

Medusa如何加速大型语言模型(LLM)的生成?
人工智能
描述
作者:Winnie
今天为大家介绍一个新技术—Medusa,它旨在加速大型语言模型(LLM)的生成。尽管其设计简单,但 Medusa能够将LLM的生成效率提高约2倍。让我们看看它是怎么做到的吧!
为什么LLM生成低效?
LLM在生成时的效率问题主要是由内存读/写操作带来的延迟,而这个问题源自自动回归解码过程的顺序性特点。每次的前向传播都需要频繁地移动模型参数,尽管这只产生一个结果,但却没有完全利用现代硬件的计算潜能。传统的解决方式(如增大批次大小)在LLM的场景下却不再适用,因为这不仅会增加延迟,还会引发内存问题。
不仅如此,这种低效还带来了额外的生成成本。例如,GPT-4的生成成本比仅仅处理prompt高了两倍,Claude2则大约高出3倍。因此,加速LLM的低效生成是一个亟待解决的问题。
Medusa来了!
面对推测性解码的复杂性,研究人员推出了Medusa技术,这个框架回归了Transformer模型的本质,减少了复杂度,增强了效率,让每个生成阶段都能快速产出结果。当将Medusa与基于树的注意机制结合时,生成速度提高了2到3倍。
接下来,让我们看一看Msdusa都做了哪些改进吧!
Medusa总体框架
Medusa的核心在于它在LLM的最后隐藏层上增加的多个Heads,使它们并行工作,预测接下来的内容。
当将Medusa Heads加入模型时,你会发现,原始模型保持不变,而只有这些Medusa Heads进行微调。在真正使用时,每个Medusa Head都会为其位置产生预测,这些预测会被组合、处理,最终给出最佳结果。
通过同时接受更多的tokens来增强解码过程的效率,从而减少了所需的解码步骤数量。
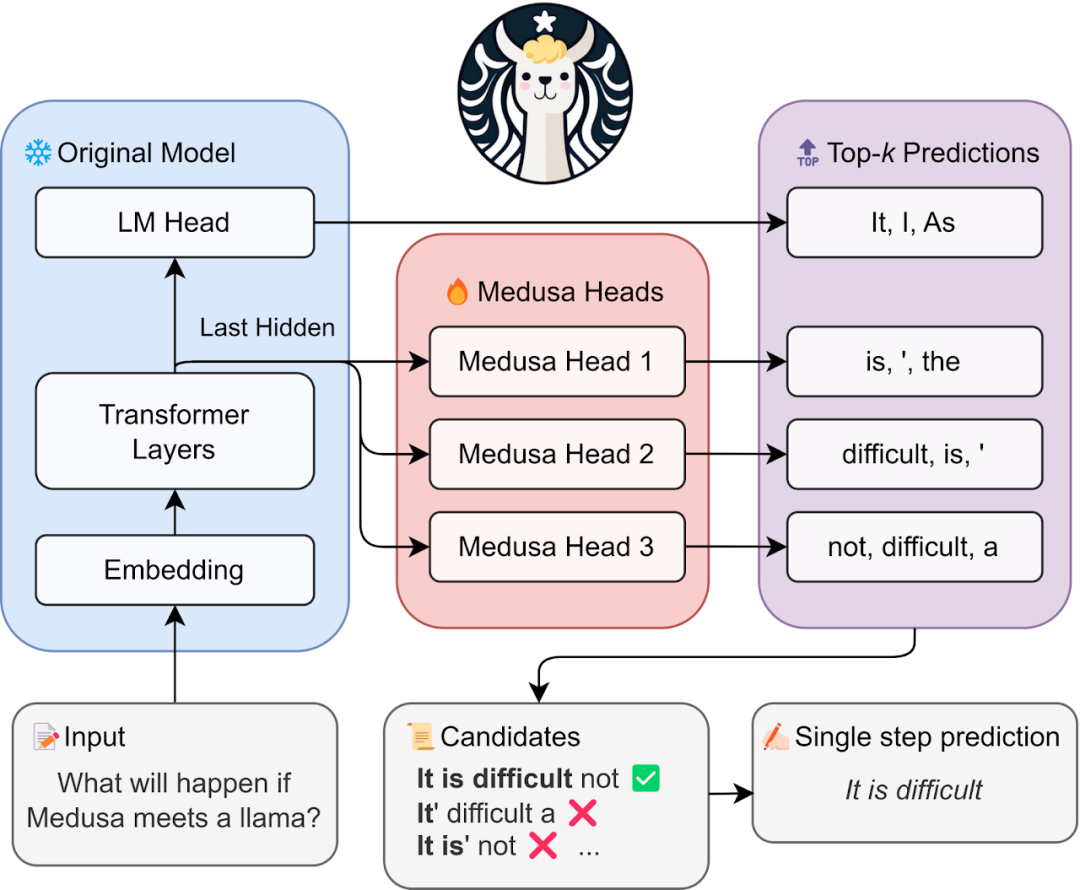
Medusa Heads
Medusa Heads与原有的语言模型头相似,但却拥有一个独特的优势:它们可以预测多个即将出现的token,而不仅仅是下一个。这种方法从Blockwise Parallel Decoding方法中汲取灵感,将每个Medusa头设计为一个单层的前馈网络,且增强了残差连接。
