

技术与计算负载如何驱动多芯片系统
制造/封装
描述
为了解决未来应用的算力需求,半导体产业内的IP与工艺创新仍在持续发展,如今多晶片(multi-die)系统已经变得愈发普遍。然而,负载需求已经开始影响到计算阵列、内存以及DDR、HBM和UCIe的带宽等,因为新一代的硬件都已转为面向未来的AI负载设计。
真正驱动多芯片系统发展的因素
SoC性能一直在迭代升级,多核设计在推动性能提升上的重要性也是被广泛讨论的话题之一,因为“登纳德缩放定律”(Dennard scaling)也被视为即将迎来终结(图1)。
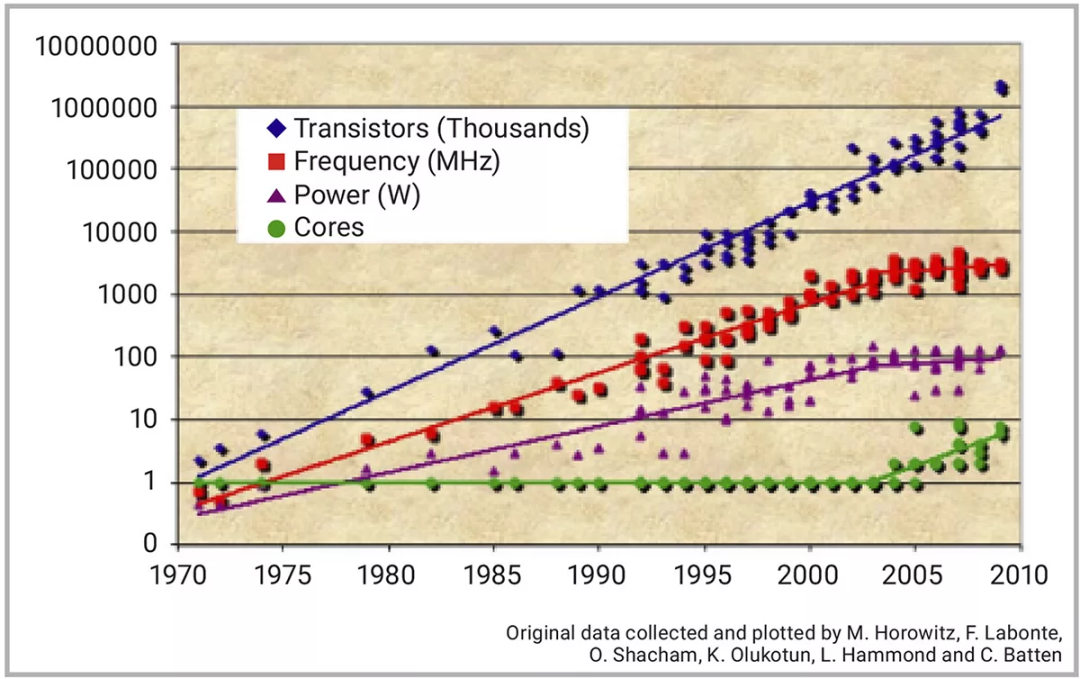
图1:SoC性能的迭代升级
即便忽略这一趋势,为了满足性能需求,晶圆代工厂持续推进下一代工艺节点,使其实现更高的频率和更高的逻辑密度从而集成更多的处理单元,同时减少功耗面积。这一持续创新的趋势可见图2。
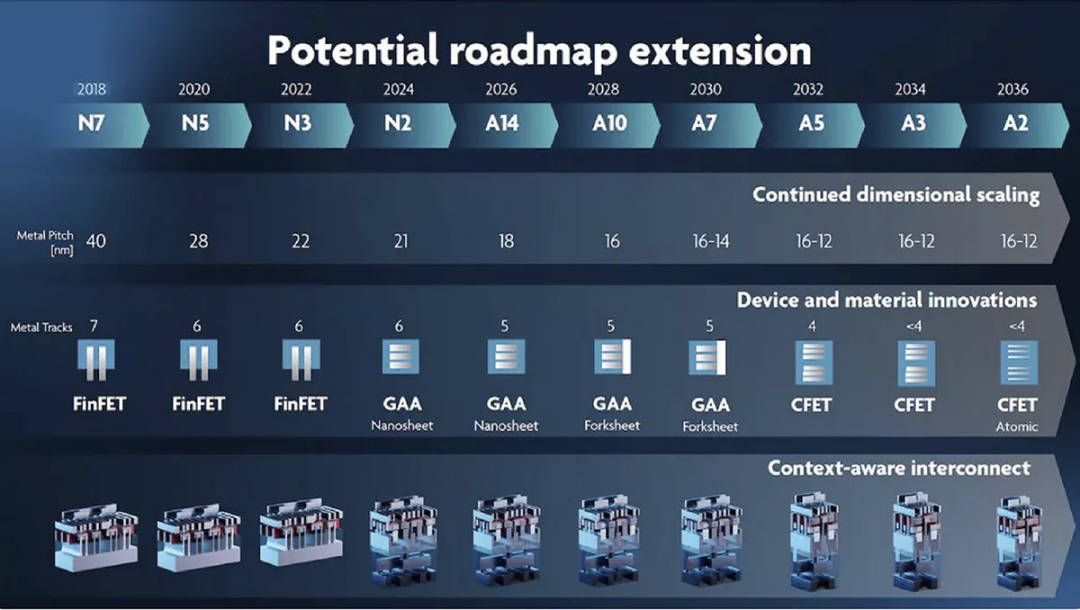
图2:最新的IMEC工艺节点路线预测图
除了工艺节点的创新外,多核架构和处理器阵列也在积极克服性能迭代提升的问题。然而,无论是多核架构的创新,还是工艺节点的迭代升级,两者都需要一个新的多芯片系统架构。解决内存墙的问题无疑是多芯片系统的主要驱动需求之一(见图3)。下图向我们展示了内存密度正以每两年翻倍的速度增长,而工作负载所需的内存密度正以每两年翻240倍的速度增长。如需了解更多详情,可以浏览发表在Medium上的《AI与内存墙》一文。
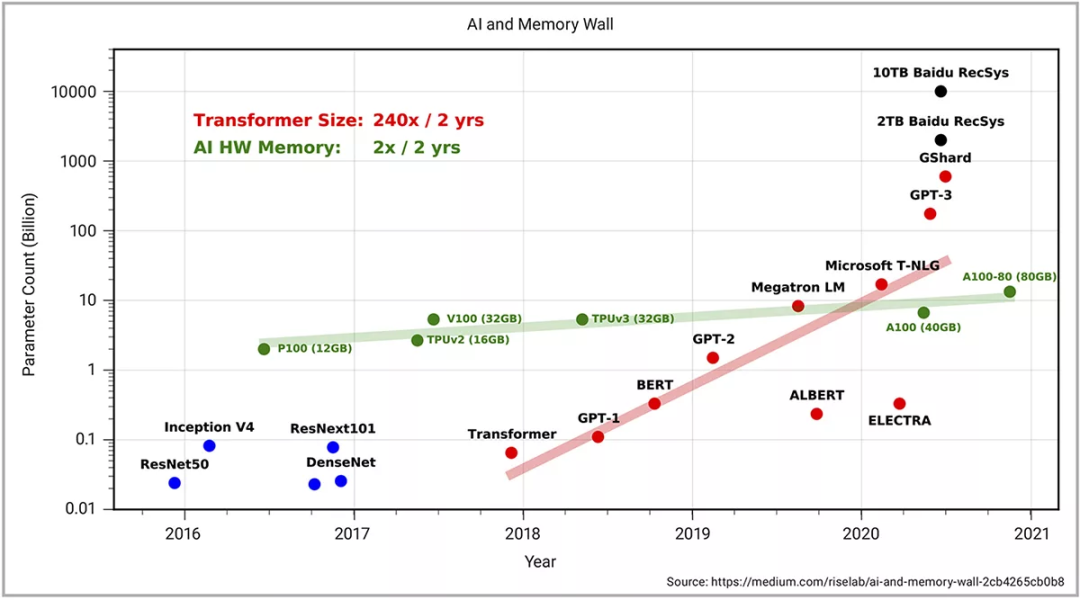
