

多核SoC的系统结构设计
电子说
描述
一直以来,一个通用处理器加上硬件逻辑是SoC设计的主流结构。
在一些需要大量数据处理的应用中,这样的结构并不能满足要求。
实际上,由于不同的任务可在很大的程度上互相独立运行,如音频和视频处理及网络协议处理等,可以将具有内在执行并行性的复杂任务分解为一系列紧密联系的子任务,并行实现。
多核SoC(Multicore SoC)或多处理器结构的SoC(MPSoC,Multiprocessor SoC)可以完成这样一个复杂任务分解到多个内核中去执行的任务。
由于不同的内核可以执行不同的子任务,多核结构在一个周期内可以执行多个指令。同样的任务使用这种并行处理与使用单个处理资源串行处理的情况相比,整个系统应用的性能有了很大的改进。
另外,多核结构的设计可以复用现有的成熟单核处理器作为处理器核心,从而可缩短设计和验证周期,节省研发成本,符合SoC设计的基本思路。多核结构是未来SoC发展的一个趋势。
现在很多产品都是以Arm作为一个主核,以及几个附加的核,同时使用RISCV来实现很多定制化的小核。
1 可用的并发性
数字电子产品的进步取决于芯片或系统设计师使用许多并行的晶体管来高效地实现系统功能的能力。设计师可以利用许多不同级别的并发性,通常这些级别的并发性可归纳为3种:
• 指令级并行性、
• 数据级并行性
• 任务级并行性。
指令级并行性(ILP,Instruction Level Parallelism)利用指令之间的无关性,使得多条指令可以同时执行,改变传统串行执行指令造成的较大延时,提高指令和程序的执行效率。
最常见的指令并行是利用指令流水线保证多条相互无关的指令重叠执行不同的指令流水阶段,从而提高指令执行的吞吐率。
为了进一步发掘指令级并行性,超长指令字(VLIW,Very Long Instruction Word)和超标量(Superscalar)技术应运而生。这两类技术都是在处理器的体系结构中加入冗余的计算部件,从而允许无关指令充分利用这些计算部件,达到多操作并行执行的效果。
数据级并行性(DLP,Data Level Parallelism)是指,一组待处理的数据内部存在较为松散的依赖关系,在理论上可以对这些松散数据并行执行。处理器的单指令多数据(SIMD)并行操作结构即利用无关数据的天然并行性,同时完成对多个数据的同一操作,以达到并行处理的目的。
由于系统往往需要完成多种功能,而这些功能可以独立于系统中的其他功能,这样就引入了任务级并行(TLP,Task Level Parallelism)的概念。例如,手机系统中的用户界面、视频处理、音频处理、无线信道处理等功能相互独立,可以成为并行处理的任务。任务级并行性可以从原本的一个串行任务中提取出来。通用的提取方法并不存在,但合适的工具和功能块能帮助发现隐藏的任务并行性。与前两类并行性相比,任务级并行性对于结构设计师更为重要。
2 多核SoC设计中的系统结构选择
对于一个多核SoC的系统结构设计,需要重点考虑对处理器的选型、处理器间的互连结构及存储器的共享方式等方面,而这些选择可以通过对以下几个主要问题的考虑来决定。
1.处理器与存储器结构
多核结构可以根据处理器核的特性分为同构多核结构和异构多核结构。
在同构多核结构中,一个芯片上集成了多个相同的处理器,这些处理器执行相同或类似的任务。这样的设计在一些多线程并行度的领域(如服务器市场中)有广泛应用。
而对于一些特定的任务(如多媒体应用)中,专用硬件在性能和功耗方面会比通用处理器更有优势。因此,发展出异构多核结构,即处理器中只有一个或数个通用核心承担任务指派功能,而诸如协处理器、加速器和外设等功能都可以由专门的硬件核心如DSP来完成,由此实现处理器执行效率和最终性能的最大化。
相对于同构多核结构来说,异构多核处理器结构的设计更加困难,而且这种结构是针对某一领域做出优化,设计另一任务需要重新设计。
多核SoC中的存储层次结构对系统性能影响同样关键,因为大部分嵌入式应用程序是数据密集型的。
存储器结构的区别主要在于选择
• 何种存储器组织结构(分布式共享存储器还是集中式共享存储器),
• 存储器和处理器的互连网络类型、
• 存储器参数(缓存大小、存储器类型、存储器块的颗粒数量、存储器颗粒的大小),
• 以及如何提高存储器带宽。
2.核间通信与Cache的结构
多核处理器的各个核心执行的程序之间需要进行数据共享与同步,因此其硬件结构必须支持核间通信。
(后面聊聊核间通信的原理)
高效的通信机制是保证多核处理器高性能的关键。
在多核处理器的设计中,核间的通信可以是基于共享Cache的结构。
在这种结构中,每个处理器内核拥有共享的二级或三级Cache。Cache中保存比较常用的数据,并通过连接核心的总线进行通信。
这种系统的优点是结构简单,而且通信速度比较高。
因此,在Cache的设计中,除了Cache自身的体系结构外,多级Cache的一致性问题也是设计中需要解决的问题。
