

基于Transformer和深度证据学习的立体匹配框架
人工智能
描述
作者:小张Tt
本文引入了Evidential Local-global Fusion (ELF)框架,用于解决立体匹配中的可信度估计和融合问题。与传统方法仅预测视差图不同,作者的模型估计了基于证据的视差,考虑了模糊不确定性和认知不确定性。通过正态逆伽马分布进行证据融合,实现了多层次预测的内部证据融合和基于成本体积和变换器的立体匹配的证据间融合。实验结果表明,所提出的框架有效地利用了多视角信息,在准确性和跨域泛化性能上达到了最先进水平。
1 前言
立体匹配是在给定一对矫正图像的情况下,估计密集视差图的目标,是各种应用中最基础的问题之一,例如3D重建、自动驾驶和机器人导航。借助卷积神经网络的快速发展,许多立体匹配模型通过构建代价体积并使用3D卷积的方式取得了有希望的性能。最近,借助transformer的支持,提出了利用自注意和交叉注意机制来利用全局信息的方法,为立体匹配带来了一种替代方法。尽管性能有所改善,但立体匹配结果的不确定性量化一直被忽视。现有立体匹配中经常出现过于自信的预测,限制了算法的部署,特别是在安全关键应用中。深度学习模型在解释性方面容易出现不可靠,特别是在面对域之外、低质量或受扰动的样本时。在立体匹配领域尤为如此,模型首先在大规模合成数据集上进行预训练,并在来自真实场景的较小数据集上进行微调。这使得不确定性估计成为防止基于立体匹配结果的潜在灾难性决策的重要组成部分。
同时,立体匹配中广泛存在多视角互补信息,但如何有效和高效地利用它们提高准确性仍然是一个挑战。例如,使用多尺度金字塔式代价体积可以提供从特征提取器获取的由粗到精的知识,但当前的融合方法未考虑不同尺度的不确定性,导致集成不可信和不完整。另外,基于代价体积的方法和基于transformer的方法提供了完全不同的处理立体对策略:前者通过卷积聚合局部特征,后者使用transformer捕捉全局信息进行密集匹配。
我们发现这两种方法互为补充。例如,如图1(c)和1(d)的红色区块所示,基于代价体积的模型在光照变化较大的区域不稳定,而基于transformer的模型在复杂的局部纹理上利用不充分。在这种情况下,不确定性估计是在不增加过多计算负载的同时,让多视信息之间具有可信的融合策略的潜在模块。基于这些动机,作者提出了一种基于证据的局部-全局融合(ELF)立体匹配框架。该框架通过利用深度证据学习同时实现不确定性估计和可靠融合。具体而言,作者在模型的每个分支中采用可信的头部来计算伴随视差的不确定性。为了同时整合多尺度的代价体积信息和基于卷积和transformer的方法之间的互补信息,作者提出了一种基于混合正态-逆Gamma分布(MoNIG)的内部证据融合模块和外部证据融合模块。这里也推荐「3D视觉工坊」新课程《面向自动驾驶领域目标检测中的视觉Transformer》。
作者的贡献可以总结如下:
作者将深度证据学习引入了基于成本体积和基于 Transformer 的立体匹配中,用于估计随机不确定性和认知不确定性;
作者提出了一种新颖的证据局部-全局融合(ELF)框架,它能够实现不确定性估计和基于证据的两阶段信息融合;
作者进行了全面的实验证明,设计的ELFNet在准确性和跨领域泛化方面始终提升了性能。

2 相关工作
