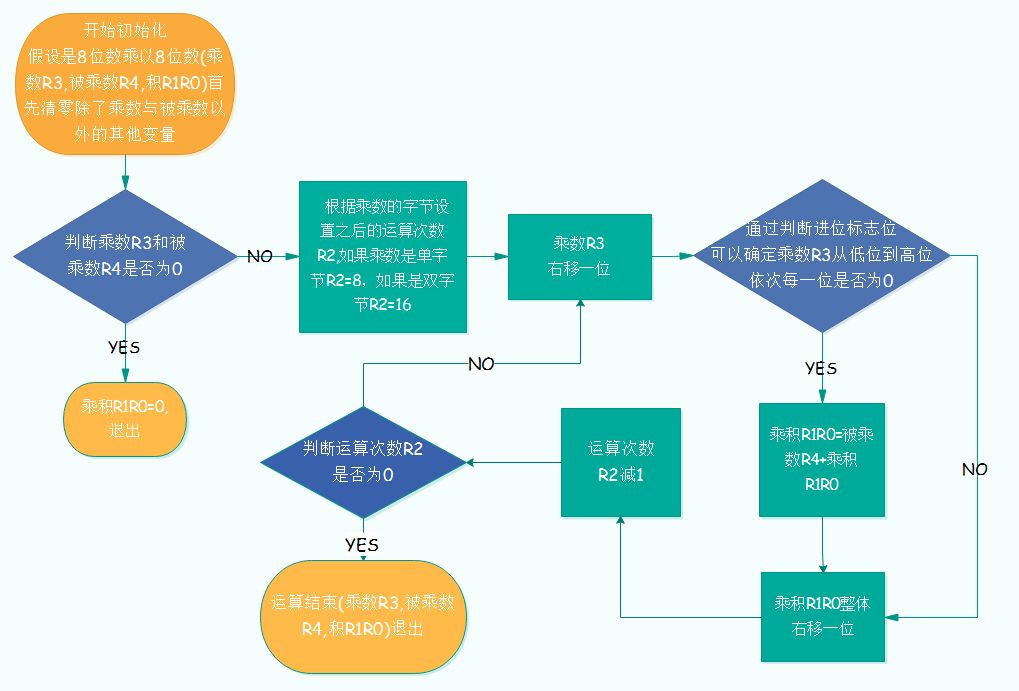
例如:乘数R3=01101101,被乘数R4=11000101,乘积R1R0。步骤如下:
1、清空乘积R1R0;
2、乘数的第0位是1,那被乘数R4需要乘上二进制数1,也就是左移0位,加到R1R0里;
3、乘数的第1位是0,忽略;
4、乘数的第2位是1,那被乘数R4需要乘上二进制数100,也就是左移2位,加到R1R0里;
5、乘数的第3位是1,那被乘数R4需要乘上二进制数1000,也就是左移3位,加到R1R0里;
6、乘数的第4位是0,忽略;
7、乘数的第5位是1,那被乘数R4需要乘上二进制数100000,也就是左移5位,加到R1R0里;
8、乘数的第6位是1,那被乘数R4需要乘上二进制数1000000,也就是左移6位,加到R1R0里;
9、乘数的第7位是0,忽略;
10、这时候R1R0里的值就是最后的乘积,至此算法完成。
以上例子运算结果:
R1R0 = R3 * R4= (R4《《6)+(R4《《5)+(R4《《3)+(R4《《2)+R4 = 101001111100001
实际运算流程图见下图:
在实际的程序设计过程中,程序优化有两个目标,提高程序运行效率,和减少代码量。我们来看下本文提供的汇编算法和普通C语言编程的效率和代码量对比。
表1.1是程序运行效率的对比数据(可能会有小的偏差),很明显汇编编译出来的运行时间要比C语言减少很多。
汇编(时钟周期)
C语言(时钟周期)
8*8位乘法
79-87
184-190
16*8位乘法
201-210
362-388
16*16位乘法
234-379
396-468
表1.1 乘法运算时钟周期对比表 表1.2是程序代码量的对比数据(可能会有小的偏差),汇编占用的程序空间也要比C语言小很多。
汇编(Byte)
C语言(Byte)
8*8位乘法
15
34
16*8位乘法
19
96
16*16位乘法
31
96
表1.2 乘法运算ROM空间使用情况对比表 综上两点,本文介绍的乘法算法各方面使用情况都要比C编译好很多。如果大家在使用过程中,原有的程序不能满足应用需求,例如遇到程序空间不够或者运行时间太久等问题,都可以按照以上方式进行优化。 汇编语言最接近机器语言的。在汇编语言中可以直接操作寄存器,调整指令执行顺序。由于汇编语言直接面对硬件平台,而不同的硬件平台的指令集及指令周期均有较大差异,这样会对程序的移植和维护造成一定的不便,所以我们针对精简指令集做了乘法运算的例程,便于大家的移植和理解。