训练这些Medusa Heads非常方便!你可以使用用于训练原始模型的同一语料库,或者使用模型本身生成一个新的语料库来训练它们。在训练阶段,原始的模型保持静态,仅Medusa Heads进行微调。这种有针对性的训练产生了一个参数效率极高的过程,可以迅速实现收敛—尤其是与speculative decoding方法中训练单独的draft model的计算密集度相比。
Medusa Heads的表现相当出色,它在预测“下一个”token时的top-1准确率约为60%。但这仅仅是个开始,它还有很大的提升空间。
Tree attention
通过Medusa Heads的测试,研究人员发现:虽然预测“下下一个”token的top-1准确率仅约为60%,但top-5准确率却飙升至超过80%。这一显著的提高表明,如果我们可以巧妙地利用Medusa Heads做出的多个top排名预测,就可以显著增加每个解码步骤生成的tokens数量。
实现这一目标的方式是首先构造一个候选集,这个集合由每个Medusa Head的预测结果的笛卡尔积形成。然后,依赖图被编码到注意力机制中,允许多个候选项目并行处理,这是受到图神经网络思想的启发。例如,在一个实际应用中,可以从第一个Medusa头部获取前两个预测,从第二个头部获取前三个预测,并将它们组合成一个多层树结构。在这种结构中,一个注意力掩码被实施,仅限制注意力于一个token的前一个token,从而保持历史上下文。通过这种方式,可以同时处理多个候选项,而无需增加批次大小。
下图是Tree attention机制用于并行处理多个候选项目的一个可视化示例。在一个示例中,来自第一个Medusa头部的前两个预测和来自第二个头部的前三个预测产生了2*3=6个候选项。这些候选项中的每一个都对应于树结构中的一个不同分支。为了保证每个token只能访问其前面的token,注意力掩码,该掩码仅允许注意力从当前token流向其前面的token。位置编码的位置指数将根据这种结构进行调整。通过这种方式,可以确保历史上下文的完整性和连贯性,同时提高解码步骤的效率和准确性。
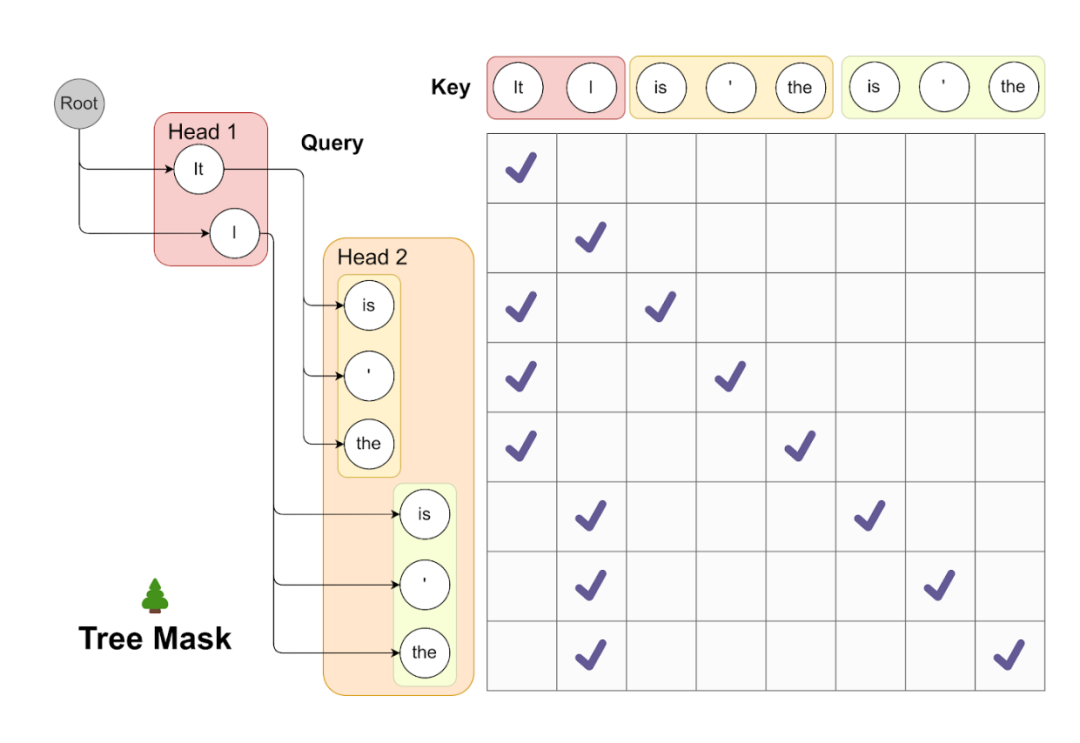
