

单细胞细胞注释详解之singleR细胞注释
描述
细胞注释是单细胞研究中十分重要的环节,人工注释需要借助文献检索或者结合常用的注释数据库来寻找marker基因,准确性相对较好,但对于研究者研究背景的了解程度具有一定的要求,并且比较耗时。软件自动化注释一般是使用软件内置参考数据集进行注释,操作相对简单,虽然准确性较人工注释相对稍差,但可以作为一种很好的辅助注释手段。
SingleR 是一个用于对 scRNA-seq 数据进行细胞类型自动注释的 R 包,其自带 7 个参考数据集,包括 5 个人类和 2 个小鼠数据集:
· BlueprintEncodeDataBlueprint (Martens and Stunnenberg 2013) and Encode (The ENCODE Project Consortium 2012) (人);
· DatabaseImmuneCellExpressionDataThe Database for Immune Cell Expression(/eQTLs/Epigenomics)(Schmiedel et al. 2018)(人);
· HumanPrimaryCellAtlasDatathe Human Primary Cell Atlas (Mabbott et al. 2013)(人);
· MonacoImmuneDataMonaco Immune Cell Data - GSE107011 (Monaco et al. 2019)(人)
· NovershternHematopoieticDataNovershtern Hematopoietic Cell Data - GSE24759(人)
· ImmGenDatathe murine ImmGen (Heng et al. 2008) (鼠)