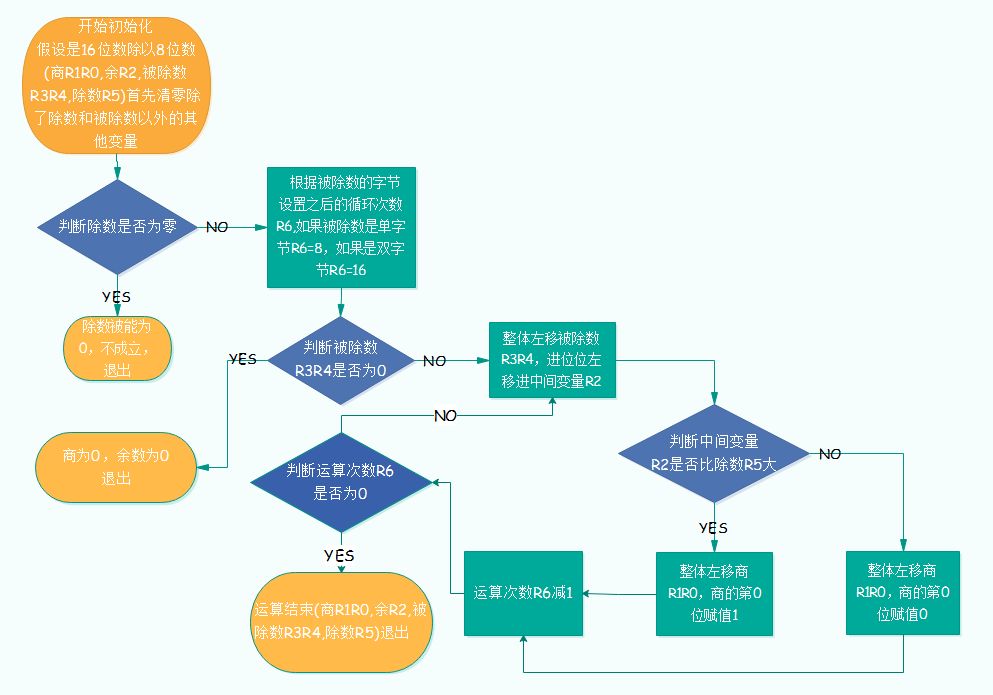
2、除法篇 单片机中的除法也是二进制的除法,和现实中数学的除法类似,是从被除数的高位开始,按位对除数进行相除取余的运算,得出的余数再和之后的被除数一起再进行新的相除取余的运算,直到除不尽为止,因为单片机中的除法是二进制的,每个步骤除出来的商最大只有1,所以我们实际编程时可以把每一步的除法看作减法运算。 例如:被除数R3R4=1100110001101101,除数R5=11000101,商R1R0,余数R2。步骤如下:
1、清空商R1R0,余数R2; 2、被除数放开最高位,第15位,为1,1比除数小,商为0,余数R2为1; 3、上一步余数并上被除数次高位,第14位,得11,11仍然比除数小,商为0,余数R2为11 4、直到放开第8位后,得11001100,比除数大,商得1,余数R2为111; 5、上一步余数并上被除数第7位,得1110,没有除数大,商为0,余数R2为1110; 6、上一步余数并上被除数第6位,得11101,没有除数大,商为0,余数R2为11101; 7、按照以上步骤,直到放开了被除数得第3位,得11101101,比除数大,商为1,余数R2为101000; 8、上一步余数并上被除数第2位,得1010001,没有除数大,商为0,余数R2为1010001; 9、上一步余数并上被除数第1位,得10100010,没有除数大,商为0,余数R2为10100010; 10、上一步余数并上被除数第0位,得101000101,比除数大,商为1,余数R2为10000000; 11、然后把以上所有步骤中得商从左至右依次排列就是最后的商100001001,余数为最后算得的余数10000000。 以上例子运算结果:R1R0 = R3R4 / R5 = 100001001 ;R2 = R3R4 % R5 = 10000000 实际运算流程图见下图:
除法运算的效率,代码量见以下表格 表2.1是程序运行效率和代码量的对比数据(可能会有小的偏差),很明显本文提供的汇编算法要优化的很多。
16/8位除法
汇编
C语言
时钟周期
287-321
740-804
使用空间(Byte)
35
142
表2.1 除法运算时钟周期对比表 所以对于除法运算,本文提供的方法也是相对较优的。 以下是针对精简指令集做的除法运算,16/8位的例程,便于大家的移植和理解。


编辑:黄飞
-
单片机怎么烧程序2025-07-23 2485
-
单片机程序应用、驱动分层独立开发方案2021-11-13 903
-
单片机按键使用程序 (51单片机)2021-11-11 2969
-
如何对单片机程序结构进行优化2021-09-22 1564
-
单片机程序如何编写2020-02-12 39881
-
单片机有哪些品牌和单片机软件延时10ms的程序及有哪些排序算法2019-07-10 1333
-
为什么单片机的程序必须是死循环2019-07-05 1938
-
51单片机有哪些常用程序?51单片机4个常用程序汇总2018-09-05 4498
-
怎么读取单片机程序_单片机程序是如何执行的_如何读懂单片机程序2018-02-02 79269
-
单片机程序的设计基础2017-11-23 823
-
单片机程序有多大 怎么看?2016-12-12 9241
-
单片机蜂鸣器_各种发声程序2015-12-29 1360
-
单片机程序烧录工具集合2015-12-28 2062
-
51单片机流水灯程序2015-12-21 2129
全部0条评论

快来发表一下你的评论吧 !
