

TPAMI 2023 | 用于视觉识别的相互对比学习在线知识蒸馏
描述
本次文章介绍我们于 TPAMI-2023 发表的一项用于视觉识别的相互对比学习在线知识蒸馏(Online Knowledge Distillation via Mutual Contrastive Learning for Visual Recognition)工作,该工作是我们发表在 AAAI-2022 论文 Mutual contrastive learning for visual representation learning [1] 的扩展版本,论文讲解链接为:
https://zhuanlan.zhihu.com/p/574701719 摘要:无需教师的在线知识蒸馏联合地训练多个学生模型并且相互地蒸馏知识。虽然现有的在线知识蒸馏方法获得了很好的性能,但是这些方法通常关注类别概率作为核心知识类型,忽略了有价值的特征表达信息。 本文展示了一个相互对比学习(Mutual Contrastive Learning,MCL)框架用于在线知识蒸馏。MCL 的核心思想是在一个网络群体中利用在线的方式进行对比分布的交互和迁移。MCL 可以聚合跨网络的嵌入向量信息,同时最大化两个网络互信息的下界。这种做法可以使得每一个网络可以从其他网络中学习到额外的对比知识,从而有利于学习到更好的特征表达,提升视觉识别任务的性能。 相比于会议版本,期刊版本将 MCL 扩展到中间特征层并且使用元优化来训练自适应的层匹配机制。除了最后一层,MCL 也在中间层进行特征对比学习,因此新方法命名为 Layer-wise MCL(L-MCL)。在图像分类和其他视觉识别任务上展示了 L-MCL 相比于先进在线知识蒸馏方法获得了一致的提升。此优势表明了 L-MCL 引导网络产生了更好的特征表达。
