

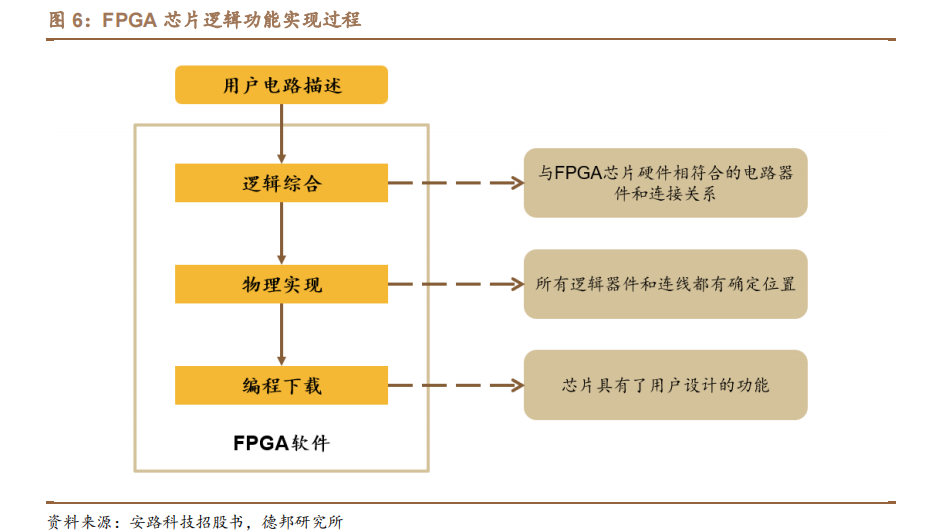
FPGA芯片设计及关键技术
可编程逻辑
描述
本文来自“FPGA专题:万能芯片点燃新动力,国产替代未来可期(2023)”,FPGA又称现场可编程门阵列,是在硅片上预先设计实现的具有可编程特性的集成电路,用户在使用过程中可以通过软件重新配置芯片内部的资源实现不同功能。通俗意义上讲,FPGA 芯片类似于集成电路中的积木,用户可根据各自的需求和想法,将其拼搭成不同的功能、特性的电路结构,以满足不同场景的应用需求。鉴于上述特性,FPGA 芯片又被称作“万能”芯片。

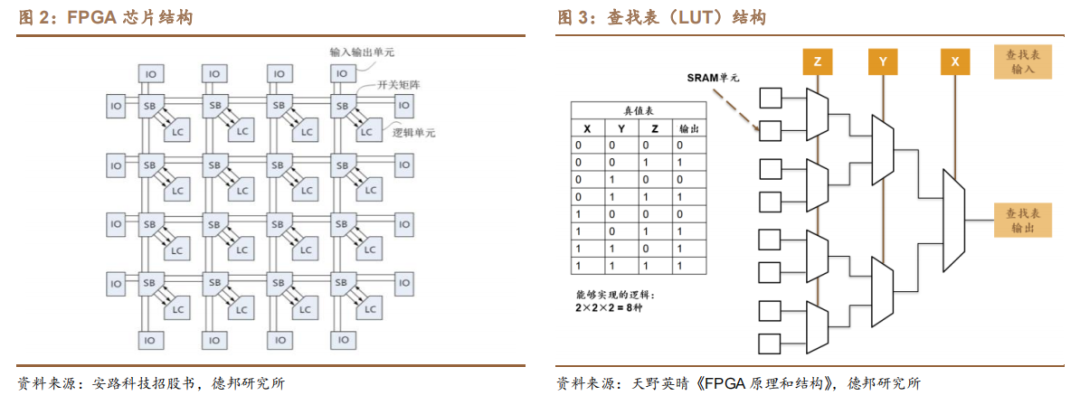
FPGA 芯片由可编程的逻辑单元(Logic Cell,LC)、输入输出单元(Input Output Block,IO)和开关连线阵列(Switch Box,SB)三个部分构成:
(1)逻辑单元:通过数据查找表(Look-up Table,LUT)中存放的二进制数据来实现不同的电路功能。LUT 的本质是一种静态随机存取存储器(Static Random Access Memory,SRAM),其大小是由输入端的信号数量决定的,常用的查找表电路是四输入查找表(4-input LUT,LUT4)、五输入查找表(5-input LUT,LUT5)和六输入查找表(6-input LUT,LUT6)。查找表输入端越多,可以实现的逻辑电路越复杂,因此逻辑容量越大,但是查找表的面积和输入端数量成指数关系,输入端数量增加一个,查找表使用的 SRAM 存储电路面积增加约一倍。