· MouseRNAseqDataa collection of mouse data sets downloaded from GEO (Benayoun et al. 2019).(鼠)
SingleR注释结果展示
首先, 基于singleR参考细胞类型对实验样本的每个细胞进行评分,若细胞在一个参考细胞类型中的得分显著高于其他标签,表示对应的细胞类型可能性越大。结果由细胞评分热图展示,如下图:
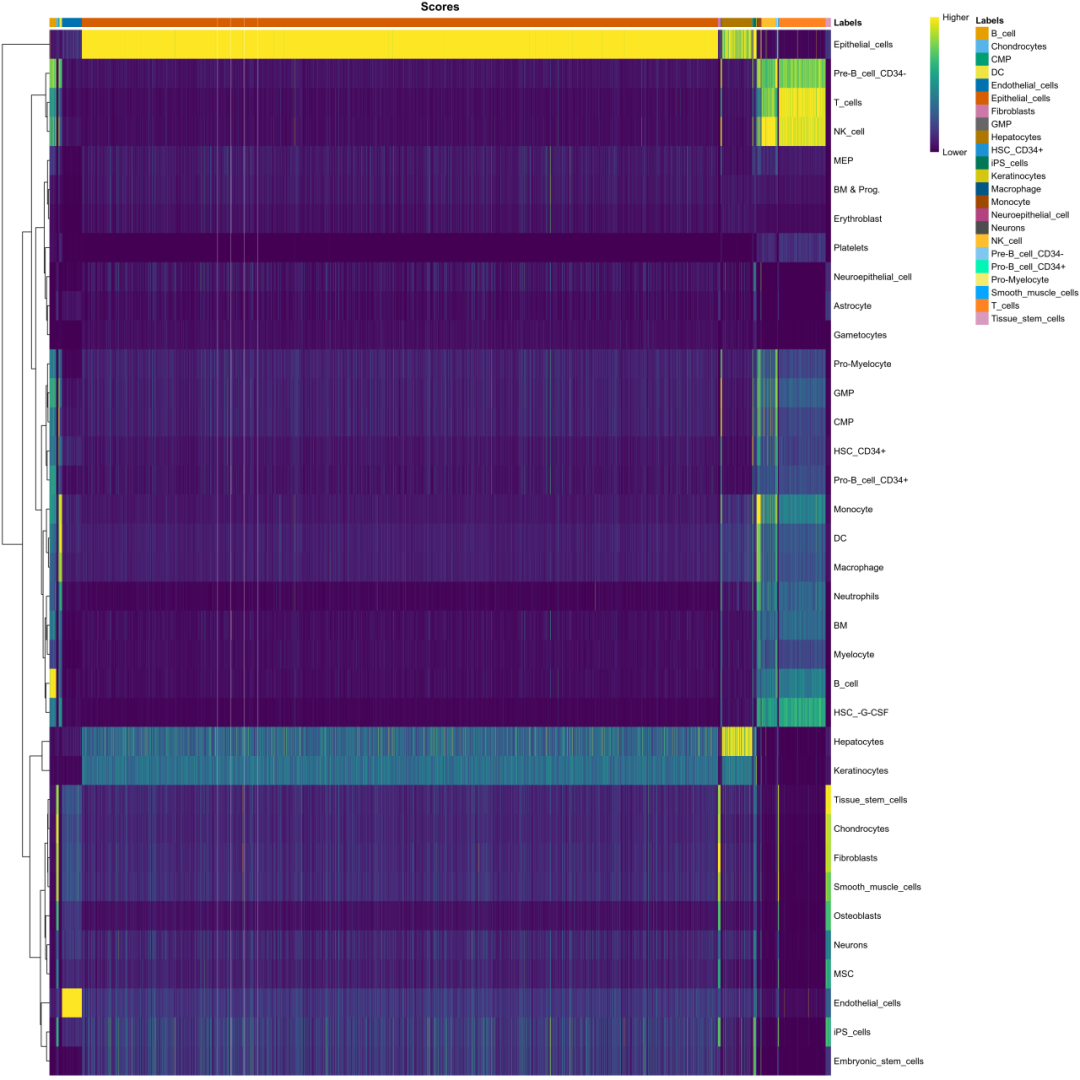
图1:细胞评分热图
横轴代表样品中的每个细胞,纵轴为 Single R 参考细胞类型;黄色到蓝色代表细胞评分逐渐降低,细胞在一个标签的得分越高,表示对应的细胞类型可能性越大。
除了对每个细胞的所属细胞类型进行评分外,singleR还会对seuret聚类结果中每个cluster中各细胞类型比例进行分析,评估每个cluster所属的细胞类型。结果由细胞比例矩阵图展示,如下图:
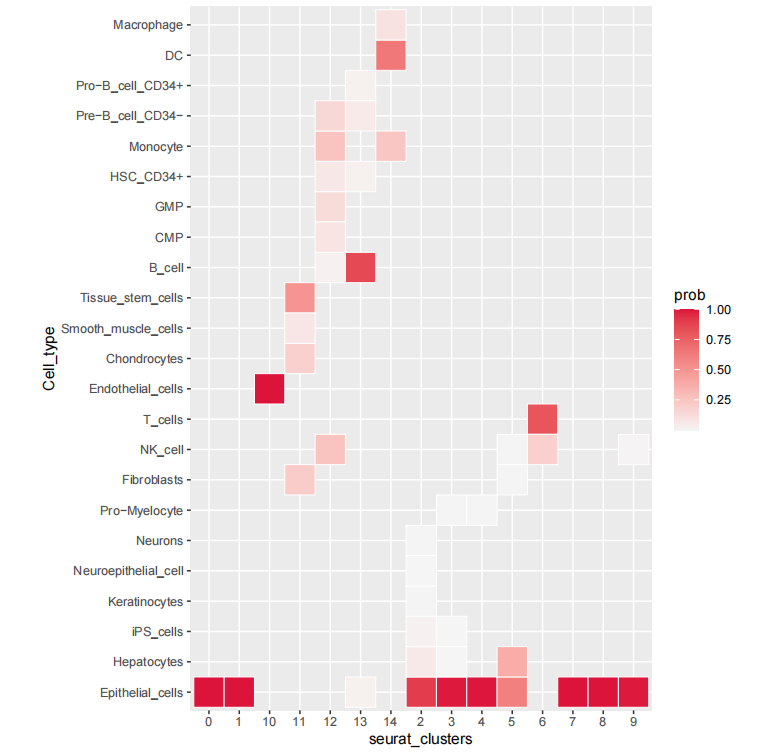
图2:细胞比例矩阵图
纵轴为 Single R 参考细胞类型,横坐标为样本 cluster,红色越深细胞比例越高,表示该细胞类型在当前cluster中的占比越高。
在得到每个细胞所属细胞类型的评分以及每个cluster中的细胞比例, Single R会基于上述数据进行细胞类型注释,并绘制细胞类型注释结果的tSNE/UMAP图。结果如下图所示:
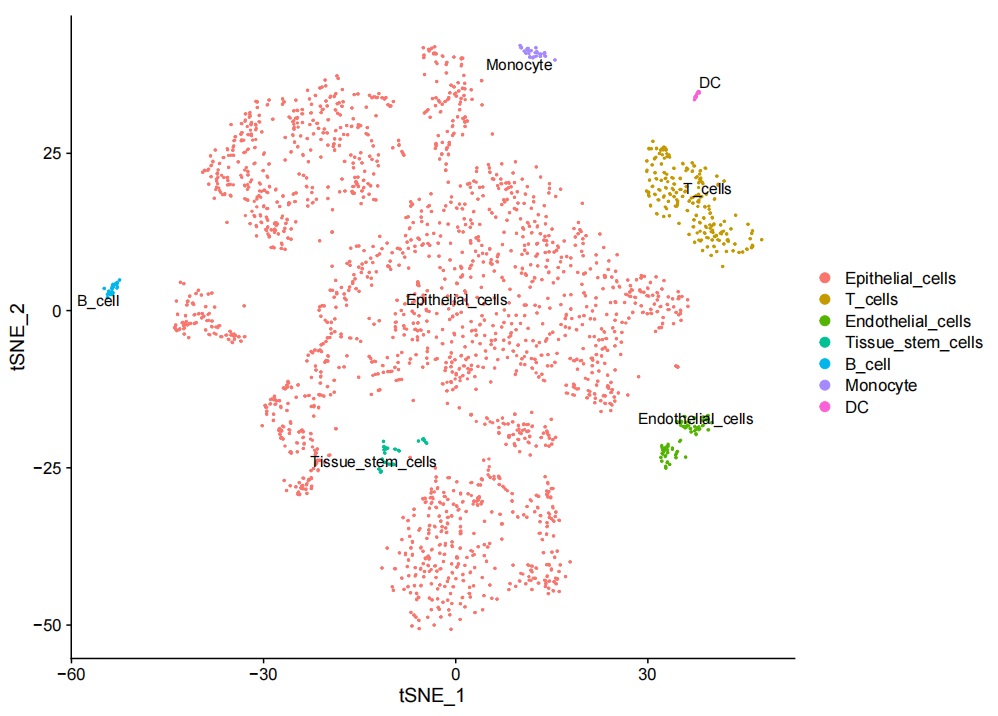
图3:细胞分群 tSNE 图
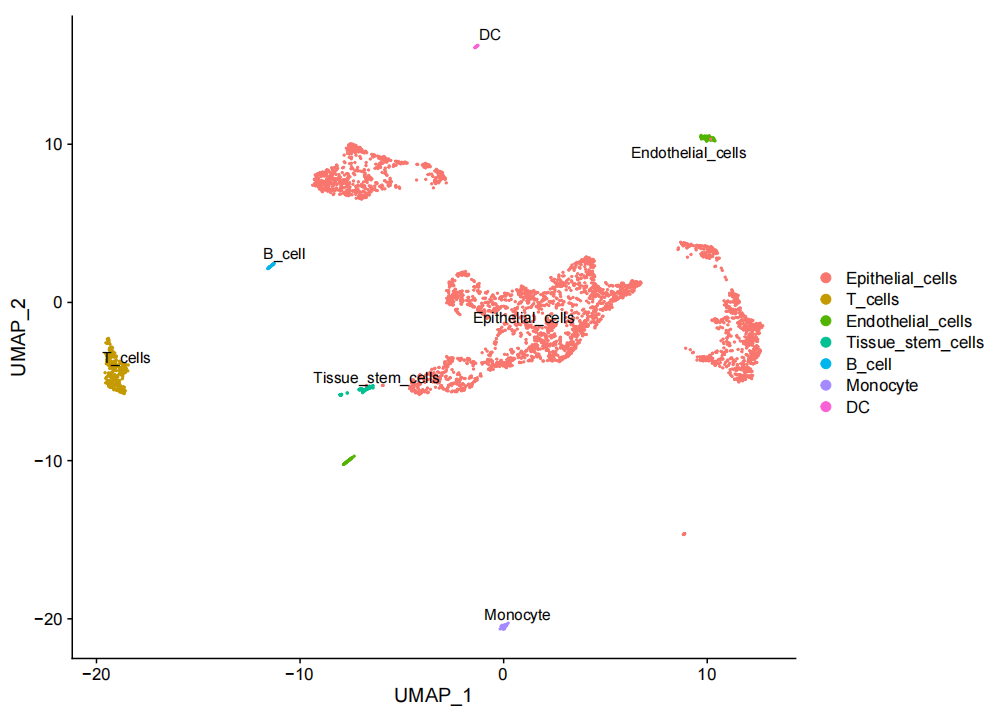
图4:细胞分群 UMAP 图
关于SBC中心实验室
