

基于MCU的设备开发安全的RTOS
描述
作者:Ralph Moore
现在,网络钓鱼、弱密码、身份验证不足和特权执行不力等唾手可得的成果正在消失,黑客被迫寻找渗透公司网络和设备的新方法。目前连接到企业网络的大量完全易受攻击的设备为此提供了肥沃的机会。到目前为止,设备安全性已经得到了很多讨论,但很少采取行动。这种情况即将改变。
在过去的几年里,我们一直致力于为基于MCU的设备开发安全的RTOS,特别是Cortex-v7M和v8M。该RTOS具有许多创新功能来遏制和限制安全漏洞。本文的目的是介绍这些功能,并说明通过使用它们可以实现高度安全的设备。
SecureSMX 基于 smx 实时、多任务内核,该内核在过去 30 年中为数百个嵌入式系统提供了可靠的操作。它提供灵活而广泛的解决方案,使OEM能够在合理的时间和成本限制内将有效的安全保护整合到其嵌入式和物联网设备中。这种安全性的基础是隔离分区,这对于此类系统来说并不容易实现。分区有许多优点:
允许硬件强制分离特权和非特权代码,并控制对系统服务、数据、内存区域和 I/O 寄存器的访问。
使其他保护成为可能,例如运行时限制和限制对对象的访问。如果没有硬件强制分区,则可以轻松绕过此类限制。
允许将稀缺的程序员人才集中在加强最关键的分区上。
防范零日漏洞。这些通常卖得很多钱,是国家安全机构严密保护的秘密[参考文献1]。但是,黑客也可以使用未修补的已知漏洞,因为无论哪种方式,他最终都会进入一个孤立的分区,在不碰到绊线的情况下,他可以做的事情受到很大限制。如果非关键分区已被渗透,系统将继续执行其基本功能。这使安全团队有时间解决问题,而不是总是追赶。
使用定义良好的接口的模块化代码的良好编程实践的硬件实施。这不仅可以生成更高质量的代码,还可以缩短集成和调试时间。
仅分区恢复。当黑客触发众多检查中的任何一项时,会立即发生内存管理故障 (MMF) 异常。这可用于关闭分区,然后重新初始化它。这比重新启动整个系统更可取,因为它不会停止正常运行。
仅分区更新。如果没有其他移动,则可以单独更新分区。这样就无需将任务关键型代码暴露给内部攻击。更新仅限于受到攻击的易受攻击的分区。旧代码和受信任的代码通常已经过详尽的测试,很少需要更新。内部攻击是一个比人们普遍认为的更大的问题[参考文献2]。
没有安全性是完美的。但是,为系统添加安全性可以减轻损害和潜在责任。
目标
这种安全的实时操作系统既旨在促进现有系统的安全改进,也旨在作为新系统的安全基础。开发人员可以根据需要使用尽可能多或尽可能少的功能。易受攻击的代码(如开源 [Ref 3] 或网络堆栈和新开发的软件包)可以通过一系列定义明确的步骤与系统的其余部分隔离。隔离可以根据需要尽可能强,如果需要,可以施加限制。同时,系统的其余部分可以继续按原样运行,基本上保持不变。因此,对于开始被黑客入侵的现有系统,有一个解决方案。
操作
SecureSMX利用Cortex-v7M和v8M架构的所有硬件安全功能,除了它不需要TrustZone。重要的是将操作硬件分离为处理程序模式 (hmode)、特权任务模式 (pmode) 和非特权任务模式 (umode)。内存保护单元 (MPU) 用于限制每个任务可以访问的内存。SVC 指令用于允许 umode 任务访问系统服务。背景区域 (BR) 仅在 hmode 中使用。
目前典型的嵌入式系统完全在hmode下运行。第一步是将代码分为在 pmode 中运行的任务(ptasks)和系统服务(例如 RTOS)、异常处理程序和在 hmode 中运行的 ISR。任务在启用 MPU 和禁用 BR 的情况下运行。每个 ptask 都可以有一个唯一的内存保护阵列 (MPA),当 ptask 开始运行时,该阵列会加载到 MPU 中。或者,任务可以使用默认的 MPA。此时,任务之间会获得一些隔离,具体取决于每个任务具有自己的 MPA 的程度以及 MPA 区域定义的紧密程度。为了实现更大的隔离,可以将任务移动到 umode。然后,系统的所有其余部分都受到硬件强制 pmode 屏障的保护。