不同的逻辑单元结构可以使用不同大小的查找表,或者是不同查找表类型的组合。此外,逻辑单元内部还包含选择器、进位链和触发器等其他组件。为了提高芯片架构效率,若干逻辑单元可以进一步组成逻辑块(Logic Block),逻辑块内部提供快速局部资源,从而形成层次化芯片架构。
(2)输入输出单元:是芯片与外界电路的接口部分,用于实现不同条件下对输入/输出信号的驱动与匹配要求。
(3)开关阵列:能够通过内部 MOS 管的开关控制信号连线的走向。
FPGA 从 Xilinx 公司 1985 年推出世界首款 FPGA 芯片“XC2064”经历过数十年发展,在硬件架构上大致经历了四个阶段:从 PROM 阶段(简单的数字逻辑)到 PAL/GAL 阶段(“与”&“或”阵列)再到 CPLD/FPGA 阶段(超大规模电路),到如今 FPGA 与 ASIC 技术融合、向系统级发展的 SoC FPGA/eFPGA 阶段。硬件水平整体趋向更大规模、更高灵活性、更优性能。

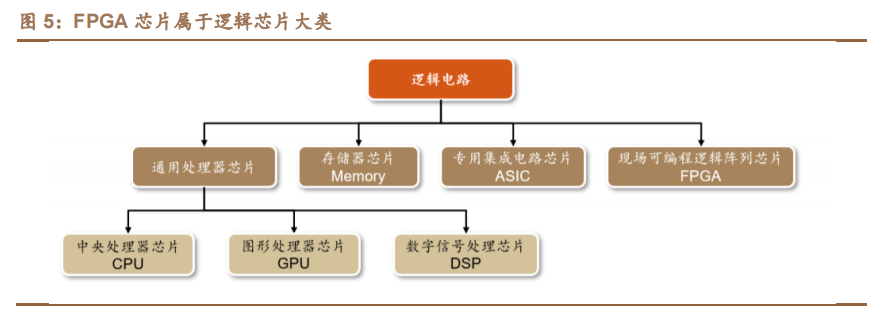
FPGA 芯片属于逻辑芯片大类。逻辑芯片按功能可分为四大类芯片:通用处理器芯片(包含中央处理芯片 CPU、图形处理芯片 GPU,数字信号处理芯片 DSP等)、存储器芯片(Memory)、专用集成电路芯片(ASIC)和现场可编程逻辑阵列芯片(FPGA)。
FPGA 兼具灵活性和并行性两大特点。
(1)灵活性:FPGA芯片拥有更高的灵活性和更丰富的选择性,通过对 FPGA 编程,用户可随时改变芯片内部的连接结构,实现任何逻辑功能。尤其是在技术标准尚未成熟或发展更迭速度快的行业领域,FPGA 能有效帮助企业降低投资风险及沉没成本,是一种兼具功能性和经济效益的选择。
