

ICCV 2023 | 重塑人体动作生成,融合扩散模型与检索策略的新范式ReMoDiffuse来了
描述
人体动作生成任务旨在生成逼真的人体动作序列,以满足娱乐、虚拟现实、机器人技术等领域的需求。传统的生成方法包括 3D 角色创建、关键帧动画和动作捕捉等步骤,其存在诸多限制,如耗时较长,需要专业技术知识,涉及昂贵的系统和软件,不同软硬件系统之间可能存在兼容性问题等。随着深度学习的发展,人们开始尝试使用生成模型来实现人体动作序列的自动生成,例如通过输入文本描述,要求模型生成与文本要求相匹配的动作序列。随着扩散模型被引入这个领域,生成动作与给定文本的一致性不断提高。
然而,生成动作的自然程度离使用需求仍有很大差距。为了进一步提升人体动作生成算法的能力,本文在 MotionDiffuse [1] 的基础上提出了 ReMoDiffuse 算法(图 1),通过利用检索策略,找到高相关性的参考样本,提供细粒度的参考特征,从而生成更高质量的动作序列。

-
论文链接:https://arxiv.org/pdf/2304.01116.pdf
-
GitHub:https://github.com/mingyuan-zhang/ReMoDiffuse
-
项目主页:https://mingyuan-zhang.github.io/projects/ReMoDiffuse.html
通过巧妙地将扩散模型和创新的检索策略融合,ReMoDiffuse 为文本指导的人体动作生成注入了新的生命力。经过精心构思的模型结构,ReMoDiffuse 不仅能够创造出丰富多样、真实度高的动作序列,还能有效地满足各种长度和多粒度的动作需求。实验证明,ReMoDiffuse 在动作生成领域的多个关键指标上表现出色,显著地超越了现有算法。
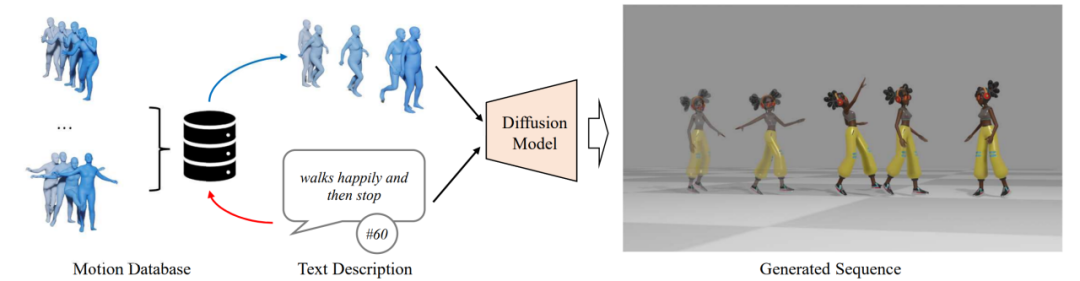
图 1. ReMoDiffuse 概览
方法介绍
ReMoDiffuse 主要由两个阶段组成:检索和扩散。在检索阶段,ReMoDiffuse 使用混合检索技术,基于用户输入文本以及预期动作序列长度,从外部的多模态数据库中检索出信息丰富的样本,为动作生成提供强有力的指导。在扩散阶段,ReMoDiffuse 利用检索阶段检索到的信息,通过高效的模型结构,生成与用户输入语义一致的运动序列。
为了确保高效的检索,ReMoDiffuse 为检索阶段精心设计了以下数据流(图 2):
共有三种数据参与检索过程,分别是用户输入文本、预期动作序列长度,以及一个外部的、包含多个 < 文本,动作 > 对的多模态数据库。在检索最相关的样本时,ReMoDiffuse 利用公式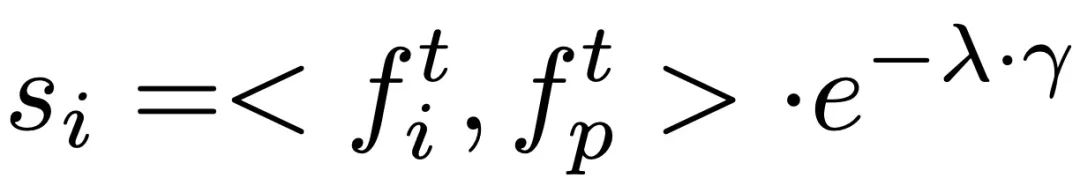 计算出每个数据库中的样本与用户输入的相似度。这里的第一项是利用预训练的 CLIP [2] 模型的文本编码器对用户输入文本和数据库实体的文本计算余弦相似度,第二项计算预期动作序列长度和数据库实体的动作序列长度之间的相对差异作为运动学相似度。计算相似度分数后,ReMoDiffuse 选择相似度排名前 k 的样本作为检索到的样本,并提取出文本特征