本文综述了在深度立体匹配领域中的两种主要研究方法:基于成本体积和基于Transformer。基于成本体积的方法通过构建三维成本体积来进行立体匹配,但在处理大规模输入时存在内存和计算复杂度的问题。基于Transformer的方法通过注意力机制来建模长程全局信息,但在处理局部纹理细节时效果不佳。为了提高整体性能,本文建议将基于成本体积和基于Transformer的方法进行融合,以捕捉互补的信息。此外,本文还讨论了不确定性估计在深度学习中的重要性,并介绍了几种不确定性估计方法,包括贝叶斯神经网络、蒙特卡洛dropout和深度集成等。最后,本文扩展了深度证据学习方法,利用内部和外部证据融合策略来提高立体匹配任务中不确定性估计的性能。
3 方法
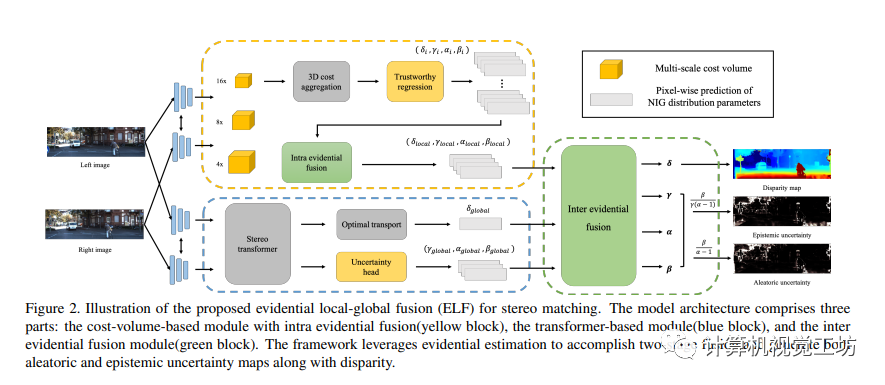
本文介绍了Evidential Localglobal Fusion(ELF)框架,该框架基于不确定性估计用于立体匹配。网络架构由三个部分组成:基于代价体积的具有内部证据融合的模块、基于变换器的模块和具有外部证据融合的模块。通过金字塔组合网络和可信赖的立体变换器,作者可以预测分布参数{δlocal, γlocal, αlocal, βlocal}和{δglobal, γglobal, αglobal, βglobal}。通过利用正态-逆伽玛分布的多视角混合,可以从整合分布{δ, γ, α, β}中进而推导出aleatoric不确定性和epistemic不确定性。
3.1 立体匹配的证据深度学习
3.1.1 背景与不确定性损失
本节介绍了立体匹配中的证据深度学习方法。通过建模视差的分布,使用正态和逆伽玛分布对视差的均值和方差进行建模。通过求取后验分布,可以计算出视差、aleatoric不确定性和epistemic不确定性。在训练过程中,使用负对数模型证据作为损失函数,并引入正则化项来减少错误预测的证据。通过期望值的形式定义总的不确定性损失,用于训练深度模型进行密集立体匹配任务。
3.1.2 在立体匹配中的不确定性估计
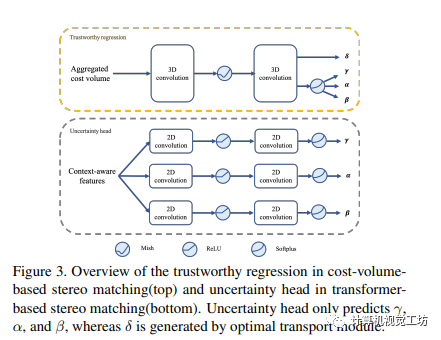
在立体匹配中,通过使用不同的网络结构,可以实现不确定性估计。在基于代价体的方法中,通过替换视差回归模块为可信回归模块,利用两个3D卷积分支和Mish激活来输出分布参数,从而更准确地估计NIG分布的参数。而在基于Transformer的方法中,采用交叉和自注意机制,通过最优传输模块回归视差和遮挡概率,并通过一个不确定性头生成参数。通过这些方法,可以提高立体匹配的不确定性估计结果的校准性。
3.2 基于证据的融合策略
在融合策略中,作者使用混合正态逆伽玛分布(MoNIG)来进行证据的融合。通过计算多个NIG分布的混合来得到MoNIG分布。融合操作通过对各个分布的参数进行加权求和,得到组合分布的参数。这种融合策略可以同时考虑到期望的置信水平和组合分布与各个单独分布之间的方差,从而提供了有关于aleatoric和epistemic不确定性的信息。
3.2.1 基于代价体立体匹配的内部证据融合
在基于代价体立体匹配中,作者使用多尺度代价体和代价体融合模块来提取不同尺度的特征,并通过代价聚合和可信回归模块生成NIG分布的参数。然后,通过内部证据融合模块将多个NIG分布集成为一个分布,作为最终的金字塔融合结果。这种基于内部证据融合的策略能够从多尺度特征中整合出可靠的输出。
3.2.2 基于成本体积和基于Transformer的立体匹配之间的相互证据融合