(2)并行性:CPU、GPU 在执行任务时,执行单元需按顺序通过取指、译码、执行、访存以及写回等一系列流程完成数据处理,且多方共享内存导致部分任务需经访问仲裁,从而产生任务延时。而 FPGA 每个逻辑单元与周围逻辑单元的连接构造在重编程(烧写)时就已经确定,寄存器和片上内存属于各自的控制逻辑,无需通过指令译码、共享内存来通信,各硬件逻辑可同时并行工作,大幅提升数据处理效率。尤其是在执行重复率较高的大数据量处理任务时,FPGA 相比 CPU 等优势明显。

相较于其他逻辑芯片而言,FPGA 在灵活性、性能、功耗、成本之间具有较好的平衡:
(1)相较于 GPU,FPGA 在功耗和灵活性等方面具备优势。一方面,由于GPU 采用大量的处理单元并且大量访问片外存储 SDRAM,其计算峰值更高,同时功耗也较高,FPGA 的平均功耗(10W)远低于 GPU 的平均功耗(200W),可有效改善散热问题;另一方面,GPU 在设计完成后无法改动硬件资源,而 FPGA根据特定应用对硬件进行编程,更具灵活性。机器学习使用多条指令平行处理单一数据,FPGA 的定制化能力更能满足精确度较低、分散、非常规深度神经网络计算需求。
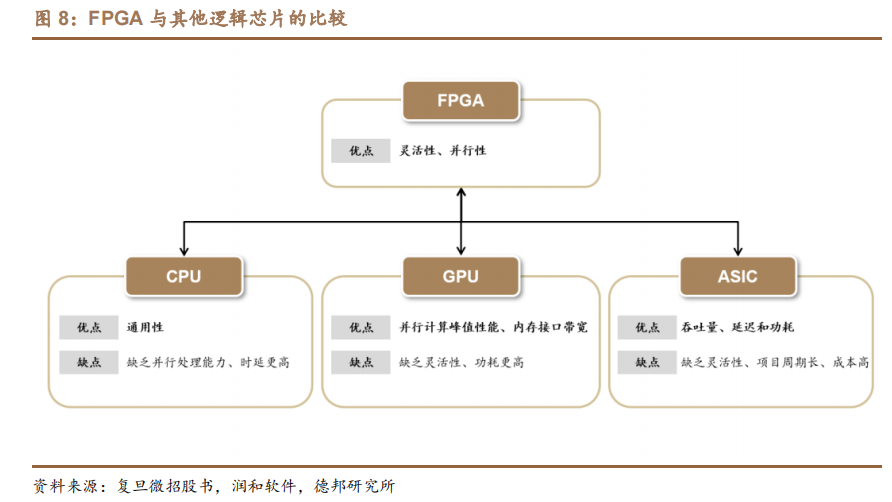
(2)相较于 ASIC 芯片,FPGA 在项目初期具备短周期、高性价比的优势。ASIC 需从标准单元进行设计,当芯片的功能及性能需求发生变化时或者工艺进步时,ASIC 需重新投片,由此带来较高的沉没成本以及较长的开发周期;而 FPGA具有编程、除错、再编程和重复操作等优点,可实现芯片功能重新配置,因此早期 FPGA 常作为定制化 ASIC 领域的半定制电路出现,被业内认为是构建原型和开发设计的较快推进的路径之一。
