

Elasticsearch存在的各种漏洞问题
描述
elasticsearch 8
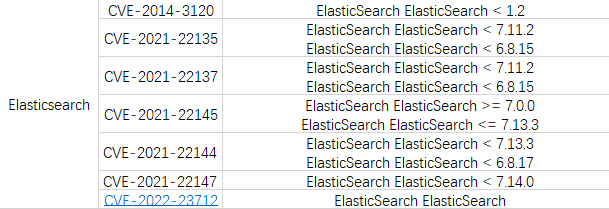
之前使用的一个老系统使用了elasticsearch7.x版本,之后又反应es版本存在各种漏洞
无奈只能做版本升级来解决问题,计划是将版本升级到8.x,在网上了解了下两个版本的区别,主要包括以下变化:
- Rest API相比较7.x而言做了比较大的改动(比如彻底删除_type),为了降低用户的升级成本,8.x会暂时的兼容7.x的请求。
- 默认开启安全配置(三层安全),并极大简化了开启安全需要的工作量,可以这么说:7.x开启安全需要10步复杂的步骤比如CA、证书签发、yml添加多个配置等等,8.x只需要一步即可)。
- 存储空间优化:更新了倒排索引,对倒排文件使用新的编码集,对于keyword、match_only_text、text类型字段有效,有3.5%的空间优化提升,对于新建索引和segment自动生效。
- 优化geo_point,geo_shape类型的索引(写入)效率:15%的提升。
- 新特性:支持上传pyTorch模型,在ingest的时候使用。比如在写入电影评论的时候,如果我们想要知道这个评论的感情正负得分,可以使用对应的AI感情模型对评论进行运算,将结果一并保存在ES中。
- 技术预览版KNN API发布,(K邻近算法),跟推荐系统、自然语言排名相关。之前的KNN是精确搜索,在大数据集合的情况会比较慢,新的KNN提供近似KNN搜索,以提高速度。
- 对ES内置索引的保护加强了:elastic用户默认只能读,如果需要写权限的时候,需有allow_restrict_access权限。
那么在基于spring-boot的开发时,我们大概需要做些对应的调整了,要包括以下几点:
- spring-data-elasticsearch版本升级
- 客户端依赖由elasticsearch-rest-high-level-client调整为elasticsearch-java
- JDK版本升级到17
借着这个机会,重温下es相关的知识……
创建索引
- 基于Elasticsearch Rest API
PUT localhost:9200/index_novel
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 1
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"fields": {
"keyword": { "ignore_above": 256, "type": "keyword" }
}
},
"author": { "type": "keyword" },
"category": { "type": "keyword" },
"type": { "type": "keyword" },
"description": { "analyzer": "ik_max_word", "type": "text" },
"content": { "analyzer": "ik_max_word", "type": "text" },
"coverUrl": { "type": "text" },
"insertTime": { "format": "date_time", "type": "date" },
"updateTime": { "format": "date_time", "type": "date" },
"status": { "type": "keyword" }
}
}
}
- 基于SpringBoot创建
- 定义Novel实体
@Data
@Document(indexName = "index_novel")
public class Novel {
}
- 定义Repository
public interface NovelDao extends ElasticsearchDao< Novel, String > { }
- 启用Elasticsearch Repositories支持
@EnableElasticsearchRepositories
4主要实现在SimpleElasticsearchRepository中:
public SimpleElasticsearchRepository(ElasticsearchEntityInformation< T, ID > metadata,
ElasticsearchOperations operations) {
this.operations = operations;
Assert.notNull(metadata, "ElasticsearchEntityInformation must not be null!");
this.entityInformation = metadata;
this.entityClass = this.entityInformation.getJavaType();
this.indexOperations = operations.indexOps(this.entityClass);
if (shouldCreateIndexAndMapping() && !indexOperations.exists()) {
indexOperations.createWithMapping();
}
}
字段类型
Elasticsearch 支持多种字段类型,每种类型都有其独特的作用和功能。其中常见的字段类型包括:
- Text:用于存储文本内容,支持全文搜索、模糊搜索、正则表达式搜索等功能。
- Keyword:用于存储关键词,支持精确匹配和聚合操作。
- Date:用于存储日期时间类型的数据,支持日期范围查询、日期格式化等功能。
- Numeric:用于存储数值类型的数据,支持数值范围查询、聚合操作等功能。
