

开源大模型FLM-101B:训练成本最低的超100B参数大模型
描述
大语言模型(LLM)在诸多领域都取得了瞩目的成就,然而,也存在两个主要的挑战:
- 训练成本极高,通常只有少数几家大公司才能负担得起。
- 现行的评估基准主要依赖知识评估(如MMLU和C-Eval)以及NLP任务评估,但这种方式存在局限性,并且容易受到数据污染的影响。
近期,一支来自中国的研究团队正是针对这些问题提出了解决方案,他们推出了FLM-101B模型及其配套的训练策略。FLM-101B不仅大幅降低了训练成本,而且其性能表现仍然非常出色,它是目前训练成本最低的100B+ LLM。
下面我们就来深入探讨他们是如何实现这一目标的吧!

Paper: FLM-101B: An Open LLM and How to Train It with $100K Budgets
Link: https://arxiv.org/pdf/2309.03852.pdf
Model: https://huggingface.co/CofeAI/FLM-101B进NLP群—>加入NLP交流群
摘要
本篇研究的两大核心亮点为:
- 增长策略:该策略赋予了LLM一个独特的训练方式,它可以从较小规模动态增长到较大规模,而不仅仅是在一开始就确定其大小。这不仅能够保持在初期阶段已学到的知识,更重要的是,它大大降低了整体的计算成本。
- IQ评估基准:该团队还提出了一个新的评估标准IQ benchmark,包含了符号映射、规则理解、模式挖掘和抗干扰能力这四个关键维度,从多方面对LLM的能力进行了全面深入的评估。
增长策略详解
与独立训练不同规模的模型的常规做法不同,在FLM-101B的训练过程中该项目团队按照16B、51B和101B参数的顺序连续训练了三个模型,每个模型都从其较小的前身那里继承了知识。
下图揭示了利用增长策略在三种典型场景中实施LLM训练的计算成本变化。在这里,我们依据一个基本原则:LLM的FLOPs与参数数量近似成正比,使我们可以通过观察模型参数变化曲线下的面积来估算训练的计算成本。
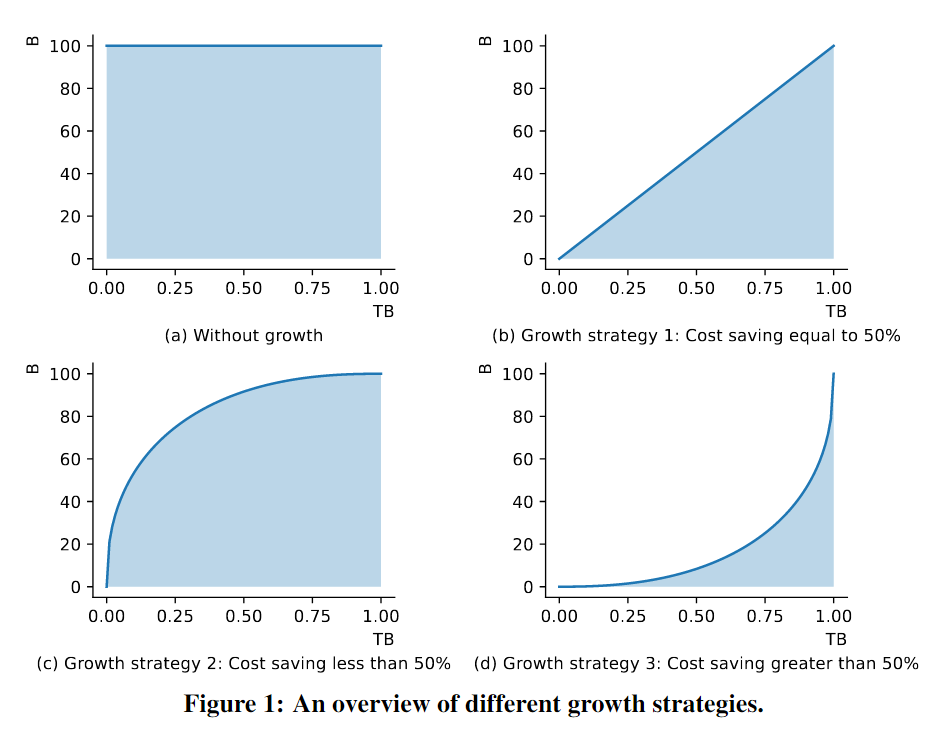
- 图(a) 一个标准的训练策略,其中没有实施模型的动态增长,从而导致训练计算成本相对较高。
- 图(b) 一个线性增长策略的应用,其结果是计算成本得以减少近50%。
