

解决医疗大模型训练数据难题,商汤最新研究成果登「Nature」子刊
描述
生成式AI正为医疗大模型迭代按下加速键。
近日,商汤科技联合行业合作伙伴,结合生成式人工智能和医疗图像数据的多中心联邦学习发表的最新研究成果《通过分布式合成学习挖掘多中心异构医疗数据》(MiningMulti-Center Heterogeneous Medical Data with Distributed Synthetic Learning),登上国际顶级学术期刊Nature子刊《自然-通讯》(NatureCommunications)。
 研究成果提出一个基于分布式合成对抗网络的联邦学习框架DSL(DistributedSynthetic Learning),可利用多中心的多样性医疗图像数据来联合学习图像数据的生成。
研究成果提出一个基于分布式合成对抗网络的联邦学习框架DSL(DistributedSynthetic Learning),可利用多中心的多样性医疗图像数据来联合学习图像数据的生成。
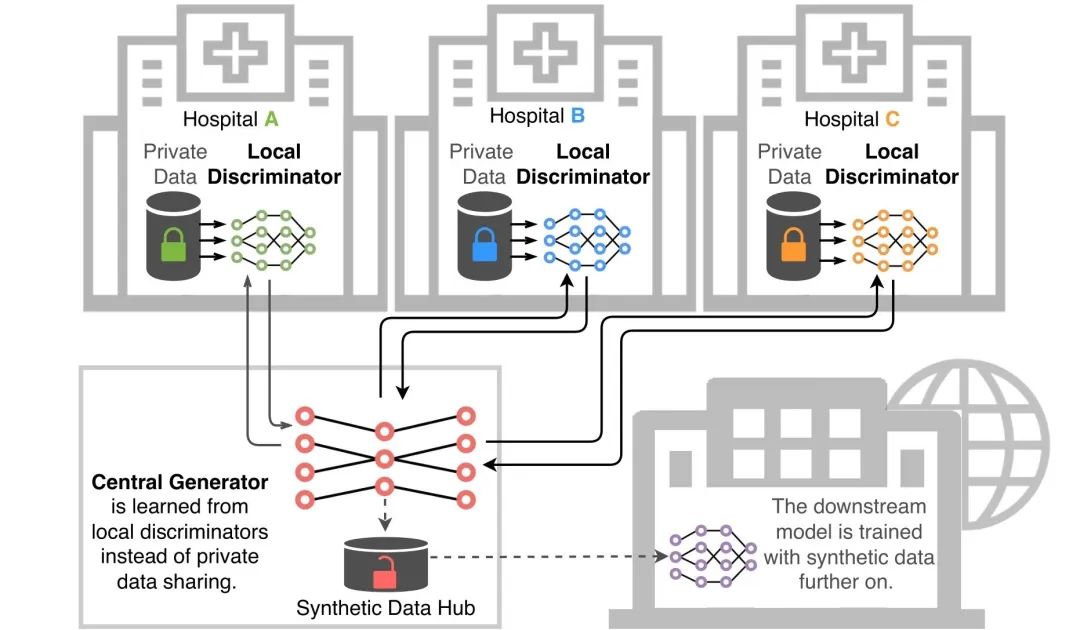 DSL框架包含一个中央生成器和多个分布式鉴别器,每个鉴别器位于一个医疗实体中。经过训练的生成器可以作为“数据生产工厂”,为下游具体任务的学习构建数据库
DSL框架包含一个中央生成器和多个分布式鉴别器,每个鉴别器位于一个医疗实体中。经过训练的生成器可以作为“数据生产工厂”,为下游具体任务的学习构建数据库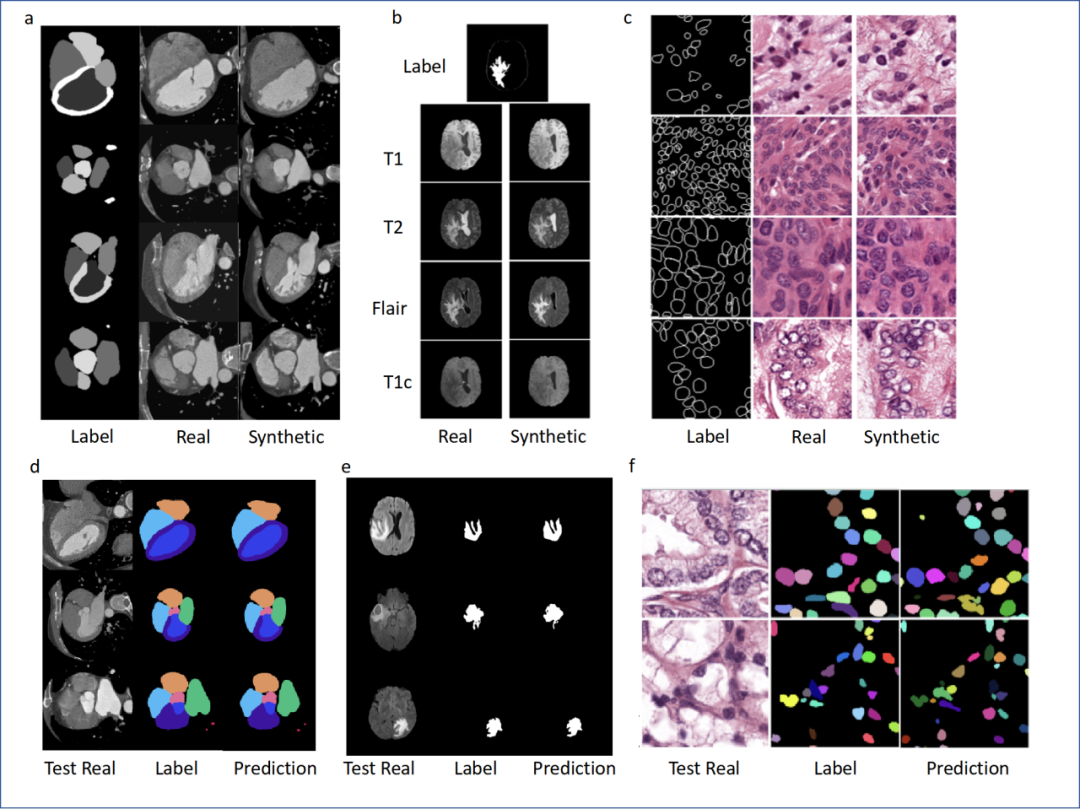 不同应用中生成数据示例:(a) 心脏CTA,(b) 大脑多模态MRI,(c) 病理图像;生成的数据构成大数据库可用于下游具体任务模型的学习,例如:(d) 全心分割,(e) 脑肿瘤分割,(f) 细胞核分割
