

自训练YOLOv5模型使用OpenVINO™优化并部署在英特尔开发套件
描述
1.1
简介
本文章将在《自训练Pytorch模型使用 OpenVINO 优化并部署在英特尔开发套件》文章的基础上进行扩展,将介绍如何使用 OpenVINO Python API 对 YOLOv5 模型进行优化以及部署,完成 YOLOv5 目标检测任务。
本文 Python 程序的开发环境是 Ubuntu20.04 LTS + PyCharm,硬件平台是英特尔开发套件爱克斯开发板 AIxBoard。
本文项目背景:针对 2023 第十一届全国大学生光电设计竞赛赛题 2 “迷宫寻宝”光电智能小车题目。基于该赛项宝藏样式,我通过深度学习训练出能分类四种不同颜色不同标记形状骨牌的模型,骨牌样式详见图 1.1。

图1.1 四种骨牌类型
1.2
YOLOv5 以及目标检测
YOLO (You Only Look Once) 是目标检测模型,目标检测是计算机视觉中一种重要的任务,目的是在一张图片中找出特定的物体,同时要求识别物体的种类和位置。在此之前的文章中 Pytorch 模型是用于图像分类,只要求识别画面中物体的种类。具体的区别通过图 1.2.1 直观可知。

图 1.2.1 图像分类、目标定位、目标检测
01
通过 labelImg 对图像进行数据集构建
Labelimg 是一款数据标注软件,支持输出包括 yolo, PascalVOC 等格式标注数据,这里我们选择 yolo 格式即可。
在环境中执行:
pip install labelimg -i https://mirror.baidu.com/pypi/simple
而后打开 labelimg 软件,如图 1.2.2
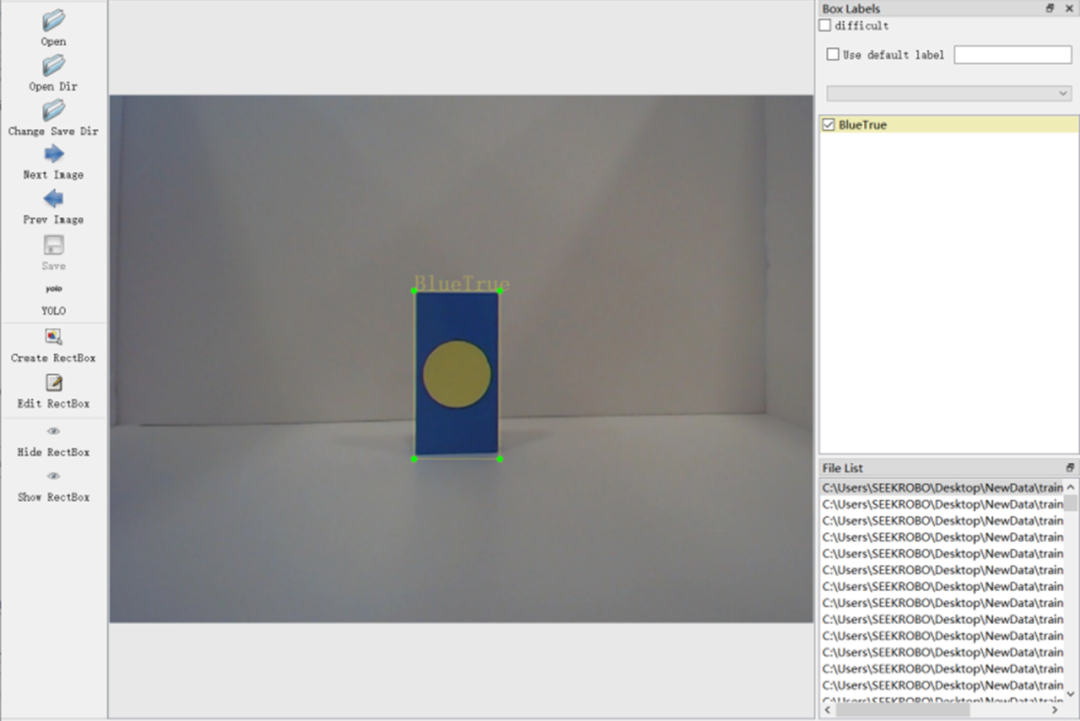
图 1.2.2 labelImg 软件界面
如图所示,选择好图片数据目录 (Open Dir) 和数据标注保存目录 (Choose Save Dir),就可以对想要的物体进行人工的数据标注。
02
标注好后检查保存目录中的 label 文件,查看是否无误,如图 1.2.3
图 1.2.3 标注好的文件
03
本次实验共标注 2000 张图片(单分类 500 张共 4 分类)具体训练流程在 YOLOv5 Github 有较为详细的教程,在此不作为重点讲解。得到 YOLOv5 模型后通过 OpenVINO Model Optimization 转化成 IR 模型,这样无论从处理速度还是精度都能获得一定程度的优化。
1.3
使用 OpenVINO Runtime 对 YOLOv5 模型进行推理
在这一章节里我们将在 Pycharm 中使用 OpenVINO Runtime 对我们训练的 YOLOv5 模型进行优化推理。
整个推理流程大致可以分为:
推理核心初始化 → 对输入图进行预处理 → 输入到推理引擎获得结果 → 通过置信度/NMS(非极大值抑制)过滤得到结果 → 将结果通过 OpenCV API 进行可视化
1.3.1
导入功能包
import openvino.runtime as ov import cv2 import numpy as np import openvino.preprocess as op
本次我们导入四个功能包,分别是 OpenVINO Runtime & PreProcess 、Numpy 、OpenCV。与之前不同在于我们需要使用 OpenVINO 自带的预处理 API 对我们的模型进行一个预先处理,使得模型能够正常工作在 OpenVINO 的推理引擎下。
PreProcess API 介绍:
OpenVINO PreProcess 是 OpenVINO Python API 大家庭的一员,主要是提供了一个 OpenVINO Runtime 原生用于数据预处理的 API 函数库,在不用 PreProcess 时,开发者需要用第三方库例如 OpenCV 来对其进行预处理,但是 OpenCV 作为一个开源的、广泛的功能库,数据预处理只能加载到 CPU 去进行实现,这无疑是增加对 CPU 资源的开销,并且之后需要将处理后数据再次返还到 iGPU 等计算设备进行推理。而 PreProcess 提供了一种方式,使得预处理也能直接集成到模型执行图中去,整个模型工作流程都在 iGPU 上流转,这样无需依赖 CPU,能提高执行效率。
由于输入数据的不同,我们需要预处理来将数据能够正确的进行处理。例如改变精度、改变输入颜色通道、输入数据的 Layout 等等。
整体 PreProcess 的流程大概是:
创建 PPP(PrePostProcess) 对象 → 声明输入数据信息 → 指定 Layout →设置输出张量信息 → 从 PPP 对象中构建 Model 并进行推理
可以明显得知,PreProcess 的存在使得预处理变得非常简单易懂,只需要在在转换前查看模型的输入输出信息,再比对自己环境下的输入数据,进行预处理改变即可。而且整个环境都可以在 iGPU 等计算设备上运行,减轻了 CPU 负担,可以把更多宝贵的资源留在处理其他重要事情上。
1.3.2
模型载入
将模型进行载入:
def Init():
global core
global model
global compiled_model
global infer_request
#核心创建
core = ov.Core()
#读取用YOLOv5模型转换而来的IR模型
model = core.read_model("best2.xml", "best2.bin")
#运用PPP(PrePostProcessor)对模型进行预处理
Premodel = op.PrePostProcessor(model)
Premodel.input().tensor().set_element_type(ov.Type.u8).set_layout(ov.Layout("NHWC")).set_color_format(op.ColorFormat.BGR)
Premodel.input().preprocess().convert_element_type(ov.Type.f32).convert_color(op.ColorFormat.RGB).scale(
[255., 255., 255.])
Premodel.input().model().set_layout(ov.Layout("NCHW"))
Premodel.output(0).tensor().set_element_type(ov.Type.f32)
model = Premodel.build()
compiled_model = core.compile_model(model, "CPU") #加载模型,可用CPU or GPU
infer_request = compiled_model.create_infer_request() #生成推理
1.3.3
图像尺寸调整