核间通信也可以通过一种基于片上的互连结构。基于片上互连的结构是指每个处理器核具有独立的处理单元和Cache,各个处理器核通过总线连接在一起,利用消息传递机制进行通信。
目前主要的总线互连方式按结构分有:
• 双向FIFO总线结构(BFBA,Bi-FIFO Bus Architecture)、
• 全局总线I结构(GBIA,Global Bus I Architecture)、
• 全局总线II结构(GBIIA,Global Bus II Architecture)、
• 交叉开关总线结构(CSBA,Crossbar Switch Bus Architecture)等。
这种结构的优点是可扩展性好,数据带宽有保证;
缺点是硬件结构复杂,且需要对软件进行较大改动。
总之,一个有效的互连结构对于多核处理器间的通信、处理器与外设的通信,以及存储器与处理器、存储器与外设的通信是很重要的。在设计核间通信时需要考虑通信速度、可扩展性及设计的复杂度等。
3.操作系统的设计
首先,操作系统的设计需要考虑多核带来的变化。
优化操作系统任务调度算法是保证多核SoC效率的关键。任务调度要考虑多个任务如何分配到处理器资源上去,以尽量提高资源的利用率,实现多个处理器之间的动态负载平衡。
其次,多核的中断处理和单核有很大不同。当多核的各处理器之间需要通过中断方式进行通信时,除处理器的本地中断控制器外,还需要增加仲裁各处理器核之间中断分配的全局中断控制器。另外,多核处理器是一个多任务系统。由于不同任务会对共享资源产生竞争,因此需要系统提供同步与互斥机制,而传统的用于单核的解决机制并不能满足多核的要求。
4.提高并行性
多核处理器要发挥多核的性能需要提高程序的并行度,单线程程序无法发挥多核处理器的优势。
通过编译优化的方法可以把单线程的代码编译成多线程的形式。
编译技术的好坏对一个程序的执行速度影响巨大。
总之,提高程序的并行性是发挥多核性能的重要一步,而通过编译技术的支持来发挥单芯片多处理器的高性能是非常重要的途径。
当处理器的内核数量上升时,一方面如果设计不合理,有可能会出现性能反而下降的问题;
另一方面功能强大的内核其结构必然复杂,功耗也难以控制。
软件开发环境和集成开发环境也是多核SoC设计的挑战之一。通常需要花费大量的时间来开发这些工具。
这里不得不感慨Linux的伟大了,感兴趣的可以在我主页搜索一下多核启动有惊喜哦。
3 多核SoC的性能评价
在设计多核SoC时,开发人员会希望预估他们所使用的核的数量与能够实现的性能提升量有多少,以此作为优化的依据。加速比(Speedup)是衡量多核SoC性能和并行化效果的一个重要指标。
加速比是指同一计算任务分别在单处理器系统和多核处理器系统中运行消耗的时间的比值。值得注意的是,加速比往往并不与处理器的数目成正比。
加速比的提升主要基于计算机体系结构设计中的一个重要原则:加快经常性事件的速度,即经常性事件的处理速度加快能明显提高整个系统的性能。对于多核SoC而言,其加速比与可并行任务占总任务的比例有关,基于这一前提,当前主要使用两种多核SoC加速比计算模型来对其性能进行评估,即阿姆达定律(Amdahl’s Law)和古斯塔夫森定律(Gustafson’s Law)。
• 阿姆达定律是在任务一定的前提下的加速比计算模型。
• 古斯塔夫森定律是在时间一定的前提下的加速比计算模型。
值得指出的是近几年来研究人员针对不同的应用领域,在阿姆达定律和古斯塔夫森定律的计算模型上进行了多方面的拓展,如考虑通信、同步和其他线程管理的开销,以及引入功耗模型等,使其更具有实用意义。
与加速比相关的另一个指标是效率(Efficiency)。正如加速比是衡量并行执行比串行执行快多少的指标,效率表示的是软件对系统计算资源的利用程度。并行执行的效率的计算公式为加速比除以使用的核的数量,用百分数表示。例如,加速比为53X,使用64个核,那么效率就等于82%(53/64=0.828)。这意味着,在应用执行过程中,平均每个核大约有17%的时间处于闲置状态。
1.阿姆达定律
阿姆达定律是并行计算领域广泛使用的加速比计算模型。
假设某计算任务中可并行执行部分的比例为f;
多核SoC的处理器数量为n,即多核SoC对并行计算任务性能提升倍数为n。
串行计算任务将由其中一个核完成,运行时间不发生变化,而并行任务将由多核完成,则该计算任务经过并行部件优化后的整体加速比为:

在这里插入图片描述
由于假定计算任务的规模在使用多核SoC平台后并不会产生变化(Fixed-size),当处理器数量趋于无穷大时,加速比将趋于1/(1-f),即多核SoC平台对计算性能的提升存在理论上界。
而多核SoC平台往往针对更大的计算问题设计,因此计算规模应该随着计算能力的提高具有较强的可扩展性(Scalarbility)。下面通过一个例子来说明阿姆达定律的应用。
[例1] 假设在一个单核SoC平台之上,某一计算任务中可并行化部分的执行时间占据整个任务执行时间的40%,若将此单核SoC平台扩展为拥有10个处理器的多核SoC,则采用该加速措施后整个系统的性能提高了多少?
