

ARM CSS N2处理器解析
处理器/DSP
描述
Arm 刚刚在 HotChips 上透露了以 CSS N2 为首的计算子系统 (CSS) 发展方向。CSS 背后的意图是提供预集成、优化和验证的子系统,以加快基础设施系统构建商的产品上市时间。想想 HPC 服务器、无线基础设施、用于工业、城市和企业自动化的大型边缘系统。
这回答了 Arm 如何在不成为芯片公司的情况下为系统开发商带来更多价值。他们比其他任何人都更了解自己的技术;通过提供预设计、优化和验证的子项目(内核、连贯互连、中断、内存管理和 I/O 接口)以及 SystemReady 验证,他们可以缩短整个系统开发周期。
加速定制芯片
围绕内核、互连和其他 IP 的完全定制设计显然能提供最大的灵活性和差异化能力,但这是要付出代价的。这种代价不仅体现在开发上,还体现在部署时间上。在快速发展的市场中,时间正在成为一个非常关键的因素--看看人工智能及其对超分级数据中心的推动作用就知道了。我们不得不相信,当前的经济不确定性加剧了这些担忧。
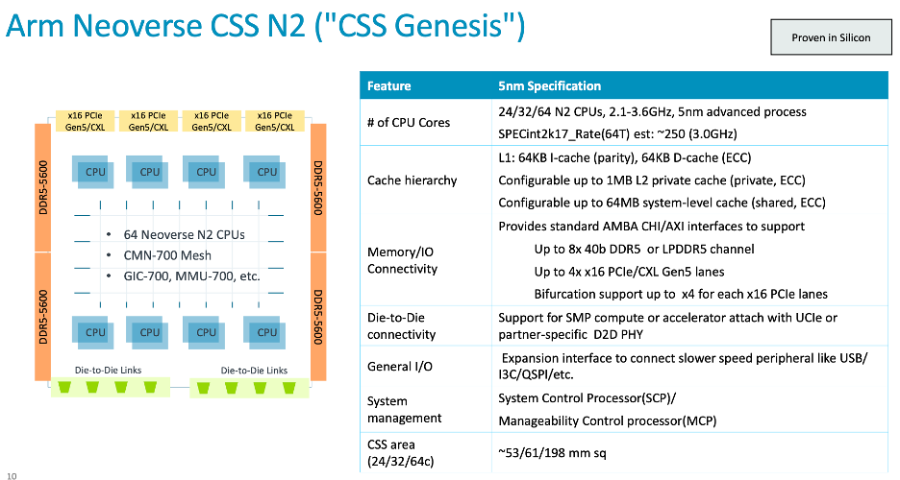
这些压力很可能迫使人们只在必要的地方强调差异化,而在其他地方则强调标准化,尤其是当经过验证的专家可以处理大型核心组件时。CSS 为多核计算提供了一个非常标准但可配置的子系统,包括 N2 内核(在本例中)、这些内核之间的相干网状网络、中断和内存管理、高速缓存层次结构、通过 UCIe 或定制接口提供的芯片组支持、DDR5/LPDDR5 外部内存接口、用于快速 IO 和相干 IO 的 PCIe/CXL Gen5、扩展 IO 和系统管理。
所有 PPA 均针对先进的 5nm TSMC 工艺进行了优化,并通过参考软件栈证明了 SystemReady。通过增加加速器、专用计算、自己的电源管理等,系统开发人员仍有很大的差异化空间。
Neoverse V2
Arm 还发布了 Neoverse V 系列的下一代产品,与 V1 版本相比,不出意外地提高了整数性能,减少了系统级缓存缺失。在其他各种基准测试中也有改进。
同样值得一提的是它在英伟达 Grace-Hopper 组合(基于 Neoverse V2)中的表现。英伟达(NVIDIA)与 Arm 分享了真实的硬件数据,介绍了与英特尔Sapphire Rapids和 AMD Genoa 的性能对比。在原始性能方面,Grace CPU 与 AMD 基本持平,总体上比 Sapphire Rapids 快 30-40%。
最令人印象深刻的是他们计算的数据中心功率限制为 5MW,这一点非常重要,因为所有数据中心的功率最终都会受到限制。在这种情况下,Grace的性能比 AMD 高出 70% 到 150%,远远领先于英特尔。
净价值
首先是 Neoverse 对 Grace-Hopper 的贡献。由于人工智能,特别是大型语言模型,该系统目前正处于技术领域的中心。这是一个令人难以置信的参考。其次,虽然英特尔和 AMD 可以提供比基于 Arm 的系统更好的峰值性能,而且 Grace-Hopper 的工作负载有些特殊,但大多数工作负载并不需要高端性能,而人工智能现在正在进入一切领域。从整个数据中心的成本和可持续发展角度来看,基于 Arm 的系统不应该发挥更大的作用,尤其是在支出预算紧缩的情况下,这一点越来越难以成立。
对于 CSS-N2,Arm 根据自己的分析估计,开发 CSS N2 级集成需要长达 80 个工程年的努力,现有客户证实这个数字是准确的。在工程师受限的环境中,这 80 个工程年可以从他们的项目成本和进度中减去,而不会影响他们想在计算核心周围增加的任何秘密差异化。
这些看起来是 Arm Neoverse 产品线非常合理的下一步计划。在 V 系列中实现更快的性能,让客户利用 Arm 自身在构建基于 N2 的计算系统方面的经验和专业知识,同时为客户添加自己的特殊调味汁留出很大的空间。
审核编辑:刘清
-
Arm新Arm Neoverse计算子系统(CSS):Arm Neoverse CSS V3和Arm Neoverse CSS N32024-04-24 3353
-
Arm Cortex-M55处理器数据集2023-08-25 1121
-
Arm Cortex-R82处理器技术参考手册2023-08-17 1738
-
rk3566处理器属于什么档次?2023-08-15 38367
-
请问RISC处理器和ARM7处理器的区别在哪2022-06-30 5996
-
arm11处理器特点2017-11-10 3302
-
ARM为移动和消费应用推出Cortex-A8处理器2016-01-22 1212
-
苹果a6处理器怎么样_a6处理器参数2012-09-13 26785
-
ARM Cortex-M1处理器构架介绍2011-11-30 9432
-
基于低功率混合信号 ARM Cortex-M4处理器的 Ki2010-06-29 1345
-
ARM推出节能型SecurCore SC000处理器2010-03-19 2261
-
恩智浦获得ARM Cortex-M4处理器授权2010-03-03 1812
-
基于ARM的PC/104处理器模块设计2009-08-25 878
-
ARM9处理器与ARM7处理器比较2006-03-11 2173
全部0条评论

快来发表一下你的评论吧 !
