

基于MMPose的姿态估计配置案例
人工智能
描述
前言
MMPose是一款基于PyTorch的姿态分析开源工具箱,是OpenMMLab项目成员之一,主要特性:
支持多种人体姿态分析相关任务:2D多人姿态估计、2D手部姿态估计、动物关键点检测等等
更高的精度和更快的速度:包括“自顶向下”和“自底向上”两大类算法
支持多样的数据集:支持了很多主流数据集的准备和构建,如 COCO、 MPII等
模块化设计:将统一的人体姿态分析框架解耦成不同的模块组件,通过组合不同的模块组件,可以便捷地构建自定义人体姿态分析模型
本文主要对动物关键点检测模型进行微调与测试,从数据集构造开始,详细解释各模块作用。对一些新手可能会犯的错误做一些说明
环境配置
mmcv的安装方式在我前面的mmdetection和mmsegmentation教程中都有写到。这里不再提
MMPose安装方法最好是使用git,如果没有git工具,可以使用mim install mmpose
最后在项目文件夹下新建checkpoint、outputs、data文件夹,分别用来存放模型预训练权重、模型输出结果、训练数据
from IPython import display !pip install openmim !pip install -q /kaggle/input/frozen-packages-mmdetection/mmcv-2.0.1-cp310-cp310-linux_x86_64.whl !git clone https://github.com/open-mmlab/mmdetection.git %cd mmdetection !pip install -e . %cd .. !git clone https://github.com/open-mmlab/mmpose.git %cd mmpose !pip install -e . !mkdir checkpoint !mkdir outputs !mkdir data display.clear_output()
在上面的安装工作完成后,我们检查一下环境,以及核对一下安装版本
from IPython import display
import mmcv
from mmcv.ops import get_compiling_cuda_version, get_compiler_version
print('MMCV版本', mmcv.__version__)
%cd /kaggle/working/mmdetection
import mmdet
print('mmdetection版本', mmdet.__version__)
%cd /kaggle/working/mmpose
import mmpose
print('mmpose版本', mmpose.__version__)
print('CUDA版本', get_compiling_cuda_version())
print('编译器版本', get_compiler_version())
输出:
MMCV版本 2.0.1 /kaggle/working/mmdetection mmdetection版本 3.1.0 /kaggle/working/mmpose mmpose版本 1.1.0 CUDA版本 11.8 编译器版本 GCC 11.3
•为方便后续进行文件操作,导入一些常用库
import os import io import json import shutil import random import numpy as np from pathlib import Path from PIL import Image from tqdm import tqdm from mmengine import Config from pycocotools.coco import COCO
预训练模型推理
在进行姿态估计前需要目标检测将不同的目标检测出来,然后再分别对不同的目标进行姿态估计。所以我们要选择一个目标检测模型。
这里选择的是mmdetection工具箱中的RTMDet模型,型号选择RTMDet-l。配置文件位于mmdetection/configs/rtmdet/rtmdet_l_8xb32-300e_coco.py,我们复制模型权重地址并进行下载。
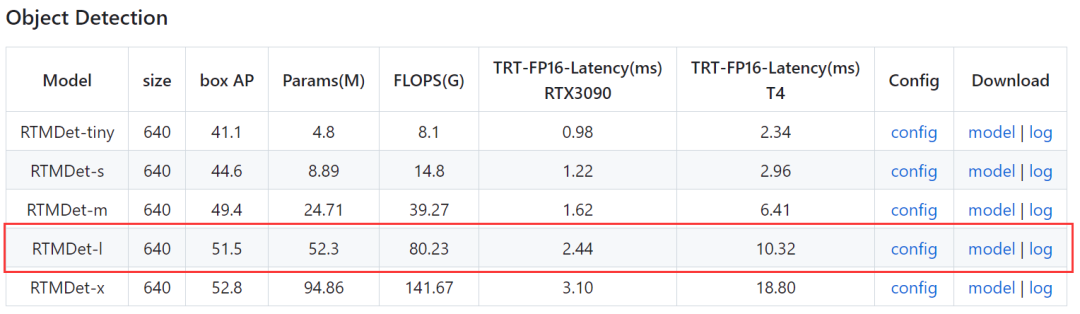
姿态估计模型选择RTMPose模型,打开mmpose项目文件夹projects/rtmpose/README.md文档,发现RTMPose模型动物姿态估计(Animal 2d (17 Keypoints))仅提供了一个预训练模型。
配置文件位于projects/rtmpose/rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py,我们复制模型权重地址并进行下载。

将预训练权重模型全部放入mmpose项目文件夹的checkpoint文件夹下。
# 下载RTMDet-L模型,用于目标检测 !wget https://download.openmmlab.com/mmdetection/v3.0/rtmdet/rtmdet_l_8xb32-300e_coco/rtmdet_l_8xb32-300e_coco_20220719_112030-5a0be7c4.pth -P checkpoint # 下载RTMPose模型,用于姿态估计 !wget https://download.openmmlab.com/mmpose/v1/projects/rtmposev1/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.pth -P checkpoint display.clear_output()
MMPose提供了一个被称为MMPoseInferencer的、全面的推理API。这个API使得用户得以使用所有MMPose支持的模型来对图像和视频进行模型推理。此外,该API可以完成推理结果自动化,并方便用户保存预测结果。