值得注意的是,与一些独立的研究相比,该方法倾向于使用简化形式的树状注意力,其中树的模式在推断期间是规则和固定的,这允许预处理树状注意力掩码,进而提高效率。通过创新这种解码方法,它不仅提供了一个新的解码路径,而且为更精确和高效的未来预测打开了新的可能性。
Typical acceptance
在早期关于投机解码的研究中,重要性采样技术用于产生与原始模型预测紧密相符的多样化输出。但随后的研究表明,随着“creativity dial”或采样温度的增加,这种方法的效率会降低。简而言之,如果一个draft model与原始模型一样优秀,理论上应接受其所有输出,使过程极为高效。但是重要性采样可能会在某个阶段拒绝这种方案。
实际上,人们常常仅调整采样温度来控制模型的创造力,而不是严格匹配原始模型的分布。那么为什么不只是接受看似合理的候选项呢?Typical acceptance策略受到截断采样的启发,目的是选取根据原始模型被视为足够可能的候选项。通过设置基于原始模型预测概率的阈值,如果候选项超过这个阈值,则将其接受。
在技术语言中,我们采用硬阈值和依赖于熵的阈值中的最小值来决定是否接受一个候选项,如截断采样中所做。这确保在解码期间选择了有意义的标记和合理的延续。第一个标记总是通过贪婪解码被接受,确保每一步至少生成一个标记。最终输出是通过接受测试的最长序列。这种方法的优点在于其适应性。如果将采样温度设置为零,它将简单地退化为最有效的形式——贪婪解码。提高温度会使方法变得更加高效,允许更长的接受序列,这一点已通过严格测试得到验证。
性能测试
在Vicuna模型上测试了Medusa,这些模型是特别为聊天应用优化和调整的羊驼模型,其大小不同,参数数量分别为7B、13B和33B。目标是衡量Medusa在现实世界的聊天机器人环境中能够多大程度上加速这些模型的运行。
训练Medusa头部选择了简单的方式,使用了公开的ShareGPT数据集,这是最初用于训练Vicuna模型的数据的一个子集,只进行了一个时代的训练。
这里的重点是——整个训练过程可以在几小时到一天之内完成,具体取决于模型的大小,全部在单个A100-80G GPU上完成。显著的是,Medusa可以与量化基模型轻松结合,从而减少内存需求。为了利用这一优势,在训练33B模型时使用了8位量化。
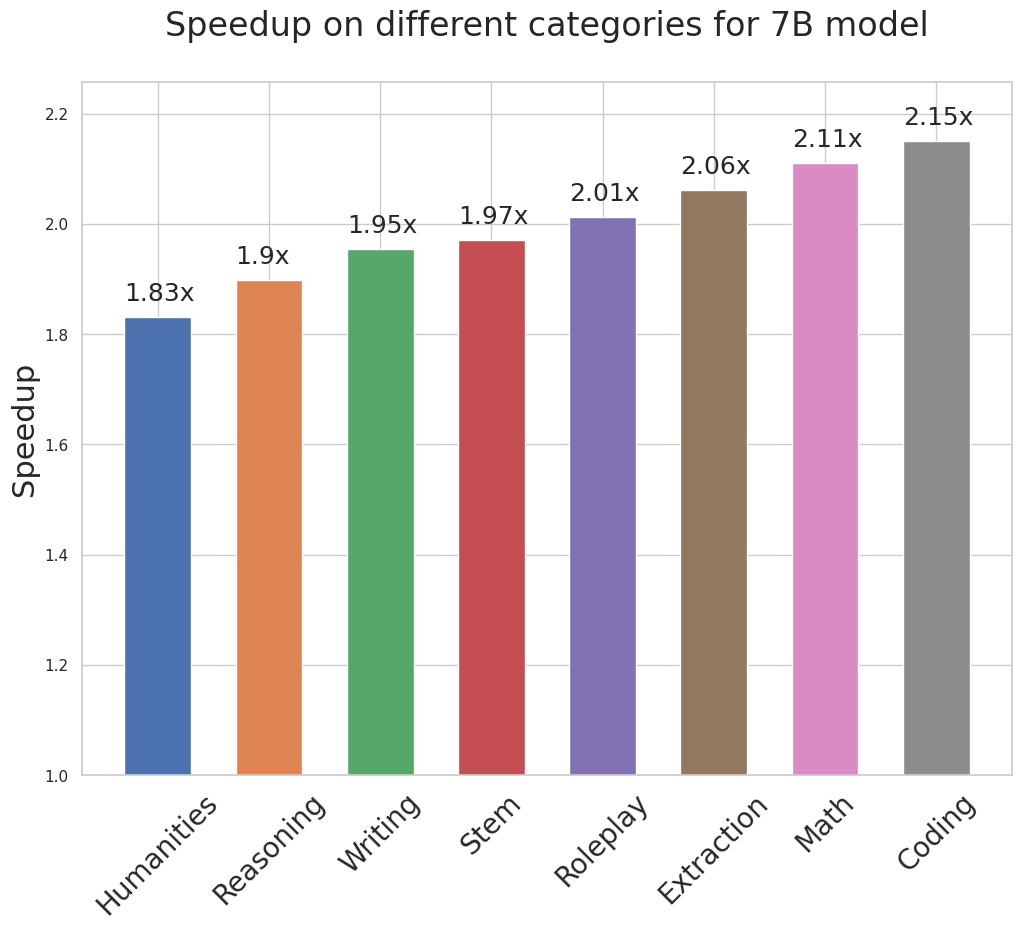