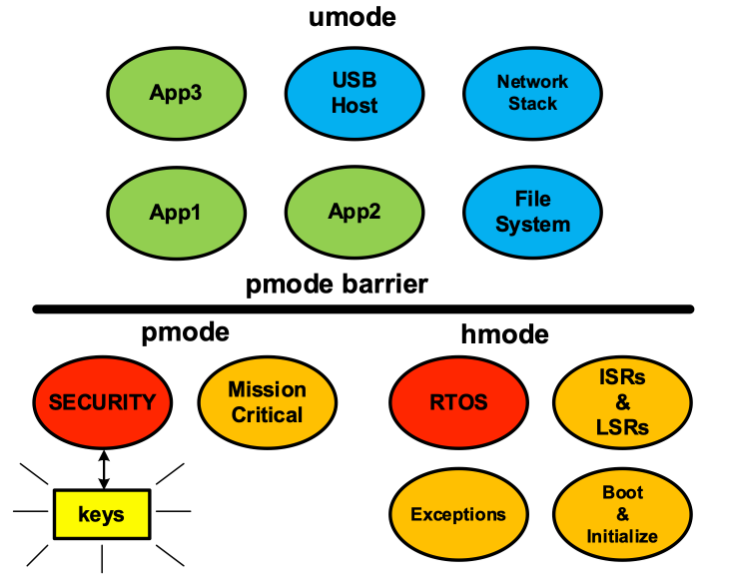
分区应用程序
什么是分区?
分区由它们包含的一个或多个任务定义。他们没有控制块。通常,分区对应于系统的逻辑部分,通常称为模块,例如文件系统。像这样的分区通常有一个顶级任务和一个或两个子任务来帮助它。但是,根据特定系统,分区可以由多个顶级任务组成,并且可以包括多个模块。例如,在给定的系统中,所有中间件或所有 utask 都可以合并到单个分区中。分区灵活性允许在投入的工作量和实现的安全性之间实现最佳权衡。
v7M 分区
众所周知,Cortex-v7M MCU 的分区很难实现,因为 v7M MPU 要求每个区域大小是 7 的幂,并且要与其大小保持一致。显然,这可能导致严重的内存浪费,并导致v4M MPU在很大程度上被嵌入式软件社区拒绝[参考文献《》]。对于安全MCU设计来说,这是一个不幸的挫折。但是,我们发现了许多克服此问题的方法,这些方法已合并到我们的新RTOS中。以下段落详细描述了这些方法,以便呈现令人信服的图片。
定义节
系统中的每个任务都需要为其使用的每个活动 MPU 插槽提供一个区域。通常所有 MPU 插槽都处于活动状态,因此每个任务需要 8 个区域。尽管某些区域可能在任务之间共享,但通常需要为典型系统定义大量区域。区域的定义始于在代码中使用杂注 [脚注 i] 来定义包含在区域(例如.sys_data)中的部分(例如.sys_bss和.sys_data)。区域的各个部分可能分布在多个模块中,但链接器将区域的所有部分合并到单个区域块中。
链接器命令文件
我们开发了一种简单的方法来创建 v7M 链接器命令文件。在其顶部,系统的所有区域的大小都以十六进制定义。要成为 1 的幂,区域大小必须只有一个非零数字,并且该数字必须是 2、4、8 或 5。因此,很容易避免区域大小错误。在区域大小下方,每个区域块的大小 = region_size*8/6、8/7、8/8 或 8/1,其对齐方式 = region_size,以及它包含的部分。这种方法的一个很好的功能是,在开发过程中,当链接器报告某个区域已被超出时,将其大小提高 8/5 或上升到下一个 8*8/8 的幂(如果它已经是 《》/《》)是一件简单的事情。

模板、内存保护阵列和任务
海洋保护区模板
每个任务都有一个内存保护阵列、MPA 或默认 MPA,在调度任务时将其加载到 MPU 中。任务的 MPA 是在创建任务后从其 MPA 模板生成的。任务可以有自己的 MPA 模板,也可以与其他任务共享一个模板。MPA 模板是使用特殊宏定义的,这些宏允许每行定义一个由 RBAR、RASR 和 region_name组成的区域。(region_name仅在调试期间使用。子区域禁用是根据区域块大小自动生成的(例如,如果区域块大小 = region_size*5/8,则设置 SRD 5、6 和 7)。这避免了用户的复杂性,同时最大限度地减少了区域大小。
缩小区域之间的差距
链接器按指定的顺序将区域块分配给内存。这可能会导致块之间出现较大的间隙,从而浪费大量内存。为了解决这个问题,运行 MPUPacker™ 以找到区域块的最佳排序。然后更改顺序以匹配链接器命令文件中,并再次运行链接器。为了帮助将代码和数据分配给区域,可以运行 MPUMapper™ 来修改映射文件以显示每个符号所在的区域。这在开发过程中非常有帮助,可以修复 MMF 并检查系统是否分区良好。