我们使用Cat Dataset数据集中的一张图片作为示例,进行模型推理。推理参数说明:
det_model:mmdetection工具箱中目标检测模型配置文件
det_weights:mmdetection工具箱中目标检测模型对应预训练权重文件
pose2d:mmpose工具箱中姿态估计模型配置文件
pose2d_weights:mmpose工具箱中姿态估计对应预训练权重文件
out_dir:图片生成的文件夹
from mmpose.apis import MMPoseInferencer img_path = '/kaggle/input/cat-dataset/CAT_00/00000001_012.jpg' # 使用模型别名创建推断器 inferencer = MMPoseInferencer(det_model = '/kaggle/working/mmdetection/configs/rtmdet/rtmdet_l_8xb32-300e_coco.py', det_weights = 'checkpoint/rtmdet_l_8xb32-300e_coco_20220719_112030-5a0be7c4.pth', pose2d = 'projects/rtmpose/rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py', pose2d_weights = 'checkpoint/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.pth') # MMPoseInferencer采用了惰性推断方法,在给定输入时创建一个预测生成器 result_generator = inferencer(img_path, out_dir = 'outputs', show=False) result = next(result_generator) display.clear_output()
可视化推理结果
import matplotlib.pyplot as plt
img_og = mmcv.imread(img_path)
img_fuse = mmcv.imread('outputs/visualizations/00000001_012.jpg')
fig, axes = plt.subplots(1, 2, figsize=(15, 10))
axes[0].imshow(mmcv.bgr2rgb(img_og))
axes[0].set_title('Original Image')
axes[0].axis('off')
axes[1].imshow(mmcv.bgr2rgb(img_fuse))
axes[1].set_title('Keypoint Image')
axes[1].axis('off')
plt.show()
数据处理
数据内容详解
Cat Dataset包含9000多张猫图像。对于每张图像,都有猫头部的注释,有9个点,2个用于眼睛,1个用于嘴巴,6个用于耳朵。
注释数据存储在1个文件中,文件名是相应的图像名称,末尾加上“cat”。每张猫图像都有1个注释文件。对于每个注释文件,注释数据按以下顺序存储:
○Number of points (关键点数目)
○Left Eye(左眼)
○Right Eye(右眼)
○Mouth(嘴)
○Left Ear-1(左耳-1)
○Left Ear-2(左耳-2)
○Left Ear-3(左耳-3)
○Right Ear-1(右耳-1)
○Right Ear-2(右耳-2)
○Right Ear-3(左耳-3)
数据集最初在互联网档案馆中找到,网站(https://archive.org/details/CAT_DATASET)
数据层级目录如下所示:
- CAT_00 - 00000001_000.jpg - 00000001_000.jpg.cat - 00000001_005.jpg - 00000001_005.jpg.cat - ... - CAT_01 - 00000100_002.jpg - 00000100_002.jpg.cat - 00000100_003.jpg - 00000100_003.jpg.cat - CAT_02 - CAT_03 - CAT_04 - CAT_05 - CAT_06
总的来说,一共有7个文件夹,每个文件夹里面有若干.jpg格式的图片文件,且对应有.cat格式的注释文件,.cat文件可以看做是文本文件,内容示例:
9 435 322 593 315 524 446 318 285 283 118 430 195 568 186 701 81 703 267
除第1个数字9表示有9个关键点,后面每2个点表示1个部位的坐标(x,y),所以一共有1 + 2 * 9 = 19个点
文件夹规整
我们将数据集中的7个文件夹中的图片与注释文件分开,分别存储在mmpose项目文件夹data文件夹中,并分别命名为images、ann
def separate_files(og_folder, trans_folder):
image_folder = os.path.join(trans_folder, 'images')
ann_folder = os.path.join(trans_folder, 'ann')
os.makedirs(image_folder, exist_ok=True)
os.makedirs(ann_folder, exist_ok=True)
for folder in os.listdir(data_folder):
folder_path = os.path.join(data_folder, folder)
if os.path.isdir(folder_path):
for file in os.listdir(folder_path):
if file.endswith('.jpg'):