卷积模型和Transformer模型在立体匹配中各有优势,却有着不同的焦点。为了整合这两种方法的预测结果,作者采用了MoNIG分布进行相互证据融合,并基于不确定性进行融合策略。具体而言,利用公式将局部和全局预测结果进行融合,得到最终的分布。
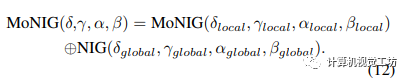
3.3 损失函数
作者定义了局部输出、全局输出和最终合并输出的不确定性损失,并且利用Transformer模块获得了注意力权重和遮挡概率。除此之外,作者采用了相对响应损失和二值熵损失函数来增强模型的准确性。最终的损失函数通过权重λi来控制不同损失的重要性。
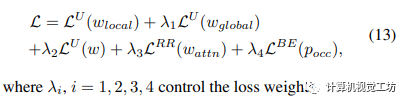
4 实验
作者在各种数据集上评估了所提出的ELFNet,包括Scene Flow ,KITTI 2012和KITTI 2015 和Middlebury 2014 。此外,作者进行不确定性分析,探讨模型性能和不确定性之间的关系。
4.1 数据集与评估指标
作者使用了FlyingThings3D子集、KITTI 2012、KITTI 2015和Middlebury 2014数据集进行实验评估。评估指标包括端点误差、视差异常点百分比和超过3像素的误差百分比。
4.2 实验细节
作者的ELF框架可以与基于Transformer和多尺度成本体积的模型兼容。在实验中,作者选择了STTR作为基于Transformer的部分,PCWNet作为基于成本体积的部分。作者使用AdamW优化器进行端到端训练,并在Scene Flow FlyingThings3D子集上进行预训练。实验中采用了数据增强技术,并在NVIDIA RTX 3090 GPU上进行了实验。
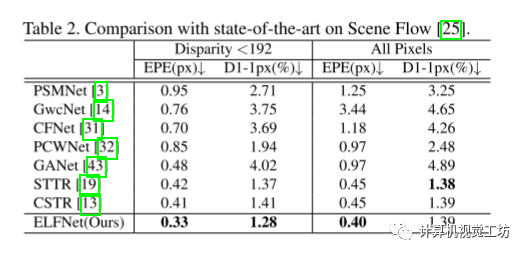
4.3 与最先进方法的比较
通过与多种最先进方法的比较,作者的方法在Scene Flow数据集上取得了优秀的性能。在EPE和D1-1px两个指标下,作者的方法均优于其他方法。具体来说,在Disparity < 192的设置下,相较于最好的方法CSTR,作者的方法在EPE上提升了19.5%,在D1-1px上提升了9.2%。在All Pixels设置下,相较于当前最先进方法,作者的方法将EPE减少了11.2%。同时,作者的ELFNet在视差估计准确性上超越了基于cost-volume和基于transformer模型,同时保持了transformer提供的遮挡估计能力。与STTR相比,作者的方法在遮挡交集联合分数上达到了相当水平。这些结果表明了作者方法的有效性和优越性。
4.4 消融实验
消融实验通过对ELF框架中各个模块的验证,证明了其各个设计的不可或缺性,并验证了证据融合在性能提升中的关键作用。具体而言,消融实验结果表明,不确定性估计模块、跨证据融合模块和内部证据融合模块对性能的提升都起到了重要作用。在Scene Flow数据集上,ELF框架通过提供不确定性估计、跨证据融合和内部证据融合的设计,将EPE减少了21.4%,并在D1-1px指标上优于基准方法。

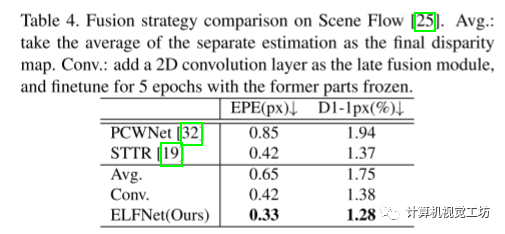
4.5 融合策略比较
通过与其他后期融合策略的比较,作者的ELFNet在Scene Flow数据集上展现出卓越的性能。与简单取平均或使用卷积层后期融合相比,ELFNet通过有效地结合基于cost-volume的模型和基于transformer的模型,取得了改进的结果,表明了其强大的融合能力和优越性能。