- 图(c) 一个适度的增长策略,虽然它未能将成本降低到50%,但仍然实现了可观的成本节约。
- 图(d) 一种更为积极的增长策略,它成功地将计算成本降低了超过50%,揭示了这种策略在减少训练成本方面的巨大潜力。
在LLM增长前后,模型始终给出任意输入的一致输出。这个属性对于知识继承和训练稳定性都是有利的。为了适应多节点3D并行框架,团队通过离线扩展模型结构,并在下一个阶段开始时重新加载检查点来实现这一点。
增长策略具体设置
规划模型增长是一个需要权衡不同大小模型固有优缺点的过程:较小的模型在计算每个训练步骤时更快,能够更快地消耗训练数据来获取更广泛的常识知识;反之,较大的模型更擅长于减少每步的损失,显示出对细微的语言模式有更深的理解,该团队使用245.37B个令牌来训练16B模型,39.64B个令牌来训练51B模型,以及26.54B个令牌来训练101B模型。不同大小的每天数十亿令牌的使用情况详见下表。
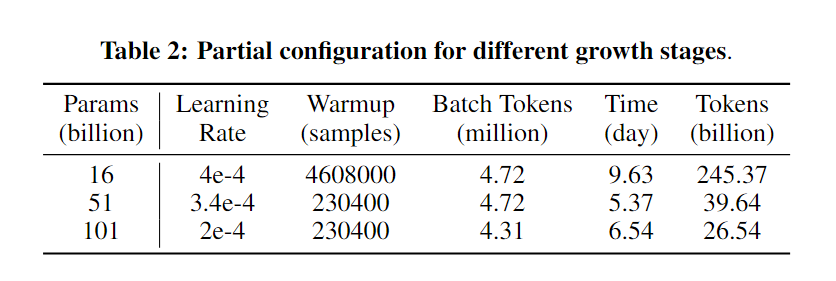
在这种增长时间表下,101B模型的总时间成本是21.54天,这比从头开始训练一个101B模型(需要47.64天)节省了54.8%的时间,相当于2.2倍的加速。
不同阶段的性能评估
研究成员对FLM在所有阶段(包括16B、51B和101B)的性能进行了评估。每个阶段的训练数据分别是0.246TB、0.04TB和0.026TB。下表呈现了各阶段FLM模型的表现。
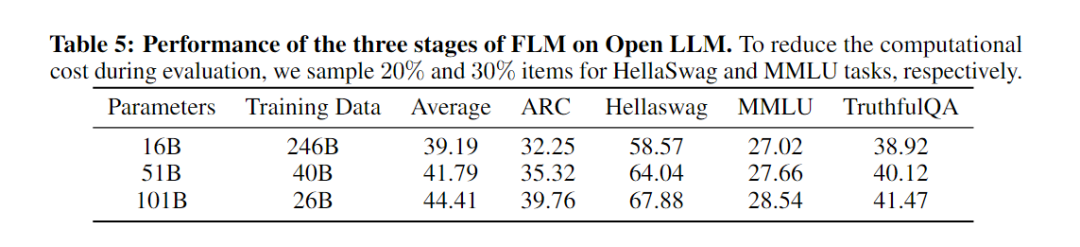
结果显示,FLM的性能确实随着模型大小的增加而提高,这符合预期。FLM-101B在几乎所有任务上都实现了最佳性能,这意味着模型能够在每次增长后从先前的阶段继承知识。他们还发现101B模型在使用较少样本的情况下比51B模型有更显著的性能提升。这表明模型在增长后的训练中成功地加入了新的权重,并在损失较低时利用了模型大小的优势。有趣的是,ARC和HellaSwag的表现也持续并显著增加。因此,可以预见,随着处理更多的训练数据,FLM-101B在开放LLM上的性能将大大提高,除了在MMLU上,因为它与特定的领域有关。
FLM主要结构和其他技术细节
Backbone