source_path = os.path.join(folder_path, file)
target_path = os.path.join(image_folder, file)
shutil.copy(source_path, target_path)
elif file.endswith('.cat'):
source_path = os.path.join(folder_path, file)
target_path = os.path.join(ann_folder, file)
shutil.copy(source_path, target_path)
data_folder = '/kaggle/input/cat-dataset'
trans_folder = './data'
separate_files(data_folder, trans_folder)
构造COCO注释文件
本质上来说COCO就是1个字典文件,第1级键包含images、annotations、categories。
○其中images包含id(图片的唯一标识,必须要是数值型,不能有字符) 、file_name(图片名字)、 height(图片高度), width(图片宽度)这些信息
○其中annotations包含category_id(图片所属种类)、segmentation(实例分割掩码)、iscrowd(决定是RLE格式还是polygon格式)、image_id(图片id,对应images键中的id)、id(注释信息id)、bbox(目标检测框,[x, y, width, height])、 area(目标检测框面积)、num_keypoints(关键点数量), keypoints(关键点坐标)
○其中categories包含supercategory、id(类别id)、name(类别名)、keypoints(各部位名称)、skeleton(部位连接信息)
○更详细的COCO(https://zhuanlan.zhihu.com/p/29393415)注释文件解析推荐博客COCO数据集的标注格式、如何将VOC XML文件转化成COCO数据格式(https://www.cnblogs.com/marsggbo/p/11152462.html)
○构造read_file_as_list函数,将注释文件中的坐标变成[x,y,v],v为0时表示这个关键点没有标注,v为1时表示这个关键点标注了但是不可见(被遮挡了),v为2时表示这个关键点标注了同时可见。因为数据集中部位坐标均标注且可见,所以在x,y坐标后均插入2。
def read_file_as_list(file_path): with open(file_path, 'r') as file: content = file.read() key_point = [int(num) for num in content.split()] key_num = key_point[0] key_point.pop(0) for i in range(2, len(key_point) + len(key_point)//2, 2 + 1): key_point.insert(i, 2) return key_num,key_point
构造get_image_size函数,用于获取图片宽度和高度。
def get_image_size(image_path): with Image.open(image_path) as img: width, height = img.size return width, height
因为数据集没有提供目标检测框信息,且图片中基本无干扰元素,所以将目标检测框信息置为[0, 0, width, height]即整张图片。相应的目标检测框面积area = width * height。
# 转换为coco数据格式
def coco_structure(ann_dir,image_dir):
coco = dict()
coco['images'] = []
coco['annotations'] = []
coco['categories'] = []
coco['categories'].append(dict(supercategory = 'cat',id = 1,name = 'cat',
keypoints = ['Left Eye','Right Eye','Mouth','Left Ear-1','Left Ear-2','Left Ear-3','Right Ear-1','Right Ear-2','Right Ear-3'],
skeleton = [[0,1],[0,2],[1,2],[3,4],[4,5],[5,6],[6,7],[7,8],[3,8]]))
ann_list = os.listdir(ann_dir)
id = 0
for file_name in tqdm(ann_list):
key_num,key_point = read_file_as_list(os.path.join(ann_dir, file_name))
if key_num == 9:
image_name = os.path.splitext(file_name)[0]
image_id = os.path.splitext(image_name)[0]
height, width = get_image_size(os.path.join(image_dir, image_name))
image = {"id": id, "file_name": image_name, "height": height, "width": width}
coco['images'].append(image)
key_dict = dict(category_id = 1, segmentation = [], iscrowd = 0, image_id = id,
