

墨芯支持Byte MLPerf助力AI应用
描述
在大模型趋势下,墨芯通过领先的稀疏计算优势,助力企业加速AI应用,商业化进程接连取得重要突破。
近日,AI推理评测ByteMLPerf 公开了墨芯S30计算卡的评测结果。墨芯成为支持ByteMLPerf的供应商之一。
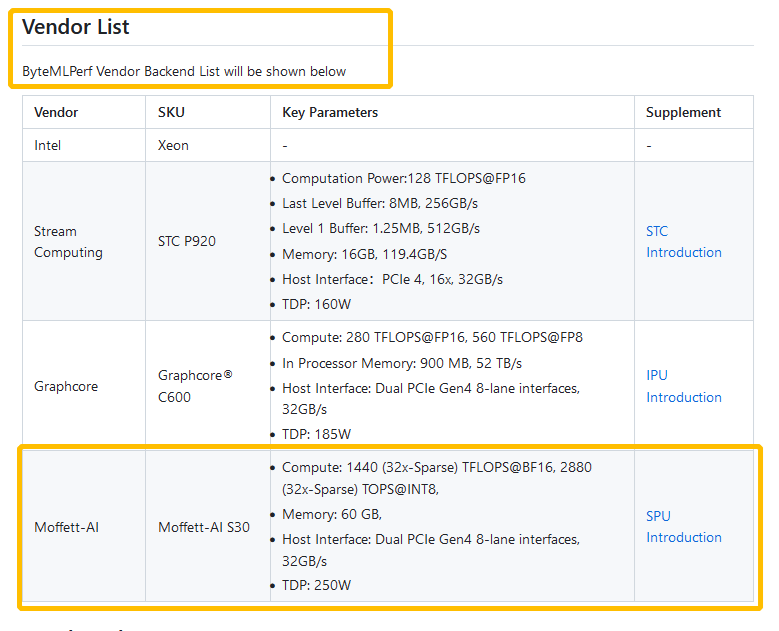
图:墨芯是适配Byte MLPerf(推理)的供应商之一