一般来说,我们发现内存浪费可以保持在 20% 以下,通常是 10%。如果需要,还可以使用其他方法来减少内存浪费。但是,如果有足够的内存,则在分区之间分布未使用的内存是有利的,因为这有助于仅分区更新。
v8M 分区
Cortex-v8M 解决了区域问题,只要求区域是 32 字节的倍数,并在 32 字节边界上对齐。因此,上述许多措施对于v8M不是必需的,尽管基本方法是相同的。然而,v8M 引入了一个新问题:如果分区重叠,就会发生 MMF。这为任务堆栈、PMSG 和动态区域创造了一个致命弱点。可以通过从与主堆不同的堆中分配它们来解决,但需要努力避免被这种不必要的体系结构缺陷所捕获。
来自 umode 的系统服务

来自 umode 的系统服务
ptasks 可以进行直接系统调用,因为它们在其 MPA 中具有sys_code和sys_data区域。这些区域将替换为 utask 的 ucom_code 和 ucom_data,这些区域无法进行直接的系统服务调用。相反,utasks 必须使用由 SVC n 指令触发的 SVC 异常,其中 n 表示 256 个服务调用之一。utask 代码中包含了一个特殊的头文件,用于将服务调用映射到具有相似名称的 shell 函数。枚举定义 n 的值,SVC 处理程序 SVCH() 使用相同顺序的跳转表跳转到所需的服务调用。对于每个调用 SVC n 的系统服务,ucom_code都有一个 shell 函数,其值由枚举定义。此系统可以轻松添加或删除服务呼叫。
当 SVC n 执行时,它会导致创建异常帧,切换到 hmode,切换到主堆栈,并启动 SVCH()。SVCH() 从异常帧重新加载 r0-r3,将参数 5 及以上从任务栈复制到主栈,并通过跳转表(在 sys_code 中)调用系统服务。当系统服务完成时,SVCH() 会进行一些调整,然后将异常返回到调用点。返回值(如果有)在 r0 中。除了生成故障异常之外,这是 utask 可以在 hmode 中访问代码的唯一方法。
来自 umode 的系统调用开销相当小,并且不会显著影响系统性能,因为系统调用不频繁。明显有害的系统调用无法通过 SVC n 使用。在某些情况下,从 umode 调用时,系统调用的有害部分会被禁止。此外,某些服务(如中断启用和禁用)无法从 umode 工作。中断禁用和启用必须替换为中断掩码和取消掩码,并提供一种方法来限制可以从 utask 中屏蔽或取消屏蔽哪些 IRQ。
通常,umode 分区将仅使用少量的系统服务调用。因此,提供了一种方法,允许为分区定义自定义枚举、自定义跳转表和自定义 shell 函数。这通过最大限度地减少对ucom_code的访问来改善隔离。一般来说,标准的枚举、跳转表和 shell 函数应该缩减到 umode 分区实际需要的,从而节省内存并提高安全性。
虽然没有必要,但 ptasks 也可以访问系统服务的 SVCH(),而不是直接调用。这在 pmode 到 umode 的转换过程中提供了一个步骤。
任务 vs. u任务
支持 PTASKS 主要是为了简化将分区从 PMODE 移动到 uMode 的过程。但是,它们可以与提高系统可靠性的utask一样有效。将任务转换为 ptasks 后,通过分配 MPA,可能会出现潜在的错误,例如未初始化的指针、堆栈溢出等。
为了安全起见,utasks比ptasks更好。这是因为如果一个任务被穿透,只需要一条指令就可以关闭MPU。这在 umode 中是不可能的,因此 umode 提供了更强的安全性。此外,pmode 屏障使得几乎不可能从 umode 访问 pmode 和 hmode。
门户