id = id, bbox = [0, 0, width, height], area = width * height, num_keypoints = key_num, keypoints = key_point)
coco['annotations'].append(key_dict)
id = id + 1
return coco
写入注释信息,并将其保存为mmpose项目文件夹data/annotations_all.json文件
ann_file = coco_structure('./data/ann','./data/images')
output_file_path = './data/annotations_all.json'
with open(output_file_path, "w", encoding="utf-8") as output_file:
json.dump(ann_file, output_file, ensure_ascii=True, indent=4)
拆分训练、测试数据
按0.85、0.15的比例将注释文件拆分为训练、测试文件
def split_coco_dataset(coco_json_path: str, save_dir: str, ratios: list,
shuffle: bool, seed: int):
if not Path(coco_json_path).exists():
raise FileNotFoundError(f'Can not not found {coco_json_path}')
if not Path(save_dir).exists():
Path(save_dir).mkdir(parents=True)
ratios = np.array(ratios) / np.array(ratios).sum()
if len(ratios) == 2:
ratio_train, ratio_test = ratios
ratio_val = 0
train_type = 'trainval'
elif len(ratios) == 3:
ratio_train, ratio_val, ratio_test = ratios
train_type = 'train'
else:
raise ValueError('ratios must set 2 or 3 group!')
coco = COCO(coco_json_path)
coco_image_ids = coco.getImgIds()
val_image_num = int(len(coco_image_ids) * ratio_val)
test_image_num = int(len(coco_image_ids) * ratio_test)
train_image_num = len(coco_image_ids) - val_image_num - test_image_num
print('Split info: ======
'
f'Train ratio = {ratio_train}, number = {train_image_num}
'
f'Val ratio = {ratio_val}, number = {val_image_num}
'
f'Test ratio = {ratio_test}, number = {test_image_num}')
seed = int(seed)
if seed != -1:
print(f'Set the global seed: {seed}')
np.random.seed(seed)
if shuffle:
print('shuffle dataset.')
random.shuffle(coco_image_ids)
train_image_ids = coco_image_ids[:train_image_num]
if val_image_num != 0:
val_image_ids = coco_image_ids[train_image_num:train_image_num +
val_image_num]
else:
val_image_ids = None
test_image_ids = coco_image_ids[train_image_num + val_image_num:]
categories = coco.loadCats(coco.getCatIds())
for img_id_list in [train_image_ids, val_image_ids, test_image_ids]:
if img_id_list is None:
continue
img_dict = {
'images': coco.loadImgs(ids=img_id_list),
'categories': categories,
'annotations': coco.loadAnns(coco.getAnnIds(imgIds=img_id_list))
}
if img_id_list == train_image_ids:
json_file_path = Path(save_dir, f'{train_type}.json')
elif img_id_list == val_image_ids:
json_file_path = Path(save_dir, 'val.json')
elif img_id_list == test_image_ids:
json_file_path = Path(save_dir, 'test.json')
else:
raise ValueError('img_id_list ERROR!')
print(f'Saving json to {json_file_path}')
with open(json_file_path, 'w') as f_json:
json.dump(img_dict, f_json, ensure_ascii=False, indent=2)
print('All done!')