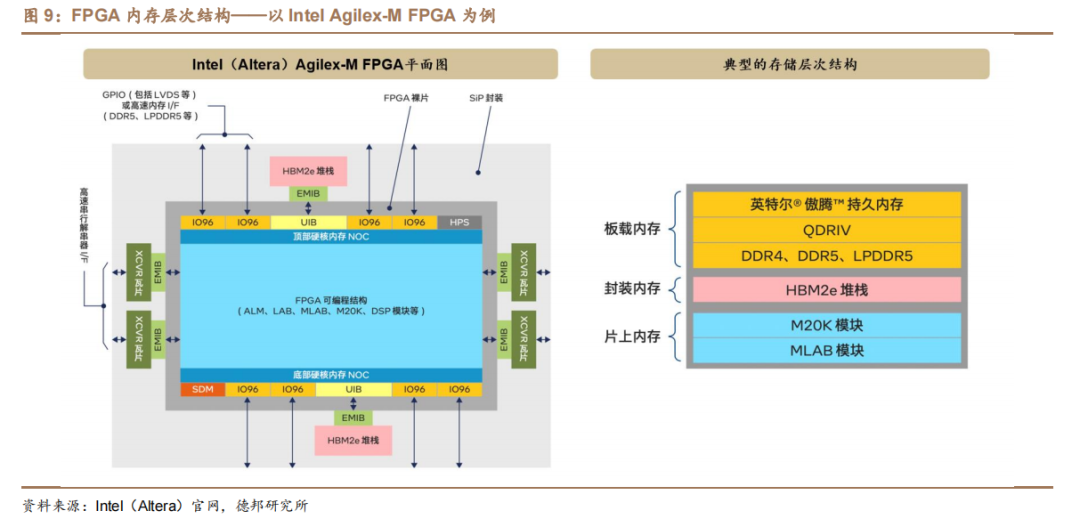
FPGA逻辑结构中的内存大致分为三个层次(以Intel Agilex-M FPGA为例),包括超本地化片上内存、以 HBM2e 堆栈形式提供的本地封装内存,以及 DDR5和 LPDDR5 等外部内存架构和接口。
片上内存(MLAB 模块和 M20K 模块):最本地化的内存;
封装内存(HBM):弥合内存层次结构中关键缺口的内存,其容量远大于片上内存(两个数量级以上),同时带宽又远大于片外内存(两个数量级以上);
片外内存(DDR5、LPDDR5 等):对于超出 HBM2e 容量的应用,或对独立内存的灵活性有要求时,需要 DDR5 和 LPDDR5 以及其他主流的内存架构。
HBM2e 与 FPGA 裸片集成在同一封装中可以在小尺寸外形规格中实现更高带宽、更低功耗、更低时延。
(1)内存容量方面:每个 HBM2e 堆栈可包含 4 层或 8 层,每层提供 2GB 内存,因此单个 Intel Agilex-M 系列 FPGA 可包含 16GB或 32 GB 的高带宽内存;
(2)带宽方面:HBM2e 可实现每堆栈高达 410Gbps 的内存带宽,较 DDR5 组件的带宽提升高达 18 倍,较 GDDR6 组件提升 7 倍。两个 HBM2e 堆栈加起来可提供高达 820Gbps 的峰值内存带宽;