为了实现完全分区隔离,有必要引入门户。这是因为函数 API 要求函数本身可供用户访问,这违反了隔离。
门户提供间接 API,用于将一个分区中的服务与其他分区中的调用方隔离。调用照常进行,但它们使用 smx 消息来指示服务器任务执行服务并通过门户返回结果。
SMX 消息由链接到包含实际消息的数据块的消息控制块 (MCB) 组成。消息可以发送到任务可以等待的消息交换。可以从消息等待的消息交换接收它们。消息可以具有优先级,并且可以按优先级顺序在交易所排队。因此,优先级较高的消息可以绕过优先级较低的消息。交换处的邮件队列可以用作服务器的工作队列。
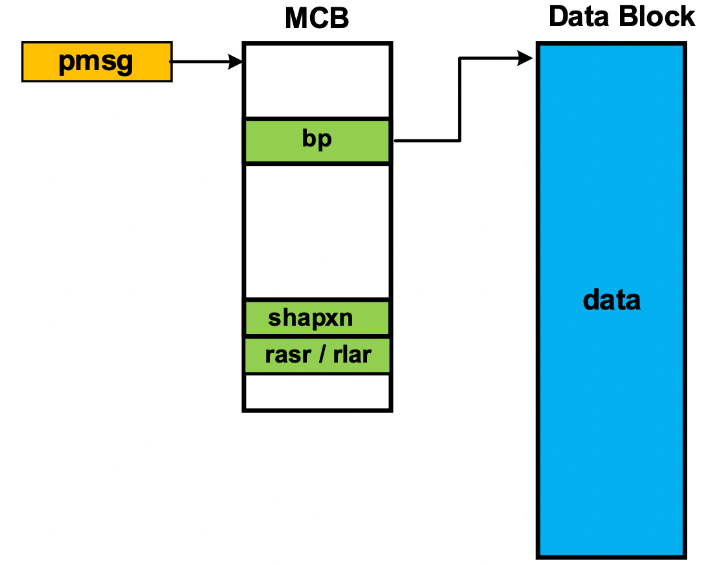
受保护的邮件 (PMSG)
对于门户,区域信息将添加到消息中,从而创建所谓的受保护消息 pmsg。当收到 pmsg 时,其区域将加载到 MPU 中的空插槽中,以及接收任务的 MPA。这允许任务访问数据块,但不能访问sys_data中的 MCB。对于门户,接收任务称为服务器,发送任务称为客户端。通常,一台服务器可能有许多客户端。客户端可以给 pmsg 一个优先级,当服务器接受 pmsg 时,这个优先级将传递给服务器。
创建门户时,将为其提供允许访问门户的客户端列表。创建过程初始化服务器控制结构,并将门户交换句柄和门户名称加载到每个客户端结构中。只有这些客户端可以访问门户,因为只有他们知道将 pmsg 发送到哪里。
提供两种类型的门户:
免费消息门户

免费消息门户
For this portal when a message is sent, the exchange becomes its owner, and then the server becomes its owner when the message is received. When sent, the pmsg region is cleared in the MPU and in the client’s MPA. Thereafter, the client cannot access nor alter the message. When the server is done, it sends the pmsg to a reply exchange from which the client may retrieve it. Once sent, the server can no longer access the pmsg. Free message portals are intended for transfer of small amounts of data and commands.
Tunnel Portal

隧道门户
隧道门户旨在快速发送大量多块数据。在这种情况下,客户端保留对 pmsg 区域的所有权和访问权限。数据块成为客户端和服务器分区之间的隧道,从而允许发送和接收多个数据块。信号量用于协调操作。传输完成后,门户关闭,永磁同步器释放。
操作
对于这两种类型的门户,头文件将服务器函数 API 映射到名称略有不同的 shell 函数。此头文件包含在进行服务器函数调用的每个客户端文件中。每个 shell 函数创建一个包含函数 ID、参数和数据 的 pmsg,并将 pmsg 发送到门户交换。服务器接收 pmsg 并使用 switch 语句将 ID 转换为函数调用,进行调用,然后将函数返回回 shell 函数,shell 函数将其返回给应用程序。所有这些都对应用程序是透明的,只是操作速度较慢。