输出:
loading annotations into memory... Done (t=0.13s) creating index... index created! Split info: ====== Train ratio = 0.85, number = 8495 Val ratio = 0, number = 0 Test ratio = 0.15, number = 1498 Set the global seed: 2023 shuffle dataset. Saving json to data/trainval.json Saving json to data/test.json All done!
可以看到训练集有8495张图片,测试集有1498张图片
模型配置文件
打开项目文件夹下的projects/rtmpose/rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py文件,发现模型配置文件仅继承_base_/default_runtime.py文件
需要修改主要有dataset_type、data_mode、dataset_info、codec、train_dataloader 、test_dataloader 、val_evaluator、base_lr、max_epochs、default_hooks。还有一些细节我在代码中有标注,可以参照着修改
修改完成后将文件写入./configs/animal_2d_keypoint/cat_keypoint.py中
custom_config = """
_base_ = ['mmpose::_base_/default_runtime.py']
# 数据集类型及路径
dataset_type = 'CocoDataset'
data_mode = 'topdown'
data_root = './data/'
work_dir = './work_dir'
# cat dataset关键点检测数据集-元数据
dataset_info = {
'dataset_name':'Keypoint_cat',
'classes':'cat',
'paper_info':{
'author':'Luck',
'title':'Cat Keypoints Detection',
},
'keypoint_info':{
0:{'name':'Left Eye','id':0,'color':[255,0,0],'type': '','swap': ''},
1:{'name':'Right Eye','id':1,'color':[255,127,0],'type': '','swap': ''},
2:{'name':'Mouth','id':2,'color':[255,255,0],'type': '','swap': ''},
3:{'name':'Left Ear-1','id':3,'color':[0,255,0],'type': '','swap': ''},
4:{'name':'Left Ear-2','id':4,'color':[0,255,255],'type': '','swap': ''},
5:{'name':'Left Ear-3','id':5,'color':[0,0,255],'type': '','swap': ''},
6:{'name':'Right Ear-1','id':6,'color':[139,0,255],'type': '','swap': ''},
7:{'name':'Right Ear-2','id':7,'color':[255,0,255],'type': '','swap': ''},
8:{'name':'Right Ear-3','id':8,'color':[160,82,45],'type': '','swap': ''}
},
'skeleton_info': {
0: {'link':('Left Eye','Right Eye'),'id': 0,'color': [255,0,0]},
1: {'link':('Left Eye','Mouth'),'id': 1,'color': [255,0,0]},
2: {'link':('Right Eye','Mouth'),'id': 2,'color': [255,0,0]},
3: {'link':('Left Ear-1','Left Ear-2'),'id': 3,'color': [255,0,0]},
4: {'link':('Left Ear-2','Left Ear-3'),'id': 4,'color': [255,0,0]},
5: {'link':('Left Ear-3','Right Ear-1'),'id': 5,'color': [255,0,0]},
6: {'link':('Right Ear-1','Right Ear-2'),'id': 6,'color': [255,0,0]},
7: {'link':('Right Ear-2','Right Ear-3'),'id': 7,'color': [255,0,0]},
8: {'link':('Left Ear-1','Right Ear-3'),'id': 8,'color': [255,0,0]},
}
}
# 获取关键点个数
NUM_KEYPOINTS = len(dataset_info['keypoint_info'])
dataset_info['joint_weights'] = [1.0] * NUM_KEYPOINTS
dataset_info['sigmas'] = [0.025] * NUM_KEYPOINTS
# 训练超参数
max_epochs = 100
val_interval = 5
train_cfg = {'max_epochs': max_epochs, 'val_begin':20, 'val_interval': val_interval}
train_batch_size = 32
val_batch_size = 32
stage2_num_epochs = 10
base_lr = 4e-3 / 16
randomness = dict(seed=2023)
# 优化器
optim_wrapper = dict(
type='OptimWrapper',
optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
paramwise_cfg=dict(
norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
# 学习率
param_scheduler = [
dict(type='LinearLR', start_factor=1.0e-5, by_epoch=False, begin=0, end=600),
dict(
type='CosineAnnealingLR',
eta_min=base_lr * 0.05,
begin=max_epochs // 2,
end=max_epochs,
T_max=max_epochs // 2,
by_epoch=True,
convert_to_iter_based=True),