(3)功耗和时延方面:由于 HBM2e 集成在封装中,因此也不需要使用外部 I/O 引脚,从而节省了电路板空间,并消除了它们会带来的功耗和互连时延。
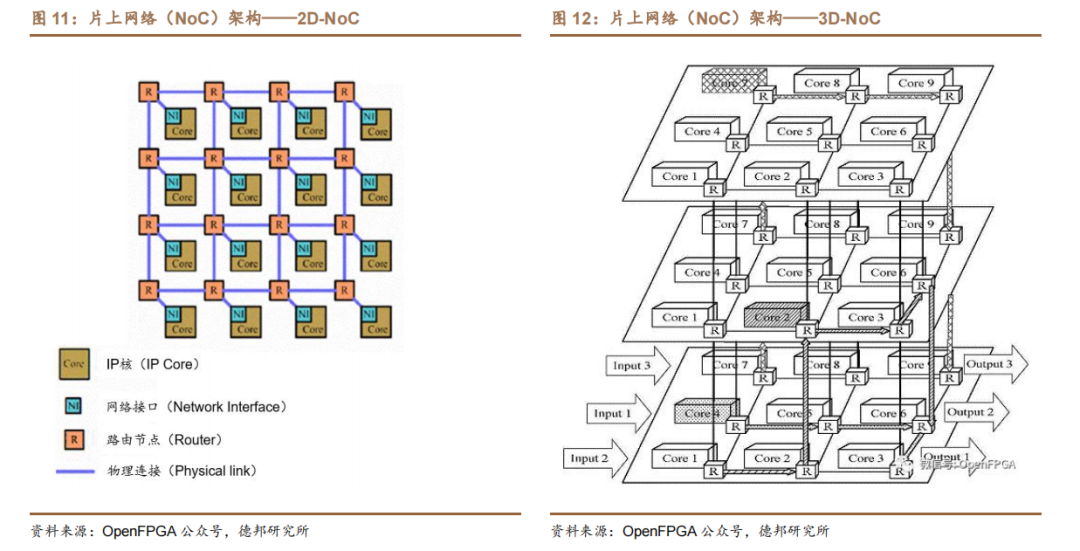
片上网络(NoC,Network on Chip)是指在单芯片上集成大量的计算资源以及连接这些资源的片上通信网络,用于在可编程逻辑(PL)、处理器系统(PS)和其它硬核块中的 IP 端点之间共享数据。
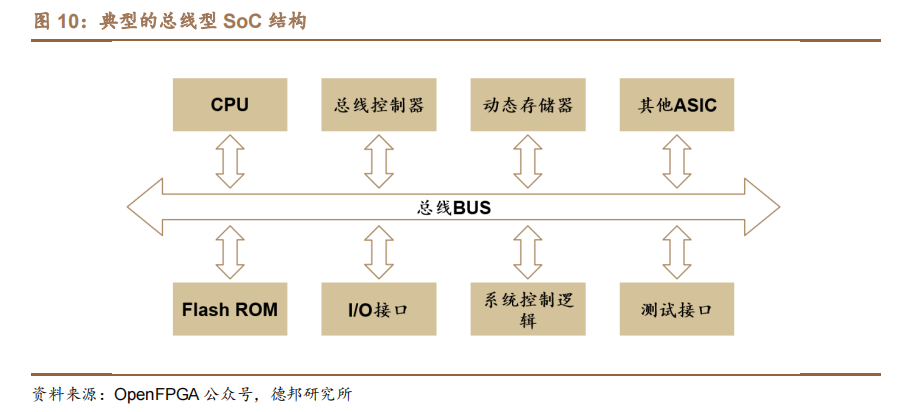
与之对应的概念——片上系统(SoC)则是包含一整套多样化和互连单元的单芯片,旨在解决一定范围的任务。传统上,SoC 包括几个计算内核、内存控制器、I/O 子系统以及它们之间的连接与切换方式(总线、交叉开关、NoC 元件)。
片上网络 NoC 包括计算和通信两个子系统。计算子系统(由 PE,Processing Element 构成的子系统)完成广义的“计算”任务,PE 既可以是现有意义上的CPU、SoC,也可以是各种专用功能的 IP 核或存储器阵列、可重构硬件等。通信子系统(由 Switch 组成的子系统)负责连接 PE,实现计算资源之间的高速通信。通信节点及其间的互连线所构成的网络即为片上通信网络。
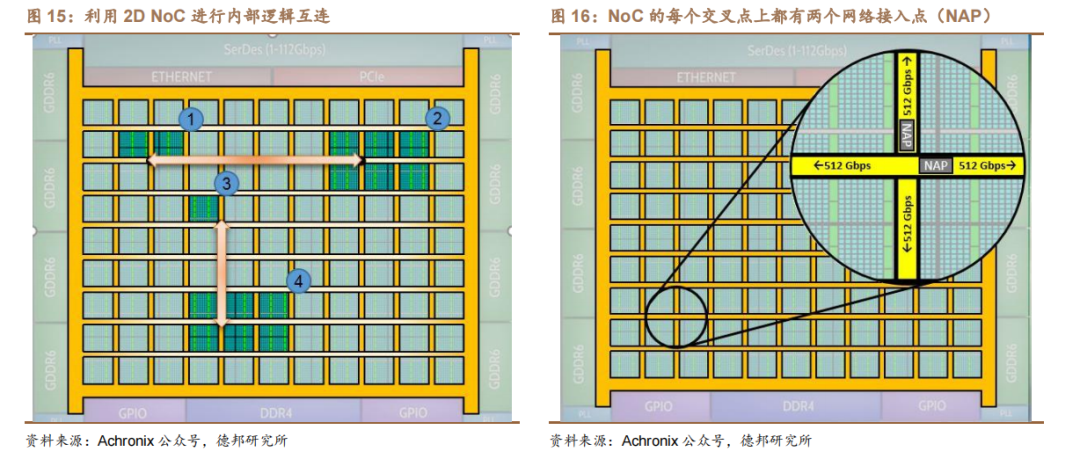
类比城市高速公路网络,NoC 架构简化互连路径,提高 FPGA 传输速率。Achronix 基于台积电(TSMC)的 7nm FinFET 工艺的 Speedster7t FPGA 器件包含了 2D NoC 架构,为 FPGA 外部高速接口和内部可编程逻辑的数据传输提供了超高带宽(~27Tbps)。