为模拟现实环境,采用了MT测试台进行评估。结果是令人鼓舞的:Medusa借助其简单的设计,在各种用例中稳定实现了约2倍的实际运行时间加速。显著的是,有了Medusa的优化,33B参数的Vicuna模型可以与13B模型一样快速运行。
结语
Medusa技术致力于通过多层头部预测方法来加速LLM的语言生成速度。该研究中引入了多个Medusa头和Tree attention机制,通过预测多个即将出现的标记而非一个来优化生成速度,同时还保持了高准确率。此外,研究还提出了Typical acceptance方案,它基于原始模型的预测概率来选择候选项,而不是依赖重要性抽样,使得创意输出更为高效和自适应。
在实际测试中,Medusa成功地将Vicuna模型的运行速度提高了大约两倍,证明了其在现实世界的聊天机器人环境中的实用性和效果。整体来看,Medusa为开发更快、更有效的聊天机器人开辟了新的可能,显示出在语言模型生成领域的巨大潜力。
编辑:黄飞
-
小白学大模型:从零实现 LLM语言模型2025-04-30 1550
-
无法在OVMS上运行来自Meta的大型语言模型 (LLM),为什么?2025-03-05 349
-
什么是LLM?LLM在自然语言处理中的应用2024-11-19 5207
-
LLM大模型推理加速的关键技术2024-07-24 3630
-
LLM模型的应用领域2024-07-09 2447
-
了解大型语言模型 (LLM) 领域中的25个关键术语2024-05-10 2252
-
Meta发布一款可以使用文本提示生成代码的大型语言模型Code Llama2023-08-25 2769
-
大型语言模型的应用2023-07-05 3096
-
基于Transformer的大型语言模型(LLM)的内部机制2023-06-25 2768
-
大型语言模型(LLM)的自定义训练:包含代码示例的详细指南2023-06-12 3902
-
大型语言模型能否捕捉到它们所处理和生成的文本中的语义信息2023-05-25 1540
-
大型语言模型有哪些用途?大型语言模型如何运作呢?2023-03-08 9714
-
大型语言模型有哪些用途?2023-02-23 6359
全部0条评论

快来发表一下你的评论吧 !