图:Byte MLPerf基准套件介绍
Byte MlPerf 的评估会分为三个方面,如下:
1. Graph Compiler的易用性、扩展性以及覆盖率;
2. 运行精度评估:包括数值误差和模型跑数据集精度;
3. 运行性能评估:不同场景下的(一般指BS不同)的吞吐和延时表现。
墨芯产品与Byte MLPerf的成功适配,标志着墨芯的商业化进程迈出重要一步,再度印证了稀疏计算在推理性能、能效比等方面的多重优势,展现出墨芯AI计算平台在业务场景中的巨大应用价值。
性能突出
凸显应用价值
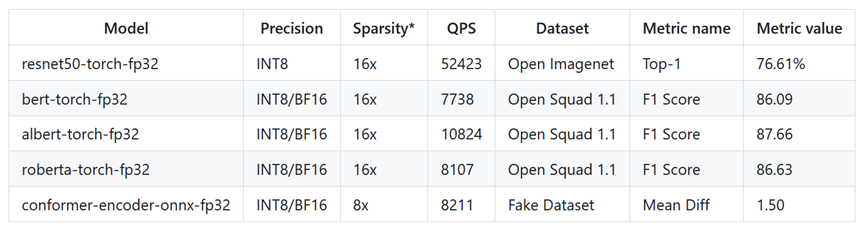
图:墨芯AI计算平台在Byte MLPerf上的性能数据
基于墨芯独创的双稀疏算法与软硬协同设计,墨芯AI计算平台不仅支持Byte MLPerf 模型库中的多个模型,而且以优秀的性能与高能效比,贴合实际业务场景的需求:
01
大幅降低TCO,助力企业降本增效
稀疏计算去除了AI计算中的无效元素,因而提升计算效率,墨芯S30计算卡的峰值功耗仅为 250W,意味着降低AI计算过程中的运营成本、基础设施等成本,缓解算力昂贵等业界难题。
02
应用场景广泛
墨芯AI计算平台支持Byte MLPerf 模型库中的计算机视觉、语音、自然语言处理等多类任务,适用于识别、检测、推荐、AIGC等多种AI应用场景,助力企业拓宽AI业务布局。
软硬协同平台
快速赋能AI落地
墨芯基于性能领先的硬件产品与软件平台,为客户提供企业级端到端的解决方案:墨芯SparseRT 软件开发环境全面支持硬件产品,为快速开发提供了完整的可扩展平台并激活稀疏计算的潜力。同时SparseRT 可以高效支持通用的AI編程框架,如TensorFlow、PyTorch、ONNX和MXNet等。用户可以在熟悉的TensorFlow或PyTorch环境里进行开发之后再进行迁移与交付。
SparseRT独特的SparseOPT为AI模型提供4至32倍的稀疏压缩能力,并且易于集成到现有的模型交付流程中,从而充分释放大模型的实时服务潜力。SparseRT提供可视化性能分析工具,支持离线和实时的模型性能分析,帮助开发人员分析模型中存在的瓶颈,并提供模型部署优化建议,使开发人员能将墨芯的软硬件解决方案几乎零成本集成到现有的基础设施和算法交付中。
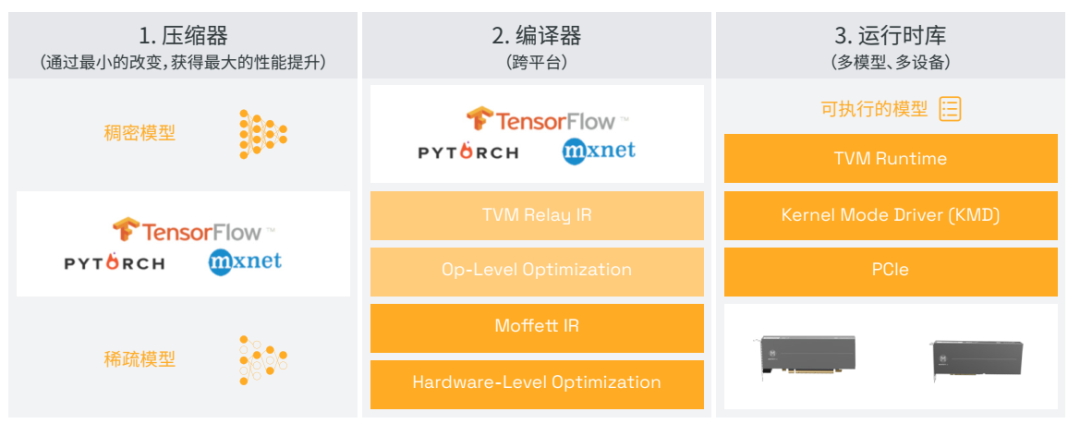
图 / 墨芯软硬协同AI计算平台
墨芯将持续与客户紧密协作,共同探索更多AI应用场景,以创新的AI计算平台与服务,为各行业的智能化升级创造更多价值。
审核编辑:刘清
-
软硬件协同优化,平头哥玄铁斩获MLPerf四项第一2022-04-08 5779
-
小米墨案AI录音笔高清图赏2019-08-20 3475
-
瑞芯微AI平台三大升级 助力端侧AI应用2019-12-24 1480
-
AI芯片厂商墨芯完成融资,将继续用于新产品的研发2021-01-20 2727
-
NVIDIA AI平台在MLPerf基准测试实现飞跃2022-07-01 1975
-
墨芯当选“2022中国AI芯片企业50强”2022-09-02 2650
-
算法将如何引领AI芯片的未来2022-09-23 1845
-
MLPerf 3.0最新发榜,戴尔AI和边缘服务器拿下历史最好成绩2023-04-12 3002
-
墨芯人工智能荣获“2024AI算力层创新企业奖”2024-05-17 1507
全部0条评论

快来发表一下你的评论吧 !