选择FreeLM作为基础架构主要是为了实现高效的长序列建模,此中采用了可外推的位置嵌入(xPos)来增强模型的长度外推能力。该技术受到了RoPE原理的启发,并在旋转矩阵中引入了指数衰减来实现目标。同时,模型保留了GPT和FreeLM的变换器块设计,并采用了来自GPT-4的分词器,以支持更大的词汇量。
预训练
FLM-101B延续了FreeLM的训练策略,结合了受语言信号指导的语言建模目标和受教师信号指导的二元分类目标。但是当模型规模扩大超过16B时,它开始展示出训练不稳定的问题。为了克服这一问题,研究团队采用了一个统一的目标,它通过使用一种掩码策略和两个专用令牌来同时处理教师和语言信号。这些令牌协助将二元分类目标转化为一个语言建模格式。
在大规模的无监督文本语料库中,该模型遵循GPT系列的训练目标,即最大化token预测的可能性。FLM-101B是一个英汉双语模型,它在语言建模中将英语和汉语语料库按约53.5:46.5的比例混合。在预训练阶段,作者整合了OIG和COIG多任务教育提示数据。
在命题判断任务中,原始的FreeLM教师目标旨在最小化二元分类的交叉熵。在FLM-101B的训练过程中,这一二元分类已转化为自回归语言模型形式。具体来说,它利用两个emoji和来代替原来的1和0二进制标签,通过对命题中的令牌应用零掩蔽来计算损失,并在每个命题的结尾预测这两个特殊令牌中的一个。这种方法成功地统一了教师目标和语言建模目标。此外,该模型摒弃了FreeLM的迭代训练方法,转而在每批数据中完全混合两种信号的样本,从而增强了数据采样分布的一致性,并提高了训练的稳定性。
需要注意的是,由于计算资源的限制,教师信号仅应用于eFLM-16B版本。
实验配置
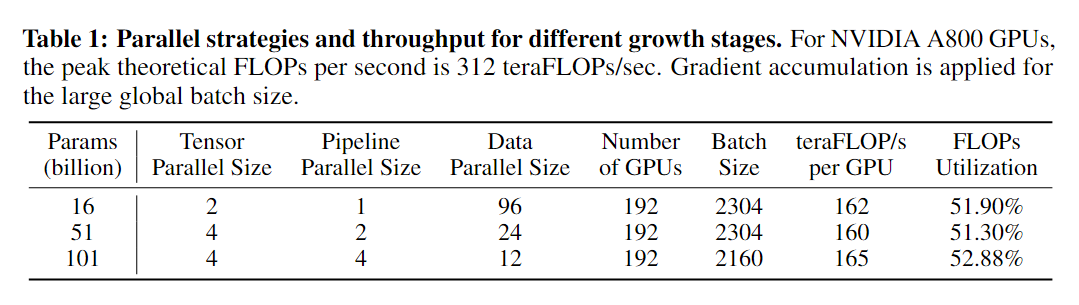
FLM-101B 在 24 个 DGX-A800 GPU (8×80G) 服务器的集群上进行训练,持续不到 26 天。基于增长策略依次完成了该集群上大小为 16B、51B 和 101B 的模型训练。
数据并行和张量模型并行已成为训练十亿规模模型的标准方法。然而,过多的张量并行可能会加剧GPU通信开销,影响训练效率。为了解决这个问题,研究整合了管道模型并行,并采用了3D并行策略来实现最优的吞吐量。此外,通过采用序列并行,沿着序列长度维度切分了输入到Transformer核心的LayerNorm和Dropout层,从而进一步节省了GPU计算资源和内存利用率。Megetron-LM 4牙杯用来实现分布式优化器来进一步减少GPU内存消耗,这是一种可以在数据并行排名中均匀分配优化器状态的技术。