计算出每个数据库中的样本与用户输入的相似度。这里的第一项是利用预训练的 CLIP [2] 模型的文本编码器对用户输入文本和数据库实体的文本计算余弦相似度,第二项计算预期动作序列长度和数据库实体的动作序列长度之间的相对差异作为运动学相似度。计算相似度分数后,ReMoDiffuse 选择相似度排名前 k 的样本作为检索到的样本,并提取出文本特征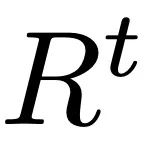 ,和动作特征
,和动作特征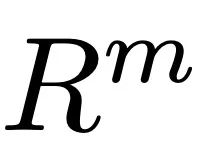 。这两者和从用户输入的文本中提取的特征
。这两者和从用户输入的文本中提取的特征 一同作为输入给扩散阶段的信号,指导动作生成。
一同作为输入给扩散阶段的信号,指导动作生成。
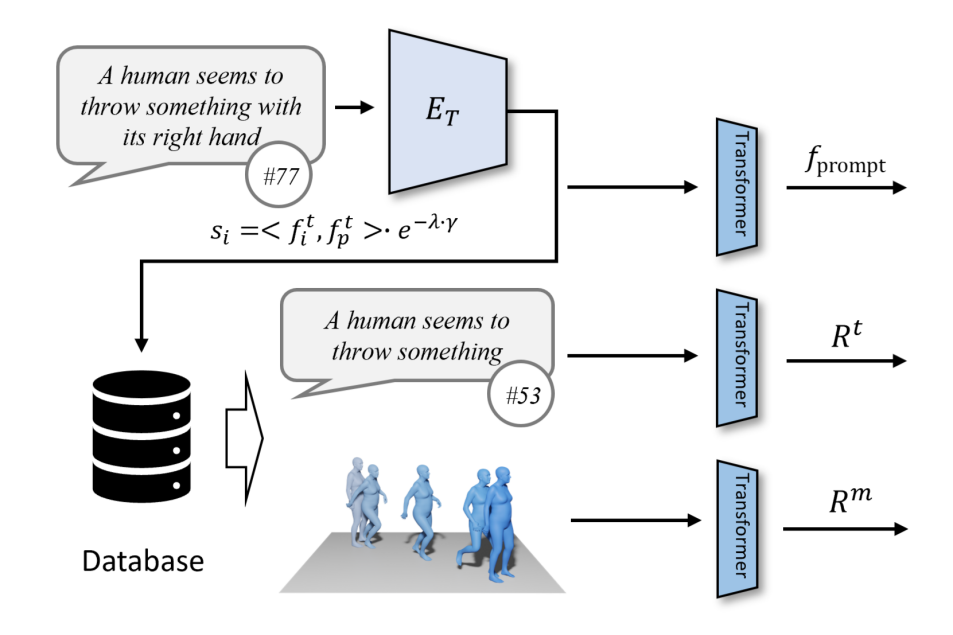
图 2:ReMoDiffuse 的检索阶段
扩散过程(图3.c)由正向过程和逆向过程两个部分组成。在正向过程中,ReMoDiffuse 逐步将高斯噪声添加到原始动作数据中,并最终将其转化为随机噪声。逆向过程专注于除去噪声并生成逼真的动作样本。从一个随机高斯噪声开始,ReMoDiffuse 在逆向过程中的每一步都使用语义调制模块(SMT)(图3.a)来估测真实分布,并根据条件信号来逐步去除噪声。这里 SMT 中的 SMA 模块将会将所有的条件信息融入到生成的序列特征中,是本文提出的核心模块。
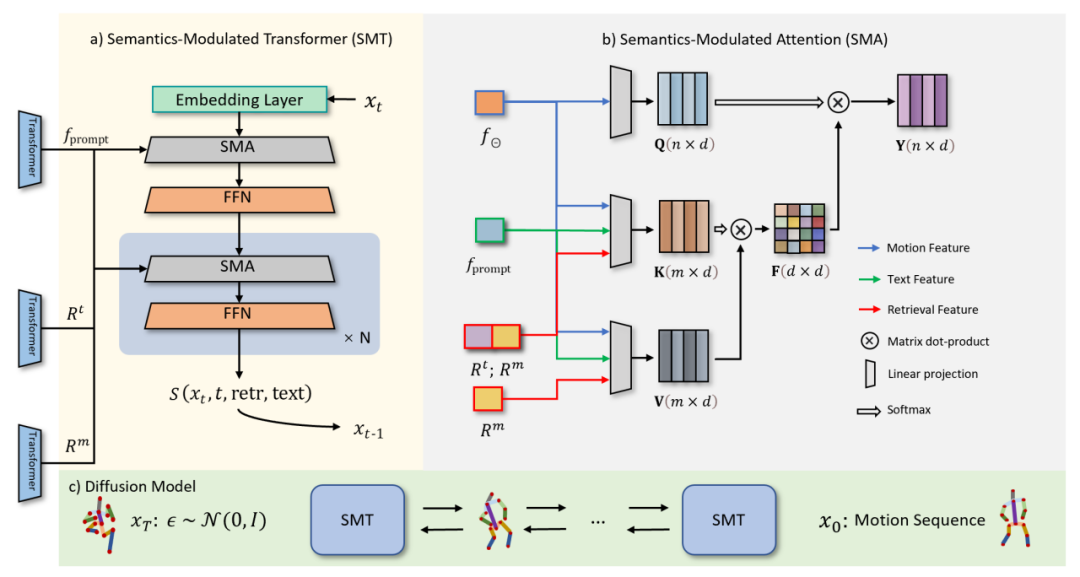
图 3:ReMoDiffuse 的扩散阶段
对于 SMA 层(图 3.b),我们使用了高效的注意力机制(Efficient Attention)[3] 来加速注意力模块的计算,并创造了一个更强调全局信息的全局特征图。该特征图为动作序列提供了更综合的语义线索,从而提升了模型的性能。SMA 层的核心目标是通过聚合条件信息来优化动作序列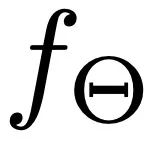 的生成。在这个框架下:
的生成。在这个框架下:
1.Q 向量具体地代表了我们期望基于条件信息生成的预期动作序列。
2.K 向量作为一种索引机制综合考虑了多个要素,包括当前动作序列特征、用户输入的语义特征,以及从检索样本中获取的特征和。其中,表示从检索样本中获取的动作序列特征,表示从检索样本中获取的文本描述特征。这种综合性的构建方式保证了 K 向量在索引过程中的有效性。