论文地址:
https://arxiv.org/pdf/2207.11518.pdf
代码地址:https://github.com/winycg/L-MCL

引言
传统的离线知识蒸馏需要预训练的教师模型对学生模型进行监督。在线知识蒸馏在无需教师的情况下同时联合训练两个以上的学生模型。深度相互学习(Deep Mutual Learning,DML)[2] 表明了模型群体可以从相互学习类别概率分布(图像分类任务最后的输出预测)中获益。每一个模型在同伴教授的模式下相比传统的单独训练效果更好。 现有的在线知识蒸馏方法通常仅仅关注结果驱动的蒸馏,但是忽略了在线蒸馏特征方面的应用。虽然先前的 AFD [3] 尝试通过在线的方式在多个网络间对齐中间特征图,Zhang 等人 [2] 指出这种做法会减少群体多样性,降低相互学习能力。为了学习更有意义的特征嵌入,我们认为一个更好的方式是从视觉表征学习角度的对比学习。
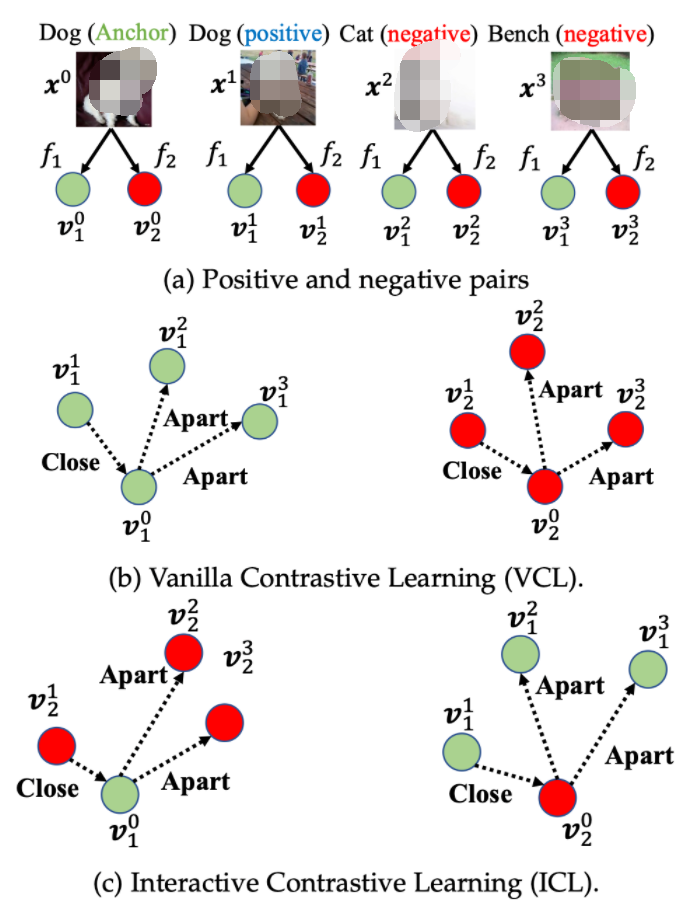

方法
2.1. 相互对比学习MCL(AAAI-2022)
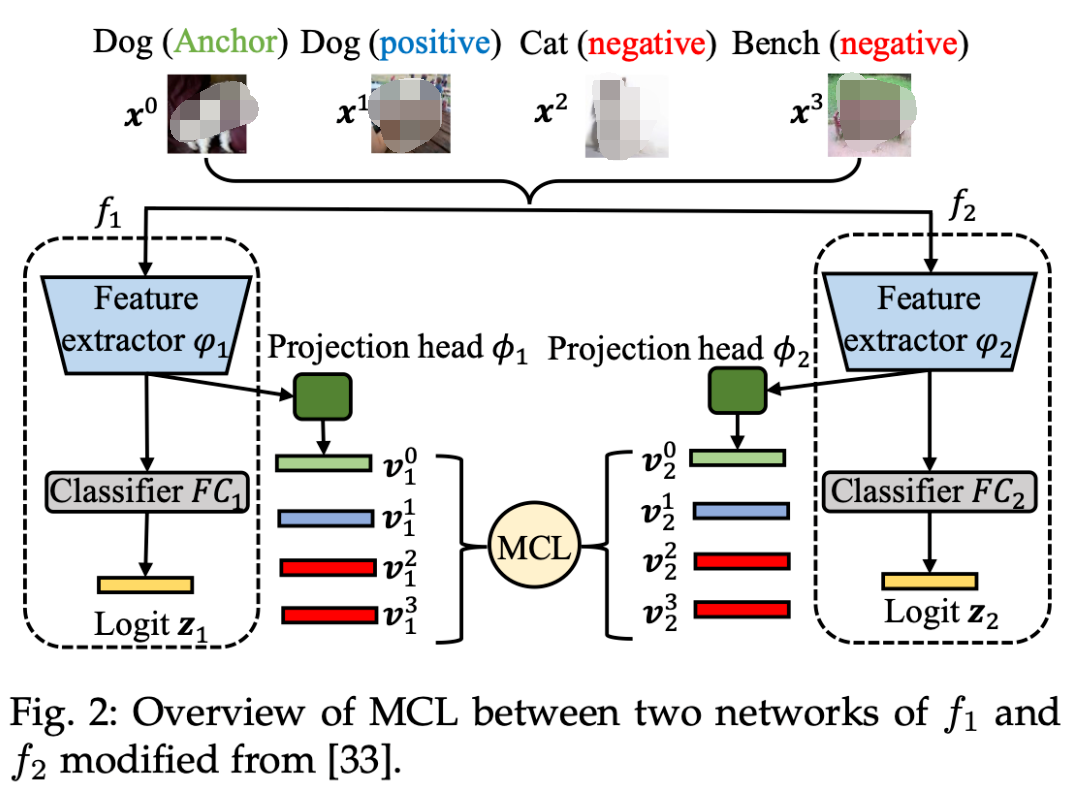
▲ 图2. 相互对比学习整体示意图
2.1.1 传统对比学习(Vanilla Contrastive Learning,VCL) 为了便于描述,本方法将 anchor 样本向量表示为 , 正样本向量表示为 和 个负样本向量表达为 。 表示向量产生自网络 。这里,特征向量通过 标准化进行预处理。使用基于 InfoNCE 的交叉熵作为对比误差:
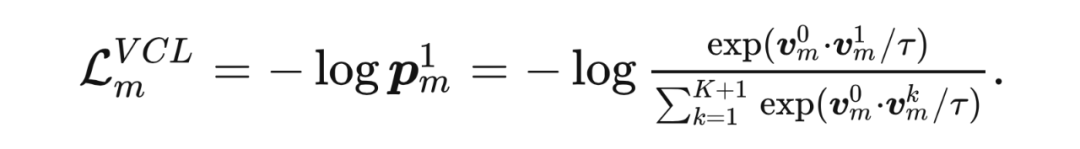 对于总共 个网络来说,所有的对比误差表示为:
对于总共 个网络来说,所有的对比误差表示为:
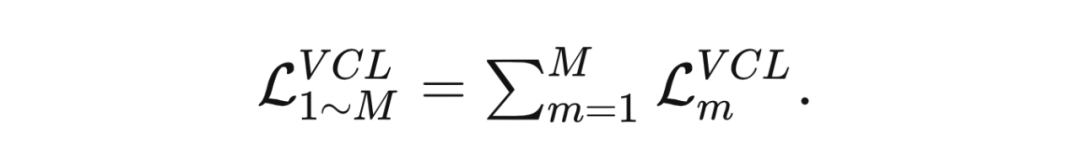
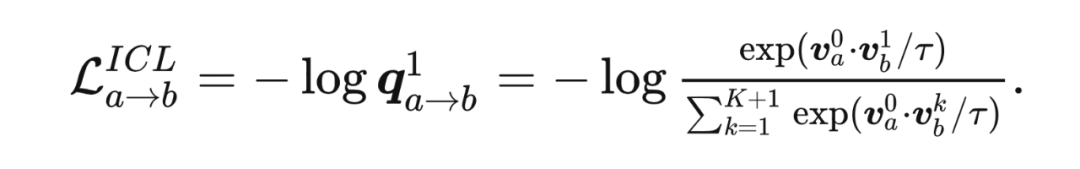
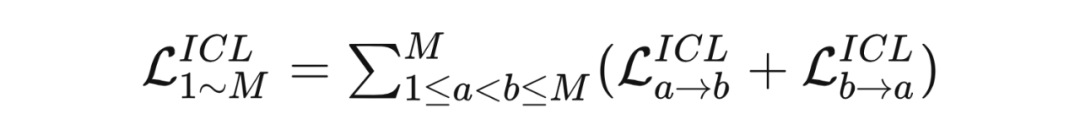 理论分析:
相比于误差 ,最小化 等价于最大化网络 互信息 的下界:
理论分析:
相比于误差 ,最小化 等价于最大化网络 互信息 的下界:
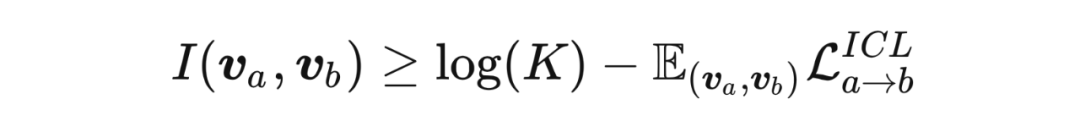
2.1.3 基于在线相互迁移的软对比学习 收到深度相互学习(Deep Mutual Learning,DML)[1] 的启发,本方法利用 KL 散度来对齐网络间的对比分布,根据本文提出的两种对比学习方法 VCL 和 ICL 来进行对比分布的双向迁移:
2.1.3.1 Soft VCL: 对于产生 的分布 来说,其监督信号是其他网络 产生的分布 ,利用 KL 散度使得 与其他分布接近:
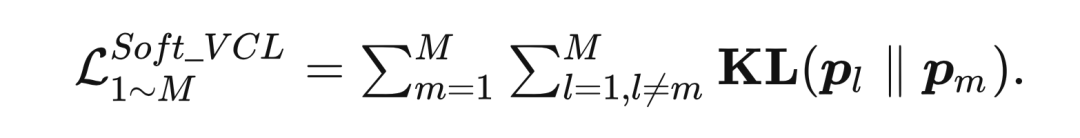
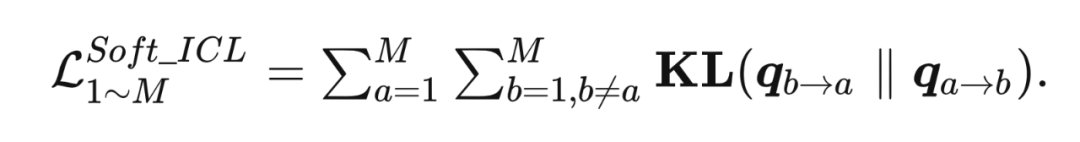
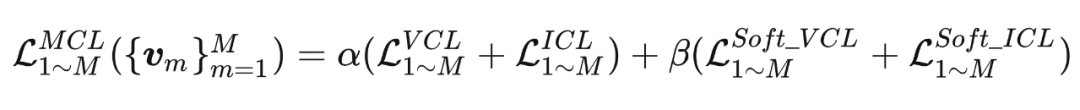
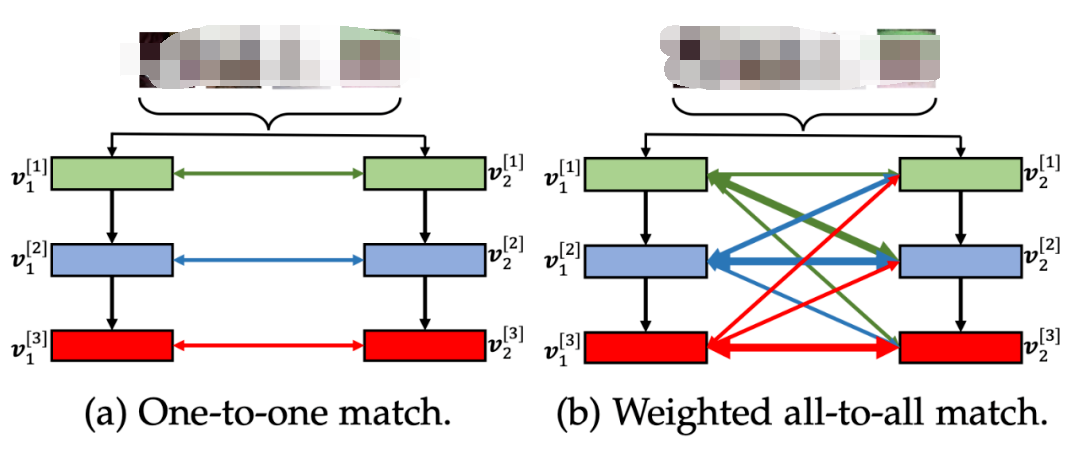