由于切换到服务器任务,门户操作可能与直接调用有很大不同。如果 pmsg 的优先级高于客户端,则服务将抢占并立即运行。这最像是直接服务呼叫。如果 pmsg 具有相同的优先级,则在客户端挂起之前,服务不会运行。如果 pmsg 的优先级较低,则服务将在将来的某个时间运行。当服务是某些低优先级功能(如事件日志记录)时,后者很有用。
免费消息门户提供 100% 隔离;隧道门户仅提供略少。
性能
性能很好,因为永磁同步发电机操作不需要复制永磁同步发电机数据块(与基于 MMU 的系统不同)。实际上,数据块可以用作客户端中的工作缓冲区,以便进一步减少数据复制。通过增加 PMSG 数据块的大小,性能得到了极大的提高。
以下是将我们的文件系统 (FS) 写入同一处理器(STM32F746,Cortex-M7)上的 SD 卡的测量性能(KB/秒),与两者都没有。它还显示了无复制模式的轻微增益,其中客户端使用入口缓冲区作为工作缓冲区。
FS+SD 7969 / 4855
FS+SD+portal no copy 6788 / 4544 85% / 94%
FS+SD+portal copy 6685 / 4419 84% / 91%
使用 MPU 和门户将读取性能降低了 16%,将写入性能降低了 9%,直接在客户端中使用门户缓冲区(无复制)时略有改进。
堆
现代嵌入式系统比过去更频繁地使用堆。但是,如果分区共享单个堆,则无法实现隔离,因此需要多个堆。

堆堆 箱结构
eheap 是我们复杂的堆管理器,包含在 SecureSMX 中。它专为嵌入式系统而设计;它支持多个堆,并使用 bin (如 DLMALLOC)来加速分配。与 dlmalloc 不同,每个堆的箱数和箱大小是可自定义的,以满足应用程序要求。例如,如果分区中经常需要 256 的块大小,则可以创建仅包含此大小的 bin 。此外,eheap 可以分配两个对齐块的幂,并且可以分配 v7M 区域。这些对于动态区域特别有用,这是此安全 RTOS 的一项功能。eheap 的多任务版本提供每堆互斥锁,以避免该堆的访问冲突。
大多数任务堆栈、受保护的消息 (pmsg)、受保护块 (pblk) 和许多系统结构都是从 v7M 系统的主堆中分配的。对于 v8M 系统,由于其非区域重叠要求,其中一些对象可能需要从另一个堆中分配。如果需要,可以为需要它们的分区创建自定义堆,例如用C++编写的分区。Eheap 可以为小型C++对象合并小块池,以加快操作速度。通常,分区堆比主堆简单得多,也小得多。此外,eheap 支持自动扫描和修复每个堆及其 bin 中的断开链接。
调度程序回调
大多数 RTOS 都提供 EXIT 和 ENTER 回调。前者可用于在任务挂起时保存扩展状态,后者可用于在任务恢复时还原扩展状态。smx 还提供 START 和 DELETE 回调。当任务首次开始运行时,前者可用于执行任务初始化并获取任务所需的资源。删除任务后,后者可用于释放资源并进行任务清理。由于 DELETE 通常是 switch 语句中低于 START 大小写的情况,因此很容易确保不会遗漏任何内容。因此,分区可以循环打开和关闭而不会泄漏,以支持仅分区恢复。
运行时限制
不幸的是,即使是完全分区隔离也不足以防止黑客攻击。即使他无法离开分区,黑客也可以从分区内造成大量损害。一个简单的攻击是将分区中的任务放入无限循环中。然后,将阻止所有同等或更低优先级的任务运行。这最终可能会使任何系统崩溃。为了防止这种情况,有必要使用任务运行时限制。
不幸的是,在实时系统中,运行时间限制既是诅咒,也是祝福——例如,我们不希望在紧急情况下(例如当起重机即将倾覆时)将关键任务戴上手铐。但是开发人员很难估计避免这种灾难可能需要多少运行时间。因此,允许重要任务在没有运行时限制的情况下运行。这一点,加上他们的高优先级,确保他们可以根据需要运行完成工作,即使在极端情况下也是如此。