图3:训练先进模型所需的算力(单位Peta FLOPs),用来训练SOTA模型,包括不同的CV、NLP和语音模型,以及不同Transformer模型的规模扩展速度(两年翻750倍);同时包括所有模型的平均规模扩展速度(2年翻15倍)。
为了满足内存带宽方面的性能需求,我们已经看到当前片外内存市场被高带宽内存(HBM)等新技术所颠覆。业界已经看到HBM3成为HPC市场的主流。这一革新仍将继续,因为 HBM 有一个很好的未来性能提升路线图。 遗憾的是,以上所表述的内存墙仅限于片外内存,而片上内存系统在如今大多数SoC设计中都起到了至关重要的作用,所以不久的将来,这一行业的革新同样不可避免。
当下的设计重心
AI与安全相关的负载计算量正在急剧地提升,这也推动了不少频率提升之外的片上性能创新。其中绝大多数创新都集中在负载所需的处理器上。例如人工智能算法推动了大规模乘法累加并行运算以及创造性嵌套循环的设计,在减少了运算周期的同时提高了单个周期完成的工作量。
不过,这些负载也需要更大的内存密度来存储权重、系数和训练数据。这就推动了更大容量和更高带宽的片上与片外内存的出现。在片外内存方面,业界已经迅速普及了新一代的HBM、DDR和LPDDR内存。然而,芯片供应商最大的差异化方案还是体现在片上内存配置上。例如,在AI加速器领域,每个供应商都在力求在全局SRAM和缓存上集成更高带宽和更高密度的内存。利用特殊方法优化每个处理单元的内存配置,也是这一创新难题中最关键的一环。
从SoC性能提升退一步看,业界面临的另一大问题就是云端AI系统的功耗。图4展示了谷歌数据中心的耗电量。显而易见,设计出具备更高能效CPU的SoC是至关重要的,多家SoC初创公司都公开宣传其AI处理器其的高效性,并声称可以解决这一问题。但是,整体的系统性能还应该将片外内存计算在内,比如DRAM的功耗往往占总功耗的18%。由于HBM的pJ/bit冠绝群雄,所以在设计中采用更低功耗的HBM越来越普遍。