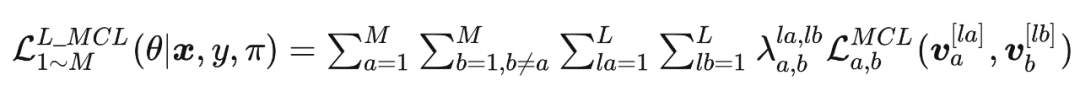 下一个章节,本文展示如何利用元网络 来优化匹配权重 。
下一个章节,本文展示如何利用元网络 来优化匹配权重 。2.2.2 训练元网络 2.2.2.1 交叉熵任务误差 使用交叉熵误差训练 个网络:
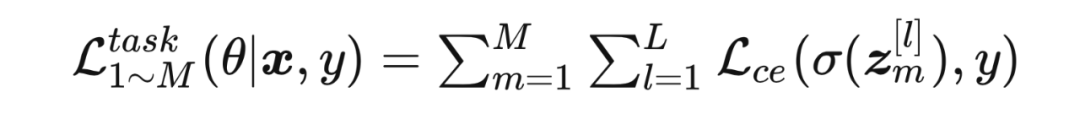 将基础的任务误差和 L-MCL 误差相加作为总误差来进行特征层面的在线蒸馏误差:
将基础的任务误差和 L-MCL 误差相加作为总误差来进行特征层面的在线蒸馏误差:
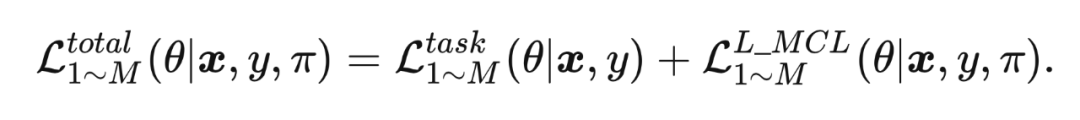
2.2.2.3 元网络 结构元网络包含了两个线性转换层 和 ,来对输入的特征向量 进行转换。转换之后,特征向量通过 正则化 来进行标准化。受到自注意力机制的启发,本文利用点乘得到匹配特征的相似性,从而衡量匹配层的相关性,然后引入 sigmoid 激活函数 来将输出值缩放到 作为层匹配权重 。整体的过程被规则化为:
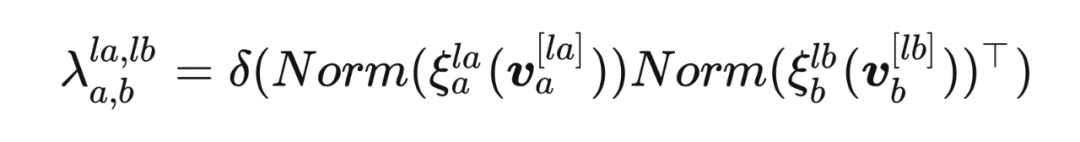

实验
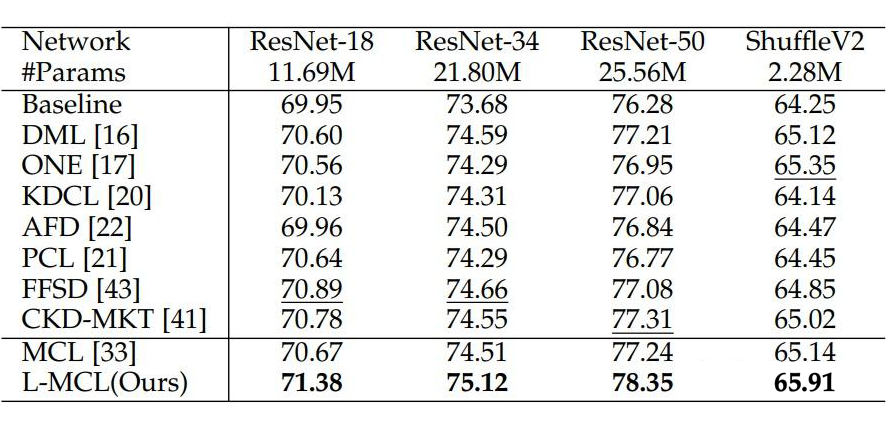
在 ImageNet 上的实验结果如下所示,表 1 和表 2 分别展示了两个同构和异构网络利用相互对比学习的实验结果。
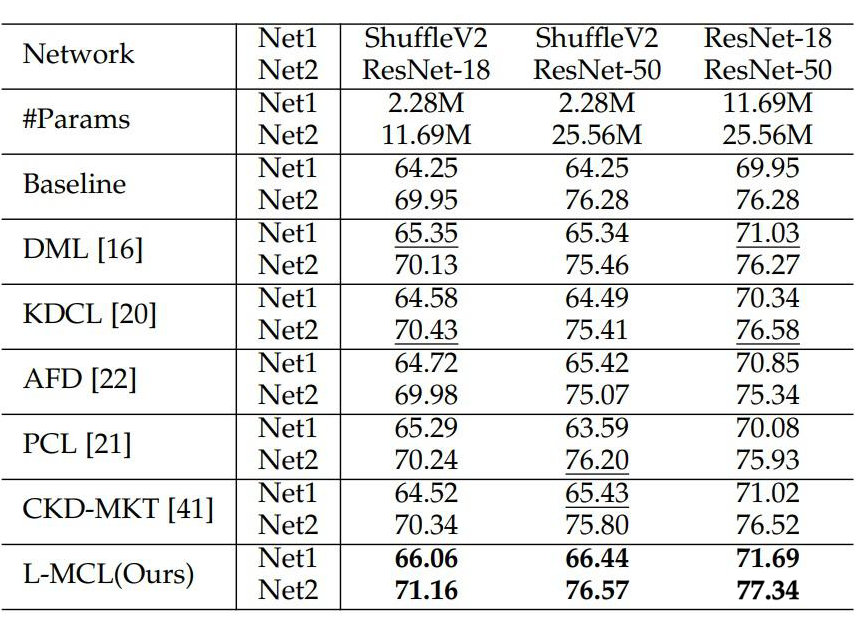 ▲ 表2. 两个异构网络利用相互对比学习的实验结果
实验结果表明本文提出的 L-MCL 相比于 baseline 以及先前流行的在线知识蒸馏方法都获得了显著的性能提升,表明在多个网络之间使用特征层面的对比学习蒸馏相比概率分布效果更好。在下游的目标检测和实例分割实验上表明了该方法相比先前的蒸馏方法引导网络学习到了更好的视觉表征,从而提升了视觉识别效果。