4.6 跨域泛化
通过在真实世界数据集上进行实验,作者证明了在零样本设置下,作者在合成的Scene Flow数据集上预训练的ELFNet具有强大的跨域泛化能力。与现有最先进模型相比,ELFNet在Middlebury 2014和KITTI 2012数据集上分别取得了显著的EPE和D1-3px分数的提升。同时,在KITTI 2015数据集上也取得了具有竞争力的泛化结果。这些实验结果进一步验证了ELFNet的优越性能和广泛适用性。
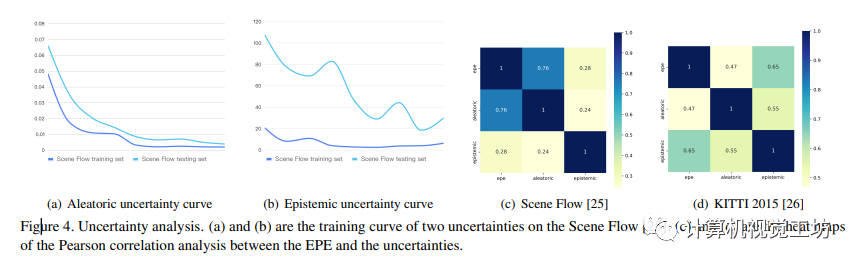
4.7 不确定性分析
本文研究了通过深度证据学习进行的不确定性估计,并提供了归因不确定性和知识不确定性的分析结果。结果显示,在模型从数据中学习更多信息时,不确定性逐渐减小。通过在不同数据集上进行皮尔逊相关分析,发现不确定性与准确性之间存在正相关关系。不同数据分布下的不同类型的误差更可能与不同类型的不确定性相关。研究还发现,估计的不确定性还受到模型架构、训练策略和数据噪声等因素的影响。此外,在定性结果中观察到,在遮挡和边界区域分配了较高的不确定性,并且不确定性图在误差发生的区域也显示活跃,这表明不确定性图为误差估计提供了线索。这里也推荐「3D视觉工坊」新课程《面向自动驾驶领域目标检测中的视觉Transformer》。

4.8 限制
尽管ELFNet能够进行不确定性估计并取得不少改进,但其推理速度存在限制。由于ELFNet涉及到两个独立的部分,因此需要更多的时间。为了改进推理速度,未来的研究可以考虑采用高效的方法,如构建自适应和稀疏的代价体积。
5 结论
本文提出了一种基于证据的局部-全局融合(ELF)框架,用于可靠地融合多视图信息进行立体匹配。通过利用深度证据学习来估计多层次的归因和知识不确定性,作者的模型能够在准确性和泛化性能方面表现出色。这为基于证据的融合策略提供了可靠的支持,并且能够利用互补的知识进一步提升立体匹配的性能。
编辑:黄飞
- 相关推荐
- 热点推荐
- 神经网络
- 深度学习
- Transformer
- 卷积神经网络
-
CREStereo立体匹配算法总结2023-05-16 3880
-
融合边缘特征的立体匹配算法Edge-Gray2021-04-29 1292
-
一种基于PatchMatch的半全局双目立体匹配算法2021-04-20 979
-
双目立体计算机视觉的立体匹配研究综述2021-04-12 1395
-
如何使用跨尺度代价聚合实现改进立体匹配算法2021-02-02 1224
-
双目立体匹配的四个步骤解析2020-08-31 6537
-
立体匹配SAD算法原理2019-06-05 2875
-
基于mean-shift全局立体匹配方法2017-11-20 1088
-
超像素分割的快速立体匹配2017-11-15 1344
-
基于颜色调整的立体匹配改进算法2017-11-02 731
-
基于扩展双权重聚合的实时立体匹配方法2017-10-31 1082
-
一种快速双目立体匹配方法_梅金燕2017-03-19 927
-
基于蚁群优化算法的立体匹配2009-06-26 1053
-
彩色镜像图像的立体匹配方法2009-04-15 1196
全部0条评论

快来发表一下你的评论吧 !