受信任度较低的任务使用计数器分配运行时限制。在帧开始时,将清除所有计数器。事实证明,时钟周期分辨率太粗糙,因此使用 CPU 时钟。每次运行任务时,都会确定它使用的时钟数并将其添加到其计数器中。如果这超出了任务的运行时限制,则任务将在门信号灯上挂起,无法再运行。在每次刻度时,当前任务的计数器都会更新,如果它超过其运行时限制,则任务将在门信号量上挂起。
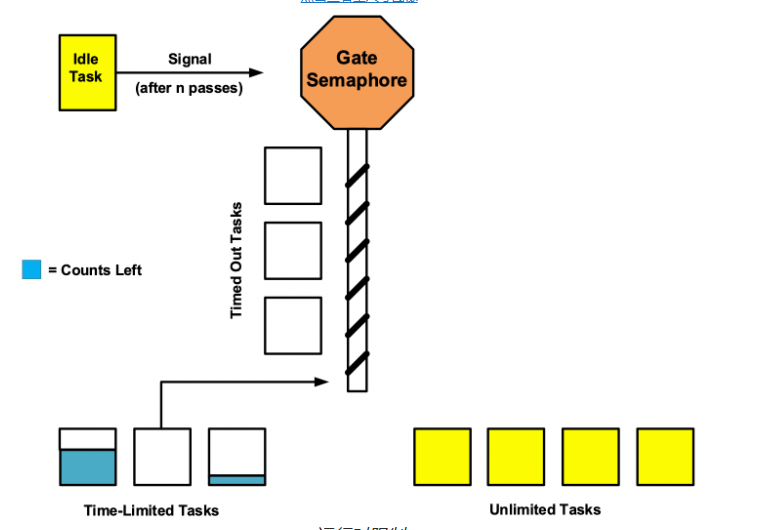
运行时限制
在任务优先级之间取得良好的平衡已经够困难的了,这使得任务能够满足其最后期限。添加固定的运行时帧只会增加此难度。相反,当空闲任务有足够的传递来完成其工作时,我们会结束运行时帧。由于空闲任务的优先级最低,因此可确保所有任务都充分运行。然后,门信号灯发出信号,并恢复所有等待任务,并清除其计数器。此外,具有相同优先级的任务以与挂起相同的顺序恢复。这样可以避免任务运行中出现可能导致问题的较大间隙。
子任务共享其顶级父任务的 [脚注 ii] 运行时限制和计数器。如果超出限制,子任务将立即挂起。仅当父项及其其他子项尝试在此之后运行时,它们才会挂起。为任务系列分配运行时限制比尝试为每个任务分配运行时限制要容易得多,因为每个任务是生成的。
令 牌
在第二次世界大战期间,家庭收到了用于肉类的红色代币,用于鱼类的蓝色代币和用于手推车的银代币。通过这种方式,我们的政府控制了消费。同样,我们需要控制分区可以使用多少每个资源以及分区如何使用该资源。我们的实时操作系统为此目的使用令牌。
句柄是存储对象地址的内存位置,例如任务 - 即它是一个特殊的指针。令牌是句柄的地址。句柄是在链接时创建的,因此它们的地址在运行时是已知的。有两种类型的令牌:HI 令牌允许创建、删除、修改和访问对象,LO 令牌仅允许访问对象(例如信号量测试和信号)。程序员为每个任务编译一个标记列表,并在创建任务后将其分配给该任务。如果未分配令牌列表,则任务不需要令牌即可访问或修改对象。后者对于恢复任务等任务是必需的,它使受信任任务的工作更简单。
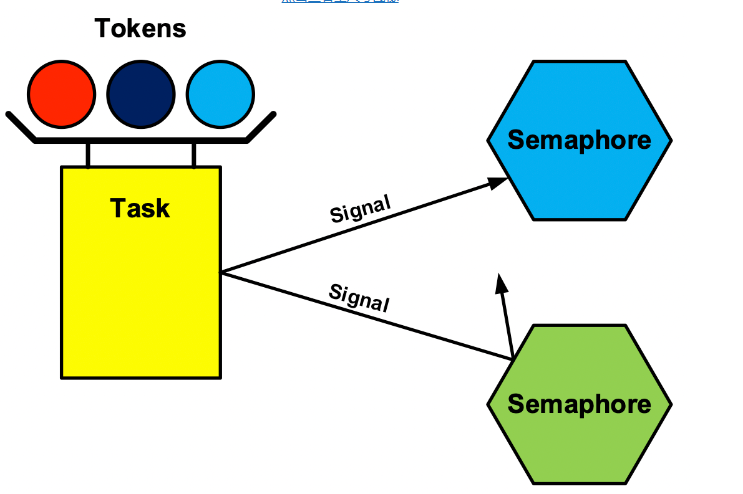
令牌 控制信号量访问
黑客可以从分区内部做的阴险的事情之一是一遍又一遍地创建相同的对象,直到对象控制块池耗尽。然后,没有其他任务可以创建该类型的对象。这被阻止如下:首先,黑客使用的任务必须具有对象的 HI 令牌。其次,一旦创建,在删除对象之前无法重新创建对象。
另一种可能的攻击是猜测一个句柄并用它来制造麻烦。例如,可以向另一个分区中的信号灯发出信号,从而导致该分区中的任务在不应该运行时运行。通过要求该对象的令牌来阻止此操作。
除了令牌之外,在使用之前,还会验证所有句柄参数是否为有效句柄。每个句柄都经过范围检查,并检查其 cbtype 字段。这可以防止黑客在系统服务调用中使用无效对象。
ISR 问题
Cortex-M 中一个严重的架构缺陷是 ISR 在 hmode 下运行。大多数 RTOS 都使情况更加复杂,它们允许从 ISR 调用内核服务。这些共同为黑客创造了一个大目标。这个目标特别诱人,因为黑客攻击它会让他进入 hmode,在那里他可以关闭 MPU 并访问他喜欢的任何内容。
SMX 始终支持不同的设计理念,其中 ISR 最小化,大多数中断处理推迟到链路服务例程 (LSR)。它们按调用的顺序运行,并排在所有任务之前。LSR 不受优先级反转问题的影响,因此比任务更适合延迟中断处理。此外,LSR 开销要少得多。当处理时间不重要时,LSR 可以简单地向信号灯发出信号,延迟中断处理任务在其中等待。最小化 ISR 大小既可以减小目标大小,又可以让 ISR 程序员更专注于使代码难以破解。
