

基于多模态学习的虚假新闻检测研究
描述
社交媒体在给人们带来便利的同时,也成为虚假新闻恣意传播的渠道,如果不及时发现遏止,极易引发群众恐慌,激起社会动荡。因此,探索准确高效的虚假新闻检测技术具有极高的理论价值和现实意义。
本文对虚假新闻相关检测技术做了全面综述。首先,对多模态虚假新闻的相关概念进行了整理和归纳,并分析了单模态和多模态新闻数据集的变化趋势。其次,介绍了基于机器学习和深度学习的单模态虚假新闻检测技术,这些技术在虚假新闻检测领域已被广泛应用,而由于虚假新闻通常包含多种数据表现形式,这些传统的单模态技术无法充分挖掘虚假新闻的深层逻辑,因此无法有效地应对多模态虚假新闻数据带来的挑战。针对此问题,对近些年来先进的多模态虚假新闻检测技术进行了整理,从多流架构和图架构的角度归纳和论述了这些多模态检测的技术方法,探讨了这些技术的思想理念与潜在缺陷。最后,分析了目前虚假新闻检测研究领域存在的困难和瓶颈,并由此给出未来的研究方向。
http://fcst.ceaj.org/CN/abstract/abstract3314.shtml
概述
社交平台的信息传播具有低成本、高效率、实时便捷等特点,这些便利为新闻在社区广泛传播提供了可能,然而,信息发布和扩散的同时也导致了社交网络上虚假新闻的恣意横行。据 2019年 CHEQ 和巴尔的摩大学的经济研究报道[1],全球每年因虚假新闻造成的损失高达 780 亿美元。2020 年 7 月,江苏南京一小区发生外卖被盗事件,据警方了解,该偷盗居民涉嫌多次盗窃,目前已被刑拘。事发后三天内,众多网络媒体发布新闻,称当事人为考研大学生,报道中还出现了“为供其深造,家中其他 3个兄弟姐妹辍学”等说法。7 月 20 日下午,警方发布通报:嫌疑人李某某大学毕业已两年,目前有固定收入,其偷外卖的原因,是一次外卖被人拿走后,产生了报复心理。目前,嫌疑人李某某已被取保候审。李某某父母和大姐在老家务农,二姐、三姐分别在北京、海南工作。换言之,“考研大学生”这一身份是虚假信息,李某某的家庭并不贫困,偷外卖也并非为了维持生活,如图1(a)、图 1(b)所示。不良媒体通过散播这些假新闻激起群众的同情,以此获取流量、关注,直到官方辟谣,这些虚假新闻才得以遏止。由此可见,虚假新闻已经成为大量不良媒体获取非法利益的工具,它们的存在会加强人们之间的不信任关系,造成不良的社会影响。因此,探索准确高效的虚假新闻检测方法尤为重要。对于虚假新闻,新闻文字源于图片的恶意编造,其描述的内容必然与图像真实内容存在冲突,即模态之间存在语义不一致性,如果单从图片或者文字角度分析,这种语义不一致性很难被模型识别,容易导致模型分类错误,因此,从多模态的角度探索虚假新闻检测技术很有必要。
纵观这些年关于虚假新闻检测的综述文章,很少有从多模态角度来分析的。早期研究者们致力于寻找和构建人工特征来表示新闻内容,这时的综述内容大多是关于这些特征的归纳整理[2-3],后来,随着深度学习技术的发展,学者们将研究重心放在了这种自动化特征提取技术上,其中涌现了大批基于深度学习的虚假新闻检测文章,近些年来,一部分学者对这些方法进行了总结[4- 5]。然而,这些文章的研究角度存在局限,并没有考虑到虚假新闻中的其他模态。有研究发现[6- 7],新闻的视觉内容是能误导读者的关键因素。此外,新闻社交图中蕴含的虚假新闻传播信息是检测取得成功的重要因素[8],因此从多模态的视角分析新闻很有必要。针对此,本文详尽地梳理了以往虚假新闻检测领域的一些工作,从单模态到多模态的角度对该领域做全面的整理和综述。本文的贡献如下:
