

开学咯!跟着解小放一起来学习企业级AIGC应用如何落地
描述


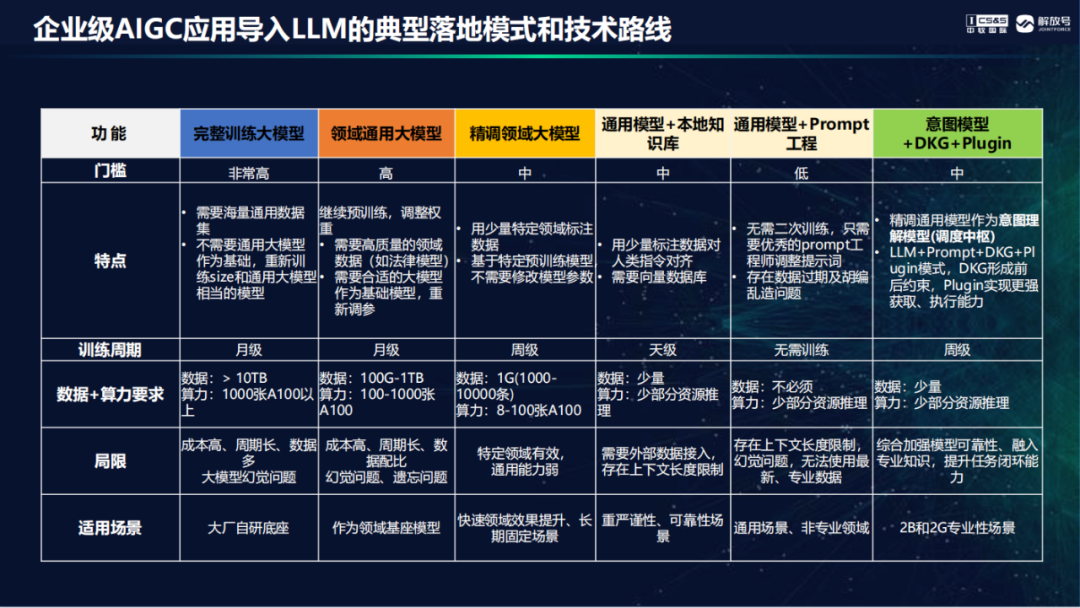
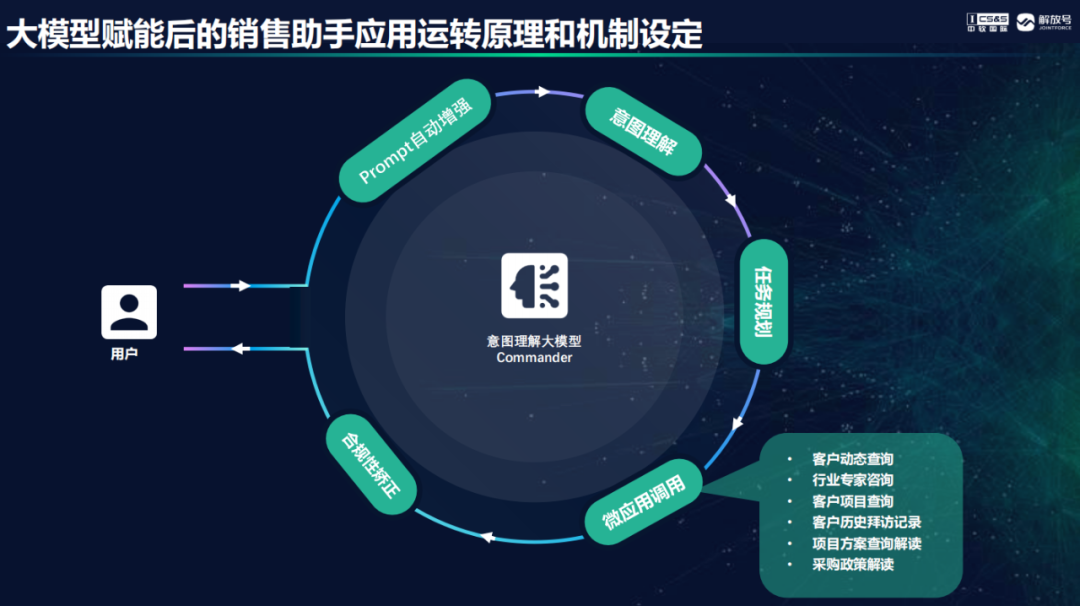
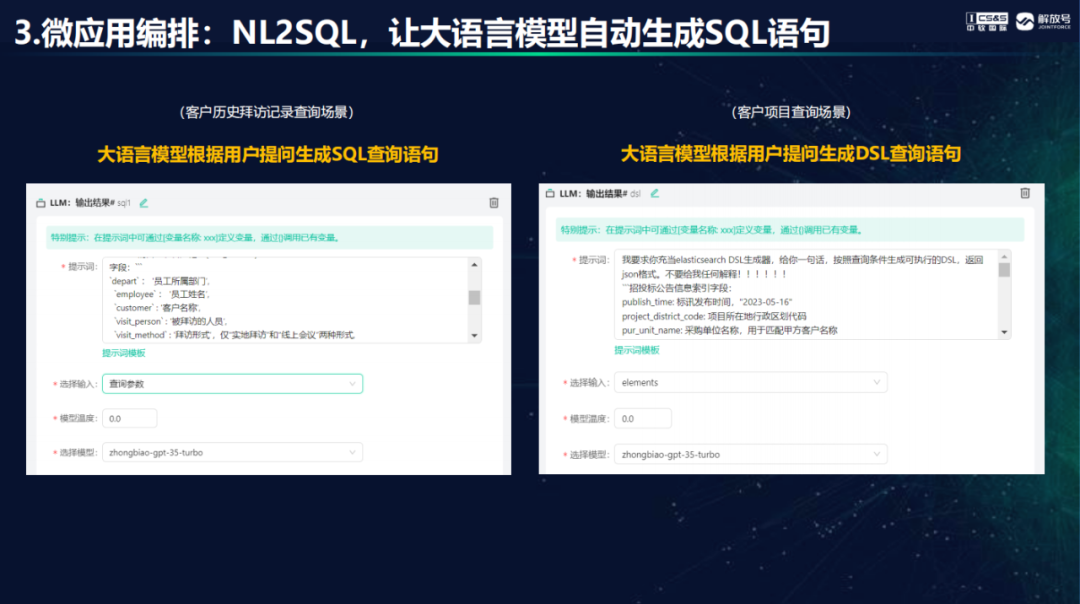
近日,星策开源社区 LLMOps meetup V3直播活动顺利举行,由星策开源和CSDN等多个平台同时播出,共吸引来14000+观众观看。中软国际AIGC研究院执行院长、解放号副总裁韩鹏受邀参加并分享当前业界最为关注的大模型在企业场景中实际落地的案例和实践,还演示了基于JointPilot平台构建AIGC企业应用的典型模式、方法、工具和关键技术,小编整理了一下,为广大开发者带来超实用的AIGC应用落地干货。


原文标题:开学咯!跟着解小放一起来学习企业级AIGC应用如何落地
文章出处:【微信公众号:中软国际】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 热点推荐
- 中软国际
-
100%开源!行业首个企业级智能体2025-07-26 1443
-
我们一起来实现氮化镓的可靠运行2022-11-03 614
-
【直播来袭】OneOS系统教程全面上线,邀您和ST、OneOS一起来学习啦!2022-04-22 1658
-
企业级的LInux系统日志管理2020-05-29 1759
-
大话企业级Android开发2019-07-11 2727
-
一起来学习吗2017-11-10 2176
-
一起来讨论吧2017-10-24 2351
-
一起来学习FPGA,欢迎爱好者加入QQ群1993625582012-02-27 4680
-
一起来学习FPGA,FPGA学习小组开始招收成员,欢迎爱好者加入2012-02-24 29083
-
SAS走进企业级存储应用2009-11-13 5038
-
一起来认识废旧电池的危害2009-11-02 1994
-
一起来认识深入了解水银2009-10-23 2986
全部0条评论

快来发表一下你的评论吧 !