NoC 使用一系列高速的行和列网络通路(水平和垂直方式)在整个 FPGA 内部分发数据,每一行或每一列都有两个 256 位的、单向的、行业标准的 AXI 通道,可以在每个方向上以 512Gbps(256bit x 2GHz)的传输速率运行。

NoC 为 FPGA 设计提供了几项重要优势,包括:(1)提高设计的性能;(2)减少逻辑资源闲置,在高资源占用设计中降低布局布线拥塞的风险;(3)减小功耗;(4)简化逻辑设计,由 NoC 去替代传统的逻辑去做高速接口和总线管理;(5)实现真正的模块化设计。
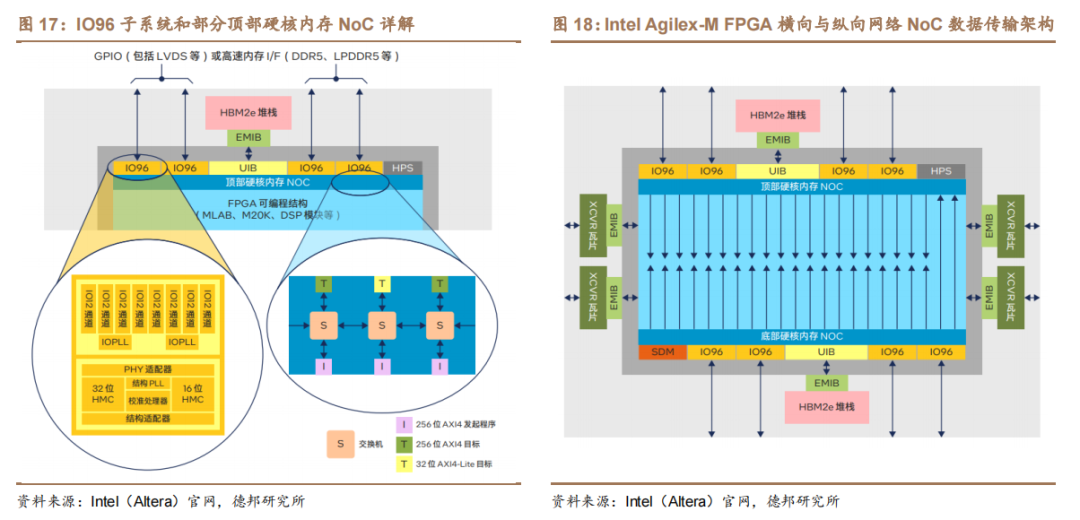
Intel(Altera)利用 NoC 架构实现内存和可编程逻辑结构之间的现高带宽数据传输。如下图所示,每个片上 HBM2e 堆栈通过 UIB 与其 NoC 通信。片外内存(DDR4、DDR5 等)则通过 IO96 子系统与 NoC 通信。NoC 通过一个由交换机(路由器)、互连链路(导线)、发起程序(I)和目标(T)组成的网络,将数据从数据源传输到目的地。每个 NoC 都提供一个横向网络,通过 AXI4 发起程序将可编程逻辑结构中的逻辑连接到集成 NoC 的目标内存。此外,每个 NoC 也都提供一个纵向网络,通过优化的路由将横向网络路径读取的内存数据分发到 FPGA的可编程逻辑结构深处(可编程逻辑结构和/或 M20K 模块)。
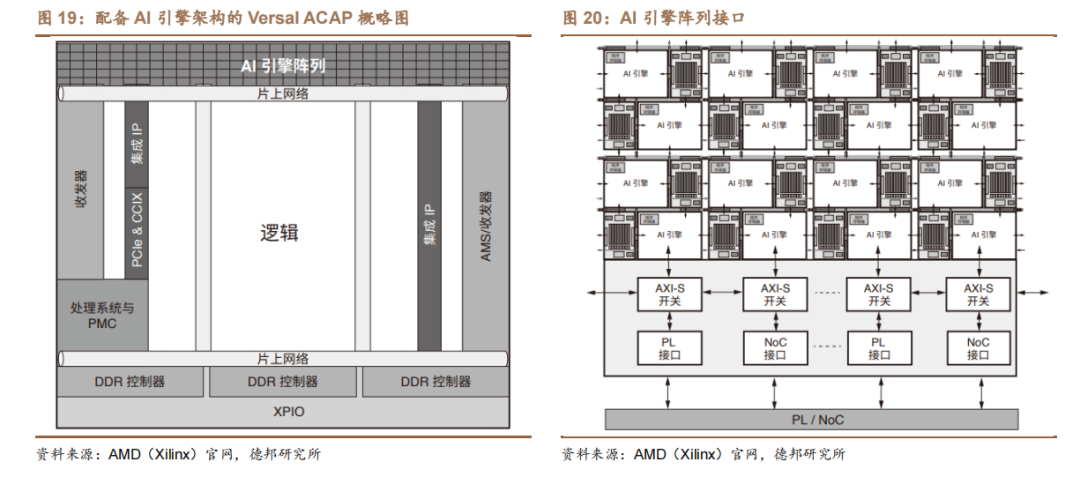