SBC中心实验室聚焦单细胞、空间多组学前沿技术,围绕基因组、表观组、转录组、蛋白组、代谢组和微生物组等多维组学研究,以国际一流水平的技术平台,二十余年专业经验的技术团队,打造创新产品服务体系,高效助力科学发现产品研发。中心始终以严谨的科学态度,坚持创新,服务国家重大战略任务,推动技术成果转化应用和带动产业集群发展。长期举办学术论坛、专题研讨会、前沿技术培训,为数十家跨国制药企业和上千家国内科研机构、院校、医院提供系统全面一站式的科研与转化解决方案,日益发挥面向生物医药全行业功能效益和策源动力。
-
微流控芯片在单细胞捕获中的应用2019-04-08 9912
-
什么是高通量单细胞RNA测序技术?2019-04-25 11464
-
微流控芯片单细胞克隆形成抑制实验用于乳腺癌干细胞特异性药物筛选2019-06-20 6747
-
厦门大学研发出全新高通量单细胞转录组测序方法2020-06-02 4771
-
单细胞转录组学技术的十年2020-09-23 4951
-
“解码”单细胞测序的故事2021-03-17 3250
-
mTORC1高活性的干细胞样状态肿瘤细胞类型分析2022-10-10 3211
-
基于单细胞与空间转录组数据评估细胞间互作分析算法2022-11-03 2311
-
基于微流控平台的单细胞通讯研究进展2022-11-29 1938
-
单细胞+转录组测序:揭示GABA信号调控神经发生2023-01-12 1952
-
CellTrek单细胞空间转录组联合分析2023-04-01 3701
-
可用于单细胞分析的选择性液滴提取微流控装置2023-04-10 2014
-
北京基因组所开发出新型高通量单细胞多组学技术2023-04-20 2264
-
使用 RAPIDS 进行更快的单细胞分析2023-07-05 1675
-
用于单细胞谱系追踪图像引导的微流控系统2023-08-18 2328
全部0条评论

快来发表一下你的评论吧 !