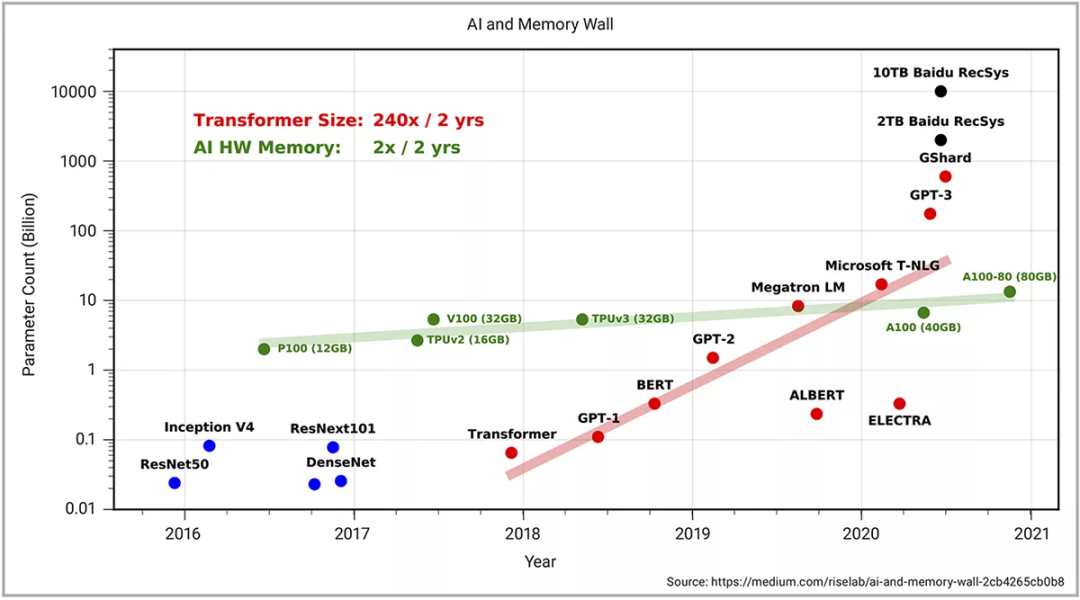
图4:谷歌数据中心耗电量
回到性能的话题上来,在讨论更为广泛的SoC系统时,AI加速器的片上竞争点很明显,往往都是如何在每一代产品中集成比竞品更多的SRAM和缓存。例如,英伟达等市场主导者会积极采用最新的工艺技术,每一代产品都集成了更大的二级缓存和更高的全局SRAM密度,以获得AI负载下更高的性能。
针对AI负载进行芯片设计的额外的挑战
当针对AI负载进行芯片设计时,还有几个因素是需要纳入考量的。其中一个老生常谈的问题是内存带宽。许多AI SoC芯片供应商将内存带宽作为关键的性能指标。然而,内存带宽还需要结合更多因素来看。比如,从全局内存访问数据所需的周期数可能是二级缓存的 1.9倍,而二级缓存所需的周期数几乎是一级缓存的6倍,以下数据来源于英伟达Ampere GPU的测试数据。
全局内存访问(最高80GB):~380周期
L2缓存:~200周期
L1缓存或共享内存访问(每个流处理器最高128kb):~34周期
乘加运算,a*b+c(FFMA):4周期
向量核心矩阵乘法运算:1周期
因此,要想提高这些负载的性能,在前几代系统中进一步提高L1和L2缓存就非常重要了。对于具有大规模处理并行性的AI计算负载而言,提高接近处理单元的缓存密度是最高效的设计改进之一。 片上系统内存优化的另一种方法则涉及AI算法相关的特定知识。例如,根据这些AI算法的最大中间激活值来设计本地内存。这就消除了片上传输数据的瓶颈。这种方法更适合用于边缘侧,因为软硬件协同设计将决定效率的高低。可惜的是,这就需要对终端应用有着足够深入的了解。同样,这类系统的建模可在提高硬件性能上发挥关键作用,而新思恰好在为开发者提供解决方案上具备得天独厚的优势。