不同应用中生成数据示例:(a) 心脏CTA,(b) 大脑多模态MRI,(c) 病理图像;生成的数据构成大数据库可用于下游具体任务模型的学习,例如:(d) 全心分割,(e) 脑肿瘤分割,(f) 细胞核分割 WAIC期间商汤科技展示大模型在医疗领域的多个落地应用案例
WAIC期间商汤科技展示大模型在医疗领域的多个落地应用案例
《自然-通讯》主要发表自然科学各个领域的高质量研究成果,影响因子16.6。
研究成果提出一个基于分布式合成对抗网络的联邦学习框架DSL(DistributedSynthetic Learning),可利用多中心的多样性医疗图像数据来联合学习图像数据的生成。
该分布式框架通过学习得到一个图像数据生成器,可以更灵活地生成数据,进而可替代多中心的真实数据,用于下游具体机器学习任务的训练,并具备较强可扩展性。
伴随大模型快速发展,Model as a Service(MaaS,模型即服务)正成为一大趋势。MaaS的大模型需要从海量的、多类型的数据中学习通用特征和规则,从而具备较强的泛化能力。
DSL框架能在保护数据隐私的同时,巧妙解决医疗大模型训练中常见的数据量不足的瓶颈,有效赋能MaaS的大模型训练。
在这一技术支撑下,商汤“医疗大模型工厂”能够帮助医疗机构更高效、高质量地训练针对不同临床问题的医疗大模型,使大模型在医疗领域的应用半径得以延伸。
兼顾隐私保护和数据共享
创新联邦学习模式打造
“数据生产工厂”
深度学习模型需要大量且多样性的数据“喂养”。
医疗领域对用户隐私保护有着极高要求,使得模型训练的医疗数据在多样性和标注质量上都受到限制,也使多中心的医疗数据收集和医疗AI模型的开发迭代面临较大挑战。
如何调和隐私保护和数据共享协作的矛盾?