]
# automatically scaling LR based on the actual training batch size
auto_scale_lr = dict(base_batch_size=1024)
# codec settings
# input_size可以换成128的倍数
# sigma高斯分布标准差,越大越易学,但进度低。高精度场景,可以调小,RTMPose 原始论文中为 5.66
# input_size、sigma和下面model中的in_featuremap_size参数需要成比例缩放
codec = dict(
type='SimCCLabel',
input_size=(512, 512),
sigma=(24, 24),
simcc_split_ratio=2.0,
normalize=False,
use_dark=False)
# 模型:RTMPose-M
model = dict(
type='TopdownPoseEstimator',
data_preprocessor=dict(
type='PoseDataPreprocessor',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
bgr_to_rgb=True),
backbone=dict(
_scope_='mmdet',
type='CSPNeXt',
arch='P5',
expand_ratio=0.5,
deepen_factor=0.67,
widen_factor=0.75,
out_indices=(4, ),
channel_attention=True,
norm_cfg=dict(type='SyncBN'),
act_cfg=dict(type='SiLU'),
init_cfg=dict(
type='Pretrained',
prefix='backbone.',
checkpoint='https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth'
)),
head=dict(
type='RTMCCHead',
in_channels=768,
out_channels=NUM_KEYPOINTS,
input_size=codec['input_size'],
in_featuremap_size=(16, 16),
simcc_split_ratio=codec['simcc_split_ratio'],
final_layer_kernel_size=7,
gau_cfg=dict(
hidden_dims=256,
s=128,
expansion_factor=2,
dropout_rate=0.,
drop_path=0.,
act_fn='SiLU',
use_rel_bias=False,
pos_enc=False),
loss=dict(
type='KLDiscretLoss',
use_target_weight=True,
beta=10.,
label_softmax=True),
decoder=codec),
test_cfg=dict(flip_test=True))
backend_args = dict(backend='local')
# pipelines
train_pipeline = [
dict(type='LoadImage', backend_args=backend_args),
dict(type='GetBBoxCenterScale'),
dict(type='RandomFlip', direction='horizontal'),
# dict(type='RandomHalfBody'),
dict(
type='RandomBBoxTransform', scale_factor=[0.8, 1.2], rotate_factor=30),
dict(type='TopdownAffine', input_size=codec['input_size']),
dict(type='mmdet.YOLOXHSVRandomAug'),
dict(
type='Albumentation',
transforms=[
dict(type='ChannelShuffle', p=0.5),
dict(type='CLAHE', p=0.5),
# dict(type='Downscale', scale_min=0.7, scale_max=0.9, p=0.2),
dict(type='ColorJitter', p=0.5),
dict(
type='CoarseDropout',
max_holes=4,
max_height=0.3,
max_width=0.3,
min_holes=1,
min_height=0.2,
min_width=0.2,
p=0.5),
]),
dict(type='GenerateTarget', encoder=codec),
dict(type='PackPoseInputs')
]
val_pipeline = [
dict(type='LoadImage', backend_args=backend_args),
dict(type='GetBBoxCenterScale'),
dict(type='TopdownAffine', input_size=codec['input_size']),
dict(type='PackPoseInputs')
]
train_pipeline_stage2 = [
dict(type='LoadImage', backend_args=backend_args),
dict(type='GetBBoxCenterScale'),
dict(type='RandomFlip', direction='horizontal'),
dict(type='RandomHalfBody'),
dict(
type='RandomBBoxTransform',
shift_factor=0.,
scale_factor=[0.75, 1.25],
rotate_factor=60),
dict(type='TopdownAffine', input_size=codec['input_size']),
dict(type='mmdet.YOLOXHSVRandomAug'),
dict(
type='Albumentation',
transforms=[
dict(type='Blur', p=0.1),
dict(type='MedianBlur', p=0.1),
dict(
type='CoarseDropout',
max_holes=1,
max_height=0.4,
max_width=0.4,
min_holes=1,
min_height=0.2,
min_width=0.2,
p=0.5),
]),
dict(type='GenerateTarget', encoder=codec),
dict(type='PackPoseInputs')
]
# data loaders
train_dataloader = dict(
batch_size=train_batch_size,