下一轮创新的侧重点是什么?
我们已经讨论了采用DDR/LDDRP和HBM等片外内存接口来提高内存带宽,但这些技术还无法跟上芯片内集成的AI处理器算力。片外内存的发展差距正在明显地扩大。Meta在近年的一次OCP峰会上指出了这一趋势(图5)。
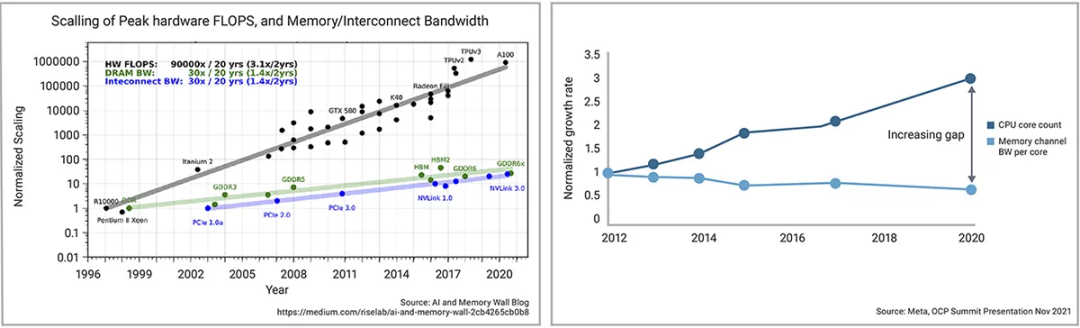
图5:不断增加的片外内存性能差距
接口 IP 标准最近在下一代标准的进步方面有所上升,以跟上这种性能差距。例如,下一代标准接口通常每四年发布一次,最近又加快到每两年发布一次。AI和安全工作负载的出现有助于更快地采用下一代技术。
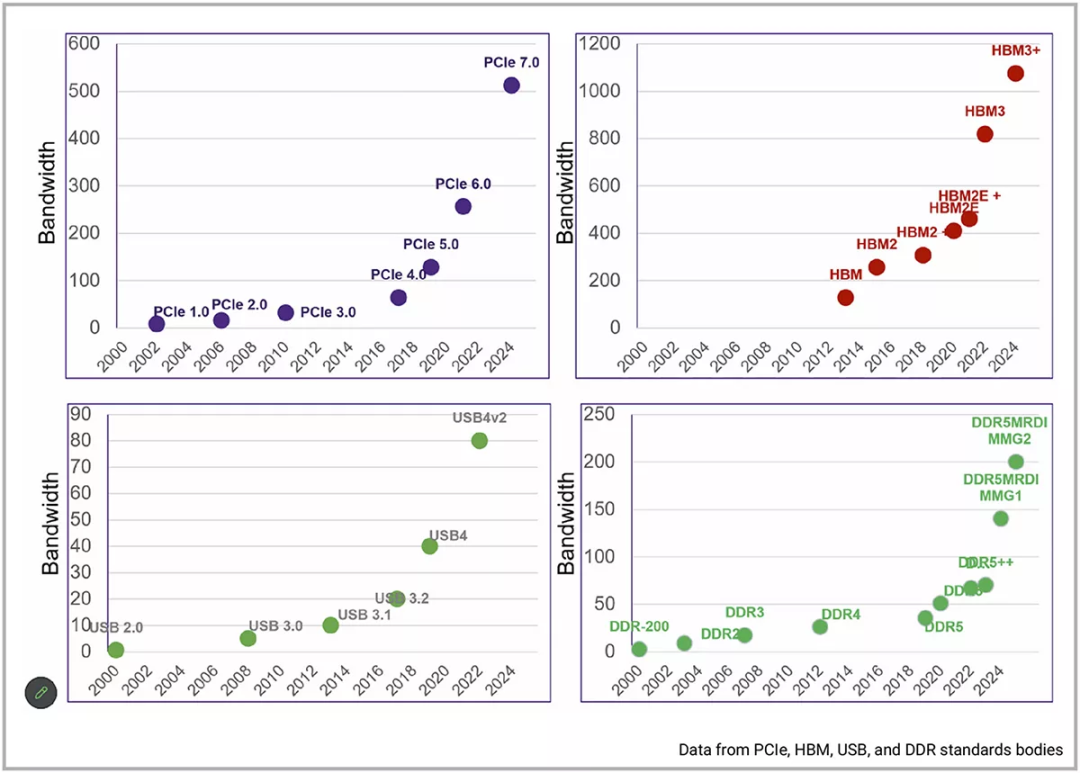
图6:下一代标准的发布速度逐渐加快,用于补全性能差距。
处理单元与内存的差距不仅体现在片外内存的进步上,也体现在了片上内存的革新上。仔细观察工艺节点的演进,我们可以发现三类持续创新(表1)
先进晶圆代工厂(如台积电)每一代处理器的最高频率都在提升,且他们开发的16nm、7nm、3nm等工艺节点也在逐渐提高性能
每个工艺节点的功耗都会降低25%以上
更高的逻辑密度意味着每mm2上可集成更多的处理器,如下表所示,其密度增加了40%以上。
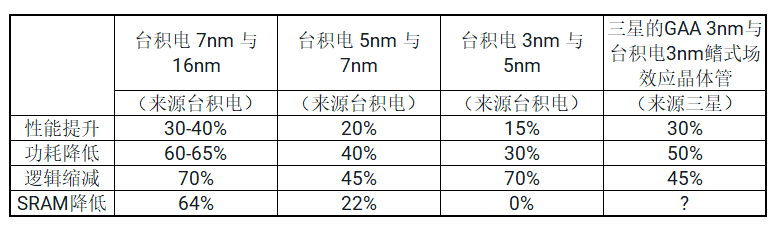
表1.工艺节点演进带来的革新
然而,正在放缓的创新是代工厂提供的片上SRAM/缓存等的密度改进。规模的削减可能已经放缓。这种减慢甚至表明,从5nm节点迁移到3nm节点可能会看到SRAM密度的轻微降低或没有降低。这给未来的计算带来了一个问题,因为人工智能工作负载需要每个处理元素更高效、更高密度的内存。新思科技专注于这一市场挑战,以确保在每个节点迁移时提高内存的密度。