由题意可知:f=0.4,n=10。根据阿姆达定律,Speedup=1/(0.6+0.4/10)=1.56
由此可见,多核SoC所带来的性能的提升,往往在很大程度上取决于可并行部分所占的比例。
2.古斯塔夫森定律
对于大量实际应用尤其是嵌入式实时应用,计算规模的扩展往往会受到计算任务执行时间的严格限制。
因此,古斯塔夫森定律讨论一种固定时间(Fixed-time)的加速比计算模型。它考虑了数据大小与核的数量成比例的增加,并假设大数据集能够以并行方式执行。改变前后的系统具有相同的运行时间。这样就可以计算出应用加速比的上限为:
Speedup=(1-f)+nf
与阿姆达尔定律公式相同,式中,n代表核心数量。为简化表述,对于指定的数据集大小,f代表并行应用中的可并行执行部分的时间百分数。例如,如果在32个核心上99%的执行时间用于可并行部分执行。对于同一数据集,与基于单个核心和单个线程运行环境相比,多核SoC环境下应用运行的加速比为:
Speedup=(1-0.99)+32(0.99)=31.69
古斯塔夫森定律表明固定执行时间的多核SoC性能加速比是处理器数量的线性函数,也就是说随着处理器数量的增加,其所能处理的任务量也随之增加,解决了阿姆达定律中对于假设任务量不变的不合理性。因此,在古斯塔夫森定律中随着处理器数量的增加,其性能也会随之提升,从而具有可扩展的特性。同时古斯塔夫森定律也表明构建大规模的多核并行SoC可以使嵌入式应用得到更大的性能收益。
4 几种典型的多核SoC系统结构
1.片上网络
随着同一芯片内部集成的处理器数量不断增加,利用传统的基于总线的互连结构已成为多核间通信的主要瓶颈。研究人员普遍认为,片上网络(Noc,Network on Chip)结构会成为多核SoC核间通信问题的最终结构解决方案。
特别是随着集成电路工艺水平的不断提高,芯片面积不断减小,NoC结构在未来多核SoC中将显得更为重要。对在基于NoC的SoC中,处理器核之间依靠网络和数据包交换机制,在一条由其他处理器或IP核构成的连接或路由上完成数据的交互。
NoC大量借鉴了计算机网络中的理论和概念,因此会着重考虑通信延时和吞吐率等问题。但作为多核SoC的互连结构,NoC在设计过程中还需要考虑路由和链路通信对于系统功耗和芯片面积产生的重大影响。
由于较好地解决了传统的基于总线的SoC多核系统在总线结构设计上所面临的带宽和复杂逻辑协议的问题,NoC体系结构可以广泛应用于多媒体处理和无线通信等计算密集型应用领域。
典型的NoC系统结构的如图4-10所示。NoC包括计算和通信两个子系统,计算子系统(PE,Processing Element)构成的子系统,完成广义的“计算”任务,PE既可以是处理器也可以是各种专用功能的IP核或存储器阵列等。
通信子系统(S,Switch)组成的子系统,负责连接PE,实现计算资源之间的高速通信。通信节点及其间的互连线所构成的网络被称为片上通信网络(OCN,On-Chip Network),它借鉴了分布式计算系统的通信方式,用路由和分组交换技术替代传统的片上总线来完成通信任务。
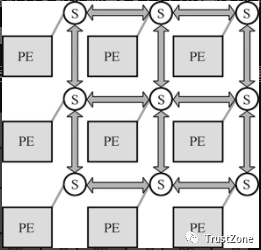
在这里插入图片描述
2.可重构SoC
可重构SoC是一种兼顾软件硬件实现特点的SoC系统结构。与基于通用微处理器软件的SoC实现相比,可重构SoC可以获得更高的性能。
而与基于ASIC的专用硬件SoC实现方案相比,可重构SoC又可以保证更高的灵活性,以满足用户复杂多变的需求。
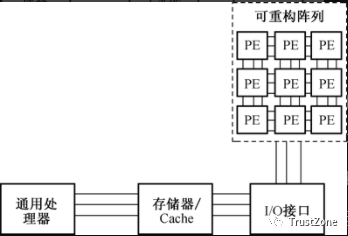
图4-11所示为一种可重构SoC的典型系统结构。可重构SoC主要由可重构逻辑阵列和通用处理器组成。通用处理器负责处理重构配置、数据流控制和存储器访问等串行控制操作;