- Boolean:用于存储布尔类型的数据,支持精确匹配和聚合操作。
- Geo-point:用于存储地理位置信息,支持距离计算、地理位置聚合等功能。
- Object:用于存储复杂的结构化数据,支持嵌套查询、嵌套聚合等功能。
text
Es中的text类型是一种用于处理长文本的数据类型,适合于全文搜索和分析。当将文本字段映射为text类型时,文本会被分析器分词处理成一个个单词, 然后被存储在倒排索引中,以便后续进行全文搜索。text类型支持多种分析器和过滤器,可以对不同的文本进行不同的分词处理,以达到最佳的搜索效果。此外, text类型还支持词项位置信息和偏移量信息的存储,以便进行精确的搜索和高亮显示。
keyword
ES把keyword类型的值作为一整体存在倒排索引中,不进行分词。 keyword适合存结构化数据,如性别、手机号、数据状态、标签HttpCode(404,200,500)等。 字段常用来精确查询、过滤、排序、聚合时,应设为keyword,而不是数值型。 如果某个字段你经常用来做range查询, 你还是设置为数值型(integer,long),ES对数字的range有优化。 还可以把字段设为multi-field,这样又有keyword类型又有数值类型,方便多种方式的使用。 最长支持32766个UTF-8类型的字符,但放入倒排索引时,只截取前一段字符串,长度由ignore_above参数决定,默认"ignore_above" : 256。
Auto
在spring中,支持一种auto的数据类型,通过在字段上添加注解实现@Field(type = FieldType.Auto),Auto申明的类型除了生成一个text类型字段外,还会多一个.keyword的keyword类型的字段。
@Field(type = FieldType.Auto)
private String title;
上面对应的mapping:
{
"title": {
"type": "text",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
}
}
fields可以让同一文本有多种不同的索引方式,比如上面text类型的字段title,可以使用text类型做全文检索,使用keyword类型做聚合和排序。
通过这种方式,可以实现一个字段运用于不同的场景。要知道字段类型的使用场景是受限的。在mapping中通过添加fields的扩展字段, 让一个字段拥有多个子字段类型,使得一个字段能够被多个不同的索引方式进行索引。
查询
以下是 Elasticsearch 中所有的查询类型:
Match Query:用于匹配文本类型字段中的文本。
Multi-match Query:用于在多个字段中匹配文本类型字段中的文本。
Term Query:用于匹配非文本类型字段(如数字、布尔值等)中的确切值。
Terms Query:用于匹配非文本类型字段(如数字、布尔值等)中的多个确切值。
Range Query:用于匹配数字、日期等范围内的值。
Exists Query:用于匹配指定字段是否存在值。
Prefix Query:用于匹配以指定前缀开头的文本。
Wildcard Query:用于匹配包含通配符的文本。
Regexp Query:用于使用正则表达式匹配文本。
Fuzzy Query:用于匹配类似但不完全匹配的文本。
Type Query:用于匹配指定类型的文档。
Ids Query:用于根据指定的文档 ID 匹配文档。
Bool Query:用于组合多个查询条件,支持AND、OR、NOT等逻辑操作。
Boosting Query:用于根据指定的查询条件调整文档的权重。
Constant Score Query:用于为所有匹配的文档分配相同的分数。
Function Score Query:用于根据指定的函数为匹配的文档分配自定义分数。
Dis Max Query:用于在多个查询条件中选择最佳匹配的文档。
More Like This Query:用于根据文档内容查找相似的文档。
Nested Query:用于在嵌套对象中查询。
Geo Distance Query:用于查询地理坐标范围内的地点。
Span Term Query:用于匹配指定的单个术语。
Span Multi Term Query:用于匹配指定的多个术语。
Span First Query:用于匹配文档中的首个匹配项。
Span Near Query:用于匹配多个术语之间的近似距离。
Span Or Query:用于匹配任何指定的术语。
Span Not Query:用于匹配不包含指定术语的文档。
Script Query:用于根据指定的脚本匹配文档。
下面看下一些常用的简单查询,后面的复合查询以及聚合查询都是基于这些简单查询来组合嵌套来实现。
URL : POST localhost:9200/index_novel/_search
match
根据关键字对某个字段进行检索,当然传入的参数会先进行分词,然后进行匹配
{
"_source": ["title","author","type","category","description","status","updateTime"],
"query": {
"match": {
"title": {
"query": "天下",
"minimum_should_match": "30%"
}
}
}
}
match_phrase
词项匹配(查询分词的词项必须完全匹配到索引分词的词项中,并且词项的相对位置position必须一致),分词后的相对位置也必须要精准匹配(slop)
{
"_source": ["title","author","type","category","description","status","updateTime"],
"query": {
"match_phrase": {
"title" : {"query": "天下", "slop": "1"}
}
}
}
term