有三种类型的 LSR 可用:tLSR、pLSR 和 uLSR。tLSR 是受信任的 LSR。它们在hmode中运行,开销非常低。它们应尽可能简短,例如仅发出信号量。pLSR和uLSRs被称为安全LSR。每个都有自己的堆栈和自己的MPA,并且表现得像一个微任务。从 LSR 队列调度时,LSR 的 MPA 将加载到 MPU 中,其堆栈将成为操作堆栈。因此,安全 LSR 可以在它们服务的分区中运行,这会将中断处理的一小部分以外的所有内容都带到它所属的分区中。这对uLSR来说是一个巨大的收获。
开发人员通常编写进行内核调用的长 ISR。安全 LSR 允许将尽可能多的代码移动到 LSR 中,然后将 LSR 移动到其相关分区中。因此,如果黑客闯入ISR代码,而不是处于hmode状态,他发现自己处于隔离的umode分区中并受到其限制。
需要注意的一件有趣的事情是,安全的 LSR 可能使用相同的 MPA 作为分区中的任务,或者它可能更像一个子任务,并且具有一些共享区域和一些唯一区域(例如 IO)。安全LSR具有非常小的控制块,通常需要非常小的堆栈。此外,它们在 ISR 和任务之间优先运行。因此,它们提供了一种有趣的IO处理方法,比通常的ISR方法更安全。
SMX感知
smxAware 为 IAR C-SPY 调试器提供内核感知。当与 SecureSMX 一起使用时,添加了 MPU 和 MPA 显示器。这使得在跟踪 MMF 时更容易查看区域大小和属性。此外,门户操作显示在事件时间线图中,MPU 区域显示在内存映射概述图中。
事件监控
监视大量内核事件,例如服务调用、ISR 运行、LSR 运行、任务操作、错误等。每个事件的相关信息都存储在事件缓冲区 EVB 中。此外,还可以定义和记录用户事件。可以过滤日志记录,以便 EVB 不会太快填满。EVB 可以定期上传到安全监控站点,在该站点中,特殊软件会查找可能表明攻击正在进行中的异常行为。如果是这样,安全控制可以采取适当的操作,例如关闭分区。
监控大型系统所有元素的运行可能是阻止逃避安全机制并缓慢渗透计算机网络的高度复杂攻击的唯一方法。
目标
在最优系统中,尽可能多的代码已经从 pmode 移动到彼此高度隔离的 umode 分区,门户用于分区间通信,所有不受信任的任务都是运行时和令牌限制的,延迟中断处理在安全的 LSR 中完成,任务关键型代码和数据受到 pmode 屏障的双重保护。
虽然这个目标对于新设计来说是可以实现的,但对于现有设计来说不太可能是可行的。将所有不受信任的代码移动到单个 umode 分区并对其应用一些限制可能是一个适当的解决方案。SecureSMX 专门设计用于提供实施部分解决方案的灵活性。它还旨在允许渐进式改进,其中安全团队一次修复一个问题,从而在不破坏银行的情况下逐步实现安全性改进。
重要的是要认识到,仍然可以使用其他安全措施,例如信任根、安全启动、安全更新、加密和代码改进。相反,它提供了坚实的安全基础,并提供了许多处理安全问题的新选项。
将应用程序移植到 SecureSMX
为了简化现有应用程序移植到我们的安全实时操作系统,FRPort 和 TXPort 包含在其中。它们提供了移植功能,可将应用程序中使用的 90% 以上的 FreeRTOS 和 ThreadX 服务调用移植到等效的 smx 服务调用。计划建设更多港口。尝试在其他 RTOS 上运行 SecureSMX 是行不通的,因为它与 smx 的富内核功能紧密绑定,而这些功能在其他 RTOS 中是缺失的。将应用程序移动到它应该导致更好的操作,并允许访问上面讨论的所有安全功能。
未来
