

什么是序列化 为什么要序列化
描述
什么是序列化?
“序列化”(Serialization )的意思是将一个对象转化为字节流。
这里说的对象可以理解为“面向对象”里的那个对象,具体的就是存储在内存中的对象数据。
与之相反的过程是“反序列化”(Deserialization )。
虽然挂着机器人的羊头,但是后面的介绍全部是计算机知识,跟机器人一丁点关系都没有,序列化就是一个纯粹的计算机概念。
序列化的英文Serialize就有把一个东西变成一串连续的东西之意。
形象的描述,数据对象是一团面,序列化就是将面团拉成一根面条,反序列化就将面条捏回面团。
另一个形象的类比是我们在对话或者打电话时,一个人的思想转换成一维的语音,然后在另一个人的头脑里重新变成结构化的思想,这也是一种序列化。
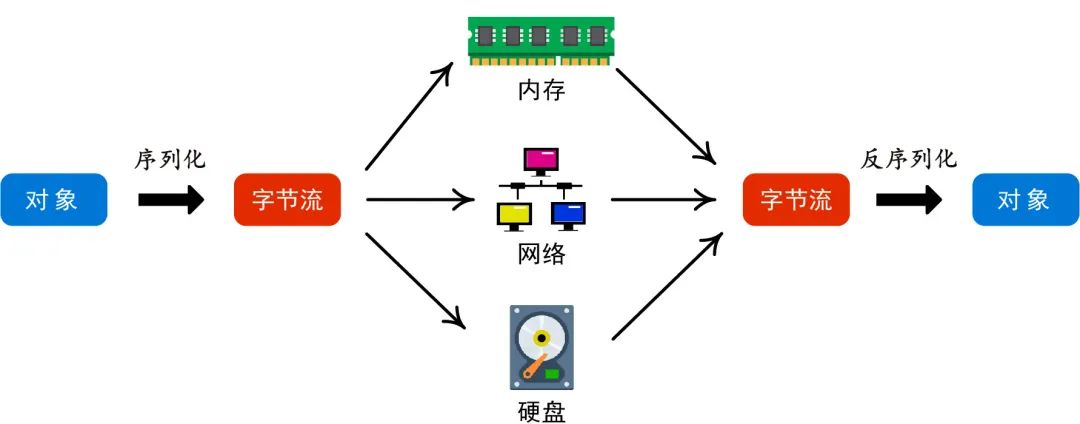
面对序列化,很多人心中可能会有很多疑问。
首先,为什么要序列化?或者更具体的说,既然对象的信息本来就是以字节的形式储存在内存中,那为什么要多此一举把一些字节数据转换成另一种形式的、一维的、连续的字节数据呢?
如果我们的程序在内存中存储了一个数字,比如25。那要怎么传递25这个数字给别的程序节点或者把这个数字永久存储起来呢?
很简单,直接传递25这个数字(的字节表示,即0X19,当然最终会变成二进制表示11001以高低电平传输存储)或者直接把这个数字(的字节表示)写进硬盘里即可。
所以,对于本来就是连续的、一维的、一连串的数据(例如字符串),序列化并不需要做太多东西,其本质是就是由内存向其它地方拷贝数据而已。
所以,如果你在一个序列化库里看到memcpy函数不用觉得奇怪,因为你知道序列化最底层不过就是在操作内存数据而已(还有些库使用了流的ostream.rdbuf()-》sputn函数)。
可是实际程序操作的对象很少是这么简单的形式,大多数时候我们面对的是包含不同数据类型(int、double、string)的复杂数据结构(比如vector、list),它们很可能在内存中是不连续存储的而是分散在各处。比如ROS的很多消息都包含向量。
数据中还有各种指针和引用。而且,如果数据要在运行于不同架构的计算机之上的、由不同编程语言所编写的节点程序之间传递,那问题就更复杂了,它们的字节顺序endianness规定有可能不一样,基本数据类型(比如int)的长度也不一样(有的int是4个字节、有的是8个字节)。
这些都不是通过简单地、原封不动地复制粘贴原始数据就能解决的。这时候就需要序列化和反序列化了。
所以在程序之间需要通信时(ROS恰好就是这种情况),或者希望保存程序的中间运算结果时,序列化就登场了。
另外,在某种程度上,序列化还起到统一标准的作用。
我们把被序列化的东西叫object(对象),它可以是任意的数据结构或者对象:结构体、数组、类的实例等等。
把序列化后得到的东西叫archive,它既可以是人类可读的文本形式,也可以是二进制形式。
前者比如JSON和XML,这两个是网络应用里最常用的序列化格式,通过记事本就能打开阅读;
后者就是原始的二进制文件,比如后缀名是bin的文件,人类是没办法直接阅读一堆的0101或者0XC9D23E72的。
序列化算是一个比较常用的功能,所以大多数编程语言(比如C++、Python、Java等)都会附带用于序列化的库,不需要你再去造轮子。
以C++为例,虽然标准STL库没有提供序列化功能,但是第三方库Boost提供了[ 2
]谷歌的protobuf也是一个序列化库,还有Fast-CDR,以及不太知名的Cereal,Java自带序列化函数,python可以使用第三方的pickle模块实现。
总之,序列化没有什么神秘的,用户可以看看这些开源的序列化库代码,或者自己写个小程序试试简单数据的序列化,例如这个例子,或者这个,有助于更好地理解ROS中的实现。
-
如何使用Serde进行序列化和反序列化2023-09-30 2622
-
如何将MAX9277序列化程序与MAX9276解序列化程序连接2026-06-16 13
-
Java序列化的机制和原理2019-07-10 1824
-
c语言序列化和反序列化有何区别2021-07-14 1477
-
关于c语言序列化和反序列化的知识点看完你就懂了2021-10-15 2481
-
SpringMVC JSON框架的自定义序列化与反序列化2022-10-10 3494
-
理解PHP反序列化漏洞2017-09-07 801
-
java序列化和反序列化范例和JDK类库中的序列化API2017-09-27 610
-
static属性为什么不会被序列化2022-07-15 2671
-
python序列化对象2023-03-10 3005
-
ROS中的序列化实现2023-09-14 1879
-
如何用C语言进行json的序列化和反序列化2023-10-07 2811
-
Java序列化怎么使用2023-10-10 1256
-
什么时候需要Boost序列化2023-11-10 1229
-
JSON:简洁代码高效搞定序列化与反序列化2026-02-25 367
全部0条评论

快来发表一下你的评论吧 !
