

墨芯Antoum芯片赋能大模型在各行各业的落地
描述
近日,墨芯人工智能携AntoumⓇ芯片亮相芯片行业的国际顶级大会Hot Chips 2023,墨芯首席架构师肖志斌博士在大会Tutorials上发表对行业趋势的分享,并在Conference Day介绍AntoumⓇ的创新架构。
一年一度的Hot Chips是全球芯片产业界影响力最大的活动,被誉为“芯片产业的风向标”,每年都有来自业界前沿的众多头部企业,发布最新产品与创新技术。
今年Hot Chips云集了NVIDIA、高通、英特尔、AMD等芯片巨头,与墨芯等代表性初创企业,介绍前沿技术与企业最新成果。
肖志斌博士进行《Moffett AntoumⓇ: A Deep-Sparse AI Inference System-on-Chip for Vision and Large Language Models》主题分享,介绍了的AntoumⓇ芯片的创新架构,及AntoumⓇ在大语言模型、计算机视觉等任务上的优势与特点。
由于深度学习模型复杂性的提升及模型的广泛应用,AI计算需求呈指数级增长。尤其是ChatGPT掀起大模型浪潮后,算力供需不平衡的问题日益突出。针对算力难题,墨芯推出全球首颗高倍率稀疏芯片AntoumⓇ,实现了更高的推理效率与能效比。
AntoumⓇ独特的稀疏计算单元SPU(Sparse Processing Unit),可以在负载均衡的情况下进行并行计算,并且只计算非零值,即忽略零元素的存储、搬移、计算,大大提高了计算单元的利用率,进而减少功耗与延时,同时增加吞吐率。SPU载有Deep Sparse Tensor Core(深度稀疏张量核心),实现稀疏神经网络的高模型精度和高硬件利用效率。
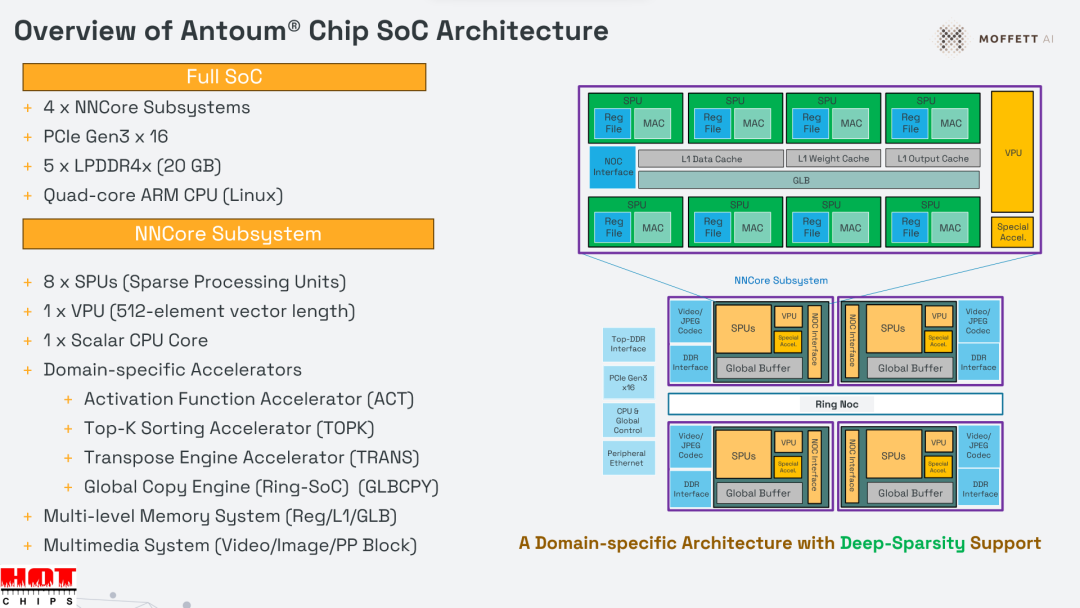
除了利用稀疏处理单元(SPU)支持深度稀疏性之外,AntoumⓇ还采用了特定领域架构,将各种特殊功能加速器以及内部设计的矢量处理单元与可扩展的片上网络连接起来。
AntoumⓇ共有 32 个 SPU,支持 BF16 和 INT8 数据精度,密集吞吐量为 14.7 TFLOPS 和 29.5 TOPS,在 32 倍稀疏性条件下可实现相当于 471.8 TFLOPS 和 943.6 TOPS 的性能。
此外,AntoumⓇ芯片还具有多个亮点:
存储器层次结构包含总计 82 MB 的片上 SRAM,由 SPU、VPU 和特殊功能加速器共享。
特殊功能加速器包括激活功能、TOPK、Transpose、嵌入式查找以及图像预处理和后处理功能。
高带宽环形互连连接四个 NNCore 子系统,支持模型并行化和张量并行化。
专用硬件视频编解码引擎和 JPEG 解码引擎。四个视频解码器引擎和一个视频编码引擎可处理多通道视频流(高达 4K),并可轻松将可扩展的深度学习集成到视频处理中。集成的 8 个硬件 JPEG 解码器可载 CPU 密集型 JPEG 解码任务,并能以超过 2000 FPS 的速度解码 1080p JPEG 图像。
PCIe Gen3 x 16 和 20 GB LPDDR4x 内存,理论峰值内存带宽高达 84 GB/s,功耗仅为 70 W。
在软件方面,AntoumⓇ由墨芯 SparseRT 软件开发环境支持,为加速开发提供了一个完整的、可扩展的平台,并增强了稀疏计算的能力。现有的机器学习(ML)框架,如 TensorFlow、PyTorch、ONNX 和 MXNet,都能得到SparseRT 全面高效的支持。独特的 SparseOPT 模型压缩工具可为AI模型提供4倍到32倍的稀疏压缩。这样就可以轻松集成到现有的模型交付中,释放大模型的潜力。
AntoumⓇ芯片的优异性能,已在连续两届权威测评MLPerf中得到验证。同时,基于AntoumⓇ的墨芯第一代AI计算卡产品已实现量产,并已在互联网、生命科学、智慧交通等领域落地,产业化接连取得重要进展。墨芯将持续为客户带来高效的大模型算力方案,赋能大模型在各行各业的落地。
审核编辑:彭菁
-
为何液晶可以应用到各行各业?2019-01-29 2518
-
5G会给各行各业带来什么?2018-07-04 5052
-
5G是怎样通过各种形式赋能各行各业2019-04-09 2239
-
“+智能”时代,华为如何将AI赋能到各行各业?2019-07-03 889
-
机器人的发展将在未来渗透我们的各行各业2019-08-17 1252
-
AWS是如何推动AI技术实际落地到各行各业场景中?2019-09-20 12590
-
智能变革时代 人工智能技术正在“赋能”各行各业2020-03-12 1606
-
“新基建”赋能各行各业的智能化转型,推动中国制造业实现转型升级2020-07-21 1370
-
华为用案例分析5G在各行各业中承担的作用2020-08-18 7618
-
徐雷:5G网络安全需要各行各业协同创新2020-11-29 3162
-
机器视觉赋能智能制造,广泛应用于各行各业2021-08-08 779
-
机智云通过数字赋能传统行业 助力各行各业智能升级2021-12-07 2479
-
全志的芯片为什么能覆盖到各行各业?专访全志集团副总裁胡东明2023-10-20 2621
-
单北斗赋能各行各业,顶坚工作记录仪开启智能化管理2024-09-06 840
-
达实智能在各行各业的应用案例2024-10-24 1461
全部0条评论

快来发表一下你的评论吧 !