而可重构逻辑阵列通常是由一系列可重构的处理单元(PE,Processing Element)、可编程的互连网络及可重构阵列与SoC中其他设备进行互连的接口组成,负责处理计算密集型任务,以提升可重构SoC的计算性能。
这样,可重构处理单元可根据应用的需求,利用可编程互连网络进行动态配置,从而对可重构处理单元进行重新组合,构成满足需求的计算系统。
在可重构SoC中,通用处理器的编译器是经过特殊优化的,可根据应用的数据流生成由可重构指令组成的配置文件,配置文件将被加载到配置存储器中,以完成对可重构阵列得的重构。
在这里插入图片描述
按照重构的方式,可重构SoC可以分为静态可重构和动态可重构两类。假如重构的过程必须在中断程序执行的前提下运行,则称为“静态可重构”;假如装载配置文件的过程可以与程序执行同时进行,即在改变电路功能的同时,仍然保证电路的动态运行,则称为“动态可重构”。
动态可重构又可进一步分为全局可重构和局部可重构。全局可重构是指在配置过程中,计算的中间结果必须取出存放在额外的存储区,直到新的配置功能全部下载完为止,重构前后电路相互独立,没有关联。局部可重构是指对可重构阵列的局部重新配置,与此同时,其余局部的工作状态不受影响。
局部可重构可以减小重构的范围和单元数目,大大缩短重构时间,将是未来可重构SoC所采取的主要工作模式。
可重构SoC利用可重构计算阵列对计算密集型任务进行处理,保证SoC具有较高的处理性能。同时可重构SoC又可以根据应用需求的变化对算阵列进行运行时动态重构,以保证系统的灵活性。
由于可重构SoC将软硬件实现的优点进行了有效的结合,近年来已经成为嵌入式领域的新兴体系结构。
3.TI的开放式多媒体应用平台(OMAP)架构
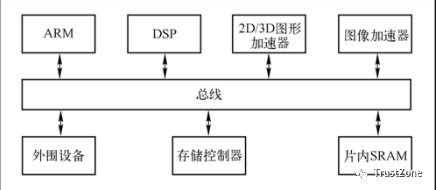
在异构多核处理器方面,RISC通用处理器和DSP的结构受到了业界的广泛关注,产品以TI的OMAP最具代表性。OMAP结构是TI公司针对移动通信及多媒体嵌入应用系统开发的多核SoC,如图4-12所示。
它采用一种双核结构,把TI的高性能低功耗DSP核与控制性能强的ARM微处理器结合起来。此外,芯片中还包括图像、图形的加速器及一些输入输出接口。在芯片中,利用低功耗的ARM处理器实现接口和控制方面的需要,而DSP用来增加芯片对音视频应用中的信号处理能力。
在这里插入图片描述
由于OMAP独特的结构,其芯片运算处理能力强、功耗低,在移动通信和多媒体信号处理方面获得较大的应用。此外,OMAP的开放式软件结构可保持双内核硬件对用户的透明度,以便于编程并集成到多功能产品中。
后续整理一下关于OMAP的资料。
审核编辑:汤梓红
-
SoC系统中的软件结构设计2023-09-25 2332
-
FPC的结构设计.zip2023-03-01 1145
-
蝶式五轨滑盖结构设计与磁动力滑盖结构设计的不同之处在哪?2021-07-28 1951
-
浅谈产品结构设计类别及产品结构设计的重要性2021-05-26 25854
-
轮辐转子的结构设计2017-01-02 871
-
基于ARM的嵌入式系统硬件结构设计2016-12-16 978
-
软件结构设计2016-09-26 2666
-
浅谈产品结构设计特点2016-02-25 6109
-
招聘--结构设计师2015-09-25 3106
-
手机结构设计心得2012-11-07 5315
-
操作系统结构设计2011-09-13 2624
-
多核处理器及其对系统结构设计的影响2011-02-27 1027
-
结构设计方面资料2010-08-09 1243
-
轴系结构设计实验2009-03-13 59518
全部0条评论

快来发表一下你的评论吧 !