3.V 向量提供了动作生成所需的实际特征。类似 K 向量,这里 V 向量也综合考虑了检索样本、用户输入以及当前动作序列。考虑到检索样本的文本描述特征与生成的动作之间没有直接关联,因此在计算 V 向量时我们选择不使用这一特征,以避免不必要的信息干扰。
结合 Efficient Attention 的全局注意力模板机制,SMA 层利用来自检索样本的辅助信息、用户文本的语义信息以及待去噪序列的特征信息,建立起一系列综合性的全局模板,使得所有条件信息能够被待生成序列充分吸收。
实验及结果
我们在两个数据集 HumanML3D [4] 和 KIT-ML [5] 上评估了 ReMoDiffuse。在与文本的一致性与动作质量两个角度上,实验结果(表 1、2)展示了我们提出的 ReMoDiffuse 框架的强大性能和优势。
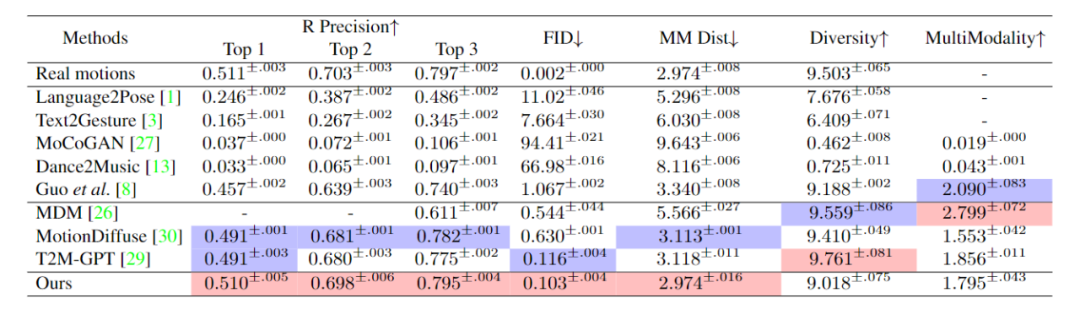
表 1. 不同方法在 HumanML3D 测试集上的表现
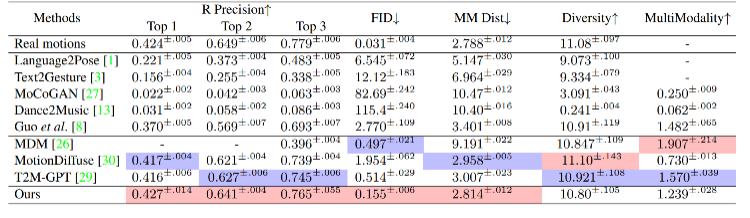
表 2. 不同方法在 KIT-ML 测试集上的表现
以下是一些能定性展示 ReMoDiffuse 的强大性能的示例(图 4)。与之前的方法相比,例如,在给定文本 “一个人在圆圈里跳跃” 时,只有 ReMoDiffuse 能够准确捕捉到 “跳跃” 动作和 “圆圈” 路径。这表明 ReMoDiffuse 能够有效地捕捉文本细节,并将内容与给定的运动持续时间对齐。

图 4. ReMoDiffuse 生成的动作序列与其他方法生成的动作序列的比较
我们对 Guo 等人的方法 [4]、MotionDiffuse [1]、MDM [6] 以及 ReMoDiffuse 所生成的相应动作序列进行了可视化展示,并以问卷形式收集测试参与者的意见。结果的分布情况如图 5 所示。从结果中可以清晰地看出,在大多数情况下,参与测试者认为我们的方法 —— 即 ReMoDiffuse 所生成的动作序列在四个算法中最贴合所给的文本描述,也最自然流畅。
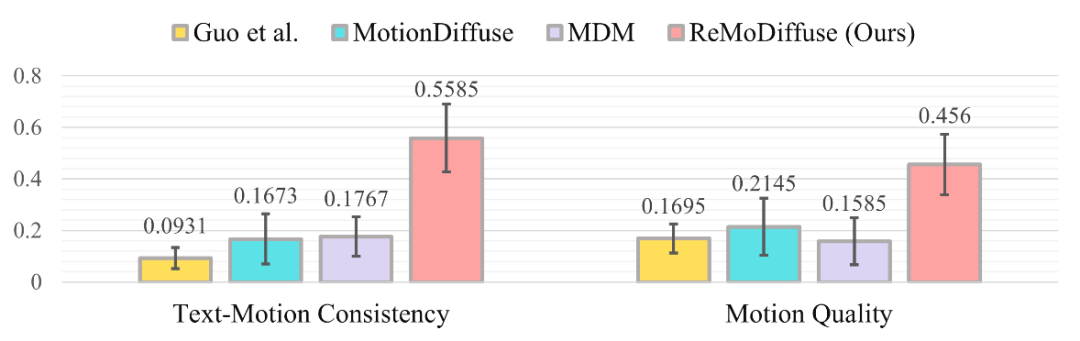
图 5:用户调研的结果分布
引用
[1] Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xinying Guo, Lei Yang, and Ziwei Liu. Motiondiffuse: Text-driven human motion generation with diffusion model. arXiv preprint arXiv:2208.15001, 2022.
[2] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020, 2021.