由于输入图的尺寸不确定性,在此我们特意加入一个 Resize 环节,用来适应不同分辨率的图像,但是若输入图像尺寸较为稳定,只需要求出其变换图的长宽比例即可。
def resizeimg(image, new_shape): old_size = image.shape[:2] #记录新形状和原生图像矩形形状的比率 ratio = float(new_shape[-1] / max(old_size)) new_size = tuple([int(x * ratio) for x in old_size]) image = cv2.resize(image, (new_size[1], new_size[0])) delta_w = new_shape[1] - new_size[1] delta_h = new_shape[0] - new_size[0] color = [100, 100, 100] new_im = cv2.copyMakeBorder(image, 0, delta_h, 0, delta_w, cv2.BORDER_CONSTANT, value=color) #增广操作 return new_im, delta_w, delta_h
1.3.4
推理过程以及结果展示
在上一节中我们把输入图像所要进行的预处理图像进行了一个定义,在这一小节则是 OpenVINO Runtime 推理程序的核心。
#************************************#
# 推理主程序 #
def main(img,infer_request):
push =[]
img_re,dw,dh = resizeimg(img,(640,640)) #尺寸处理
input_tensor = np.expand_dims(img_re, 0) #获得输入张量
infer_request.infer({0: input_tensor}) #输入到推理引擎
output = infer_request.get_output_tensor(0) #获得推理结果
detections = output.data[0] #获得检测数据
boxes = []
class_ids = []
confidences = []
for prediction in detections:
confidence = prediction[4].item() #获取置信度
if confidence >= 0.6: #初步过滤,过滤掉绝大多数的无效数据
classes_scores = prediction[5:]
_, _, _, max_indx = cv2.minMaxLoc(classes_scores)
class_id = max_indx[1]
if (classes_scores[class_id] > .25):
confidences.append(confidence)
class_ids.append(class_id)
x, y, w, h = prediction[0].item(), prediction[1].item(), prediction[2].item(), prediction[3].item() #获取有效信息
xmin = x - (w / 2) #由于NMSBoxes缘故,需要从中心点得到左上角点
ymin = y - (h / 2)
box = np.array([xmin, ymin, w, h]) #记录数据
boxes.append(box)
indexes = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.5) #NMS筛选
detections = []
for i in indexes:
j = i.item()
detections.append({"class_index": class_ids[j], "confidence": confidences[j], "box": boxes[j]}) #储存获取的目标名称和框选位
for detection in detections:
box = detection["box"]
classId = detection["class_index"]
confidence = detection["confidence"]
if(confidence<0.88): #再次过滤
continue
else :
push.append(classId)
rx = img.shape[1] / (img_re.shape[1] - dw)
ry = img.shape[0] / (img_re.shape[0] - dh)
img_re = cv2.rectangle(img_re, (int(box[0]), int(box[1])), (int(box[0] + box[2]), int(box[1] + box[3])), (0, 255, 0), 3)
box[0] = rx * box[0] #恢复原尺寸box,如果尺寸不变可以忽略
box[1] = box[1] *ry
box[2] = rx * box[2]
box[3] = box[3] *ry
xmax = box[0] + box[2]
ymax = box[1] + box[3]
img = cv2.rectangle(img, (int(box[0]), int(box[1])), (int(xmax), int(ymax)), (0, 255, 0), 3) #绘制物体框
img = cv2.rectangle(img, (int(box[0]), int(box[1]) - 20), (int(xmax), int(box[1])), (0, 255, 0), cv2.FILLED) #绘制目标名称底色填充矩形
img = cv2.putText(img, str(label[classId])+' '+str(int(confidence*100))+'%', (int(box[0]), int(box[1]) - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0)) #绘制目标名称
cv2.imshow("d", img_re)
cv2.imshow('w',img)
cv2.waitKey(0)
以上推理函数编写已经完成。以下是运行主程序:
#********************主程序***********************#
def MainToSolve(infer):
img = cv2.imread("boundtest.jpg") #如果需要实时,只需要将输入img变成从摄像机抓取的帧画面
main(img,infer)
#从这里开始,初始化以及推理
Init()
MainToSolve(infer_request)
当我们运行该程序时,会得到如图 1.3.1。