训练的稳定性
超过100B参数的模型在训练过程中通常会遇到一系列稳定性问题,这包括损失发散、梯度爆炸和数值的溢出或下溢。这不仅大大增加了寻找合适的超参数(例如最优学习率)的难度,还增加了训练过程中需要持续监控和维护的需求,如问题解决、数据调整和重启等,使项目预算变得不可预测。不过,研究团队找到了一个有前途的解决方案来减轻这些问题。
他们基于Tensor Programs理论来预测损失,该理论揭示了一系列与模型训练动态相关的通用关系,尤其是在模型宽度趋向于无限的情况下。这产生了一个参数化的映射,可以用于找到小模型及其更大对应模型之间某些超参数的最优值,这被称为μP。这个理论提供了两个重要见解:
- “更宽更好”的原则表明,在μP指导下,更宽的模型在处理相同的数据时会产生比其更窄的版本更低的损失。这意味着如果一个窄模型可以收敛,那么其更宽的版本也将会收敛。
- 他们还指出可以使用小模型的损失来预测大模型的损失值,这一点在GPT-4技术报告中得到了表述,并且在开源社区也有μScaling项目验证了这一点,它结合μP和修改后的缩放规则来实现损失预测。
为了实现训练稳定性,研究团队在FLM-16B训练开始前确定了数据分布,然后对三个超参数(学习率、初始化标准偏差和输出层的softmax温度)进行了网格搜索。这个搜索是通过运行一个有40M代理模型完成的,该模型具有较小的隐藏状态维度和头部数量。网格搜索找到了最优的超参数组合,而这些参数随后被应用到更大的16B模型上,确保了一个无不稳定的顺利训练体验。
借助μP和特定的增长策略,他们成功地避免了在FLM-51B和FLM-101B中的增长后分歧问题,从而实现了一个有效且稳定的训练过程。
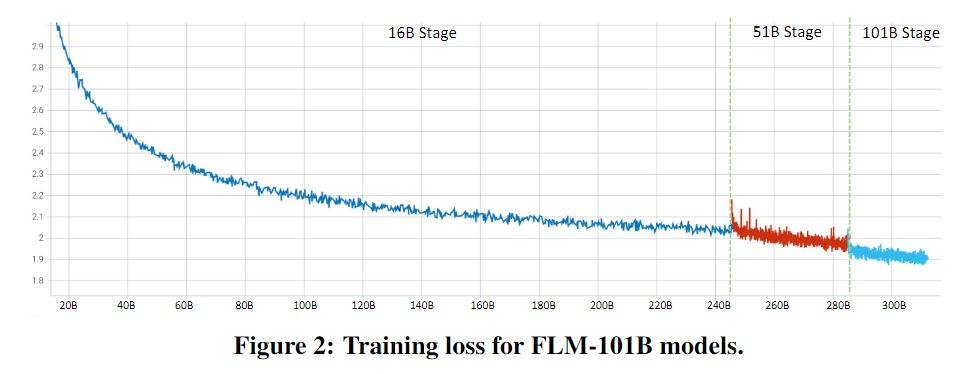
模型初步评估
与开源模型的对比
考虑了ARC-Challenge, HellaSwag, MMLU, and TruthfulQA四个数据集,和目前的开源模型进行了对比,性能如下:
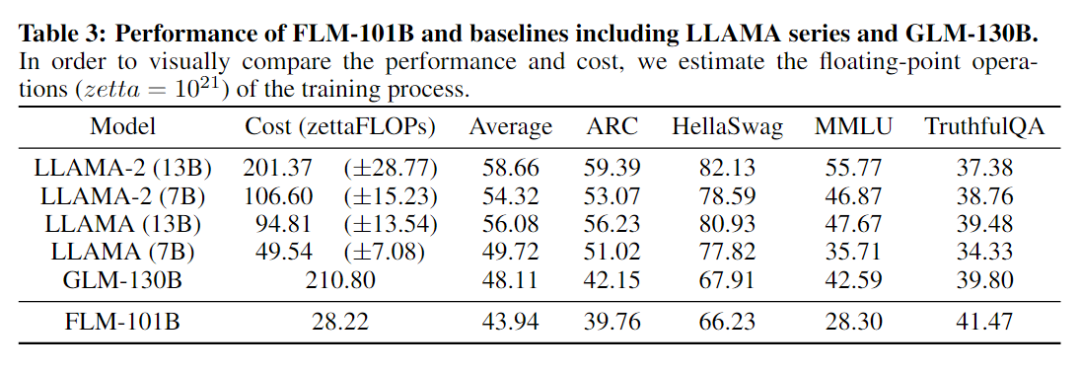
在所有基线模型中,FLM-101B的平均得分为43.94,排名最低。然而,深入探究这些任务的本质可以发现,这并不表明模型的表现较差。