AMD(Xilinx)在 AI 引擎和可编程逻辑之间部署 NoC 架构,可大幅降低功耗。AMD Versal 产品最突出的优势之一,是能够在自适应引擎中将 AI 引擎阵列与可编程逻辑(PL)结合使用,由 AI 引擎阵列接口连接 AI 引擎阵列和可编程逻辑。这样的资源结合为在最佳资源、AI 引擎、自适应引擎或标量引擎中实现功能提供了极大的灵活性。该方案与传统可编程逻辑 DSP 和 ML 实现方案相比,可将芯片面积计算密度提高达 8 倍,从而在额定值情况下,可将功耗降低 40%。
审核编辑:汤梓红
-
汽车总线及其关键技术的研究2012-07-10 19629
-
CDMA原理与关键技术2012-08-16 3419
-
GPS芯片的关键技术是什么2019-07-30 2650
-
无人驾驶汽车的关键技术是什么?2020-03-18 4872
-
物联网的关键技术有哪些2020-06-16 3122
-
McWiLL系统的关键技术/优势及应用2020-11-24 1641
-
鲲鹏920芯片是布局云端计算的关键技术2021-01-25 2872
-
怎样去证明FPGA+DSP系统中FPGA的关键技术是存在的?2021-04-08 1382
-
智能通信终端有哪些关键技术?2021-05-26 2396
-
MIMO-OFDM中有哪些关键技术?2021-05-27 3075
-
ASON网络关键技术有哪些?2021-05-28 1849
-
POE的关键技术有哪些?2021-06-10 3439
-
什么是HarmonyOS?鸿蒙OS架构及关键技术是什么?2021-09-23 3685
-
视觉导航关键技术及应用2023-09-25 974
全部0条评论

快来发表一下你的评论吧 !
