

怎样使用SpinalHDL Pipeline组件里的resulting及overloaded?
描述
今天来看下SpinalHDL Pipeline组件里的resulting及overloaded的使用
》resulting
在Stage中的数据结构中,有四种类型:
val stageableToData = mutable.LinkedHashMap[StageableKey, Data]() val stageableOverloadedToData = mutable.LinkedHashMap[StageableKey, Data]() val stageableResultingToData = mutable.LinkedHashMap[StageableKey, Data]() val stageableTerminal = mutable.LinkedHashSet[StageableKey]()
关于stageableToData,在之前的文章中已有介绍,今天来看下stageableOverloadedToData以及stageableResultingToData的作用。在提供的API中,相关的注册函数有:
stageableOverloadedToData注册:
def overloaded(key : StageableKey) : Data = {
internals.stageableOverloadedToData.getOrElseUpdate(key, ContextSwapper.outsideCondScope{
key.stageable()//.setCompositeName(this, s"${key}_overloaded")
})
}
stageableResultingToData注册:
def resulting(key : StageableKey) : Data = {
internals.stageableResultingToData.getOrElseUpdate(key, ContextSwapper.outsideCondScope{
key.stageable()//.setCompositeName(this, s"${key}_overloaded")
})
}
def resulting[T <: Data](key : Stageable[T]) : T = {
resulting(StageableKey(key.asInstanceOf[Stageable[Data]], null)).asInstanceOf[T]
}
def resulting[T <: Data](key : Stageable[T], key2 : Any) : T = {
resulting(StageableKey(key.asInstanceOf[Stageable[Data]], key2)).asInstanceOf[T]
}
字如其名,resulting可以理解为获取Stageable的最终结果,而overload则是对数据的重载。不妨先来看看在pipeline中这两种类型所起的作用:
在pipeline的build函数里,对于stageableResultingToData,其首先的处理方式代码如下:
for(s <- stagesSet){
for(key <- s.internals.stageableResultingToData.keys){
s.apply(key)
}
}
这里对于每个stage中stageableResultingToData里所注册的每种类型StageableKey,其都会调用Stage的apply函数将其注册到StageableToData中,也就意味着如果前级也有该对应的StageableKey,那么在连接阶段两者是可以建立连接关系的。
随后,在internal conntection阶段,对于stageableResultingToData中的变量,采用的赋值逻辑为:
for((key, value) <- s.internals.stageableResultingToData){
value := s.internals.outputOf(key)
}
而outputOf的赋值逻辑为:
def outputOf(key : StageableKey) = stageableOverloadedToData.get(key) match {
case Some(x) => x
case None => stageableToData(key)
}
可以看出,这里的处理方式为,如果该变量在stageableOverloadedToData中存在,那么会将stageableOverloadedToData中的值赋值驱动stageableResultingToData中对应的变量,否则将会从stageableToData中寻找对应的变量进行驱动(上一步已经将对应的StageableKey注册进stageableToData中)。
》Show Me The Code
分析完了源代码,上一个简单的example:
case class Test3() extends Component{
val io=new Bundle{
val data_in=slave(Flow(Vec(UInt(8 bits),4)))