MMLU任务通常需要特定领域的知识来解答。考虑到FLM-101B的训练数据中并没有特意加入任何教科书或考试题目,所以其取得的分数是合理的。一个直接证明是,在一个结合了FreeLM目标并包含这种知识的FLM变体(eFLM-16B,见第4.3节)中,即使是一个16B的模型也能超越GLM-130B的表现。
TruthfulQA、ARC和HellaSwag更强调常识和维基级别的知识,它们的表现随着数据量和训练损失的增加而提高。尽管FLM-101B只使用了不到0.16TB的英文数据(大约是LLAMA-2的1/10),但它仍然在所有基线中获得了最高的41.47的准确度。在ARC和HellaSwag上,FLM-101B与GLM-130B有相似的英文数据量(约0.2TB)并且表现相当。此外,GLM-130B的训练数据包括ARC和Hellaswag。
引入专业知识后的再评估
研究团队决定在FLM训练过程中引入专业知识数据来增强其效果,通过将FreeLM目标和专业数据相结合,以加强FLM-16B的效能。这种增强的数据源包括部分MMLU辅助训练集,一些与C-Eval测试有相似域和格式的考试题目,以及其他领域的知识数据。通过这种方式创建的模型被命名为eFLM-16B。
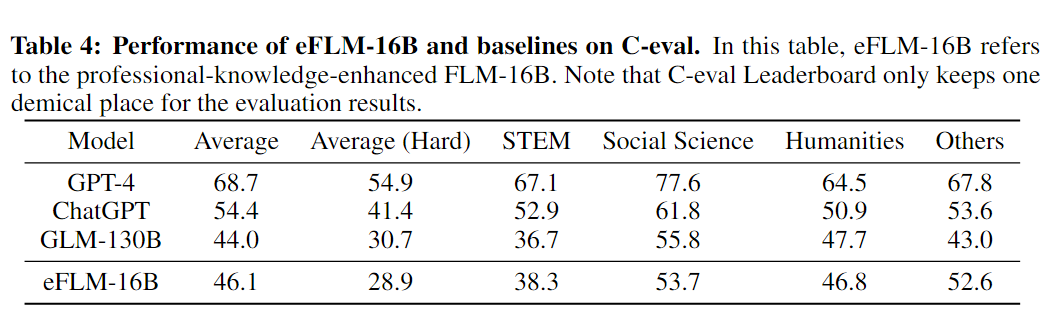
一个明显的发现是,引入相关领域的专业知识数据可以显著提升MMLU和C-Eval的分数。具体来说,在这两项任务中,eFLM-16B的表现都超过了GLM-130B,提高了约2个百分点。
这个结果验证了一个重要的观点:仅仅依靠数据集的分数是不能全面反映语言模型的智能水平的,因为特定训练数据的影响可能是巨大的,而不是反映模型的综合能力。这表明,在评估语言模型的智能时,不能只依赖于特定的数据集得分来判断,而应该考虑一个更全面的评估方法来确保模型的智能是全面和多元的。
在IQ基准上的评估
符号映射
最新的研究表明,在处理特定类别的文本分类任务时(比如将文档或情感进行分类),现有方法常常难以泛化。这主要是因为很多可以公开获取的网站包含了大量用于训练的、带有标签的原始语言文本数据集,如SemEval、IMDB和Yelp 6。这导致了模型倾向于过度拟合标签的语义,而非从全新的上下文中推断它们的含义。