根据词条完全匹配,也就是精确查询,搜索前不会对搜索词进行分词解析,直接对搜索词进行查找;
{
"_source": ["title","author","type","category","description","status","updateTime"],
"query": {
"term": { "author": "泪冠哀歌" }
}
}
复合查询
bool
query和filter两种不同的Context
- query context:相关性算分
- filter context:不需要算分 ( yes or no ),可以缓存cache,性能更高
bool一共支持4中查询,每一种子查询都可以嵌套多个简单查询
- must 必须匹配某些条件才可以返回,计算分值
- must_not 必须不匹配某些条件,不计算分值
- should 当满足此条件时,计算分值
- filter 必须匹配,不会计算分值
{
"query":{
"bool":{
"filter":{
"term":{ "title":"遮天" }
},
"should":[
{
"match": { "title":"遮天" }
}
],
"must":[
{
"match":{ "title":"遮天" }
}
]
}
}
}
constant_score
查询返回的相似度分与字段上指定boost参数值相同的数据
{
"_source": ["title","author","type","category","description","status","updateTime"],
"query": {
"constant_score": {
"filter": {
"term": {
"description": "天下"
}
},
"boost": 1
}
}
}
dis_max
最大析取(disjunction max) 返回的文档必须要满足多个查询子句中的一项条件; 若一个文档能匹配多个查询子句时,则dis_max查询将为能匹配上查询子句条件的项增加额外分,即针对多个子句文档有一项满足就针对满足的那一项分配更高分, 这也能打破在多个文档都匹配某一个或多个条件时分数相同的情况;
{
"_source": ["title","author","type","category","description","status","updateTime"],
"query": {
"dis_max": {
"tie_breaker": 0.7,
"queries": [
{
"term": {
"description": "天下"
}
}
]
}
}
}
聚合查询
聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如:
语法:
{
"aggs": {
"自定义聚合名称": {
"聚合类型": {
"聚合参数": "参数值"
}
}
}
}
- 聚合类型
- Terms(词条聚合):按照字段值进行分组,统计每个分组的文档数量。
- Sum(求和聚合):计算指定字段的总和。
- Avg(平均值聚合):计算指定字段的平均值。
- Min(最小值聚合):找出指定字段的最小值。
- Max(最大值聚合):找出指定字段的最大值。
- Stats(统计聚合):计算指定字段的统计信息,包括最小值、最大值、总和、平均值和文档数量。
- Extended Stats(扩展统计聚合):计算指定字段的扩展统计信息,包括最小值、最大值、总和、平均值、标准差和文档数量。
- Cardinality(基数聚合):计算指定字段的唯一值数量。
- Date Histogram(日期直方图聚合):按照时间间隔对日期字段进行分组。
- Range(范围聚合):将文档按照指定范围进行分组,例如按照价格范围、年龄范围等。
- Nested(嵌套聚合):在嵌套字段上执行子聚合操作。
- 聚合参数
- field(字段):指定要聚合的字段。
- size(大小):限制返回的聚合桶的数量。
- script(脚本):使用脚本定义聚合逻辑。
- min_doc_count(最小文档数量):指定聚合桶中文档的最小数量要求。
- order(排序):按照指定字段对聚合桶进行排序。
- include/exclude(包含/排除):根据指定的条件包含或排除聚合桶。
- format(格式):对聚合结果进行格式化。
- precision_threshold(精度阈值):用于基数聚合的精度控制。
- interval(间隔):用于日期直方图聚合的时间间隔设置。
- range(范围):用于范围聚合的范围定义。
分页
- from-size
- 查询优点
- 支持随机翻页
- 查询缺点
- 受制于 max_result_window 设置,不能无限制翻页。
- 存在深度翻页问题,越往后翻页越慢。
- From + size 查询适用场景
- 第一:非常适合小型数据集或者大数据集返回 Top N(N <= 10000)结果集的业务场景。
- 第二:类似主流 PC 搜索引擎(谷歌、bing、百度、360、sogou等)支持随机跳转分页的业务场景。
- search_after
- search_after 优点
- 不严格受制于 max_result_window,可以无限制往后翻页。 ps:不严格含义:单次请求值不能超过 max_result_window;但总翻页结果集可以超过。
- search_after 缺点
- 只支持向后翻页,不支持随机翻页。
- search_after 适用场景
- 类似:今日头条分页搜索 https://m.toutiao.com/search 不支持随机翻页,更适合手机端应用的场景。
- scroll
- scroll 查询优点
- 支持全量遍历。 ps:单次遍历的 size 值也不能超过 max_result_window 大小。
- scroll 查询缺点
- 响应时间非实时。
- 保留上下文需要足够的堆内存空间。