[3] Zhuoran Shen, Mingyuan Zhang, Haiyu Zhao, Shuai Yi, and Hongsheng Li. Efficient attention: Attention with linear complexities. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 3531–3539, 2021.
[4] Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5152–5161, 2022.
[5] Matthias Plappert, Christian Mandery, and Tamim Asfour. The kit motion-language dataset. Big data, 4 (4):236–252, 2016.
[6] Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H Bermano. Human motion diffusion model. In The Eleventh International Conference on Learning Representations, 2022.
原文标题:ICCV 2023 | 重塑人体动作生成,融合扩散模型与检索策略的新范式ReMoDiffuse来了
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
- 相关推荐
- 热点推荐
- 物联网
-
Vgg16模型无法使用模型优化器重塑怎么解决?2025-03-06 395
-
如何将一个FA模型开发的声明式范式应用切换到Stage模型2025-06-04 351
-
基于图元方向变形的人体模型生成新算法2017-11-17 816
-
基于耦合多隐马尔可夫模型人体动作识别2018-03-29 1199
-
如何使用改进的深度神经网络实现人体动作识别模型2019-12-19 1555
-
扩散模型在视频领域表现如何?2022-04-13 2667
-
基于扩散模型的图像生成过程2023-07-17 4587
-
如何加速生成2 PyTorch扩散模型2023-09-04 2186
-
ICCV 2023生成式AI引人瞩目,商汤多项技术突破展现中国“创新力”2023-10-04 1791
-
如何在PyTorch中使用扩散模型生成图像2023-11-22 1381
-
谷歌推出能一次生成完整视频的扩散模型2024-01-29 1259
-
谷歌推出AI扩散模型Lumiere2024-02-04 1946
-
浙大、微信提出精确反演采样器新范式,彻底解决扩散模型反演问题2024-11-27 1547
-
Diffusion生成式动作引擎技术解析2025-03-17 3333
-
航空设计大模型智能系统:重塑未来飞行器研发范式2026-05-01 403
全部0条评论

快来发表一下你的评论吧 !