为了解决这个问题,研究者将原始类别标签替换为在训练数据中不太可能见到的emoji,来测试模型的真正理解能力和泛化能力。这种做法也把评估任务变得更加侧重于上下文学习。下图是一个符号映射的例子。
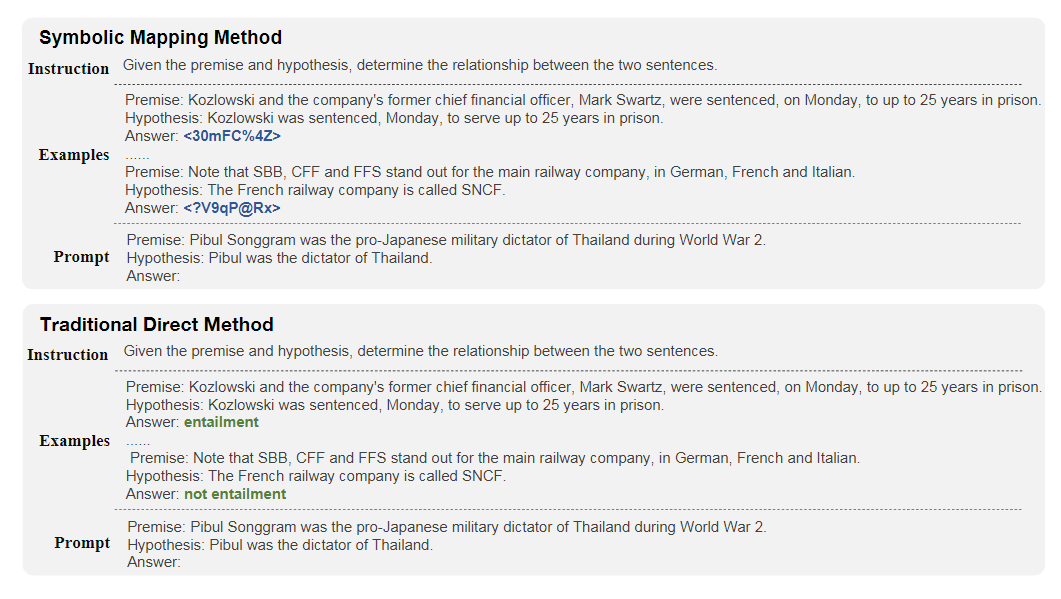
研究者还开创了一种新的IQ基准测试方式。他们利用了已有的基准数据源,例如SuperGLUE和CLUE,并对其中最多300个样本的原始类别进行了随机字符串替换。下图是模型在该基准上的评估结果。
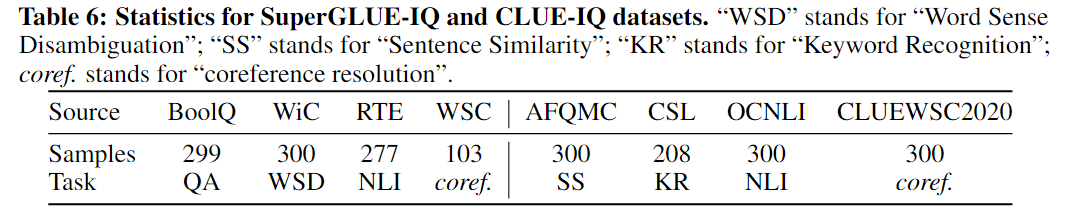
在进行BoolQ、WiC和RTE这些任务测试时,FLM-101B模型和GPT-3的表现非常相似,并且都比GLM-130B表现更好。尤其是在BoolQ任务上,它们的表现比GLM-130B高出9个百分点。但在WSC任务中,GLM-130B表现最佳,领先其他模型18个百分点,这归功于它的双向结构,这使得它在处理共指解析任务时更有优势。值得注意的是,尽管FLM-101B的计算成本只有GPT-3的1/13,但其表现却相当不错。
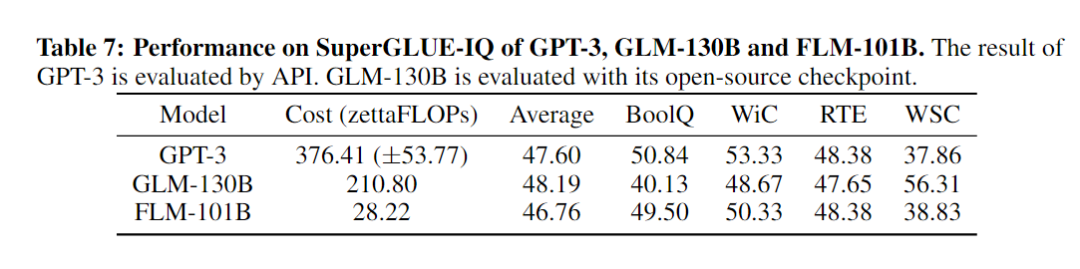
在CLUE-IQ基准测试中,FLM-101B表现最好,得分高达42.07。它特别在AFQMC、CSL和CLUEWSC2020等任务上表现出色,这显示了该模型在处理中文任务时具有出色的能力。有意思的是,它在中文的WSC任务上胜过GLM-130B,但在英文版上却稍逊一筹。这揭示了中英两种语言之间存在的巨大差异。综上所述,FLM-101B不仅在中文IQ测试中表现突出,其成本效益比也相当显著,只需要GLM-130B的大约12%的成本就能实现更优秀的表现。
规则理解
理解并按照给定规则执行是衡量人类智能的一个基本方面。为了评估这种理解能力,研究团队设计了一个规则理解评估测试。这个测试与基于思维链的推理测试有所不同;它更侧重于理解简单规则并做出正确行动,而不是推理能力。例如,“计数数字序列”是规则理解评估的一个典型任务,而在模型实现这种基本的规则理解能力之前,它是不能完成基于思维链的逐步推理的。
此外,还有一些具体任务来深入评估这一能力,包括无提示计数和字符串替换任务。在无提示计数任务中构建了一个包含150个项目的数据集,一个典型的示例是提示从一个数到另一个数进行计数,如“从10010数到10035:10010,10011,10012,...”。