- scroll 查询适用场景
- 全量或数据量很大时遍历结果数据,而非分页查询。
- 官方文档强调:不再建议使用scroll API进行深度分页。如果要分页检索超过 Top 10,000+ 结果时,推荐使用:PIT + search_after。
排序
和关系型数据库一样,对关键属性进行升序或降序返回数据。但是要注意,字段不能是text类型
{
"sort": {
"insertTime": { "order": "desc" }
}
}
高亮
我们可能有这样的需求,在检索结果中,将检索关键词进行高亮展示,就像百度搜索的结果,标题和描述中都标记为红色了,elasticsearch同样支持这样的查询, 返回的高亮内容主要是通过`'元素包裹,当然可以通过配置修改。需要注意的是,设置的高亮字段需要和检索字段匹配。
{
"highlight": {
"pre_tags": [
""
],
"post_tags": [
""
],
"fields": {
"description": {
"fragment_size": 100,
"number_of_fragments": 5
}
}
}
}
集成
Elasticsearch与SpringBoot的集成非常简单:
- 引入依赖
< dependency >
< groupId >org.springframework.boot< /groupId >
< artifactId >spring-boot-starter-web< /artifactId >
< /dependency >
< dependency >
< groupId >org.springframework.boot< /groupId >
< artifactId >spring-boot-starter-data-elasticsearch< /artifactId >
< /dependency >
- 编写文档对应实体,申明索引信息
通过@org.springframework.data.elasticsearch.annotations.Document注解可以定定义索引信息,比如是否在系统启动后自动创建
通过@org.springframework.data.elasticsearch.annotations.Field定义各个字段类型等信息
@Data
@Document(indexName = "index_novel")
public class Novel {
// 省略 ...
@Field(type = FieldType.Auto)
private String title;
@Field(type = FieldType.Keyword)
private String author;
@Field(type = FieldType.Keyword)
private String type;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String description;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String content;
// 省略...
}
- 定义DAO抽象接口与代理实现
通过自定义接口方便扩展,当ElasticsearchRepository中提供的方法无法支持时,可以根据业务需求自定义查询方式
在BaseElasticsearchRepository中,可以基于ElasticsearchOperations自定义各种复杂查询
public interface ElasticsearchDao< T, ID > extends ElasticsearchRepository< T, ID >{
}
public class BaseElasticsearchRepository< T,ID > extends SimpleElasticsearchRepository< T,ID > implements ElasticsearchDao< T,ID >{
private ElasticsearchEntityInformation entityInformation;
private ElasticsearchOperations elasticsearchOperations;
public BaseElasticsearchRepository(ElasticsearchEntityInformation metadata, ElasticsearchOperations operations) {
super(metadata, operations);
this.entityInformation = metadata;
this.elasticsearchOperations = operations;
}
}
public interface NovelDao extends ElasticsearchDao< Novel, String > {
}
- 启用Repository并配置DAO的通用实现
@SpringBootApplication
@EnableElasticsearchRepositories(basePackages = "com.sucl.springbootelasticsearch8.dao", repositoryBaseClass = BaseElasticsearchRepository.class)
public class SpringbootElasticsearch8Application {
public static void main(String[] args) {
SpringApplication.run(SpringbootElasticsearch8Application.class, args);
}
}
- 在Service层的使用
@Service
public class NovelService {