“联邦学习提供了全新的解题思路。联邦学习是一种分布式机器学习方法, 可以在不共享数据的情况下对多中心的数据进行联合建模,联合学习某一特定应用模型。”
与主流的联邦学习模式不同,DSL框架的学习目标是数据生成器,而非具体应用的任务模型。
该分布式架构由一个位于中央服务器的数据生成器和多个位于不同数据中心的数据鉴别器组成。
在学习过程中,中央生成器负责生成“假”的图像数据,并发送给各个数据中心,各个数据中心用本地的真实数据和“假”数据进行对比后将结果回传给中央服务器,并基于反馈结果训练中央生成器生成更仿真的图像数据。
分布式的合成学习结束后,中央生成器可作为“数据生产工厂”,根据给定的约束条件(标注)生成高质量仿真图像数据,从而得到一个由生成数据组成的数据库。
该数据库可替代真实数据,用于下游具体任务的学习,使下游模型的更新迭代不再受到真实数据可访问性制约。同时,该方法通过分布式架构和联邦学习方式保证中央服务器无需接触数据中心真实数据,也不需要同步各中心的鉴别器模型,有效保障了数据安全和隐私保护。
DSL框架包含一个中央生成器和多个分布式鉴别器,每个鉴别器位于一个医疗实体中。经过训练的生成器可以作为“数据生产工厂”,为下游具体任务的学习构建数据库
赋能MaaS新生态
为医疗大模型开发迭代
按下加速键
DSL框架已通过多个具体应用的验证。
包括:大脑多序列MRI图像生成及下游的大脑肿瘤分割任务,心脏CTA图像生成及下游的全心脏结构分割任务,多种器官的病理图像生成及细胞核实例分割任务等。
在可扩展性方面,该方法还可支持多模态数据中缺失模态数据的生成、持续学习等不同场景。
不同应用中生成数据示例:(a) 心脏CTA,(b) 大脑多模态MRI,(c) 病理图像;生成的数据构成大数据库可用于下游具体任务模型的学习,例如:(d) 全心分割,(e) 脑肿瘤分割,(f) 细胞核分割DSL框架的构建,也有利于推动MaaS服务模式发展。
MaaS的医疗大模型在数据学习过程中,同样会遇到医疗数据隐私安全保护问题。基于DSL框架,可以有效地从多中心多样性数据中建立数据集仓库,通过生成数据,为大模型的开发迭代提供创新思路。
细化到具体应用场景,DSL框架可助力医疗机构高效开展跨中心、跨地域模型训练工作。
不同区域医疗机构在疾病数据多样性方面存在明显地域性差异,过去受限于数据安全和隐私保护要求,使用跨中心医疗数据联合训练医疗模型难度大。而借助DSL框架,有望帮助医疗机构更加高效便捷地开展跨中心医疗模型训练。
在2023 WAIC世界人工智能大会上,商汤科技与行业伙伴合作推出医疗大语言模型、医疗影像大模型、生信大模型等多种垂类基础模型群,覆盖CT、MRI、超声、内镜、病理、医学文本、生信数据等不同医疗数据模态。并展示了融入医疗大模型的升级版“SenseCare智慧医院”综合解决方案,以及多个医疗大模型落地案例。
借助商汤大装置的超大算力和医疗基础模型群的坚实基础,商汤得以成为“医疗大模型工厂”,帮助医疗机构针对不同临床问题高效训练模型,甚至辅助机构实现模型自主训练。
WAIC期间商汤科技展示大模型在医疗领域的多个落地应用案例
随着DSL框架的推出,医疗大模型训练将有望突破“数据孤岛”的桎梏,一定程度上降低医疗大模型的训练门槛,有助于加速模型开发迭代,使医疗大模型的应用范围得以覆盖更多临床医疗问题。
商汤科技将持续聚焦医疗机构的多样化需求,推动医疗大模型在更多医疗场景落地。 点击“阅读原文“查看论文详情

相关阅读,戳这里
《多场景落地!商汤打造“医疗大模型工厂”引领智慧医疗持续创新》
《嘉会医疗与商汤科技达成战略合作》

原文标题:解决医疗大模型训练数据难题,商汤最新研究成果登「Nature」子刊
文章出处:【微信公众号:商汤科技SenseTime】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 热点推荐
- 商汤科技
-
vr/ar在医疗上取得的成果2018-11-14 4034
-
医疗模型人训练系统是什么?2019-08-19 2135
-
基于MDA的训练仿真建模研究2009-12-25 1013
-
超级电容成能源储存系统的研究热门2016-11-14 965
-
深入了解最新的深度学习研究成果2019-04-03 5253
-
中国研究登上《柳叶刀》子刊封面!这里有全球首个AI眼科门诊2019-07-02 790
-
字节跳动参与的海外研究成果入选Nature子刊2022-05-20 4589
-
多场景落地!商汤打造“医疗大模型工厂”引领智慧医疗持续创新2023-07-11 1269
-
面向产业端正式提供服务,商汤重磅升级医疗健康大模型“大医”2023-10-16 1151
-
百度蛋白大语言模型研究成果登上Nature子刊封面2023-11-25 2402
-
再登Nature!DeepMind大模型突破60年数学难题,解法超出人类已有认知2023-12-24 1499
-
商汤医疗联合成立上海公共服务MaaS训练及成果转化联盟2024-11-28 1258
-
NVIDIA在ICRA 2025展示多项最新研究成果2025-06-06 1720
-
Nature传感器新子刊第一篇论文出炉,中国青年学者联手撰写2025-11-27 1225
-
北京大学与阿里巴巴达摩院合作研究成果荣登国际顶级学术期刊自然2026-05-22 721
全部0条评论

快来发表一下你的评论吧 !