▲ 表2. 两个异构网络利用相互对比学习的实验结果
实验结果表明本文提出的 L-MCL 相比于 baseline 以及先前流行的在线知识蒸馏方法都获得了显著的性能提升,表明在多个网络之间使用特征层面的对比学习蒸馏相比概率分布效果更好。在下游的目标检测和实例分割实验上表明了该方法相比先前的蒸馏方法引导网络学习到了更好的视觉表征,从而提升了视觉识别效果。
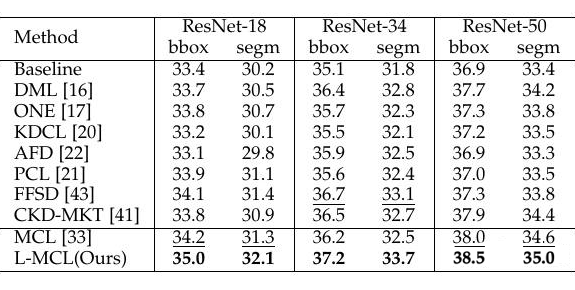
▲ 表3. 通过在线蒸馏的预训练网络迁移到下游的目标检测和与实例分割的实验

参考文献
[1] Yang C, An Z, Cai L, et al. Mutual contrastive learning for visual representation learning[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2022, 36(3): 3045-3053.[2] Zhang Y, Xiang T, Hospedales T M, et al. Deep mutual learning[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 4320-4328.[3] Chung I, Park S U, Kim J, et al. Feature-map-level online adversarial knowledge distillation[C]//International Conference on Machine Learning. PMLR, 2020: 2006-2015.