val data_out=master(Flow(UInt(8 bits)))
}
noIoPrefix()
val A,B=Stageable(UInt(8 bits))
val pip=new Pipeline{
val stage0=new Stage{
this.internals.input.valid:=io.data_in.valid
A:=io.data_in.payload(0)+io.data_in.payload(1)
B:=io.data_in.payload(2)+io.data_in.payload(3)
}
val stage1=new Stage(Connection.M2S()){
io.data_out.payload:=resulting(A)+resulting(B)
io.data_out.valid:=this.internals.output.valid
}
}
pip.build()
}
在这个例子里,在stage1中仅用到了resulting语句。按前面所述,stage1中最终stageableResultingToData中会包含两个变量,build阶段也会向其stageableToData阶段注册两个变量A、B:
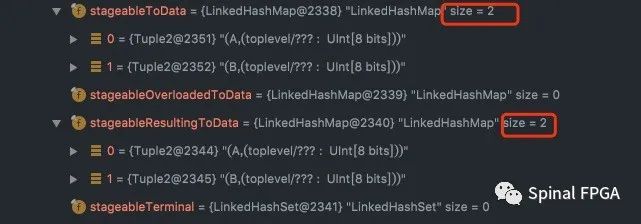
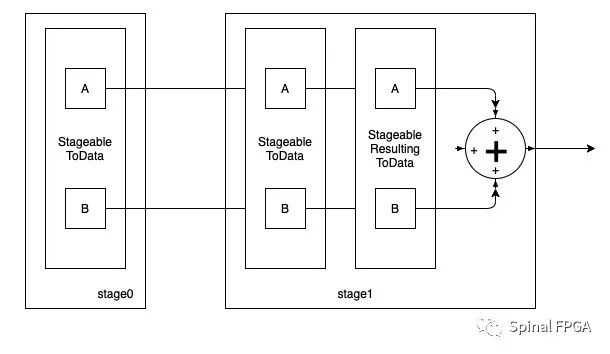
在这里,由于stage0中也包含A、B,故这里最终的驱动关系为:
再来看一个resulting和overlaoded共用的代码:
case class Test4() extends Component{
val io=new Bundle{
val data_in=slave(Flow(Vec(UInt(8 bits),4)))
val data_out=master(Flow(UInt(8 bits)))
}
noIoPrefix()
val A,B=Stageable(UInt(8 bits))
val pip=new Pipeline{
val stage0=new Stage{
this.internals.input.valid:=io.data_in.valid
A:=io.data_in.payload(0)+io.data_in.payload(1)
B:=io.data_in.payload(2)+io.data_in.payload(3)
}
val stage1=new Stage(Connection.M2S()){
io.data_out.payload:=resulting(A)+B
io.data_out.valid:=this.internals.output.valid
overloaded(A):=A+1
}
}
pip.build()
}
这里在stage1中对A调用了overloaded重载,结合上面的赋值顺序,最终的驱动关系为:
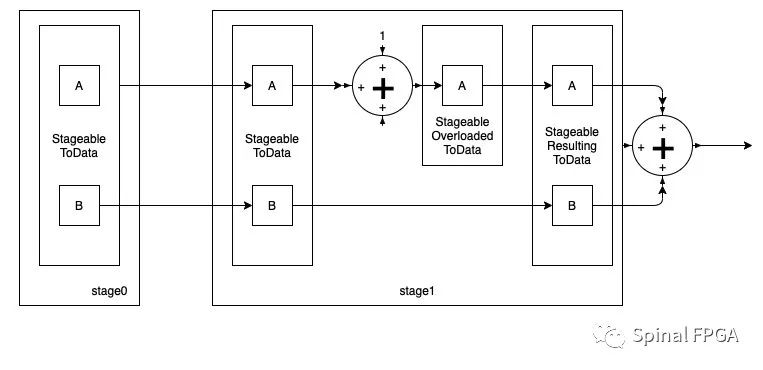
看到这里,可能会有一个疑问:为什么不能直接写成A:=A+1的形式呢?主要在于A本身处于StageableToData,在进行Stage之间的连接时已经对齐进行赋值驱动,这里如果直接写成A:=A+1相当于对电路进行重复驱动,从而导致报错。
》总结
resulting&overloaded主要用于在某个Stage阶段对电路在结合上一Stage基础上需做一些额外判断对该阶段的相应电路做新的赋值驱动时进行处理。如在NaxRsicV中Cache里的一些电路处理:
overloaded(BANK_BUSY)(bankId) := BANK_BUSY(bankId) || bank.write.valid && REDO_ON_DATA_HAZARD
在流水线的某一阶段在保持Stageable语义而不必新增Stageable情况下通过overlaoded、resulting来进行Stage内的电路对象驱动。
审核编辑:刘清
-
浅析SpinalHDL中Pipeline中的复位定制2024-03-17 2075
-
在SpinalHDL里在顶层一键优化Stream/Flow代码生成2023-12-14 1872
-
SpinalHDL里pipeline的设计思路2023-08-12 2415
-
SpinalHDL里如何实现Sobel边缘检测2022-08-26 2235
-
SpinalHDL运行VCS+Vivado相关仿真2022-08-10 4093
-
如何在SpinalHDL里启动一个仿真2022-07-26 4094
-
SpinalHDL是如何让仿真跑起来的2022-07-25 2694
-
分享一个在SpinalHDL里apply的有趣用法2022-07-19 2305
-
SpinalHDL里用于跨时钟域处理的一些手段方法2022-07-11 3397
-
在SpinalHDL中关于casez的使用2022-07-06 4687
-
谈谈SpinalHDL中StreamCCByToggle组件设计不足的地方2022-06-30 5910
-
在SpinalHDL里switch方法有何用处呢2022-06-22 1545
-
SpinalHDL里时钟域中的定制与命名2021-03-22 2947
全部0条评论

快来发表一下你的评论吧 !