除了改善片上内存之外,改善这种计算与内存比的另一种方法是在分布式计算和内存系统架构中扩展这些片上存储。为了提高性能,未来的架构必须利用多芯片系统,以满足单个芯片上正确的处理器和内存比的需求,并将该性能扩展到复杂系统中的多芯片系统中。
UCIe和XSR标准的出现,填补了连接多个裸片扩展性能的可靠标准方案空白。AI加速器产业几乎都在这类负载中用到了die-to-die互联技术。UCIe是一种标准的并行die-to-die接口,在目前性能领先的multi-die系统中,UCIe正迅速成为主流接口。最重要的是,这些die-to-die互联标准已经普及到了嵌入式内存,性能明显优于供特定处理单元访问的外部内存。这也是各大企业竞相角逐性能最高密度最高的嵌入式内存阵列的原因,即为了满足未来持续增长的负载需求。 性能显然是下一代单片SoC和多芯片(multi-die)系统架构创新的主要驱动力。
为了进一步提高性能,业界开发出了独特而创新的AI处理器。未来的工艺节点为实现更高的处理单元密度提供了可能,所以性能的提升不可避免。然而,内存性能也必须得到提升。最高效的内存永远是那些布局临近处理单元的。为了更好地扩展这些未来SoC的性能,除了靠新接口IP标准提高带宽外,还将利用multi-die系统架构。下一代接口IP比如HBM3和UCIe等都将用于提高带宽,但创新型的嵌入式内存同样不可或缺,以便在每一代工艺节点上扩展性能。
结语