·
原文标题:TPAMI 2023 | 用于视觉识别的相互对比学习在线知识蒸馏
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 热点推荐
- �
-
如何使用Python进行图像识别的自动学习自动训练?2024-01-12 1945
-
上交提出RCLSTR:面向场景文本识别的关系对比学习2023-09-14 1539
-
机器视觉与生物特征识别的关系2023-08-09 1731
-
视觉颜色识别与传感器颜色识别的区别2023-03-20 2319
-
用于NAT的选择性知识蒸馏框架2022-12-06 1620
-
ECCV 2022 | CMU提出FKD:用于视觉识别的快速知识蒸馏框架!训练加速30%!2022-09-09 1777
-
关于快速知识蒸馏的视觉框架2022-08-31 1844
-
知识引导的开放环境视觉识别2021-05-19 664
-
【语音识别】你知道什么是离线语音识别和在线语音识别吗?2021-04-01 7185
-
深度学习:知识蒸馏的全过程2021-01-07 7172
-
基于机器视觉识别的交通灯控制系统2018-01-09 19596
-
基于改进极限学习机算法的行为识别2017-11-17 929
-
基于铁轨识别的列车滑动在线监测系统潘峥嵘2017-03-16 798
-
求助,会搞视觉识别的高人,企鹅8135699692015-03-20 1622
全部0条评论

快来发表一下你的评论吧 !