到目前为止,许多设备已被黑客入侵,但黑客主要关注网络钓鱼等唾手可得的果实,以进入计算机网络。然而,随着公司采用更好的安全软件和更好的安全实践,唾手可得的果实开始消失。如前所述,下一个主要黑客目标可能是已经连接到计算机网络的数千台未受保护的设备。这些很容易被黑客入侵。
设备供应商的高层管理人员需要决定他们是想现在开始采取谨慎的步骤,还是稍后雇佣一支军队来处理对其设备的攻击。法院将来可能会裁定安全性不足构成疏忽,因此设备制造商将面临损害赔偿[参考文献5]。这可能会使许多公司倒闭。即使这种情况没有发生,可证明的安全性也可能成为许多类型设备的主要销售点。
纵观广泛的软件图景,在大多数嵌入式系统中,可能只有大约10%的软件完成关键工作。此代码是公司业务的本质。它可能写得很严格,经过彻底测试,经过现场验证,因此不太可能改变。剩下的 90% 的代码是第三方、开源和新开发代码的混合体,并且可能带有许多漏洞。如果不进行分区,此代码中任何地方的黑客攻击都会暴露整个系统,从而助长赎金攻击和关键数据的盗窃。像这样让公司的胆量变得脆弱是没有意义的。
此外,应该预计内部攻击将变得更加普遍。当提供大笔资金时,员工的忠诚度可能是可以协商的。任务关键型代码是公司皇冠上的明珠。它应该被锁起来,除了少数高度信任的员工之外,所有人都无法访问。由于任务关键型代码可能不需要更新,因此不需要将其包含在仅分区更新中。如果更新中不包含任务关键型代码,则无法篡改,这为避免灾难性攻击提供了一些希望。
结论
我们的新RTOS旨在提供一套灵活的工具和结构,以提高现有基于MCU的系统以及新系统的安全性。它允许以最少的受信任的遗留代码修改来做到这一点。其固有的灵活性允许首先解决最重要的问题,从而逐步提高系统安全性。
如果将 SecureSMX 用作新系统的基础,则很可能可以在很少或没有进度或开发成本增加的情况下实施强大的安全性。这是因为它提供了设计实践的硬件实施,经证明可以减少集成和调试时间。而下游的回报,在安全保护方面,是巨大的。对于上面介绍的所有功能,SecureSMX 与 SMX 的代码大小增加约为 20 KB。考虑到典型MCU上的大片上闪存,以及与典型应用代码的大小相比,这是可以忽略不计的。一个更大的问题是节省宝贵的片上SRAM,我们提供了工具和技术来最大限度地减少由于v7M架构上的对齐而导致的浪费,如减少区域之间的差距一节所述。
编辑:黄飞
-
risc-v的mcu对RTOS兼容性如何2024-05-27 1210
-
微控制器MCU常用RTOS盘点2016-10-27 3805
-
MSP432 MCU发挥RTOS所具有的优势2018-09-10 3592
-
嵌入式软件设计人员可以做些什么来提高设备的安全性2021-11-08 1168
-
PX5的ARM TrustZone支持让嵌入式系统变得更加安全!2023-05-18 333
-
技术干货:MCU专用RTOS种类盘点2015-05-08 10695
-
如何优化基于MCU的RTOS的设计和开发2020-05-27 2735
-
优化基于MCU的RTOS的设计和开发的方法2020-10-02 3051
-
瑞萨电子主流32位MCU扩展Microsoft Azure RTOS嵌入式开发套件2021-06-18 2962
-
RTOS是什么,裸机开发的详细介绍2022-03-07 8613
-
如何选择正确的RTOS2022-08-11 1612
-
RTOS:物联网设备的基础和第一道防线2022-08-24 1095
-
RTOS开发最佳实践2024-08-20 1541
-
保姆级教程 | i.MX 93开发板适配Zephyr RTOS全解析2026-04-28 11212
-
使用IAR Arm工具链开发和调试Zephyr RTOS2026-05-25 790
全部0条评论

快来发表一下你的评论吧 !
