

机器学习模型评估指标
人工智能
描述
机器学习模型指标
在机器学习建模过程中,针对不同的问题,需采用不同的模型评估指标。
主要分为两大类:分类、回归。
1分类问题评估指标
• 混淆矩阵

真阳(True Positive,TP):被模型预测为正的正样本。
假阳(False Positive,FP):被模型预测为正的负样本。
假阴(False Negative,FN):被模型预测为负的正样本。
真阴(True Negative,TN):被模型预测为负的负样本。
真阳率(True Positive Rate,TPR)或灵敏度(sensitivity)
TPR
=TP/(TP+FN)
===> 正样本预测结果数/正样本实际数
真阴率(True Negative Rate,TNR)或特指度/特异度(specificity)
TNR
= TN/(TN+FP)
===> 负样本预测结果数/负样本实际数
假阳率(False Positive Rate,FPR)
FPR
= FP/(FP+TN)
===> 被预测为正的负样本结果数/负样本实际数
假阴率(False Negative Rate,FNR)
FNR
= FN/(TP+FN)
===> 被预测为负的正样本结果数/正样本实际数
• 准确率 – Accuracy
o 准确率,是最常用的分类性能指标。
Accuracy
= (TP+TN)/(TP+FN+FP+TN)
即正确预测的正反例数/总数
• 精确率(查准率)- Precision
o 只针对预测正确的正样本,表现为预测为正的里面有多少真正是正的。可理解为查准率。
Precision
= TP/(TP+FP)
即正确预测的正例数/实际正例总数
• 召回率(查全率)- Recall
o 召回率表现出在实际正样本中,分类器能预测出多少。与真正率相等,可理解为查全率。
Recall
= TP/(TP+FN)
即正确预测的正例数/实际正例总数
• ROC曲线
o ROC(Receiver Operating Characteristic)曲线,又称接受者操作特征曲线。ROC曲线的横轴为False Positive Rate,也叫伪阳率(FPR),即预测错误且实际分类为负的数量与所有负样本数量的比例,纵轴为True Positive Rate,也叫真阳率(TPR),即预测正确且实际分类为正的数量与所有正样本的数量的比例。
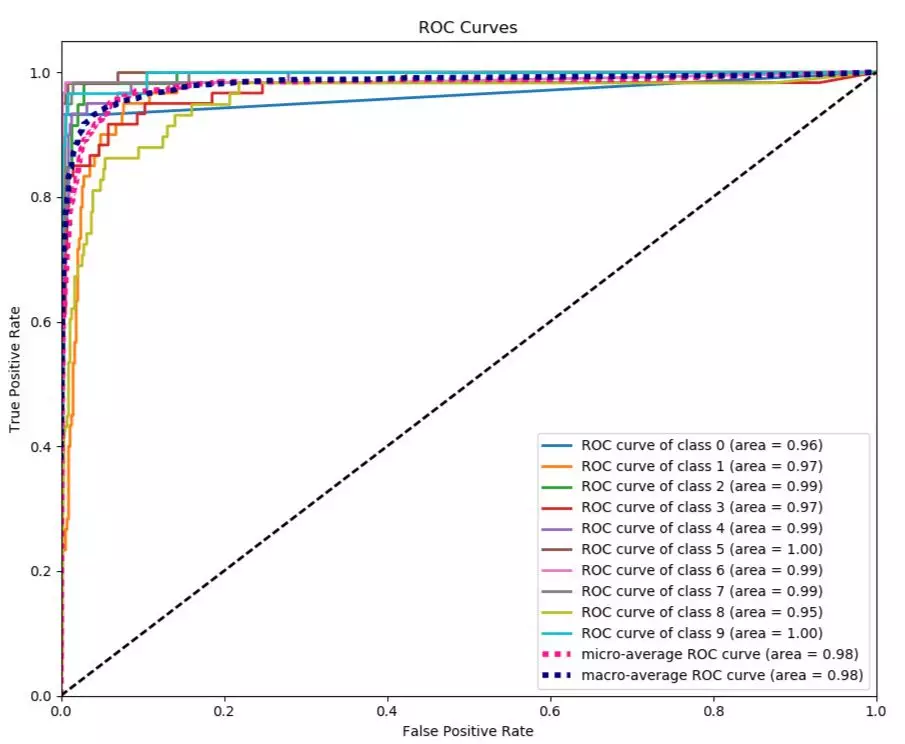
• AUC
o AUC的全称是(Area Under ROC Curve),也就是ROC曲线下方的面积,AUC的范围是0到1,AUC越大,代表模型的性能越好。
2分类问题评估指标
• MAE(Mean Absolute Error)平均绝对误差
o 平均绝对误差(Mean Absolute Error,MAE),也称为L1损失,是最简单的损失函数之一,也是一种易于理解的评估指标。它是通过取预测值和实际值之间的绝对差值并在整个数据集中取平均值来计算的。从数学上讲,它是绝对误差的算术平均值。MAE仅测量误差的大小,不关心它们的方向。MAE越低,模型的准确性就越高。
• MSE(Mean Squared Error)均方误差
o 均方误差也称为L2损失,MSE通过将预测值和实际值之间的差平方并在整个数据集中对其进行平均来计算误差。MSE也称为二次损失,因为惩罚与误差不成正比,而是与误差的平方成正比。平方误差为异常值赋予更高的权重,从而为小误差产生平滑的梯度。MSE永远不会是负数,因为误差是平方的。误差值范围从零到无穷大。MSE随着误差的增加呈指数增长。一个好的模型的MSE值接近于零。
• RMSE(Root Mean Squared Error)均方根误差
o RMSE是通过取MSE的平方根来计算的。RMSE也称为均方根偏差。它测量误差的平均幅度,并关注与实际值的偏差。RMSE值为零表示模型具有完美拟合。RMSE越低,模型及其预测就越好。
• NRMSE(Normalized Root Mean Squared Error)归一化均方根误差
o 归一化RMSE通常通过除以一个标量值来计算,它可以有不同的方式。有时选择四分位数范围可能是最好的选择,因为其他方法容易出现异常值。当您想要比较不同因变量的模型或修改因变量时,NRMSE是一个很好的度量。它克服了尺度依赖性,简化了不同尺度模型甚至数据集之间的比较。
审核编辑:汤梓红
-
机器学习模型之性能度量2020-05-12 1716
-
从利用认知 API 到构建出自定义的机器学习模型面临哪些挑战?2021-07-12 1467
-
什么是机器学习? 机器学习基础入门2022-06-21 3103
-
部署基于嵌入的机器学习模型2022-11-02 3647
-
机器学习之模型评估和优化2017-10-12 1124
-
网络安全评估指标优化模型2017-11-21 616
-
如何构建检测信用卡诈骗的机器学习模型?2018-10-04 3792
-
机器学习算法常用指标汇总2019-02-13 6220
-
机器学习的模型评估与选择详细资料说明2020-03-24 1466
-
机器学习模型评估的11个指标2020-05-04 4471
-
这些机器学习分类器性能标准你知道吗?2020-11-27 2918
-
分类模型评估指标汇总2020-12-10 1654
-
探究机器学习 (ML) 模型的性能2021-04-13 3546
-
如何评估机器学习模型的性能?机器学习的算法选择2023-04-04 1913
-
机器学习算法汇总 机器学习算法分类 机器学习算法模型2023-08-17 2437
全部0条评论

快来发表一下你的评论吧 !