(1)详尽地从单模态到多模态角度对虚假新闻检测领域相关技术做了归纳和整理;(2)将基于新闻社交图的检测技术作为一种特殊的多模态处理方法,并对其最新技术的研究现状做了补充和完善;(3)梳理了现有虚假新闻检测技术存在的研究瓶颈,并给出了未来研究方向。
多模态虚假新闻检测技术
不同形式的信息源可以看成不同的模态[51],新闻是典型的多模态数据,书面报道的新闻通常包含图片和文本两种模态信息,短视频新闻至少包含图像、音频和字幕等多模态信息,新闻社交图中包含新闻内容以及新闻行为等多种模态信息。多模态虚假新闻检测技术的关键是如何构建模型框架学习新闻数据的多模态信息,以提升虚假新闻检测性能。总结至今提出的一些文章,大致可以划分为两类:基于流形式的多模态虚假新闻检测技术和基于图形式的多模态虚假新闻检测技术。
基于流形式的虚假新闻检测技术
基于单流架构的技术
单流架构指在模型输入之前,不同模态数据的初级特征会通过拼接、函数映射等方式进行数据融合,得到的多模态特征内部中各个模态的信息是独立的,而多模态信息需要在后续模型中学习。最具代表性的是基于 Transformer 架构的多模态模型,如ViLT(vision-and-language transformer)[52]、MBT(multimodal bottleneck transformer)[53]等,各模态的数据会预处理为序列化数据,例如,文本会转化为多个 token组成的序列,图片会转化为多个不重叠的图片 patch序列,音频数据会先转化为频谱图,最终组成多个不重叠的频谱图 patch 序列,多个模态的特征最终会进行拼接,构成模型的多模态输入特征,单流架构框架如图 2所示。
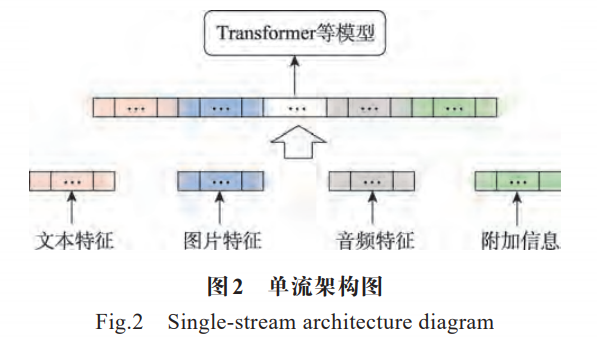
目前,单流架构模型在视频分类、情感分析、图像生成等多模态领域中得以广泛应用,单流模型具有结构简单、容易实现、高准确率等优势,在虚假新闻检测领域中,是一个极具潜力的研究方向。但参考目前的一些研究,其也存在一些缺陷:(1)在网络训练时需要花费更多的迭代次数才能获得好的多模态表示;(2)由于模型的输入特征通常是多个模态特征拼接而成,模型有较高的计算复杂度;(3)单流模型的学习需要大量的训练数据集,而在虚假新闻检测领域中,目前没有足够多可以训练的数据。
基于多流架构的技术
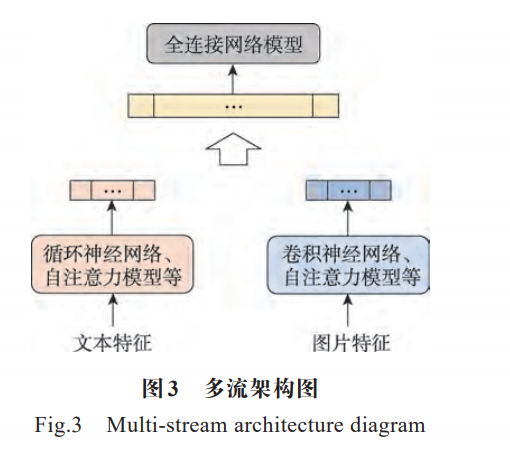
近些年来,关于多模态虚假新闻检测领域,研究者们更常用的是基于多流架构的技术。多流架构是指根据不同模态数据设计不同模型提取模态高级特征,从各个模态高级特征中学习多模态特征并输入下游的分类器中预测各个类别的概率。相比单流架构,多流架构更加灵活,其可以针对不同模态数据单独设计模型提取模态特征。多流框架如图 3所示。