而字符串替换(4次尝试)任务则是为了检验模型按照人类意图精确编辑文本的能力,它包含300个项目,每一个都开始于清晰的指示。例如,“替换单词”任务会要求在下面的句子中用目标词替换指定的词,而“替换小写字母”任务则要求将给定文本中的所有大写字母修改为小写。为了保证任务的多样性,计数范围和待替换的单词都是通过均匀分布来确定的。
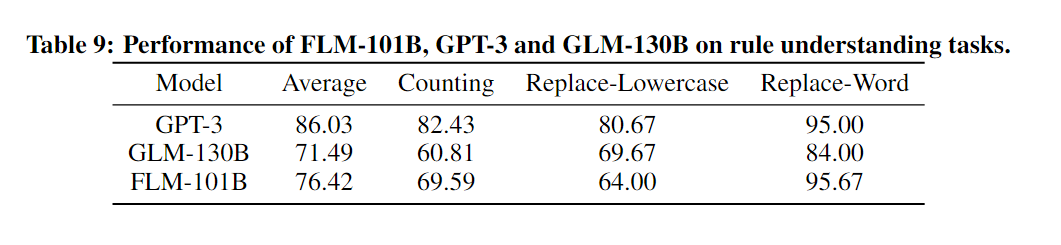
下表展示了模型在规则理解任务上的表现性能。
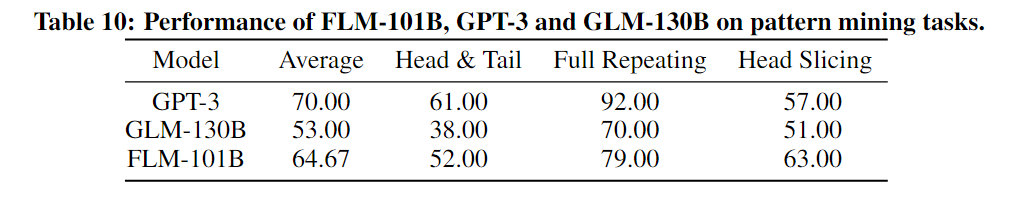
模式识别
模式识别涉及到在新环境中归纳和推断出现的模式。在这个基准测试中包含三个任务来进行评估。
- 头尾添加任务要求在给定的输入前后添加头和尾,这两个元素(即头和尾)应与给定示例中的元素完全相同。
- 完全重复任务则要求将输入序列完全重复一次。
- 头部切片任务,模型需要返回输入的前一定数量的字符,这个数字可以从前面的示例中推断出来。
下图是一个示例。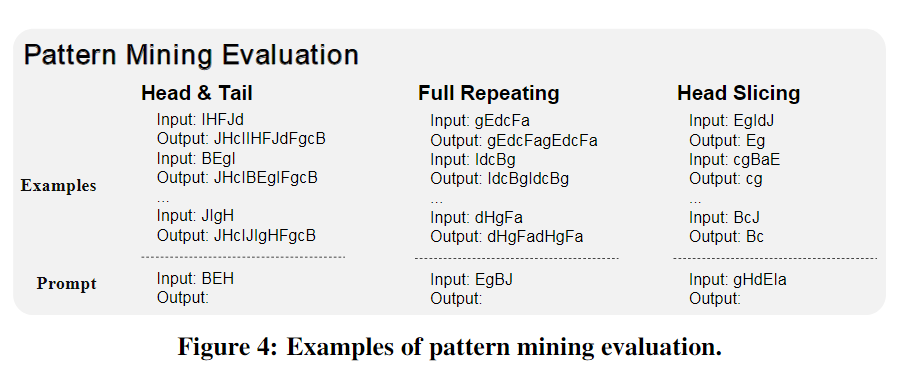
在模式挖掘的所有三项任务中,FLM-101B取得了第二好的表现。与规则理解评估相似,由于有更多的训练数据,GPT-3取得了最好的表现。在头部切片任务上,FLM-101B超越了GPT-3和GLM-130B。在另外两项任务中,这三个模型的表现顺序相同:GPT-3排在第一,FLM-101B排在第二,GLM-130B排在第三。详细来说,FLM-101B相比GLM-130B分别提高了14%和9%。
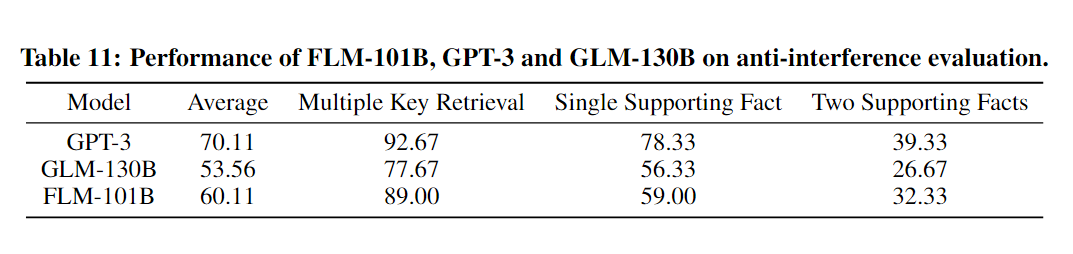
抗干扰评估
抗干扰能力对于在全新的嘈杂环境中找到和利用与特定目标真正相关的信息至关重要。例如,许多LLM会在接收到嘈杂输入的提示时开始胡言乱语。为此,作者在三种任务类型中进行抗干扰评估:
- 多关键词检索是一种谜题,它在大量无关的文本中隐藏了一些关键词。如果LLM的抗干扰能力不够强,它们将输出错误甚至无意义的词。
- 单一支持事实跟踪和双重支持事实跟踪任务测试模型是否能够找到隐藏在一系列无关陈述中的支持事实链来正确回答问题。
下图显示了此测试的两个典型示例。
