

hash算法在FPGA中的实现(2)
描述
在前面的文章中:hash算法在FPGA中的实现(一)——hash表的组建,记录了关于hash表的构建,这里记录另外一个话题,就是hash链表。我们知道,只要有hash的地方,就一定有冲突,关键就看如何解决冲突了。这里介绍两种常见的设计hash链表的方案。当然,解决hash冲突也不一定就要用链表的方法,还有其他方案。
hash链表说明
首先说下什么hash链表?还是借用上一篇文章中的图片来说明这个问题,如下图所示。hash链表是为了解决hash冲突而建立的一种数据结构。当某个key计算出hash值后,对应的hash桶中已经有了数据,出现了冲突,那这个时候就需要用一个链表来将具体相同hash值的key“链”起来,方便后续的查询。
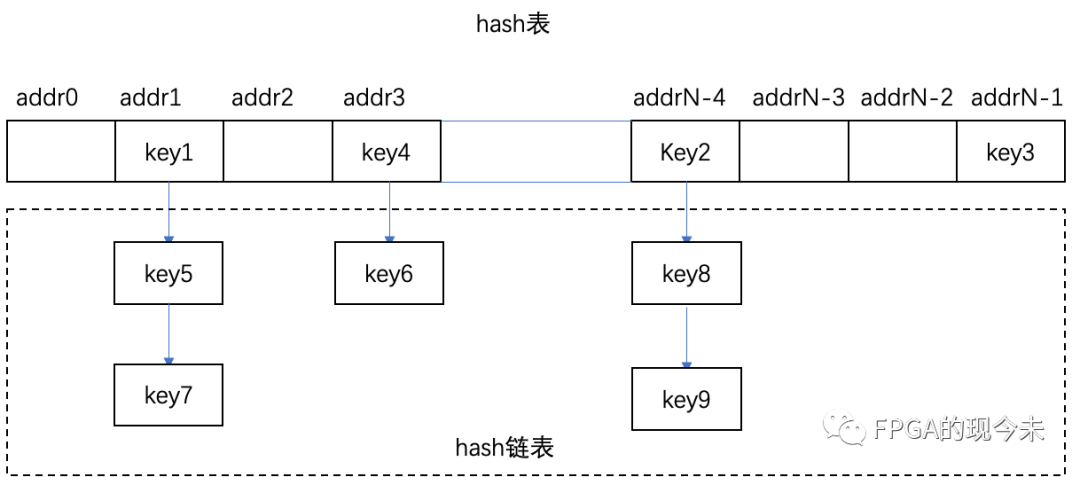
图中关于hash链表的示意,只是一种简单的表示,在FPGA的实际设计中,情况往往要复杂得多。
方案1——DDR
有的时候,我们并不知道链表到底会有多长,那么自然地会想到用DDR来存放链表。如何在DDR里组织数据结构呢?一般来讲,hash链表的数据结构如下:

hash桶中除了上文所讲的数据结构外,还有一个下一链的地址addr1,它指向链表的一个节点,该链表节点的数据结构和hash桶类似,也包括key值和地址,如图中key A和addr2,对于由addr2指向的最后一链,只有key B和最后一链标记NULL。
这样的数据结构,在DDR中存放的时候,显然是不高效的。因为每处理一次hash,有多少个链表节点就要读多少次DDR。我们知道DDR的性能有2个指标,一个是Gbps,一个是Mpps。处理一次hash时读DDR的次数越多,处理的hash次数就会越少,性能就越低,所以我们优化链表的数据结构,降低对DDR的读取次数。
优化的思路和hash桶的数据结构类似,如下图所示:

在一个节点中,不再只存放一个key,上图示例是存放了5个key。实际一次DDR的读写,可能最少是128byte或者256byte,以104bit的五元组为key来计算,可以存放9个key。一次可以读取N个key,相比以前的链表方案,读DDR的次数为原来的N分之一,性能提升N倍。
将这个话题继续引申下,如果hash桶存放在DDR中,那又如何构建hash表呢?如果真的需要把hash桶存放在DDR中,hash表的构建和hash链表的构建就是完全一模一样的了。
方案二——内部RAM
如果考虑所有的冲突次数在一定范围之内,那么可以把所有的链表存放在一起,即存放在一个内部的RAM中,实现对所有hash桶的链表管理。如下图所示:

以4个hash桶为例子说明链表的管理,key1的hash值为0,落入到hash桶0,因此时hash桶中的指针指向地址0,即addr0,addr0为空,即可以写入key1在地址0中。同样key2的hash值也为0,由于addr0中已经有数据,此时addr1为空,因此将key2写入addr1中,同时把addr1写入key1中的下一链,完成链表的构建。
其他的key值大家可以自行推敲演练。采用这样的方案,所有的链表都存放在一个ram中,处理冲突的次数是有限的,相比DDR的方案,还是简单一些。
总结
关于上述2种方案,这里做一个简单的总结。
| DDR链表 | 内部RAM链表 | |
|---|---|---|
| 应用场景 | 万能场景,使用无限制 | |
| 冲突次数 | 无限制,只要ddr有足够空间 | 对总体冲突次数(RAM的深度)有限制,超过后hash表无法写入,或者需要定期老化 |
| 实现难易程度 | 相对复杂,涉及到DDR的读改写操作 | 相对简单,但是也要实现对RAM的读改写操作, |
| 性能 | 低,需要串行读DDR,链表越长,性能越低 | 高,虽然相比DDR链表性能高,同样也是链表越长,性能越低。 |
不管采用哪种方案,高效地组建表项,减少对hash表和链表的访问次数是hash处理性能的关键。
-
基于FPGA的压缩算法加速实现2025-07-10 2821
-
hash算法在FPGA中的实现(1)2023-09-07 2380
-
从hash算法的原理和实际应用等几个角度,对hash算法进行一个讲解2020-06-03 4380
-
Hash算法简介2018-06-08 5948
-
基于SHA-1算法的硬件设计及实现(FPGA实现)2017-10-30 1239
-
hash表的实现原理2017-09-28 1430
-
在FPGA上实现CRC算法的程序2016-06-07 1182
-
FPGA中实现PID算法2014-12-03 29430
-
AES中SubBytes算法在FPGA的实现2010-11-09 915
-
MAC在FPGA中的高效实现2010-08-06 1165
-
CVSD算法分析及其在FPGA中的实现2010-04-01 3204
-
1HASH函数在软件自保护中的应用2009-08-07 636
-
FPGA实现的FIR算法在汽车动态称重仪表中的应用2006-03-11 1192
全部0条评论

快来发表一下你的评论吧 !