图 1.3.1 图像结果
如图所示,YOLOv5 模型通过转换成IR模型,再经过 PPP 预处理以及 Runtime 引擎,成功运行在 AlxBoard。整体上性能非常不错。
1.4
模型应用场景简述:
原先的 Pytorch 模型只完成了图像分类的任务,本文通过 YOLOv5 训练并运用 OpenVINO 技术来完成了目标检测这一更高难度的任务,通过得到物块的位置我们就能更好的给予小车底盘信息,用来精确对物块进行任务(抓取或是推到)
搭载 AlxBoard 的四轮小车如图 1.4.1。

图 1.4.1 AlxBoard 智能小车
通过此小车,我们还能发挥想象去做更多的应用场景,通过 OpenVINO 赋能小车系统,我们还能实现例如空对地无图导航等等更具有特色的应用场景。
1.5
结论
自训练 YOLOv5 模型在通过 OpenVINO Model Optimizer 模型优化后用 OpenVINO PreProcess 先进行预处理,处理后用 OpenVINO Runtime 进行推理,推理过程简单清晰。推理整个过程由于加入了 PPP(PrePostProcess) 的预处理技术,整个处理可以放在 iGPU 上运行,有效减少 CPU 的开销。通过 OpenVINO 技术优化后的模型优势明显,加上 AlxBoard 开发者板,能让我们迅速构建起智能小车来验证系统。
OpenVINO 简单易上手,提供了健全的文档和 OpenVINO Notebooks 范例,帮助开发者专注在自身应用的实现和算法搭建。
-
龙哥手把手教你学视觉-深度学习YOLOV5篇2021-09-03 0
-
怎样使用PyTorch Hub去加载YOLOv5模型2022-07-22 0
-
英特尔BOOT Loader开发套件-高级嵌入式开发基础2011-12-07 780
-
基于C#和OpenVINO™在英特尔独立显卡上部署PP-TinyPose模型2022-11-18 2510
-
在英特尔独立显卡上部署YOLOv5 v7.0版实时实例分割模型2022-12-20 4052
-
在C++中使用OpenVINO工具包部署YOLOv5模型2023-02-15 4635
-
使用旭日X3派的BPU部署Yolov52023-04-26 878
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8目标检测模型2023-05-12 1307
-
AI爱克斯开发板上使用OpenVINO加速YOLOv8目标检测模型2023-05-26 1234
-
在AI爱克斯开发板上用OpenVINO™加速YOLOv8-seg实例分割模型2023-06-05 996
-
使用OpenVINO优化并部署训练好的YOLOv7模型2023-08-25 1507
-
基于OpenVINO在英特尔开发套件上实现眼部追踪2023-09-18 753
-
基于英特尔开发套件的AI字幕生成器设计2023-09-27 870
-
使用英特尔哪吒开发套件部署YOLOv5完成透明物体目标检测2024-11-25 205
全部0条评论

快来发表一下你的评论吧 !