在所有baseline中,FLM-101B实现了第二好的性能89%、59%和32.3%,与GLM-130B相比,其优势约为11%、3%和6%。考虑到计算成本,FLM-101B的出众是显而易见的。
总结
该研究开发了中英双语的FLM-101B模型,一个开源的、成本低廉的但功能强大的LLM,它成功地在10万美元的预算内从零开始训练。
研究团队利用增长策略来训练模型,以降低初始成本,首先得到一个知识相对有限的基本模型,然后再逐步扩展该模型的知识库以适应不同领域的需求。
此外,研究团队还认识到,要准确评估一个LLM的智能程度,需要更先进和综合的评估方法。传统的评估方法,如MMLU、SuperGLUE和CLUE等,已不再足够。为了解决这一问题,他们创造了一个系统的IQ评估基准测试,它能够全面而准确地衡量智力的四个核心方面,而且还可以方便地进行自动评估。
-
ARM用以解决图像超分模型过参数问题2022-06-10 2916
-
探索一种降低ViT模型训练成本的方法2022-11-24 1563
-
飞行训练成绩评估模型的建立与实现2016-05-04 769
-
缓解模型训练成本过高的问题2022-05-10 2599
-
智能开源大模型baichuan-7B技术改进2023-06-17 2076
-
开源大模型Falcon(猎鹰) 180B发布 1800亿参数2023-09-18 3051
-
Meta发布CodeLlama70B开源大模型2024-01-31 2171
-
Meta推出最强开源模型Llama 3 要挑战GPT2024-04-19 1812
-
谷歌Gemini Ultra模型训练成本近2亿美元2024-06-07 1458
-
英伟达开源Nemotron-4 340B系列模型,助力大型语言模型训练2024-06-17 1497
-
Anthropic AI模型训练成本飙升,预计未来将达百亿级2024-07-09 1288
-
AI大模型训练成本飙升,未来三年或达千亿美元2024-07-11 2719
-
采用FP8混合精度,DeepSeek V3训练成本仅557.6万美元!2025-01-13 1944
-
华为正式开源盘古7B稠密和72B混合专家模型2025-06-30 1549
-
摩尔线程发布MusaCoder:首个基于国产GPU全栈训练的开源代码大模型2026-06-12 239
全部0条评论

快来发表一下你的评论吧 !