基于图形式的虚假新闻检测方法
社会性是新闻的基本特性之一,新闻数据可以表示为新闻和新闻受众互动的社交网络图,新闻社交网络图包含了新闻文章、评论等纯文本数据,也包含了节点、连边等关系型数据,这些不同形式数据组成的图可以看作特殊的多模态数据。本节主要综述基于新闻社交图的虚假新闻检测技术,其大致可以包含两类:基于图机器学习的技术和基于图神经网络的技术。
基于图机器学习的技术虚假信息的传播主要包含三种因素[71]:一是新闻内容的合理性;二是传播者的个性以及可信度;三是传播网络的同质性。基于以上因素,研究者根据新闻内容和社交信息建立了不同的新闻社交图,如新闻传播树、新闻立场网络等,以探究虚假新闻的传播模式。传播树代表了在社交媒体上新闻文章的发帖和转发之间的关系。Wu等人[72]将消息传播模式描述为树结构的关系,传播树不仅能反映转发者与作者之间的关系,还能反映转发者的即时行为和情感。其次,Ma 等人[13]分别构建了真新闻和假新闻的消息传播树,利用真新闻和假新闻存在的不同传播模式,计算两棵传播树之间的子结构的相似性,实验证明该方法可以有效帮助检测假新闻。
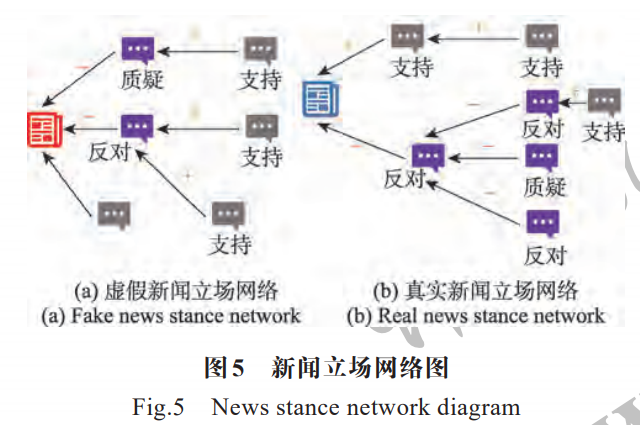
立场网络的节点表示新闻和帖子,边表示帖子与帖子之间的支持和反对关系。利用立场网络进行虚假新闻检测,即检测与某新闻相关帖子的可信度,可信度越低,代表该新闻是假新闻的可能性越大。在新闻的传播中,有学者发现[73],可以通过用户分享的观点、猜测和证据来自我纠正一些不正确的信息。如图 5 所示,图 5(a)表示虚假新闻的立场网络,图 5(b)表示真实新闻的立场网络。此外,有学者对假新闻传播树和立场网络进行综合分析。Davoudi等人[74]提出了一种包含动态分析、静态分析和结构分析三个结构的检测框架。其分别使用循环神经网络、全连接神经网络和 Node2Vec 学习传播树和立场网络随时间的演化模式、检测结束时传播树和立场网络的整体特征以及传播树和立场网络的结构特征,最终汇总三个结构的输出完成虚假新闻的检测。
基于图神经网络的技术
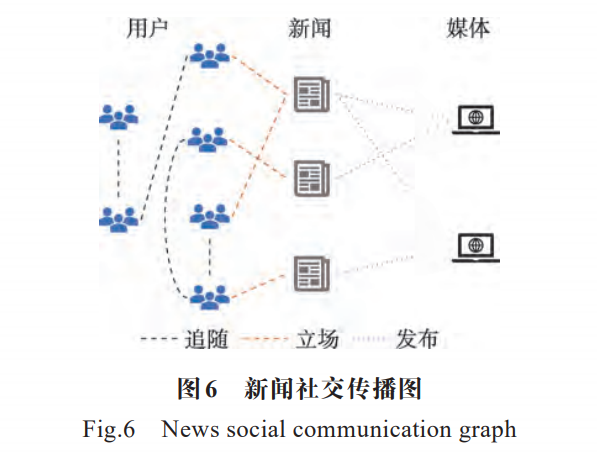
近年来,研究者们借鉴了卷积网络、循环网络和深度自编码器的思想,设计了可以用于处理图数据的神经网络结构——“图神经网络”[76]。该技术在处理图关系数据时有独特的优势,而虚假新闻的散布和传播是以图形式实现的,图中节点表示与新闻相关的实体信息,而连边表示不同实体之间的联系。新闻社交传播图如图6所示。
图卷积网络(graph convolutional network,GCN)是借用卷积网络的思想处理图数据而提出的一种图神经网络模型,其核心思想是学习一个映射函数,对于图中的一个节点,聚合该节点的特征和邻居节点的特征来生成该节点的新表示。Chandra等人[78]提出的 SAFER(socially aware fake news detection framework)模型使用 GCN 来获取具有用户信息的新闻表示,然而他们构建的是同质图网络,会导致信息丢失问题。在此基础上,Wang等人[79]以新闻文本、图片和知识概念为节点构建异质图,一定程度上缓解了该问题。此外,Bian等人[80]从新闻的传播深度和散布广度两个角度研究虚假新闻的扩散模式,如图 7 所示,他们提出了双向图卷积神经网络,从自上而下和自下而上两个方向分别获取虚假新闻传播和散布的模式,最终的实验结果证明该方法的有效性。