num_workers=2,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
dataset=dict(
type=dataset_type,
data_root=data_root,
metainfo=dataset_info,
data_mode=data_mode,
ann_file='trainval.json',
data_prefix=dict(img='images/'),
pipeline=train_pipeline,
))
val_dataloader = dict(
batch_size=val_batch_size,
num_workers=2,
persistent_workers=True,
drop_last=False,
sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
dataset=dict(
type=dataset_type,
data_root=data_root,
metainfo=dataset_info,
data_mode=data_mode,
ann_file='test.json',
data_prefix=dict(img='images/'),
pipeline=val_pipeline,
))
test_dataloader = val_dataloader
default_hooks = {
'checkpoint': {'save_best': 'PCK','rule': 'greater','max_keep_ckpts': 2},
'logger': {'interval': 50}
}
custom_hooks = [
dict(
type='EMAHook',
ema_type='ExpMomentumEMA',
momentum=0.0002,
update_buffers=True,
priority=49),
dict(
type='mmdet.PipelineSwitchHook',
switch_epoch=max_epochs - stage2_num_epochs,
switch_pipeline=train_pipeline_stage2)
]
# evaluators
val_evaluator = [
dict(type='CocoMetric', ann_file=data_root + 'test.json'),
dict(type='PCKAccuracy'),
dict(type='AUC'),
dict(type='NME', norm_mode='keypoint_distance', keypoint_indices=[0, 1])
]
test_evaluator = val_evaluator
"""
config = './configs/animal_2d_keypoint/cat_keypoint.py'
with io.open(config, 'w', encoding='utf-8') as f:
f.write(custom_config)
模型训练
使用训练脚本启动训练
!python tools/train.py {config}
因为训练输出太长,这里截取一段模型在测试集上最佳精度:
08/06 19:15:56 - mmengine - INFO - Evaluating CocoMetric... Loading and preparing results... DONE (t=0.07s) creating index... index created! Running per image evaluation... Evaluate annotation type *keypoints* DONE (t=0.57s). Accumulating evaluation results... DONE (t=0.03s). Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.943 Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.979 Average Precision (AP) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.969 Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = -1.000 Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.944 Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 20 ] = 0.953 Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.987 Average Recall (AR) @[ IoU=0.75 | area= all | maxDets= 20 ] = 0.977 Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets= 20 ] = -1.000 Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets= 20 ] = 0.953 08/06 19:15:56 - mmengine - INFO - Evaluating PCKAccuracy (normalized by ``"bbox_size"``)... 08/06 19:15:56 - mmengine - INFO - Evaluating AUC... 08/06 19:15:56 - mmengine - INFO - Evaluating NME... 08/06 19:15:57 - mmengine - INFO - Epoch(val) [60][47/47] coco/AP: 0.943453 coco/AP .5: 0.979424 coco/AP .75: 0.969202 coco/AP (M): -1.000000 coco/AP (L): 0.944082 coco/AR: 0.953471 coco/AR .5: 0.987316 coco/AR .75: 0.977303 coco/AR (M): -1.000000 coco/AR (L): 0.953471 PCK: 0.978045 AUC: 0.801710 NME: 0.121770 data_time: 0.101005 time: 0.435133 08/06 19:15:57 - mmengine - INFO - The previous best checkpoint /kaggle/working/mmpose/work_dir/best_PCK_epoch_55.pth is removed 08/06 19:16:01 - mmengine - INFO - The best checkpoint with 0.9780 PCK at 60 epoch is saved to best_PCK_epoch_60.pth.