private NovelDao novelDao;
public NovelService(NovelDao novelDao) {
this.novelDao = novelDao;
}
}
基于SpringBoot对Elasticsearch的继承整体比较简单,由于ES的查询种类非常多,在Spring中提供了与DSL QUERY对应的API可以使用,只不过没法通过通用的SimpleElasticsearchRepository中实现。
示例
现在基于ES8做了一个简单的示例,主要包括以下功能:
- 从起点小说网按类型加载小说到es
- 基于spring-boot-starter-data-elasticsearch实现小说句的检索
- 起点小说数据加载到elasticsearch,主要实现方式是通过工具jsoup解析小说网站的,并按文档结构组装文档数据,并调用es API将数据存储到es中,大概有以下几个过程
- 访问起点小说网https://www.qidian.com/free/all/,根据传入的分类与页码参数按页获取页面html
- 解析上一步html,分别获取每个小说目录html片段,解析成一部小说文档数据
- 按目录分别加载每个章节页面html,按章节分别加载章节小说内容,最后将所有内容拼接到小说文档数据中
- 调用API将小说数据存储到elasticsearch
- 篇幅有限,具体实现可以参考下面的github
- 小说查询相关DAO可以参考上面的集成
略
- 添加service与controller
@Service
public class NovelService {
private NovelDao novelDao;
public NovelService(NovelDao novelDao) {
this.novelDao = novelDao;
}
/**
* 批量保存
* @param novels
* @return
*/
public List< Novel > saveNovels(List< Novel > novels) {
List< Novel > savedNovels = new ArrayList< >();
novels.forEach(this::configureNovel);
novelDao.saveAll(novels).forEach(savedNovels::add);
return savedNovels;
}
/**
* 根据关键字在指定字段值检索
* @param keyword
* @param fields
* @return
*/
public List< Novel > searchNovels(String keyword, String[] fields) {
DslQuery dslQuery = DslQuery.of(DslQuery.Type.MULTI_MATCH, String.join(",",fields), keyword);
return novelDao.commonQuery(dslQuery, null);
}
/**
* 根据主键查询单条数据,按指定字段查找相似数据
* @param novel
* @param fields
* @param pageable
* @return
*/
public Page< Novel > getPageSimilarNovel(Novel novel, String[] fields, Pager pager) {
return novelDao.searchSimilar(novel, fields, PageRequest.of(pager.getPageIndex(), pager.getPageSize()));
}
}
示例内容涉及到Elasticsearch DSL QUERY组装过程以及上面说到的SimpleElasticsearchRepository不足以支撑业务查询时的一些扩展方法。 示例使用了起点小说网站加载小说数据,其他网站实现思路一样。由于篇幅原因,具体代码实现可以参考:
https://github.com/sucls/springboot-elasticsearch-8
结束语
Elasticsearch版本有7.x升级到8.x时,不仅仅是客户端的变更,运行环境也有较大的改变,Spring版本也做了大版本升级。最后在项目里仅仅是修改了客户端用来匹配与es服务交互时,保证请求响应的过程没有问题。
- 相关推荐
- 热点推荐
- 存储
- 模型
- 漏洞
- 自然语言
- Elasticsearch
-
苹果承认GPU存在安全漏洞2024-01-18 1511
-
Python 更新 Elasticsearch 的几种方法2023-11-01 2413
-
SpringBoot 连接ElasticSearch的使用方式2023-10-09 2792
-
Elasticsearch保姆级入门2023-09-01 1781
-
MySQL数据如何同步Elasticsearch2023-03-24 1679
-
Windows安装ElasticSearch2023-02-15 1866
-
ElasticSearch是什么?应用场景是什么?2022-10-09 3338
-
Elasticsearch6.1教程2022-07-04 586
-
采用ZigBee协议的智能家居设备存在漏洞吗?2021-05-19 1897
-
PCB设计中存在的漏洞有哪些?2020-10-30 1464
-
ElasticSearch的初步环境2020-03-31 1561
-
ElasticSearch的词条查询2019-04-30 1486
-
linux安装配置ElasticSearch之源码安装2019-01-11 3043
-
Spring-Elasticsearch插件说明2016-12-13 651
全部0条评论

快来发表一下你的评论吧 !