总的来说,基于图形式的虚假新闻检测方法具有准确率高、灵活性强等优点,可以识别影响虚假信息传播的重要节点,为模型提供了一定的可解释能力。但也存在一些问题,如新闻社交图需要事先人为构建,当与新闻相关的实体数量太多时,需要花费大量时间,有时还可能错漏关键实体信息;其次,图的训练需要花费大量时间,对硬件的需要较大;此外,涉及时间因素的图检测技术仍然发展不完善。
结论
在互联网时代下,如何在海量的新闻中准确高效地识别虚假信息成为了国际关心的热点话题。经过多年的研究探索,虚假新闻检测技术已经从早期的人工检测发展成如今的自动化检测,基于机器学习的人工特征提取转变为如今的深度学习自动特征提取,对新闻单一对象的检测方法演变为用户特征、文本、图片、视频特征以及传播特征等多模态联合的检测方法。
本文对虚假新闻检测研究相关理论进行了整理,从单模态到多模态角度对虚假新闻检测数据集与相关技术做了全面的综述,并对现有研究中存在的缺陷做了归纳整理,最后给出该领域存在的问题以及以后的研究方向。本文不仅对后来的学者们有借鉴作用,而且还对专业媒体平台应对虚假新闻冲击提供重要的实际应用价值。
-
网络虚假新闻的生成形态2009-10-26 911
-
Bloomsbury AI团队加入Facebook团队,共同构建新的自然语言杜绝假新闻2018-07-09 641
-
多文化场景下的多模态情感识别2017-12-18 1313
-
Facebook扩大内容核查范围,机器学习+全方位审核打击假新闻2018-06-27 2921
-
如何才能将AI技术应用到虚假新闻的打击中去?2018-10-08 2184
-
AI如何检测这类虚假新闻2019-04-28 3346
-
如何采用区块链技术打击虚假新闻2019-05-29 1749
-
Twitter收购Fabula AI 用于检测虚假信息传播2019-07-01 896
-
滑铁卢大学研究人员开发出一种新的人工智能工具 可鉴别并清除虚假新闻2019-12-17 3963
-
AI全新应用场景 技术趋势多模态学习2020-07-18 2531
-
Transformer模型的多模态学习应用2021-03-25 12261
-
简述文本与图像领域的多模态学习有关问题2021-08-26 7997
-
更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」2023-07-16 1774
-
DreamLLM:多功能多模态大型语言模型,你的DreamLLM~2023-09-25 1975
-
虚假新闻网站利用AI批量炮制假新闻,数量猛增惊人2023-12-20 1829
全部0条评论

快来发表一下你的评论吧 !