可以看到模型PCK达到了0.978,AUC达到了0.8017,mAP也都挺高,说明模型效果非常不错!
模型精简
mmpose提供模型精简脚本,模型训练权重文件大小减少一半,但不影响精度和推理
将在验证集上表现最好的模型权重进行精简
import glob
ckpt_path = glob.glob('./work_dir/best_PCK_*.pth')[0]
ckpt_sim = './work_dir/cat_pose_sim.pth'
# 模型精简
!python tools/misc/publish_model.py
{ckpt_path}
{ckpt_sim}
模型推理
这里和上面的模型推理使用相同的思路,使用RTMDet模型进行目标检测,使用我们自己训练的RTMPose模型进行姿态估计。
不过pose2d参数是我们上面保存的配置文件./configs/animal_2d_keypoint/cat_keypoint.py,pose2d_weights为最佳精度模型精简后的权重文件glob.glob('./work_dir/cat_pose_sim*.pth')[0]。
img_path = '/kaggle/input/cat-dataset/CAT_00/00000001_012.jpg'
inferencer = MMPoseInferencer(det_model = '/kaggle/working/mmdetection/configs/rtmdet/rtmdet_l_8xb32-300e_coco.py',
det_weights = 'checkpoint/rtmdet_l_8xb32-300e_coco_20220719_112030-5a0be7c4.pth',
pose2d = './configs/animal_2d_keypoint/cat_keypoint.py',
pose2d_weights = glob.glob('./work_dir/cat_pose_sim*.pth')[0])
result_generator = inferencer(img_path, out_dir = 'outputs', show=False)
result = next(result_generator)
display.clear_output()
可视化训练结果
img_og = mmcv.imread(img_path)
img_fuse = mmcv.imread('outputs/visualizations/00000001_012.jpg')
fig, axes = plt.subplots(1, 2, figsize=(15, 10))
axes[0].imshow(mmcv.bgr2rgb(img_og))
axes[0].set_title('Original Image')
axes[0].axis('off')
axes[1].imshow(mmcv.bgr2rgb(img_fuse))
axes[1].set_title('Keypoint Image')
axes[1].axis('off')
plt.show()
编辑:黄飞
-
基于RV1126开发板的人脸姿态估计算法开发2025-04-14 2423
-
基于飞控的姿态估计算法作用及原理2023-11-13 2573
-
基于PoseDiffusion相机姿态估计方法2023-07-23 2830
-
AI技术:一种联合迭代匹配和姿态估计框架2023-07-18 1151
-
硬件加速人体姿态估计开源分享2023-06-25 1279
-
一种基于去遮挡和移除的3D交互手姿态估计框架2022-09-14 1703
-
基于OnePose的无CAD模型的物体姿态估计2022-08-10 2542
-
移动和嵌入式人体姿态估计2022-01-26 646
-
基于编解码残差的人体姿态估计方法2021-05-28 983
-
基于Bagging-SVM集成分类器的头部姿态估计方法2021-05-07 1123
-
基于深度学习的二维人体姿态估计算法2021-04-27 1229
-
基于深度学习的二维人体姿态估计方法2021-03-22 1385
-
针对姿态传感器的姿态估计方法的详细资料说明免费下载2018-12-11 1182
-
光照变化情况下的静态头部姿态估计2009-04-22 2362
全部0条评论

快来发表一下你的评论吧 !