多芯片系统(Multi-Die System)是业界热度最高的话题之一。然而,要想满足当下AI与安全负载需求,解决内存技术挑战必将推动下一代SoC架构的创新。随着工艺节点的演进,这些架构需要更高的性能和更高的内存密度。如果内存的扩展速度慢于处理单元,但负载却要求更高的内存密度,那么就必须打造颠覆性的内存技术。一个明确的解决方案就是多芯片系统(Multi-Die System),充分利用更多高带宽和高密度的片上内存。这些内存与IO创新将得到快速应用,以满足未来负载的需求,并为即将到来的行业革新带来机遇。
- 相关推荐
- 热点推荐
- 芯片系统
-
八通道智能驱动器SiLM92108,集成驱动与诊断,简化多电机系统设计2026-01-09 201
-
网络化多电机伺服系统监控终端设计2025-06-23 432
-
充电桩负载测试系统技术解析2025-03-05 22541
-
一文解析多芯片封装技术2024-12-30 2569
-
多通道负载测试和性能评估?2024-11-11 3445
-
负载开关芯片-负载开关电路芯片2024-09-29 1556
-
多芯片封装技术是什么2023-05-24 5654
-
电机负载计算方法 运转功率及加速功率计算2022-09-19 6880
-
多通道电子负载的功能特点2022-07-13 2553
-
银联宝揭秘LED驱动芯片调试技术2019-11-01 2618
-
基于消息驱动的多Agent通信系统结构研究2017-12-11 1207
-
基于负载均衡的多源流数据实时存储系统2017-11-21 1213
-
ps脉冲传输线的多容性负载阻抗匹配模型和计算2010-06-11 1034
-
多芯片整合封测技术--多芯片模块(MCM)的问题2009-10-05 7276
全部0条评论

快来发表一下你的评论吧 !
